Qwen3-Max
Reference: (55 封私信) 深入解析U-Net:图像分割的经典架构与应用 - 知乎
当然可以!U-Net 是一种经典的深度学习神经网络架构 ,最初为医学图像分割而设计,后来被广泛应用于图像生成、去噪、超分辨率等任务------尤其在 Stable Diffusion 等扩散模型中扮演核心角色。
下面我们用通俗语言 + 图解思维 + 实例来解释:
一、U-Net 是什么?名字从哪来?
- 名字来源 :因为它的结构图看起来像字母 "U"。
- 提出时间:2015 年由 Olaf Ronneberger 等人在论文《U-Net: Convolutional Networks for Biomedical Image Segmentation》中首次提出。
- 原始用途 :给显微镜下的细胞图像做像素级分割(比如标出每个细胞的边界)。
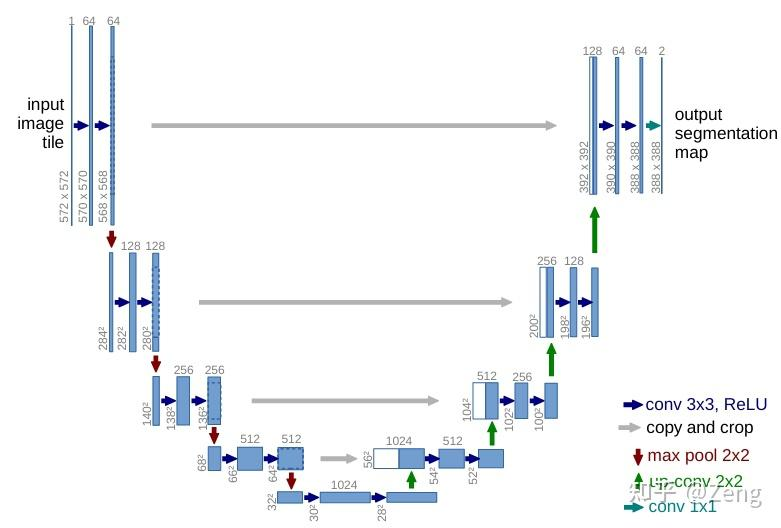
二、U-Net 的核心结构(以图像为例)
这个地方和参考部分冲突,比如:请参考 Reference: (55 封私信) 深入解析U-Net:图像分割的经典架构与应用 - 知乎
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| #### 3.1 整体架构概览 UNet的名称来源于其U型的网络结构,整体可以分为三个主要部分: 1. 收缩路径(Contracting Path):也称为编码器(Encoder) 2. 瓶颈层(Bottleneck):连接编码器和解码器 3. 扩张路径(Expansive Path):也称为解码器(Decoder) |
想象你要处理一张 256×256 的图片,U-Net 分为两部分:
📌 1. 编码器(Encoder)------"下采样路径"
-
目标:提取高层次语义特征(比如"这是一个人脸"、"有眼睛鼻子")
-
方法:不断用卷积(Conv)+ 池化(Pooling)缩小图像尺寸,同时增加通道数
-
示例流程:
输入 (256×256×3) ↓ Conv + ReLU → Pooling 特征图 (128×128×64) ↓ Conv + ReLU → Pooling 特征图 (64×64×128) ↓ ... 最底层 (16×16×512) ← 这里包含全局语义信息
📌 2. 解码器(Decoder)------"上采样路径"
-
目标:恢复空间细节(比如"眼睛在左上角,边缘要清晰")
-
方法:用反卷积(或插值)逐步放大图像,同时融合编码器对应层的特征 (叫 skip connection)
-
示例流程:
底层 (16×16×512) ↑ Upsample → Concat(来自编码器的 32×32 特征) → Conv (32×32×256) ↑ Upsample → Concat(来自编码器的 64×64 特征) → Conv (64×64×128) ↑ ... 输出 (256×256×1) ← 每个像素都有预测标签(如"细胞"或"背景")
✨ 关键创新:Skip Connections(跳跃连接)
- 把编码器每一层的高分辨率细节直接传给解码器对应层
- 解决了传统编码-解码结构丢失细节的问题
- 正是这个设计,让 U-Net 在需要精确定位的任务中表现极佳
三、举个生活化例子 🌰
想象你在画一幅精细的建筑草图:
- 编码器 = 你先退后几步,眯着眼看整体:"哦,这是一座带塔楼的教堂。"(抓大放小)
- 解码器 = 你走近画板,开始细化:"塔楼在左边,窗户是拱形的......"
- Skip Connection = 你一边画,一边不断回头看原建筑的照片,确保窗户位置、砖块纹理不画错。
没有 skip connection,你可能记得"是教堂",但把门画到屋顶上 😅
四、U-Net 在 Stable Diffusion 中的作用
在 Stable Diffusion 中,U-Net 不是用来分割图像 ,而是作为去噪网络(Denoising Network):
🎯 任务:给一个带噪声的潜在图像(latent),预测噪声是多少
- 输入:带噪 latent + 时间步 t + 文本条件(text embedding)
- 输出:预测的噪声
- 训练目标:让预测噪声 ≈ 真实添加的噪声
🔁 为什么用 U-Net?
- 它既能理解全局语义(通过深层编码),又能保留局部结构(通过 skip connection)
- 非常适合"从模糊到清晰"的渐进去噪过程
💡 注意:Stable Diffusion 的 U-Net 没有最终的输出卷积层生成图像,而是输出与输入 latent 同尺寸的"噪声残差"。
五、U-Net vs 其他架构
| 架构 | 特点 | 适用场景 |
|---|---|---|
| U-Net | 编码-解码 + skip connection | 图像分割、扩散去噪、医学影像 |
| ResNet | 残差连接,深层分类 | 图像分类、特征提取 |
| Transformer | 全局注意力机制 | NLP、ViT 图像分类、DiT 生成 |
| GAN Generator | 通常用转置卷积上采样 | 对抗生成(如 StyleGAN) |
六、可视化示意(文字版)
Input Image
│
[Conv → ReLU → Pool] ← Encoder
│
[Conv → ReLU → Pool]
│
Bottleneck (最深)
│
[Upsample → Concat(skip) → Conv] ← Decoder
│
[Upsample → Concat(skip) → Conv]
│
Output Mask / Denoised Latent✅ 总结
- U-Net 是一种"U形"编码-解码网络 ,靠 skip connection 保留细节。
- 最初用于医学图像分割,现在广泛用于生成模型(如 Stable Diffusion 的核心去噪模块)。
- 在 SD 中,U-Net 接收带噪 latent 和文本提示,预测噪声,反复迭代得到干净 latent。
- 它不是大模型本身,但却是大模型(如 SD)能高效高质量生成的关键组件。