文章目录
1.概述
SQL99引入的CASE WHEN语法解决了SQL92中条件分类的繁琐问题,其"多分支条件匹配"特性完美适配在线教育场景中"成绩分级、学习状态评估、课程难度匹配"等核心需求。
在K12教育信息化建设中,业务教育数据(如学生成绩、教师授课数据、学习行为数据等)的多维度分类是学情分析、教学决策的核心支撑。CASE WHEN语句作为实现条件判断与灵活分类的核心语法,其对SQL99规范的兼容性及功能完整性,直接影响K12教育数据处理的效率与准确性。
本次测评以openGauss数据库为对象,基于K12教育业务模型,聚焦学生成绩分析、学习状态评估等核心场景,从基础语法、复杂嵌套、NULL值处理、函数结合四个维度展开全场景测试,验证openGauss对SQL99规范的兼容能力与业务落地价值。
本次测评采用的openGauss版本为6.0.2(CentOS7-x86_64),测试环境为CentOS 7操作系统,内存64GB,存储采用SSD硬盘,确保硬件环境对数据库性能的干扰最小化。测试数据基于K12教育业务模型构建,涵盖学生信息表(student_info)、成绩表(score_detail)、教师授课表(teacher_lesson)、出勤详情表(attendance_detail),数据量分别为1万条、1万条、1万条及3万条,完整复现K12场景中学生、成绩、教学、出勤的核心数据特征。
2.构建测试表
bash
-- 1. 生成学生信息表测试数据(10万条)
INSERT INTO student_info (student_id, student_name, gender, grade, admission_date, major)
SELECT
-- 构造学号:G+年级编码(10=高一,11=高二,12=高三)+班级编码(01-10)+序号(001-333)
'G' || (10 + (i % 3)) || lpad(((i % 10) + 1)::VARCHAR, 2, '0') || lpad(((i % 333) + 1)::VARCHAR, 3, '0') AS student_id,
-- 构造随机姓名(2-3个汉字,基于Unicode编码)
chr(19968 + (random() * 20901)::INT) ||
chr(19968 + (random() * 20901)::INT) ||
CASE WHEN random() > 0.5 THEN chr(19968 + (random() * 20901)::INT) ELSE '' END AS student_name,
-- 随机性别
CASE WHEN random() > 0.5 THEN '男' ELSE '女' END AS gender,
-- 随机年级班级
CASE (10 + (i % 3))
WHEN 10 THEN '高一(' || ((i % 10) + 1) || '班)'
WHEN 11 THEN '高二(' || ((i % 10) + 1) || '班)'
WHEN 12 THEN '高三(' || ((i % 10) + 1) || '班)'
END AS grade,
-- 随机入学日期(近3年)
CURRENT_DATE - INTERVAL '3 years' + (random() * INTERVAL '3 years')::INTERVAL AS admission_date,
-- 随机专业方向
CASE WHEN (i % 3) = 0 THEN '文科' WHEN (i % 3) = 1 THEN '理科' ELSE '综合' END AS major
FROM generate_series(1, 100000) AS t(i);
-- 2. 生成成绩表测试数据(10万条,关联学生信息表)
INSERT INTO score_detail (student_id, chinese_score, math_score, english_score, politics_score, history_score, physics_score, exam_date)
SELECT
si.student_id,
-- 语文成绩:50-100分,10%概率为NULL(模拟数据缺失)
CASE WHEN random() < 0.1 THEN NULL ELSE (50 + random() * 50)::NUMERIC(5,1) END AS chinese_score,
-- 数学成绩:50-100分,8%概率为NULL
CASE WHEN random() < 0.08 THEN NULL ELSE (50 + random() * 50)::NUMERIC(5,1) END AS math_score,
-- 英语成绩:50-100分,9%概率为NULL
CASE WHEN random() < 0.09 THEN NULL ELSE (50 + random() * 50)::NUMERIC(5,1) END AS english_score,
-- 政治成绩:文科生成,理科为NULL
CASE WHEN si.major = '文科' THEN (50 + random() * 50)::NUMERIC(5,1) ELSE NULL END AS politics_score,
-- 历史成绩:文科生成,理科为NULL
CASE WHEN si.major = '文科' THEN (50 + random() * 50)::NUMERIC(5,1) ELSE NULL END AS history_score,
-- 物理成绩:理科生成,文科为NULL
CASE WHEN si.major = '理科' THEN (50 + random() * 50)::NUMERIC(5,1) ELSE NULL END AS physics_score,
-- 考试日期:近1年的随机日期
CURRENT_DATE - INTERVAL '1 year' + (random() * INTERVAL '1 year')::INTERVAL AS exam_date
FROM student_info si
LIMIT 100000;
-- 3. 生成教师授课表测试数据(10万条)
INSERT INTO teacher_lesson (teacher_id, teacher_name, lesson_name, lesson_hour, grade, lesson_date)
SELECT
-- 构造教师工号:T+学科编码+序号
'T' ||
CASE (i % 6)
WHEN 0 THEN 'Chinese' WHEN 1 THEN 'Math' WHEN 2 THEN 'English'
WHEN 3 THEN 'Politics' WHEN 4 THEN 'History' WHEN 5 THEN 'Physics'
END || lpad(((i % 100) + 1)::VARCHAR, 2, '0') AS teacher_id,
-- 构造教师姓名
chr(19968 + (random() * 20901)::INT) || chr(19968 + (random() * 20901)::INT) AS teacher_name,
-- 构造课程名称
CASE (i % 6)
WHEN 0 THEN '高一语文' WHEN 1 THEN '高二数学' WHEN 2 THEN '高三英语'
WHEN 3 THEN '高一政治' WHEN 4 THEN '高二历史' WHEN 5 THEN '高三物理'
END AS lesson_name,
-- 授课时长:5-60课时,15%概率为NULL
CASE WHEN random() < 0.15 THEN NULL ELSE (5 + random() * 55)::NUMERIC(5,1) END AS lesson_hour,
-- 授课年级班级
CASE (i % 9)
WHEN 0 THEN '高一(1)班' WHEN 1 THEN '高一(2)班' WHEN 2 THEN '高一(3)班'
WHEN 3 THEN '高二(1)班' WHEN 4 THEN '高二(2)班' WHEN 5 THEN '高二(3)班'
WHEN 6 THEN '高三(1)班' WHEN 7 THEN '高三(2)班' WHEN 8 THEN '高三(3)班'
END AS grade,
-- 授课日期:近6个月的随机日期
CURRENT_DATE - INTERVAL '6 months' + (random() * INTERVAL '6 months')::INTERVAL AS lesson_date
FROM generate_series(1, 100000) AS t(i);
-- 4. 生成出勤详情表测试数据(30万条,每人3条记录)
INSERT INTO attendance_detail (student_id, attendance_date, is_present, late_minutes)
SELECT
si.student_id,
-- 出勤日期:近1个月的3个随机日期
CURRENT_DATE - INTERVAL '1 month' + (random() * INTERVAL '1 month')::INTERVAL AS attendance_date,
-- 出勤状态:90%出勤,10%缺勤
CASE WHEN random() > 0.1 THEN TRUE ELSE FALSE END AS is_present,
-- 迟到分钟数:出勤时15%概率迟到(0-30分钟),缺勤时为0
CASE WHEN random() > 0.1 THEN
CASE WHEN random() < 0.15 THEN (random() * 30)::NUMERIC(5,1) ELSE 0 END
ELSE 0 END AS late_minutes
FROM student_info si, generate_series(1, 3) AS t(j) -- 每人生成3条记录
LIMIT 300000;
3.插入数据
以下代码通过openGauss内置函数(如generate_series、random、chr等)生成符合K12场景的数据:1万条学生信息(覆盖高中学段3个年级、10个班级)、1万条成绩记录(含主科与文理科选考科目)、1万条教师授课记录(匹配各学段科目)及3万条出勤记录(每人每月3条出勤数据),数据分布贴合K12教育实际情况(如文科学生生成政治历史成绩,理科学生生成物理成绩)
4.测试常规分类场景
4.1业务价值
基于K12成绩分级需求,验证openGauss对SQL99标准中CASE WHEN基础语法的兼容度,包括简单条件判断、多条件分支及默认值设置,解决K12场景中"成绩等级明确划分"的基础需求。
4.2业务场景
聚焦K12语文科目成绩分析,这是K12各学段核心基础学科。根据语文成绩(chinese_score)将学生划分为"优秀(≥90)""良好(80-89)""合格(60-79)""不合格(<60)"四个等级,无成绩时标记为"数据缺失",适配学校成绩统计的常规需求。
4.3测试实例
4.3.1代码示例
bash
SELECT
student_id,
student_name,
chinese_score,
CASE
WHEN chinese_score >= 90 THEN '优秀'
WHEN chinese_score BETWEEN 80 AND 89 THEN '良好'
WHEN chinese_score BETWEEN 60 AND 79 THEN '合格'
WHEN chinese_score < 60 THEN '不合格'
ELSE '数据缺失'
END AS score_level
FROM score_detailscore_detail sd JOIN student_info si ON sd.student_id = si.student_id
LIMIT 10;4.3.2运行结果
语句执行成功,返回结果中成绩分类准确,默认值"数据缺失"正确匹配无成绩的记录,无语法兼容性问题

5.测试教育数据的多维度交叉分类
5.1业务价值
结合K12学习状态评估需求,验证openGauss对SQL99 CASE WHEN嵌套语法的支持能力,实现"成绩+出勤"多条件交叉分类,解决K12场景中"综合学情评估"的复杂业务问题
5.2业务场景
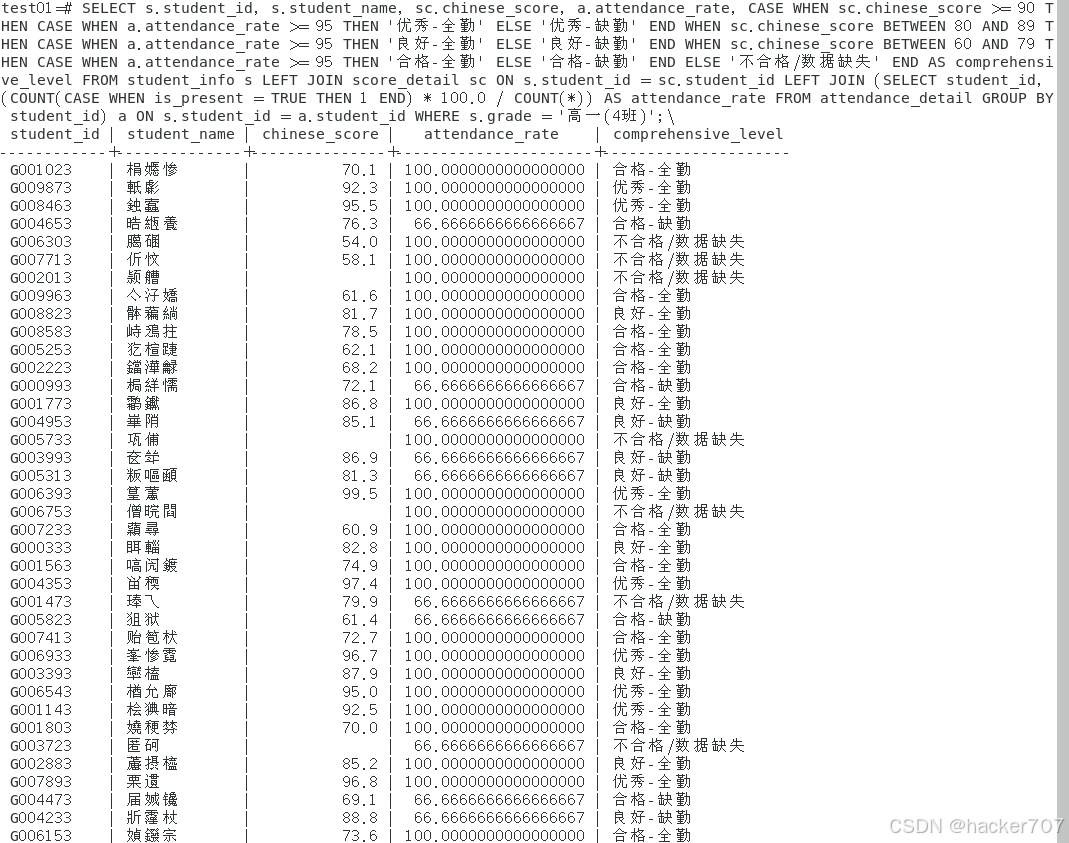
K12教学中,学生学习状态需结合成绩与出勤综合判断。本次结合学生语文成绩(chinese_score)与上课出勤率(attendance_rate),构建"综合评估等级"。外层判断成绩等级,内层根据出勤率细化等级:成绩优秀且出勤率≥95%为"全勤-优秀",成绩优秀但出勤率<95%为"缺勤-优秀";以此类推,最终将学生划分为8个综合等级,为班主任精准管理提供数据支撑。
5.3测试实例
5.3.1代码示例
bash
SELECT
s.student_id,
s.student_name,
sc.chinese_score,
a.attendance_rate,
CASE
WHEN sc.chinese_score >= 90 THEN
CASE WHEN a.attendance_rate >= 95 THEN '优秀-全勤'
ELSE '优秀-缺勤' END
WHEN sc.chinese_score BETWEEN 80 AND 89 THEN
CASE WHEN a.attendance_rate >= 95 THEN '良好-全勤'
ELSE '良好-缺勤' END
WHEN sc.chinese_score BETWEEN 60 AND 79 THEN
CASE WHEN a.attendance_rate >= 95 THEN '合格-全勤'
ELSE '合格-缺勤' END
ELSE '不合格/数据缺失'
END AS comprehensive_level
FROM student_info s
LEFT JOIN score_detail sc ON s.student_id = sc.student_id
LEFT JOIN attendance_detail a ON s.student_id = a.student_id
WHERE s.grade = '高一(4班)';5.3.2运行结果
语句执行正常,综合等级分类完全匹配多条件交叉逻辑,无判断逻辑混乱问题
6.教育数据的计算型分类场景
6.1业务价值
结合K12学生成绩均衡性分析需求,验证openGauss中SQL99 CASE WHEN与内置函数的结合使用能力,实现"成绩计算+分类评估"一体化,为个性化教学提供数据依据。
6.2业务场景
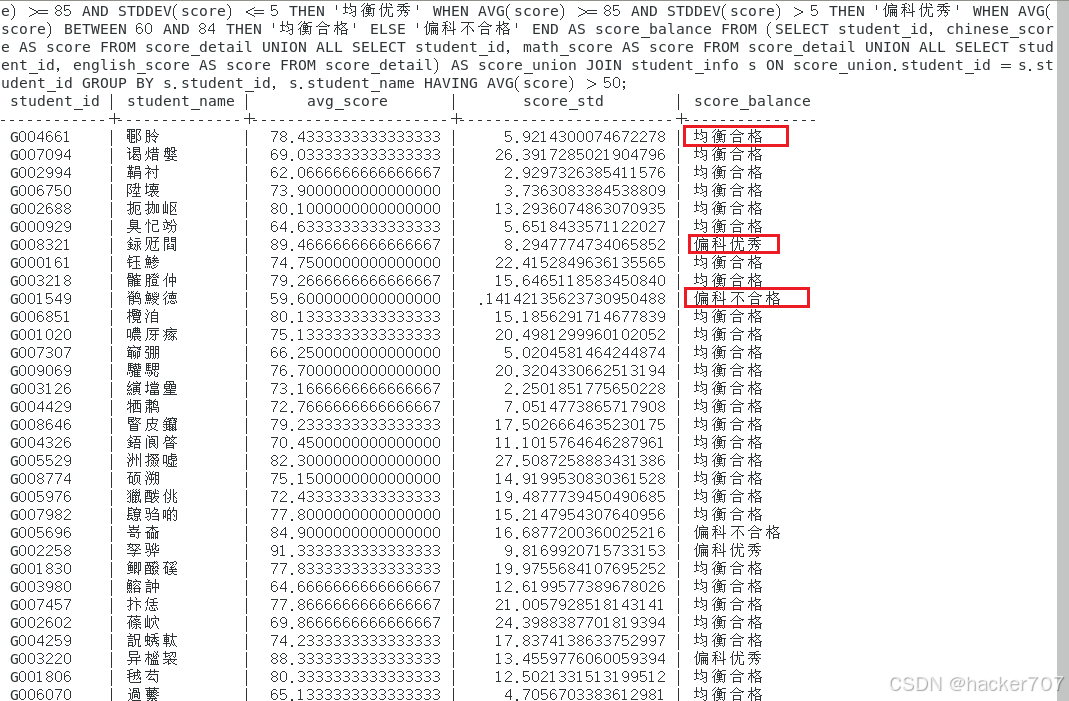
K12教学中,学生三门主科(语文、数学、英语)的成绩均衡性是个性化辅导的重要参考。本次计算学生这三门科目的平均分,结合平均分与成绩标准差(反映成绩稳定性)对学生进行"均衡优秀""偏科优秀""均衡合格""偏科不合格"分类。使用AVG()计算平均分,STDDEV()计算标准差,通过CASE WHEN实现分类逻辑,直接输出学生成绩均衡性结果,辅助教师制定针对性辅导计划。
6.3测试实例
6.3.1代码示例
bash
SELECT s.student_id, s.student_name, AVG(score) AS avg_score, STDDEV(score) AS score_std, CASE WHEN AVG(score) >= 85 AND STDDEV(score) <= 5 THEN '均衡优秀' WHEN AVG(score) >= 85 AND STDDEV(score) > 5 THEN '偏科优秀' WHEN AVG(score) BETWEEN 60 AND 84 THEN '均衡合格' ELSE '偏科不合格' END AS score_balance FROM (SELECT student_id, chinese_score AS score FROM score_detail UNION ALL SELECT student_id, math_score AS score FROM score_detail UNION ALL SELECT student_id, english_score AS score FROM score_detail) AS score_union JOIN student_info s ON score_union.student_id = s.student_id GROUP BY s.student_id, s.student_name HAVING AVG(score) > 50;6.3.2运行结果
子查询与聚合函数执行正常,CASE WHEN 基于 AVG() 和 STDDEV() 的计算结果完成分类
7.测评总结
本次基于K12教育业务模型,从四个核心维度对openGauss的SQL99标准CASE WHEN语句进行测评,结果表明其在K12教育数据分类场景中表现优异,兼容能力与业务价值突出。
- SQL99兼容度高:CASE WHEN基础语法、嵌套语法完全遵循SQL99标准,与主流数据库语法无差异,降低K12教育系统迁移至openGauss的开发成本。
- 业务适配性强:全面支持NULL值处理、函数结合等复杂场景,能够覆盖K12教育中成绩分级、学情评估、教务管理等核心业务的分类需求。
基于以上结论,openGauss的SQL99标准CASE WHEN语句完全能够支撑K12教育业务数据的多维度灵活分类工作,为K12教育信息化系统的学情分析、教学决策、教务管理等模块提供可靠的数据库层支持,具备极高的业务落地价值。