从 token 到向量:微信 CALM 模型颠覆大语言模型范式
大家好,我是AI算法工程师七月,曾在华为、阿里任职,技术栈广泛,爱好广泛,喜欢摄影、羽毛球。目前个人在烟台有一家企业星瀚科技。
- 关注公众号:量子基态,获取最新观察、思考和文章推送。
- 关注知乎:量子基态,获取最新观察、思考和文章推送。
- 关注CSDN:量子基态,获取最新观察、思考和文章推送。
- 关注稀土掘金:量子基态,获取最新观察、思考和文章推送。
- 网站1 :七月
- 网站2:zerodesk
我会在这里分享关于 编程技术、独立开发、行业资讯,思考感悟 等内容。爱好交友,想加群滴滴我,wx:swk15688532358,交流分享
如果本文能给你提供启发或帮助,欢迎动动小手指,一键三连 (点赞、评论、转发),给我一些支持和鼓励,谢谢。
作者:七月 链接:www.xinghehuimeng.com.cn 来源:七月 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
传送门
项目:shaochenze.github.io/blog/2025/C...
论文:2510.27688 Continuous Autoregressive Language Models
微信CALM模型发布
自从GPT的发布到现在,一直是以预测下一个token的作为大语言模型的范式。这一能力离不开token的自回归生成机制,让模型可以通过逐词预测构建文本序列。
添加图片注释,不超过 140 字(可选)
然而,随着模型参数量突破万亿级,token预测方式暴露出了诸多缺点:一次仅能生成一个token的模式严重限制其效率;另外token的语义上限让模型难以突破上上下文的思考。
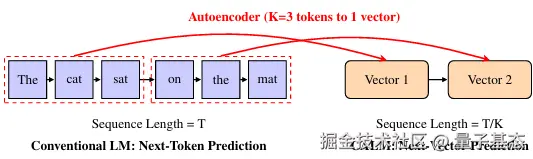
因此,微信AI联合清华发布了CALM,从预测token转变为预测下一个向量。通过将持续多个token压缩为语义向量,使得生成的步骤变为原来的1/k,再性能相当的前提下,训练的计算量降低了44%,推理减少34%。
模型架构
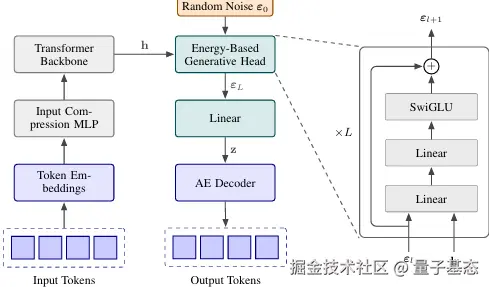
CALM 的整体架构由四大模块组成,形成端到端的生成链路:预处理模块对输入文本进行 tokenization,按固定长度 K 划分 token 块;语义压缩模块通过高保真自编码器将每个 token 块转化为连续潜向量;连续生成模块基于 Transformer 骨干网络与 Energy Transformer 生成头,自回归预测下一个潜向量;语义重构模块通过解码器将生成的潜向量转化为 token 序列输出。其中,Transformer 骨干网络采用标准的 Decoder-only 结构,确保模型具备强大的上下文理解能力,生成头则替换为 Energy Transformer 适配连续向量生成需求。
提升语义带宽
CALM 提出了 "语义带宽" 的核心概念 ------ 即每个生成单元所能承载的语义信息量。通过将 K 个 token 打包为一个连续向量,模型的语义带宽实现了 K 倍提升,生成步骤则相应减少至 1/K。例如当 K=4 时,原本需要 4 步生成的 4 个 token,现在仅需 1 步即可完成,很明显的是效率获得了极大的提升。
传统的模型通过学习上下文与下一个 token 的概率分布实现序列生成。这种模式的第一个瓶颈在于语义带宽的物理极限:token 的语义承载能力受限于词表规模。
在典型的 32K 词表中,每个 token 的语义带宽仅约 15 位,若要翻倍带宽,词表规模需呈指数级增长,这会导致模型计算量与存储成本急剧爆炸。从字符级到子词级的进化,已耗尽了离散 token 的优化空间,进一步提升语义密度变得不可行。
和传统的离散的token相比,这种打包token为向量进行预测的方式,极大的提升了语义承载能力上限,并且由于其架构特点,具备潜空间结构,支持梯度优化等,为无思染的训练等方式提供了基础。
添加图片注释,不超过 140 字(可选)
根据研究,这种多token合成为一个向量并不是简单的直接合并,而是通过自编码器建立一种离散token和向量之间的双向映射。
无似然建模
仅仅是通过简单的token的合成并不能满足大模型的大规模语义的这个要求。因此研究中指出,通过基于transformers的编码器和交叉熵损失函数的优化,来确保重构精度。经过实验表明该方案能以超过99%的准确率重构token序列,基本相当于无损压缩。
这种方案的缺点也显而易见,那就是前空间的脆弱,即使是轻微的噪声也会导致解码器出现输出不同文本的情况。
对此,官方采用了VAE+KL的方式提升模型的鲁棒性,进一步提升稳定性,确保重构率仍能保持再99%的无损压缩的精度。
将语言建模从离散token转换为向量后,由于连续空间中不存在有限此表,这就无法通过softmax计算显式概率分布,所以传统的那种最大似然的训练方式已经不再适用于CALM的训练。CALM团队提出了一种新的方案:通过个生成头以隐藏状态为输入,直接输出前向量,不需要迭代采样就可以实现直接计算完成。
上文中的生成头是通过能量分数实现的,一改常态的,模型不在使用某个token出现的概率,反而通过能量分数判断生成向量和真实语义的契合度。通过距离损失和对比学习损失的双约束机制实现能量机制,避免了模式崩溃的问题。
训练
该研究的训练可大致分为三个阶段:
- 第一阶段训练高保真自编码器,使用大规模文本语料(如 The Pile)通过交叉熵损失优化双向映射精度;
- 第二阶段冻结自编码器参数,用潜向量序列训练 Transformer 骨干与 Energy Transformer 生成头,通过能量损失函数优化生成性能;
- 第三阶段解冻自编码器部分参数,与生成模块联合微调,进一步提升端到端生成质量。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
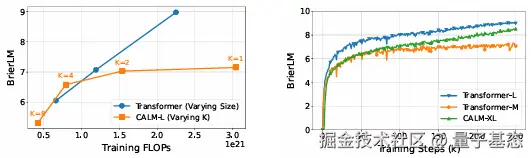
根据论文,语义带宽 K 是 CALM 的核心参数,直接影响性能与效率:K=1 等同于传统 token 级生成,无效率优势;K=2 时训练算力减少 50%,性能下降不明显;K=4 时实现效率与性能的最佳平衡,与同量级传统模型性能相当且训练算力减少 44%、推理算力减少 34%;K=8 时算力进一步降低,但性能出现明显下滑,推测是现有模型尺寸不足以支撑更大语义带宽所致,而随着模型参数量增加,CALM 有望支持更大 K 值以提升性能 - 效率比。
效果
根据论文中后续的研究报告,CALM的研究在标准语言建模任务上的实验验证充分展现了其优势。

添加图片注释,不超过 140 字(可选)
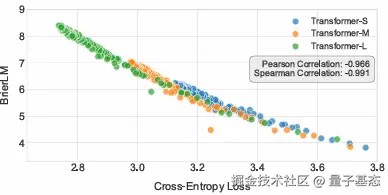
再WikiText-103数据集的测试中,CALM-M(371M 参数,K=4)的参数量略高于 Transformer-S,但训练与推理算力显著降低,性能仅轻微下降。随着参数量增加,CALM-L(735M)和 CALM-XL(1.82B)的性能反超传统 Transformer。

添加图片注释,不超过 140 字(可选)
在 K 值影响实验中,训练与推理 FLOPs 随 K 值增加呈线性下降,K=8 时算力仅为 K=1 时的 1/8,而 K=1 到 K=4 时性能下降幅度小于 5%,K=8 时下降幅度达 12%,验证了 K=4 的最优选择。鲁棒性测试中,当噪声方差为 0.3 时,CALM 的重构准确率仍保持 99.9%,生成文本的语法正确性与语义连贯性无明显下降,而传统模型在同等干扰下性能下降幅度超过 20%,印证了其潜空间的稳定性与抗干扰能力。