作者:来自 Elastic Alexander Wert

本文探讨了 OpenTelemetry 数据质量的 Instrumentation Score,分享了实用见解、关键经验,并通过 Elastic 强大的可观测性功能,提供了实践操作的实现方法。
OpenTelemetry 的采用率正在快速上升,越来越多的公司依赖 OpenTelemetry 来收集可观测性数据。虽然 OpenTelemetry 提供了清晰的规范和语义约定来指导遥测数据收集,但它也带来了显著的灵活性。高灵活性意味着高责任 ------ 基于 OTel 的数据收集容易出现问题,导致中等或低质量的遥测数据。低质量数据会阻碍后端分析、混淆用户并降低系统性能。为了从 OpenTelemetry 数据中获取可操作的洞察,保持高数据质量至关重要。Instrumentation Score 项目通过提供一种标准化方法来衡量 OpenTelemetry 数据质量,解决了这一挑战。尽管规范和工具仍在发展中,但其基本概念已经非常有吸引力。在本文中,我将分享我在实验 Instrumentation Score 概念中的经验,并演示如何利用 Elastic Stack ------ 使用 ES|QL、Kibana Task Manager 和 Dashboards ------ 在 Elastic Observability 内基于该方法构建数据质量分析 POC。
Instrumentation Score ------ 基于规则的数据质量分析的力量
当你第一次听到 "Instrumentation Score" 这个词时,你可能会想:"好吧,这是一个类似百分比的指标,说我的仪器(即 OTel 数据)得分 60/100。那又怎样?它能帮我做什么?"
然而,Instrumentation Score 不仅仅是一个数字。它的核心力量在于构成该分数的各条规则。规则定义的原理、影响等级和判定标准提供了一个评估框架,使你能够深入分析数据质量问题,并识别具体需要改进的领域。同时,Instrumentation Score 规范并未强制要求计算分数和规则评估使用特定工具或实现细节。
在探索 Instrumentation Score 概念的过程中,我建立了以下思维模型,用于推导可操作的洞察。
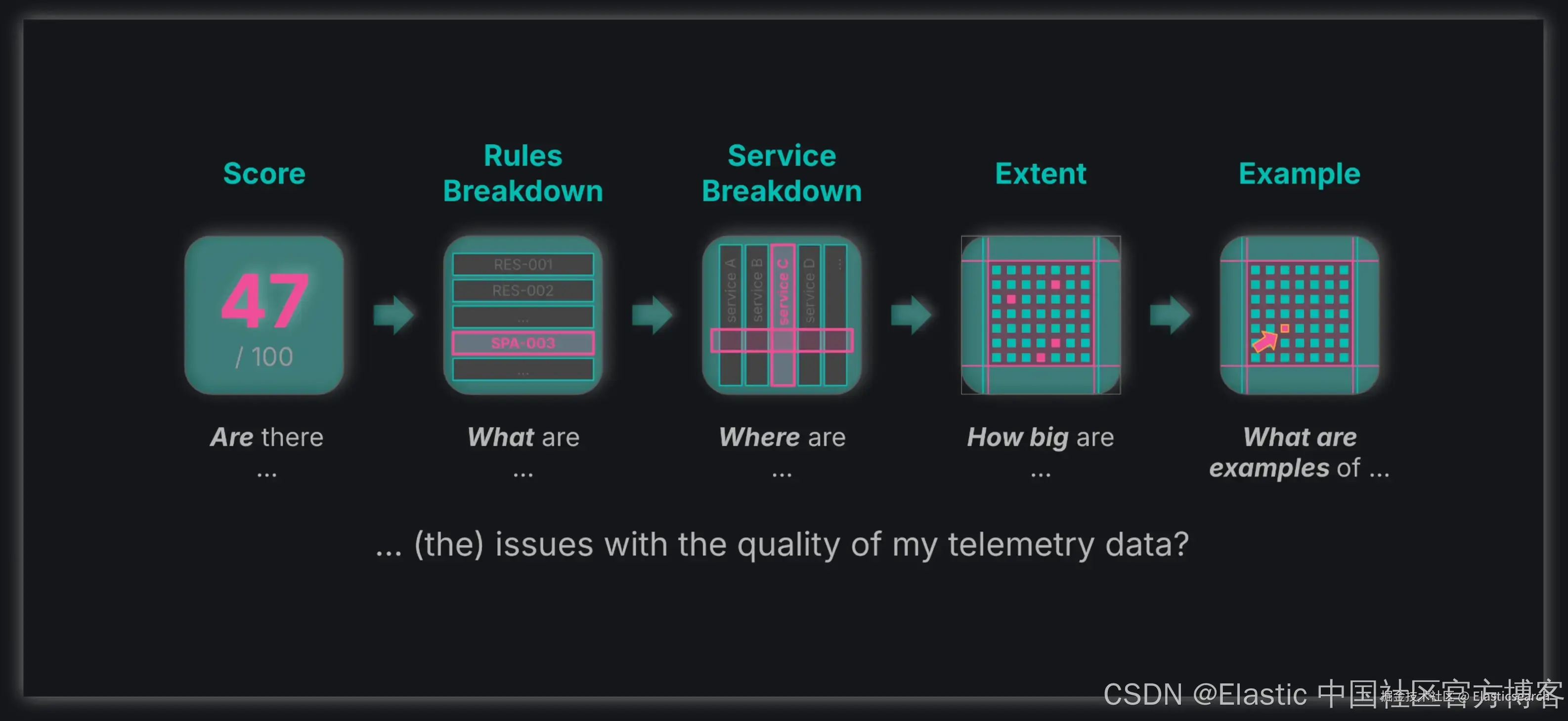
分数
分数本身是你遥测数据质量的指标。分数越低,数据质量改进的空间越大。通常,如果分数低于 75,你应考虑修复你的仪器和数据收集流程。
按 Instrumentation Score 规则的分解
查看各条 Instrumentation Score 规则的评估结果,可以让你洞察数据质量存在的问题。此外,规则的原理解释了违反该规则为什么会成为问题。
例如,我们来看 SPA-002 规则:
描述:
追踪中不应包含孤立的 span(orphan spans)。
原理:
孤立的 span 表明追踪仪器或数据完整性可能存在问题。这可能导致追踪数据不完整或误导,从而阻碍有效的故障排查和性能分析。
如果你的数据违反了 SPA-002 规则,你就知道问题出在哪里(即追踪存在断裂),规则原理也解释了为什么这是个问题(即分析能力受限)。
按服务分解
当你的系统很大,拥有数百甚至数千个实体(如服务、Kubernetes pods 等)时,仅仅用一个二进制信号 ------ 比如 "某条规则是否通过" ------ 并不真正可操作。是所有服务的数据都违反了某条规则,还是只有少部分服务?
按服务(或其他实体类型)分解规则评估,可以帮助你识别数据质量问题的具体位置。例如,假设只有一个服务 ------ cart-service ------(在你的五十个服务中)违反了 SPA-002 规则。有了这些信息,你可以集中修复 cart-service 的检测,而无需检查所有五十个服务。
一旦你知道哪些服务(或其他实体)违反了哪些 Instrumentation Score 规则,你就非常接近可操作的洞察了。然而,在我实验 Instrumentation Score 评估时,我发现有两点对于数据质量分析特别有用:(1)规则违规的量化指标,和(2)数据中具体的规则违规示例。
量化规则违规范围
Instrumentation Score 规范已经为每条规则定义了影响等级(如 NORMAL、IMPORTANT、CRITICAL)。但这仅涵盖规则本身的重要性,而不是违规的范围。例如,如果你的服务中一百万条追踪中只有一条存在孤立 span,从技术上讲,SPA-002 规则被违反了。但如果只有百万分之一的追踪受影响,这真的算是问题吗?可能并不算。但如果有一半追踪出现断裂,那就绝对是问题。
因此,为每个服务提供规则违规的量化指标 ------ 例如 "40% 的追踪违反了 SPA-002" ------ 可以提供额外信息,说明规则违规的严重程度。
具体示例
最后,没有什么比来自自己数据的具体、直观示例更有意义和解释力。如果 cart-service 的遥测数据违反了 SPA-002(即存在孤立 span),你是否希望看到该服务的一条具体追踪示例来展示违规情况?分析具体示例可以帮助你找到断裂追踪的根本原因 ------ 或者更广泛地,理解为什么你的数据违反了 Instrumentation Score 规则。
使用 Elastic 实现 Instrumentation Score
Instrumentation Score 规范并未规定计算分数或评估规则的工具使用或实现细节。这意味着你可以将 Instrumentation Score 概念与 OpenTelemetry 数据发送到的任何后端集成。
为了构建一个将 Instrumentation Score 与 Elastic Observability 端到端集成的 POC,我结合了 ES|QL 的强大功能,以及 Kibana 的任务管理器和仪表板功能。
每条 Instrumentation Score 规则都可以被表达为一个 ES|QL 查询,覆盖以下步骤:
-
规则是否通过
-
按服务分解
-
违规程度的计算
-
抽样具体违规示例
下面是一个检查 severity_number 字段有效性的 LOG-002 规则示例查询:
ini
`
1. FROM logs-*.otel-* METADATA _id
2. | WHERE data_stream.type == "logs"
3. AND @timestamp > NOW() - 1h
4. | EVAL no_sev = severity_number IS NULL OR severity_number == 0
5. | STATS
6. logs_wo_severity = COUNT(*) WHERE no_sev,
7. example = SAMPLE(_id, 1) WHERE no_sev,
8. total = COUNT(*)
9. BY service.name
10. | EVAL rule_passed = (logs_wo_severity == 0),
11. extent = CASE(total != 0, logs_wo_severity / total, 0.0)
12. | KEEP rule_passed, service.name, example, extent
`AI写代码这些规则评估查询被封装在一个 Kibana instrumentation-score 插件中,该插件利用任务管理器定期执行。然后,instrumentation-score 插件会将所有不同规则的评估查询结果汇总,根据 Instrumentation Score 规范的计算公式计算最终的 Instrumentation Score 值(整体和按服务分解)。生成的 Instrumentation Score 值,以及规则评估结果(含示例和违规程度)会被存储在单独的 Elasticsearch 索引中以供使用。
将结果存储在专用 Elasticsearch 索引后,我们可以构建仪表板来可视化 Instrumentation Score 洞察,并让用户排查数据质量问题。
在这个 POC 中,我实现了部分 Instrumentation Score 规则,以验证这种方法。
Instrumentation Score 概念允许扩展自定义规则。我在 POC 中也这样做了,用来测试一些尚未被正式定义为 Instrumentation Score 规范规则的质量规则,但这些规则对 Elastic Observability 来说很重要,可以让 OTel 数据发挥最大价值。
在 OpenTelemetry Demo 上应用 Instrumentation Score
OpenTelemetry Demo 是最常用的环境,用于试玩和展示 OpenTelemetry 的功能。最初,我认为这个 demo 是测试 Instrumentation Score 实现的最糟糕环境。毕竟,它是 OpenTelemetry 的展示环境,我预期它的 Instrumentation Score 接近 100。令人惊讶的是,情况并非如此。
概览
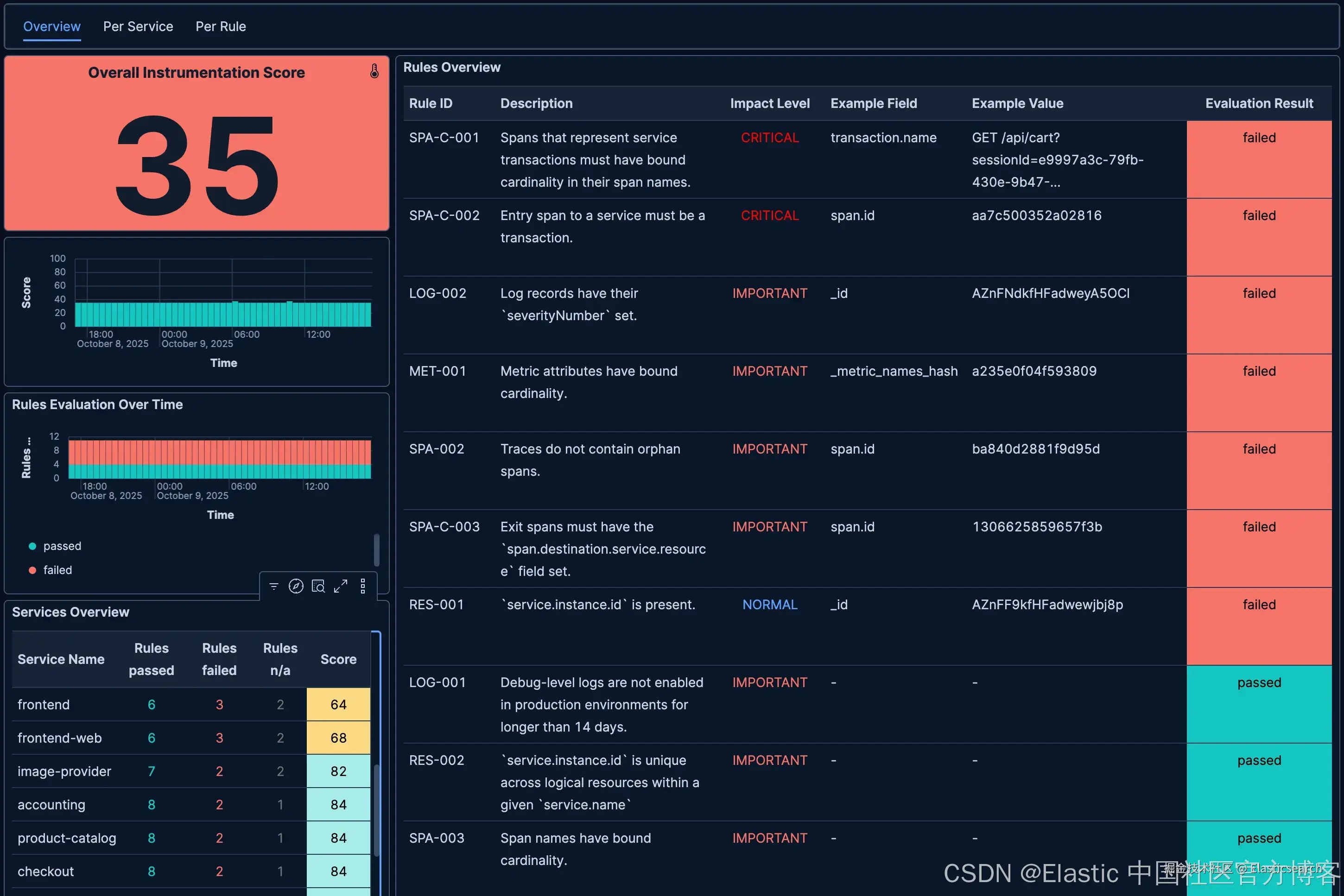
这个仪表板展示了 OpenTelemetry Demo 环境的 Instrumentation Score 结果概览。你可能首先注意到的是非常低的整体得分 35(左上角)。左下角的表格显示了按服务分解的得分。有点令人意外的是,所有服务的得分都高于整体得分。这怎么可能?
主要原因在于,Instrumentation Score 规则本身是二元结果 ------ 通过或未通过。所以可能每个服务只未通过一条不同的规则。因此,服务得分并不完美,但也不是很差。但从整体角度来看,许多规则都未通过(每条规则由不同服务未通过),因此整体得分非常低。
右侧表格显示了各个规则的结果,包括描述、影响等级和示例发生情况。我们看到 11 条已实现的规则中有 7 条未通过。我们选取之前的例子 ------ SPA-002(第 5 行),孤立 span 规则。
仪表板显示 SPA-002 规则未通过时,我们知道 OTel traces 中存在孤立 span。但具体在哪里呢?
进一步分析有两种方式:
-
针对特定规则钻取,查看哪些服务违反了该规则;
-
针对特定服务钻取,查看该服务违反了哪些规则。
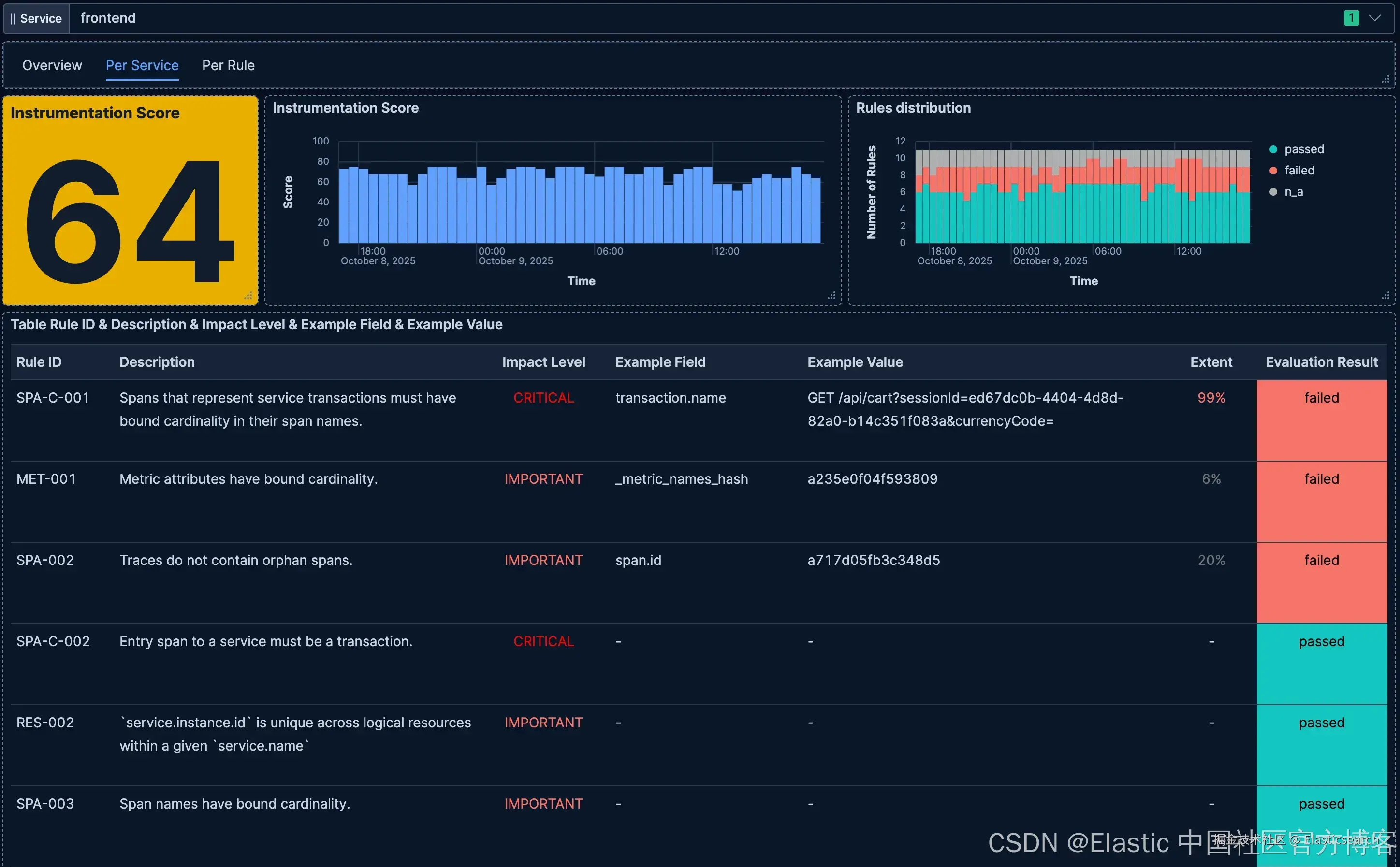
规则钻取
下方仪表板展示了对单条规则的详细评估结果。在本例中,我们在顶部选择了 SPA-002 规则。

除了规则的元信息,如描述、理由和标准外,我们在右侧还能看到一些统计信息。例如,我们看到有 2 个服务未通过该规则,16 个通过,19 个服务该规则不适用(例如,这些服务没有 tracing 数据)。在下方的表格中,我们看到受到该规则违规影响的两个服务:frontend 和 frontend-proxy 服务。对于每个服务,我们还可以看到违规的程度。以 frontend 服务为例,大约 20% 的 traces 存在孤立 spans。这条信息非常关键,因为它表明规则违规的严重程度。如果低于 1%,问题可能可以忽略,但五条 traces 中有一条损坏,则必须修复。此外,对于每个服务,我们都有一个示例 span.id,其对应的 span 在其他 spans 的 parent.id 中被引用,但找不到实际的 span。这使我们能够对具体示例进行进一步分析(例如,通过 Kibana 的 Discover 调查引用的 spans)。
通过这个视图,我们现在知道 frontend 服务有大量损坏的 traces。但该服务是否还违反了其他规则?如果是,哪些规则?
服务钻取
为了回答上述问题,我们可以切换到 "按服务仪表板"。
学习与观察
我对 Instrumentation Score 的实验非常有启发性,也展示了这个概念的强大 ------ 尽管它仍处于早期阶段。如果实现和计算包括按有意义的实体(如 services、K8s pods、hosts 等)进行拆分,这会特别有价值。通过这种拆分,你可以将数据质量问题缩小到可管理的范围,而不必在大量数据和实体中逐一筛查。
此外,我意识到对问题范围(按规则和服务)有所了解,以及提供具体示例,有助于让问题更加直观。
进一步思考规则违规范围的概念,甚至可以考虑将其纳入得分公式本身。在我看来,这会使得得分更加可比,并更能反映实际影响。我在 Instrumentation Score 项目的一个 issue 中提出了这个想法。
结论
Instrumentation Score 是确保 OpenTelemetry 数据高质量的强大方法。
感谢维护者 Antoine Toulme、Daniel Gomez Blanco、Juraci Paixão Kröhling 和 Michele Mancioppi,让这个伟大的项目得以实现,也感谢所有贡献者的参与!
通过规则和得分计算的正确实现,用户可以轻松获得可操作的洞察,了解需要在 instrumentation 和数据收集中修复的内容。Instrumentation Score 规则仍处于早期阶段,并在稳步改进和扩展。我期待社区未来在这个项目范围内构建更多内容,也希望加大我自己的贡献。