一、SIMON算法简介
SIMON算法是由美国国家安全局设计的一种轻量级分组密码算法,以其简洁高效的特点在资源受限环境中得到广泛应用。论文下载地址:The SIMON and SPECK lightweight block ciphers。该算法采用Feistel结构,具有硬件实现面积小、功耗低等优势。SIMON64/128是SIMON算法家族中的一个具体配置,其中64表示分组长度,128表示密钥长度。整个加密过程包含44轮迭代操作,每轮都包含特定的轮函数计算和轮密钥加操作。
SIMON算法的核心在于其轮函数设计,通过循环移位、按位与和异或运算的组合实现非线性变换。这种设计既保证了密码强度,又使得硬件实现极为高效。轮函数中包含了左循环移位、按位与运算和异或运算,这些操作在硬件层面都可以用极少的逻辑资源实现。
二、流水线实现
本设计采用Verilog硬件描述语言实现了SIMON64/128算法的四级流水线结构。整个系统由三个主要模块构成:顶层控制模块、密钥扩展模块和轮函数计算模块。
在顶层simon模块中,通过精心设计的流水线架构实现了高效的数据处理。系统采用四级流水线,每级处理11轮加密操作,四个simon_round模块并行工作,显著提高了吞吐量。状态寄存器数组state0:4构成了流水线的核心,负责在时钟边沿传递中间计算结果。这种设计使得每个时钟周期都能开始一个新的加密操作,极大提升了系统性能。
密钥扩展模块key_shedule采用序列化设计,通过40个时钟周期完成全部44个轮密钥的生成。该模块利用常数序列Z3和特定的密钥更新函数,从初始128位主密钥派生出所有轮密钥。密钥扩展过程中采用了循环移位和异或运算的组合,确保生成的轮密钥满足密码学安全要求。
轮函数模块simon_round实现了11轮连续的加密操作。每个轮函数包含标准的SIMON轮操作:首先对左半部分进行循环移位和按位与操作,然后将结果与右半部分和轮密钥进行异或。通过11级组合逻辑的级联,该模块在一个时钟周期内完成11轮变换,体现了深度流水线设计的优势。
控制逻辑方面,系统通过ks_busy和encrypt_busy信号协调密钥扩展和加密过程。din_vld_delay寄存器链实现了精确的输出有效性控制,确保只有在完整加密完成后才标记输出有效。这种设计保证了数据处理的正确性和时序的精确性。
cpp
module simon (
input clk,
input rst_n,
input encrypt,
input load_key,
input [63:0] plaintext,
input [127:0] key,
output [63:0] ciphertext,
output reg dout_vld,
output simon_busy
);
wire ks_busy;
wire encrypt_busy;
wire [32*44-1:0] rkey;
wire [31:0] rkey_part[0:43];
wire [63:0] round_out[0:3];
reg [63:0] state[0:4];
reg [3:0] din_vld_delay;
assign ciphertext = state[4];
assign encrypt_busy = encrypt | (|din_vld_delay);
assign simon_busy = encrypt_busy | ks_busy;
always @(posedge clk or negedge rst_n) begin
if (~rst_n) begin
state[0] <= 64'd0;
state[1] <= 64'd0;
state[2] <= 64'd0;
state[3] <= 64'd0;
state[4] <= 64'd0;
end else begin
state[1] <= round_out[0];
state[2] <= round_out[1];
state[3] <= round_out[2];
state[4] <= round_out[3];
if(~ks_busy&encrypt)state[0] <= plaintext;
end
end
always @(posedge clk or negedge rst_n) begin
if (~rst_n) begin
din_vld_delay <= 4'd0;
dout_vld <= 1'b0;
end else if (~ks_busy) begin
din_vld_delay <= {encrypt, din_vld_delay[3:1]};
dout_vld <= din_vld_delay[0];
end
end
genvar i;
generate
for (i = 0; i < 44; i = i + 1) begin : assign_rkey
assign rkey_part[i] = rkey[32*(44-i)-1 : 32*(43-i)];
end
endgenerate
key_shedule u_ks(
.clk(clk),
.rst_n(rst_n),
.load_key(load_key),
.key(key),
.rkey(rkey),
.ks_busy(ks_busy)
);
simon_round u_r1to11 (
.din(state[0]),
.key1(rkey_part[0]),
.key2(rkey_part[1]),
.key3(rkey_part[2]),
.key4(rkey_part[3]),
.key5(rkey_part[4]),
.key6(rkey_part[5]),
.key7(rkey_part[6]),
.key8(rkey_part[7]),
.key9(rkey_part[8]),
.key10(rkey_part[9]),
.key11(rkey_part[10]),
.dout(round_out[0])
);
simon_round u_r12to22 (
.din(state[1]),
.key1(rkey_part[11]),
.key2(rkey_part[12]),
.key3(rkey_part[13]),
.key4(rkey_part[14]),
.key5(rkey_part[15]),
.key6(rkey_part[16]),
.key7(rkey_part[17]),
.key8(rkey_part[18]),
.key9(rkey_part[19]),
.key10(rkey_part[20]),
.key11(rkey_part[21]),
.dout(round_out[1])
);
simon_round u_r23to33 (
.din(state[2]),
.key1(rkey_part[22]),
.key2(rkey_part[23]),
.key3(rkey_part[24]),
.key4(rkey_part[25]),
.key5(rkey_part[26]),
.key6(rkey_part[27]),
.key7(rkey_part[28]),
.key8(rkey_part[29]),
.key9(rkey_part[30]),
.key10(rkey_part[31]),
.key11(rkey_part[32]),
.dout(round_out[2])
);
simon_round u_r34to44 (
.din(state[3]),
.key1(rkey_part[33]),
.key2(rkey_part[34]),
.key3(rkey_part[35]),
.key4(rkey_part[36]),
.key5(rkey_part[37]),
.key6(rkey_part[38]),
.key7(rkey_part[39]),
.key8(rkey_part[40]),
.key9(rkey_part[41]),
.key10(rkey_part[42]),
.key11(rkey_part[43]),
.dout(round_out[3])
);
endmodule
module simon_round (
input [63:0] din,
input [31:0] key1,
input [31:0] key2,
input [31:0] key3,
input [31:0] key4,
input [31:0] key5,
input [31:0] key6,
input [31:0] key7,
input [31:0] key8,
input [31:0] key9,
input [31:0] key10,
input [31:0] key11,
output [63:0] dout
);
wire [31:0] x1, x2, x3, x4, x5, x6, x7, x8, x9, x10, x11;
wire [31:0] y1, y2, y3, y4, y5, y6, y7, y8, y9, y10, y11;
wire [31:0] f1, f2, f3, f4, f5, f6, f7, f8, f9, f10, f11;
assign x1 = din[63:32], y1=din[31:0];
assign f1=({x1[30:0],x1[31]}&{x1[23:0],x1[31:24]})^{x1[29:0],x1[31:30]};
assign x2 = y1 ^ f1 ^ key1, y2 = x1;
assign f2=({x2[30:0],x2[31]}&{x2[23:0],x2[31:24]})^{x2[29:0],x2[31:30]};
assign x3 = y2 ^ f2 ^ key2, y3 = x2;
assign f3=({x3[30:0],x3[31]}&{x3[23:0],x3[31:24]})^{x3[29:0],x3[31:30]};
assign x4 = y3 ^ f3 ^ key3, y4 = x3;
assign f4=({x4[30:0],x4[31]}&{x4[23:0],x4[31:24]})^{x4[29:0],x4[31:30]};
assign x5 = y4 ^ f4 ^ key4, y5 = x4;
assign f5=({x5[30:0],x5[31]}&{x5[23:0],x5[31:24]})^{x5[29:0],x5[31:30]};
assign x6 = y5 ^ f5 ^ key5, y6 = x5;
assign f6=({x6[30:0],x6[31]}&{x6[23:0],x6[31:24]})^{x6[29:0],x6[31:30]};
assign x7 = y6 ^ f6 ^ key6, y7 = x6;
assign f7=({x7[30:0],x7[31]}&{x7[23:0],x7[31:24]})^{x7[29:0],x7[31:30]};
assign x8 = y7 ^ f7 ^ key7, y8 = x7;
assign f8=({x8[30:0],x8[31]}&{x8[23:0],x8[31:24]})^{x8[29:0],x8[31:30]};
assign x9 = y8 ^ f8 ^ key8, y9 = x8;
assign f9=({x9[30:0],x9[31]}&{x9[23:0],x9[31:24]})^{x9[29:0],x9[31:30]};
assign x10 = y9 ^ f9 ^ key9, y10 = x9;
assign f10=({x10[30:0],x10[31]}&{x10[23:0],x10[31:24]})^{x10[29:0],x10[31:30]};
assign x11 = y10 ^ f10 ^ key10, y11 = x10;
assign f11=({x11[30:0],x11[31]}&{x11[23:0],x11[31:24]})^{x11[29:0],x11[31:30]};
assign dout = {y11 ^ f11 ^ key11, x11};
endmodule
module key_shedule (
input clk,
input rst_n,
input load_key,
input [127:0] key,
output [32*44-1:0] rkey,
output ks_busy
);
localparam [0:39] Z3= 40'b1101101110101100011001011110000001001000;
integer i;
reg busy;
reg [31:0] rkey_r[0:43];
reg [7:0] key_counter;
wire [31:0] key_tmp1, key_tmp2;
assign rkey={rkey_r[0], rkey_r[1], rkey_r[2], rkey_r[3], rkey_r[4], rkey_r[5], rkey_r[6], rkey_r[7],
rkey_r[8], rkey_r[9], rkey_r[10], rkey_r[11], rkey_r[12], rkey_r[13], rkey_r[14], rkey_r[15],
rkey_r[16], rkey_r[17], rkey_r[18], rkey_r[19], rkey_r[20], rkey_r[21], rkey_r[22], rkey_r[23],
rkey_r[24], rkey_r[25], rkey_r[26], rkey_r[27], rkey_r[28], rkey_r[29], rkey_r[30], rkey_r[31],
rkey_r[32], rkey_r[33], rkey_r[34], rkey_r[35], rkey_r[36], rkey_r[37], rkey_r[38], rkey_r[39],
rkey_r[40], rkey_r[41], rkey_r[42], rkey_r[43]};
assign key_tmp1 = {rkey_r[43][2:0], rkey_r[43][31:3]}^rkey_r[41];
assign key_tmp2 = rkey_r[40]^key_tmp1^{key_tmp1[0],key_tmp1[31:1]}^32'hfffffffc;
assign ks_busy = busy|load_key;
always @(posedge clk, negedge rst_n) begin
if(!rst_n)begin
key_counter<=8'd0;
busy<=1'b0;
for(i=0;i<44;i=i+1)begin
rkey_r[i]<=32'd0;
end
end else begin
if(load_key & ~busy) begin
busy<=1'b1;
rkey_r[40]<=key[127:96];
rkey_r[41]<=key[95:64];
rkey_r[42]<=key[63:32];
rkey_r[43]<=key[31:0];
end else if(busy) begin
key_counter<=key_counter+8'd1;
for(i=0;i<43;i=i+1)begin
rkey_r[i]<=rkey_r[i+1];
end
rkey_r[43]<=key_tmp2^Z3[key_counter];
if(key_counter==8'd39) begin
busy<=1'b0;
key_counter<=8'd0;
end
end
end
end
endmodule三、仿真与总结
我们使用下面的testbech在modelsim上进行仿真:
cpp
module tb;
reg clk;
reg rst;
reg encrypt,load_key;
reg [63:0] plaintext;
reg [127:0] key;
wire [63:0] ciphertext;
wire dout_vld,busy;
simon u_simon(
.clk(clk),
.rst_n(rst),
.encrypt(encrypt),
.load_key(load_key),
.plaintext(plaintext),
.key(key),
.ciphertext(ciphertext),
.dout_vld(dout_vld),
.simon_busy(busy)
);
initial begin
clk = 0;
rst = 0;
encrypt=0;
load_key=0;
plaintext = 64'h0;
key = 128'h030201000b0a0908131211101b1a1918;
#20;
rst = 1;
#20;
load_key = 1;
#10;
load_key = 0;
#10;
wait(busy==0);
#25;
#10;
encrypt = 1;
plaintext = 64'h656b696c20646e75;
#10;
encrypt=0;
#20;
encrypt = 1;
plaintext = 64'h0;
#10;
encrypt = 0;
#10;
encrypt = 1;
plaintext = 64'hffffffffffffffff;
#10;
encrypt = 0;
end
always @(negedge dout_vld) begin
$display("ciphertext = %h",ciphertext);
end
always #5 clk = ~clk;
endmodule代码中使用了官方测试向量:
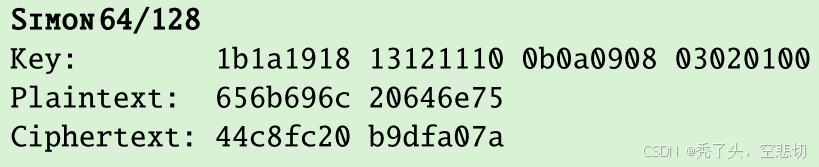
modelsim仿真结果如下,可以看到结果与预期完全一致:

该SIMON64/128流水线实现展示了现代密码算法硬件优化的典型方法。通过四级流水线架构,系统在面积和速度之间取得了良好平衡,既保持了较高的吞吐率,又控制了硬件资源消耗。密钥扩展与加密操作的并行执行进一步提升了整体效率。
深度组合逻辑的运用使得单个模块能够处理多轮加密,减少了流水线级数,降低了控制复杂度。精心设计的时序控制机制确保了数据在流水线中的正确流动,避免了资源冲突和数据 hazards。
这种实现方式特别适合需要高性能加密的应用场景,如网络安全设备、高速通信系统等。同时,模块化的设计也为进一步优化和配置变更提供了便利,体现了硬件密码实现领域的最佳实践。
附件 Python实现
为了方便理解和对比,最后同时附上Python实现:
python
def RLn(x, n):
t1 = (x << n) & 0xffffffff
t2 = (x >> (32 - n)) & 0xffffffff
return t1 | t2
def RRn(x, n):
t1 = (x >> n) & 0xffffffff
t2 = (x << (32 - n)) & 0xffffffff
return t1 | t2
def key_schedule(key):
z3 = [1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1]
rkey = [0] * 44
for i in range(4):
rkey[i] = key[i]
for i in range(4, 44):
tmp1 = RRn(rkey[i - 1], 3) ^ rkey[i - 3]
tmp2 = tmp1 ^ RRn(tmp1, 1)
rkey[i] = rkey[i - 4] ^ tmp2 ^ z3[i - 4] ^ 0xfffffffc
print(f"key{i}: {rkey[i]:08x}")
return rkey
def encrypt(plain, rkey):
x, y = plain[0], plain[1]
for i in range(44):
tmp = x
x = y ^ (RLn(x, 1) & RLn(x, 8)) ^ RLn(x, 2) ^ rkey[i]
y = tmp
print(f"encrypt{i}: {x:08x} {y:08x}")
cipher = [x, y]
return cipher
if __name__ == '__main__':
plain = [0x656b696c, 0x20646e75]
key = [0x03020100, 0x0b0a0908, 0x13121110, 0x1b1a1918]
rkey = key_schedule(key)
cipher = encrypt(plain, rkey)
print(f"cipher: {cipher[0]:08x} {cipher[1]:08x}")