从理论到实践:在微控制器上部署TinyML,
让嵌入式设备拥有"大脑"
曾几何时,人工智能还是云端服务器的专属,需要庞大的算力和能耗支撑。而今,随着TinyML(Tiny Machine Learning)技术的兴起,我们得以将机器学习模型"注入"到资源极度受限的微控制器中,让终端设备真正拥有本地、实时的智能。本文将带你深入探索,如何一步步在一个普通的STM32微控制器上,部署一个能识别加速度计手势的TinyML模型,开启嵌入式智能化的实战之旅。
一、 缘起:为何是TinyML?嵌入式智能的必然演进
在传统的物联网架构中,嵌入式终端设备主要负责数据采集,然后通过无线网络将海量数据上传至云端进行处理和推理。这种模式面临着几个核心痛点:
-
高延迟:数据在云端的往返通信无法满足工业控制、自动驾驶等需要毫秒级响应的实时应用。
-
网络依赖:在信号不佳或断网环境下,设备功能将直接失效。
-
隐私与安全:所有原始数据上传云端,存在隐私泄露和数据安全风险。
-
功耗与带宽:持续传输数据(尤其是视频、音频等高维数据)会急剧消耗设备电量并占用大量网络带宽。
TinyML的出现,正是为了解决这些痛点。 它的核心理念是:将机器学习模型的推理(Inference)过程,直接放在资源极其有限的终端微控制器上运行。 这意味着:
-
极致低功耗:MCU本身的功耗可低至毫瓦甚至微瓦级别,一次推理所消耗的能量远低于一次无线数据传输。
-
实时响应:数据在本地处理,推理结果可在毫秒内输出,满足硬实时要求。
-
隐私保护:原始数据无需离开设备,仅在本地处理并输出结果(如"手势A"、"异常状态"等抽象指令)。
-
网络解脱:设备可以脱离网络独立运行,大大扩展了应用场景。
其应用场景无限广阔:唤醒词检测、视觉唤醒、异常振动检测、手势识别、关键字 spotting 等等。可以说,TinyML正为嵌入式系统装上了一个能够感知和理解环境的"边缘大脑"。
二、 核心挑战:在"螺蛳壳里做道场"
在MCU上部署ML模型,本质上是在"螺蛳壳里做道场",我们面临着一系列严峻的资源约束:
-
内存(RAM):通常只有几十到几百KB。模型权重和中间层的激活值都必须能放进这片狭小的空间。
-
存储(Flash):通常只有几百KB到几MB。整个模型(包括权重和推理代码)必须被存储于此。
-
算力(CPU):主频通常在几十到几百MHz,没有专用的GPU或NPU。
面对这些挑战,一个完整的TinyML项目流程并非简单的"训练-部署",而是一个充满优化与权衡的工程闭环。其典型流程如下图所示:
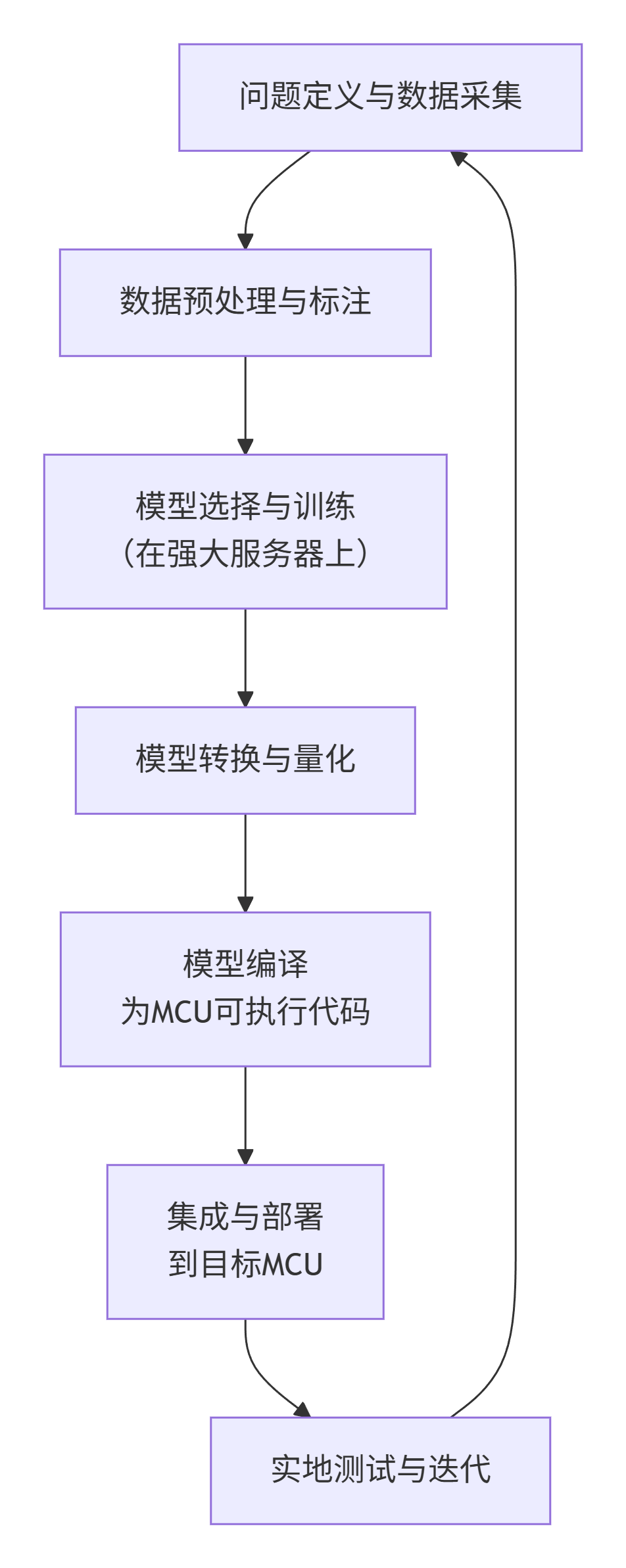
三、 实战演练:构建一个STM32手势识别系统
接下来,我们以"基于STM32和MPU6050加速度计的手势识别"为例,完整复盘这个过程。
1. 问题定义与硬件选型
-
目标:让设备能够识别用户划出的特定手势(例如"上勾拳"、"下切"、"左挥"、"右挥")。
-
核心MCU:STM32F411RE(Cortex-M4内核,128KB Flash,512KB RAM),性能足以应对简单的TinyML模型。
-
传感器:MPU6050(三轴加速度计+陀螺仪),用于捕获手势运动数据。
2. 数据采集------模型的"食粮"
数据是模型的基石,这一步至关重要。
-
搭建数据采集固件:编写STM32程序,以100Hz的频率从MPU6050读取三轴加速度计数据,并通过串口实时发送到PC。
-
录制数据:使用一个简单的Python脚本接收并保存串口数据。为每个手势(例如"上勾拳")录制100组数据,每组持续约1-2秒。同时,录制一些"未知"或"无手势"的数据作为负样本。
-
数据格式 :每一行数据包含一个时间戳和ax, ay, az三个加速度值。每个数据文件以手势标签命名(如
punch_up_01.csv)。
关键技巧:数据采集时要考虑不同用户、不同速度、不同方向的变化,以增强模型的鲁棒性。
3. 模型训练------在云端"炼钢"
我们使用Google的TensorFlow和TensorFlow Lite for Microcontrollers生态来完成这一步。
-
数据预处理:
-
滑动窗口:由于一个手势跨越多个时间点,我们采用一个固定长度(如128个数据点,即1.28秒)的滑动窗口来截取一个完整的手势样本。
-
标准化:将加速度数据减去均值,除以标准差,使其分布更利于模型收敛。
-
-
模型设计与训练:
-
这是一个典型的时序序列分类问题。我们选择一个简单的一维卷积神经网络。
-
模型结构示例:
pythonpython model = tf.keras.Sequential([ tf.keras.layers.Conv1D(8, 3, activation='relu', input_shape=(128, 3)), # 输入:128个时间点,3个轴 tf.keras.layers.MaxPooling1D(2), tf.keras.layers.Conv1D(16, 3, activation='relu'), tf.keras.layers.MaxPooling1D(2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(32, activation='relu'), tf.keras.layers.Dense(4, activation='softmax') # 输出:4个手势类别的概率 ]) -
在PC上使用Keras进行训练和评估,直到在测试集上达到满意的准确率(如>95%)。
-
4. 模型量化与转换------模型的"瘦身术"
这是通往MCU的关键一步。量化能将32位浮点权重转换为8位整数,模型大小通常能减少75%,并且推理速度更快。
python
python
# 创建一个TFLite转换器
converter = tf.lite.TFLiteConverter.from_keras_model(model)
# 启用默认的int8量化
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# 提供代表性的数据集以校准量化参数
converter.representative_dataset = representative_dataset_gen
# 确保所有操作都有int8实现
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
# 设置输入输出类型为int8(推理时需在MCU端做对应转换)
converter.inference_input_type = tf.int8
converter.inference_output_type = tf.int8
tflite_model = converter.convert()
# 保存量化后的模型
open('gesture_model_int8.tflite', 'wb').write(tflite_model)5. 集成与部署------在MCU上"安家"
-
获取TensorFlow Lite Micro库 :将其作为一组
.c和.h文件集成到你的STM32 HAL项目中(例如使用STM32CubeIDE)。 -
集成模型 :使用
xxd -i命令将.tflite模型文件转换为一个C语言头文件(一个const unsigned char数组),并将其链接到固件中。 -
编写推理代码:
-
创建解释器:调用TFLite Micro的API,加载模型到内存,并分配张量(tensors)。
-
预处理输入:从MPU6050读取最新的128个数据点,进行相同的标准化处理,并量化为int8类型,填充到输入张量。
-
调用推理 :
interpreter->Invoke(); -
解析输出:从输出张量中获取4个类别的int8分数,将其反量化为近似概率,最高分对应的类别即为识别结果。
-
核心代码片段示意:
python
c
// 伪代码逻辑
static tflite::MicroInterpreter* interpreter = nullptr;
void setup() {
// ... 硬件初始化
// 映射模型
const tflite::Model* model = tflite::GetModel(gesture_model_tflite);
// 构建解释器,使用预定义的TensorArena(一片静态内存区域)
static uint8_t tensor_arena[kTensorArenaSize];
interpreter = new tflite::MicroInterpreter(...);
interpreter->AllocateTensors();
}
void loop() {
// 1. 填充输入数据到input_tensor->data.int8
fill_input_buffer_from_sensor(input_tensor->data.int8);
// 2. 推理
TfLiteStatus invoke_status = interpreter->Invoke();
if (invoke_status != kTfLiteOk) { /* error handling */ }
// 3. 获取输出
TfLiteTensor* output_tensor = interpreter->output(0);
int8_t* output_scores = output_tensor->data.int8;
// 4. 后处理:找到最大得分索引
int gesture_id = argmax(output_scores, 4);
printf("Recognized Gesture: %d\n", gesture_id);
}四、 优化心法与挑战剖析
部署成功只是第一步,性能优化才是嵌入式开发的精髓。
-
内存管理 :
kTensorArenaSize的大小需要反复试验。它需要容纳模型、输入输出张量和中间激活值。太大浪费空间,太小导致AllocateTensors()失败。 -
精度与速度的权衡:量化会带来轻微的精度损失。如果损失不可接受,可以考虑混合量化或选择支持FP16的MCU。同时,可以调整模型结构(如减少层数、滤波器数量)来换取更小的体积和更快的速度。
-
功耗实测:在连续推理和间歇唤醒两种模式下,使用电流表实测系统功耗。你会发现,采用"采集数据时唤醒MCU至高频,推理完成后进入STOP模式"的策略,能极大地降低平均功耗。
五、 未来展望与结语
TinyML的生态正在飞速发展。未来,我们将看到:
-
更强大的MCU:内置NPU的微控制器将变得普及。
-
自动化工具链:如Google的TensorFlow Lite Model Maker,可以进一步降低开发门槛。
-
在线学习:在设备端进行增量学习,让模型能够适应环境和用户的个性化变化。
回首这次探索,我们从数据采集、模型训练,到量化、转换,最终在资源拮据的STM32上成功部署了一个智能手势识别模型。这个过程,完美诠释了嵌入式开发者如何在一个"寸土寸金"的系统里,通过极致的优化和对硬件、软件的深刻理解,将前沿的AI算法转化为稳定、高效、低功耗的嵌入式智能。
这,正是嵌入式技术的魅力所在------于方寸之间,显无限神通。希望本文能成为你踏入TinyML世界的一块敲门砖,期待看到你在嵌入式智能领域的精彩创造!