
前言
随着 AI 的发展,我们越来越希望 AI 能够与我们自己的应用程序或外部服务进行交互。比如,让 AI 帮你查询数据库、调用内部 API,甚至执行一些自动化任务。MCP 正是为此而生,它定义了一套标准,让 LLM 可以发现并安全地调用外部工具。
本文将带你从零开始,使用 Node.js 和 MCP TypeScript SDK 构建一个简单的 AI MCP。这个工具的功能是:根据指定的掘金用户 ID,抓取该用户的文章列表。同时还扩展了如何使用 TRAE 的创建智能体功能,联动这个MCP做进一步 Workflow。
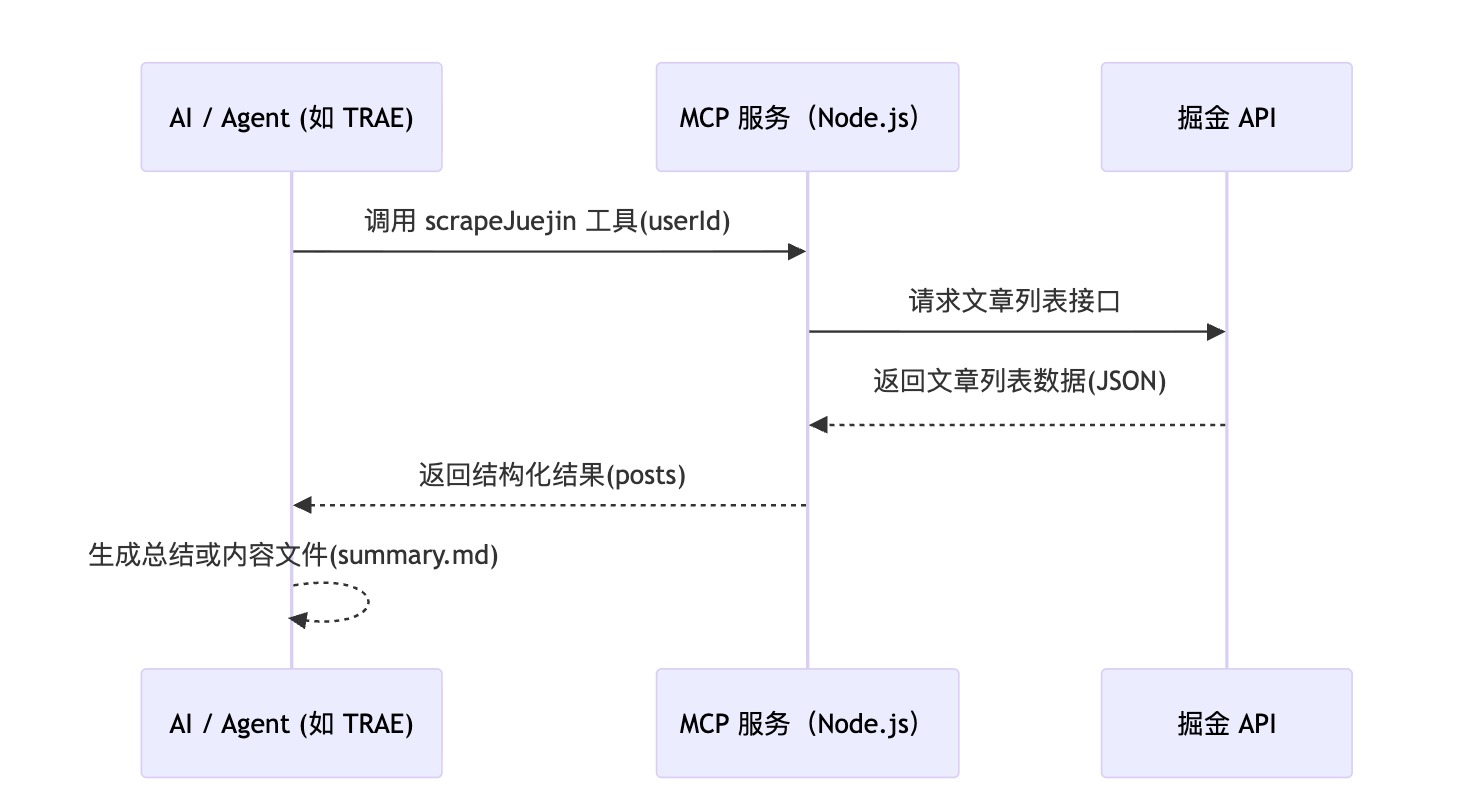
注:本文仅针对最基础的实践,旨在本地跑通创建和调用的过程,整体逻辑如下图
一、项目初始化和依赖安装
1. 初始化项目
Bash
npm init -y2. 安装依赖
@modelcontextprotocol/sdk: MCP 官方 SDK,用于构建服务和工具express: 用于快速搭建 HTTP 服务器axios: 用于向掘金 API 发送网络请求zod: 一个强大的 TypeScript-first 的 schema 校验库,用于定义工具的输入输出结构tsx: 一个零配置的 TypeScript 执行器,让我们能直接运行.ts文件typescript: TypeScript 语言支持
Bash
npm install @modelcontextprotocol/sdk express axios zod tsx typescript3. 添加启动脚本
注意 :我们添加了
"type": "module",因为 MCP SDK 使用了 ES Modules
在package.json中添加启动脚本
json
// ...existing code...
"type": "module",
"main": "server.ts",
"scripts": {
"start": "tsx server.ts",
},
// ...existing code...二、创建 MCP 服务与定义工具
创建主文件 server.ts,整个过程可以分为四个核心部分:
- 创建 MCP 服务实例:这是所有工具的"容器"
- 定义数据结构 (Schema) :使用 Zod 清晰地定义工具的输入参数和输出结果的格式,这相当于为 AI 提供了清晰的 API 文档
- 注册工具并实现逻辑:编写工具的核心代码,比如调用外部 API、处理数据等
- 启动 HTTP 服务器:将 MCP 服务通过一个 HTTP 端点暴露出去,让 AI 客户端可以连接
ts
// 导入所需的模块
import { McpServer } from '@modelcontextprotocol/sdk/server/mcp.js'; // 导入 MCP 服务核心类
import { StreamableHTTPServerTransport } from '@modelcontextprotocol/sdk/server/streamableHttp.js'; // 导入 MCP 的 HTTP 传输层
import express from 'express'; // 导入 Express 框架,用于创建 HTTP 服务器
import { z } from 'zod'; // 导入 Zod 库,用于数据校验和模式定义
import axios from 'axios'; // 导入 Axios 库,用于发送 HTTP 请求
// --- 1. 创建并配置 MCP 服务 ---
// McpServer 是 Model Context Protocol (MCP) 的核心实现。
// 它负责管理工具的注册、请求的路由和生命周期。
const server = new McpServer({
name: 'juejin-scraper-server', // 服务名称,用于标识
version: '1.0.0' // 服务版本
});
// --- 2. 定义工具的数据结构 (Schema) ---
// 使用 Zod 定义工具的输入和输出数据的结构,确保类型安全。
// 这就像是工具的 "API 文档",告诉调用者需要提供什么参数,以及会返回什么样的数据。
const blogPostSchema = z.object({
title: z.string().describe('文章标题'), // 定义文章标题为字符串类型
url: z.string().describe('文章链接') // 定义文章链接为字符串类型
});
// --- 3. 注册一个具体的工具 ---
// `registerTool` 方法将一个函数注册为 MCP 服务可以调用的工具。
server.registerTool(
'scrapeJuejin', // 工具的唯一名称,调用时使用
{
// 工具的元数据,用于描述工具的功能
title: '掘金文章抓取器',
description: '从指定的掘金用户主页抓取文章列表',
// 定义工具的输入参数 schema
inputSchema: {
userId: z.string().describe('需要抓取文章的掘金用户 ID')
},
// 定义工具的输出结果 schema
outputSchema: {
posts: z.array(blogPostSchema).describe('抓取到的文章列表')
}
},
// 工具的核心实现逻辑
async ({ userId }) => {
try {
// 定义掘金API的URL
const apiUrl = 'https://api.juejin.cn/content_api/v1/article/query_list';
// 使用 axios 发送 POST 请求到掘金 API,并设置 5 秒超时
const { data } = await axios.post(
apiUrl,
{
user_id: userId, // 传入用户ID
sort_type: 2, // 按发布时间倒序排序
cursor: '0' // 从第一页开始
},
{ timeout: 5000 } // 设置5秒的请求超时,增加健壮性
);
// 检查掘金 API 返回的数据是否包含错误
if (data.err_no !== 0) {
throw new Error(`掘金 API 错误: ${data.err_msg}`);
}
// 掘金 API 在用户没有文章时可能返回 null,这里做兼容处理,确保 articles 是一个数组
const articles = Array.isArray(data.data) ? data.data : [];
// 将 API 返回的文章数据映射成我们定义的 blogPostSchema 格式
const posts = articles.map((article: any) => ({
title: article.article_info.title,
url: `https://juejin.cn/post/${article.article_info.article_id}`
}));
const output = { posts };
// 按照 MCP 规范,返回处理成功的结果
// content: 用于纯文本显示
// structuredContent: 用于结构化数据处理
return {
content: [{ type: 'text', text: JSON.stringify(output, null, 2) }],
structuredContent: output
};
} catch (error: any) {
// 捕获并处理在工具执行过程中发生的任何错误
console.error(`[Tool Error] scrapeJuejin:`, error);
return {
content: [
{ type: 'text', text: `抓取掘金文章时出错: ${error.message}` }
],
isError: true // 标记这是一个错误响应
};
}
}
);
// --- 4. 设置并启动 HTTP 服务器 ---
const app = express();
app.use(express.json()); // 使用 Express 中间件来解析 JSON 请求体
// 定义 MCP 的主入口点 '/mcp'
app.post('/mcp', async (req, res) => {
// 创建一个 HTTP 传输层实例
// StreamableHTTPServerTransport 负责将标准的 HTTP 请求/响应与 MCP 服务的流式处理模型连接起来
const transport = new StreamableHTTPServerTransport({
sessionIdGenerator: undefined, // 使用默认的会话ID生成器
enableJsonResponse: true // 允许在非流式响应时返回单个JSON对象
});
// 监听客户端连接关闭事件,并相应地关闭 transport
res.on('close', () => {
transport.close();
console.log('[MCP Log] 客户端连接关闭');
});
// 将 MCP 服务连接到 transport,使其准备好处理请求
await server.connect(transport);
// transport 处理传入的 HTTP 请求,并将其转发给 MCP 服务进行处理
await transport.handleRequest(req, res, req.body);
});
const port = parseInt(process.env.PORT || '3000');
app
.listen(port, () => {
console.log(
`掘金抓取器 MCP 服务已启动,监听在 http://localhost:${port}/mcp`
);
})
.on('error', (error) => {
console.error('服务器启动失败:', error);
process.exit(1);
});三、运行与测试
1. 运行终端
在项目终端运行
Bash
npm start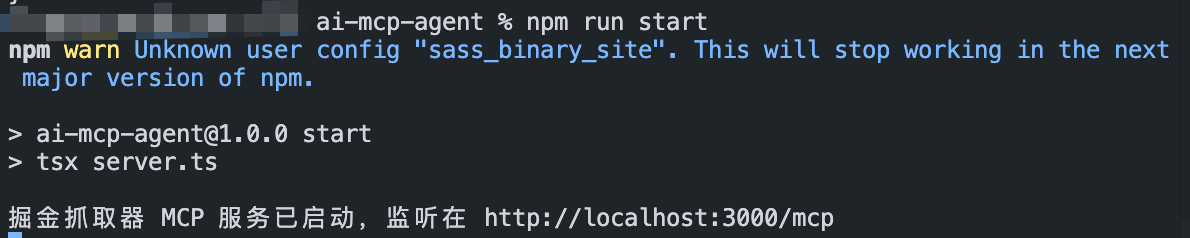
2. 在另一个终端测试
Bash
curl -X POST -H "Content-Type: application/json" -H "Accept: application/json, text/event-stream" -d '{"jsonrpc":"2.0","id":1,"method":"tools/call","params":{"name":"scrapeJuejin","arguments":{"userId":"1588154756765454"}}}' http://localhost:3000/mcp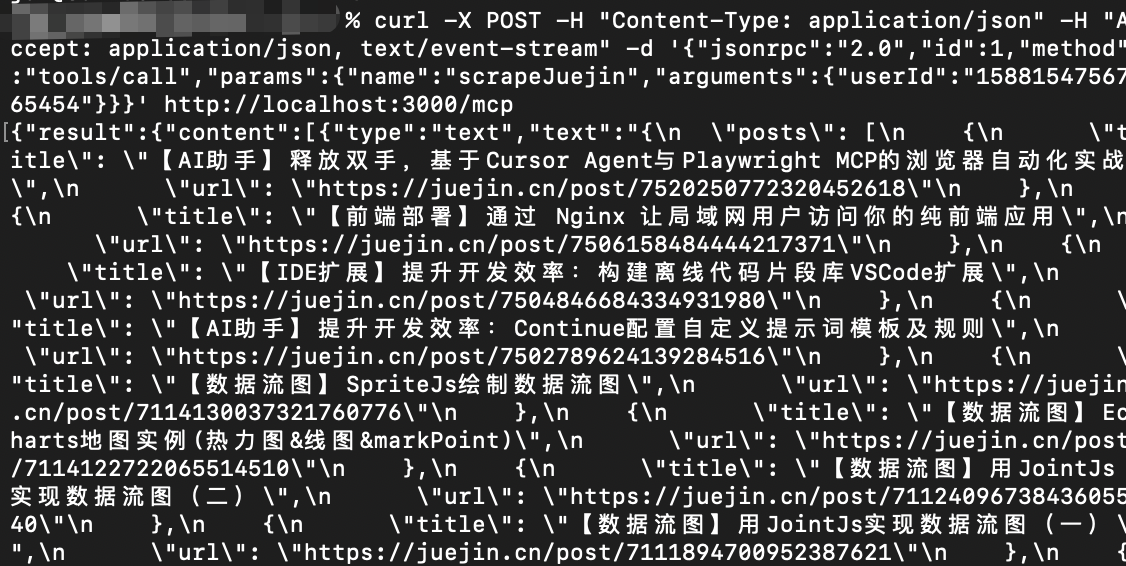
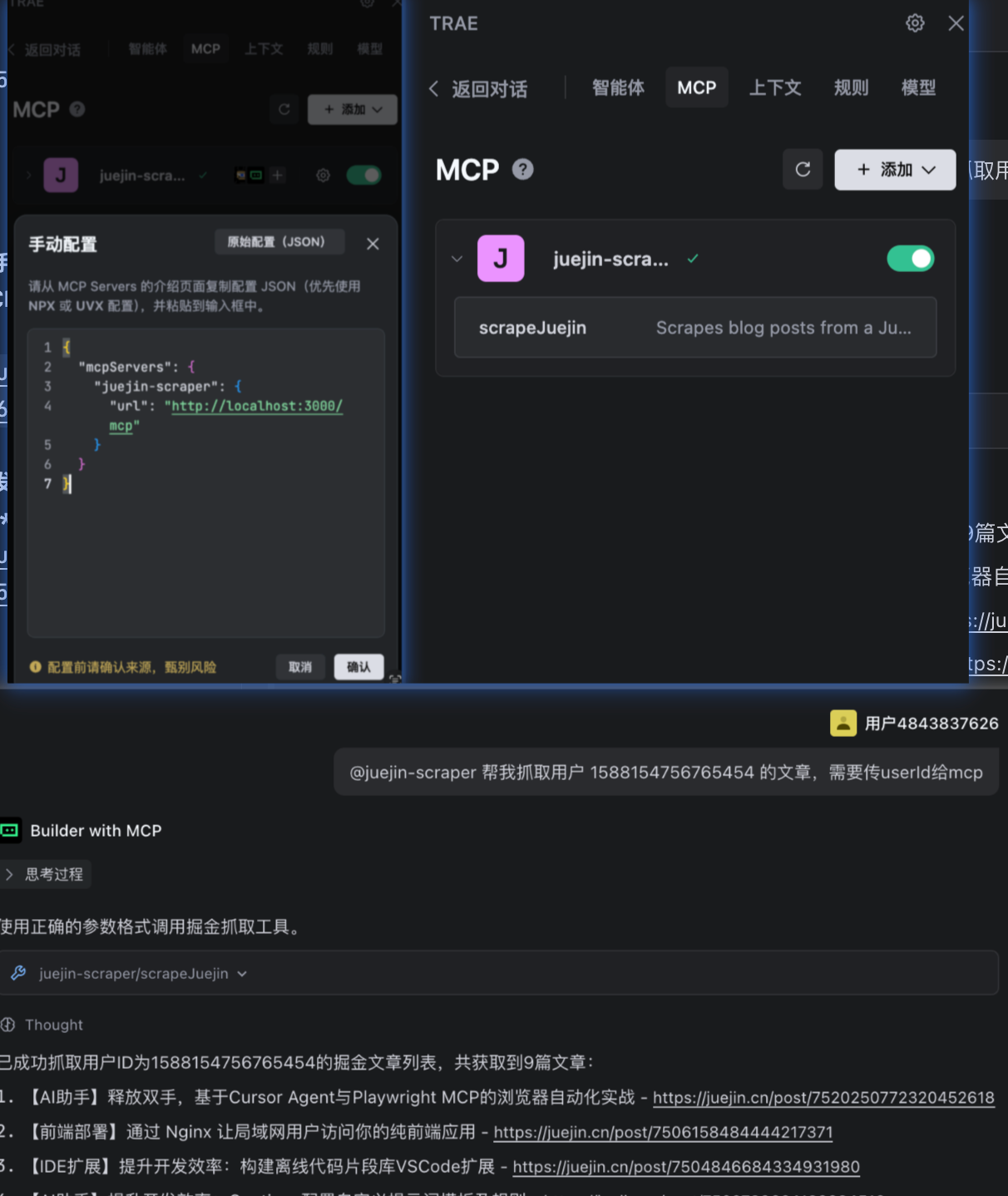
四、在TRAE中添加MCP工具并调用
MCP 工具创建好之后,需要一个 AI 代理(Agent)来发现并调用它。下面我们以 TRAE IDE 内置的Agent为例,演示如何将我们创建的工具集成进去。
json
{
"mcpServers": {
"juejin-scraper": {
"url": "http://localhost:3000/mcp"
}
}
}
五、在TRAE中创建智能体调用MCP
1. 在智能体页面进行创建
- 定义名称:掘金抓取
- 用提示词定义简单工作流
md
1. 通过 juejin-scraper MCP传参userId给MCP
2. 获取到文章列表之后使用互联网访问每个文章链接对内容做个总结
3. 将总结内容生成一个summary.md到根目录2. 调试运行
- 输入提示词调用
md
访问1588154756765454用户的掘金主页并总结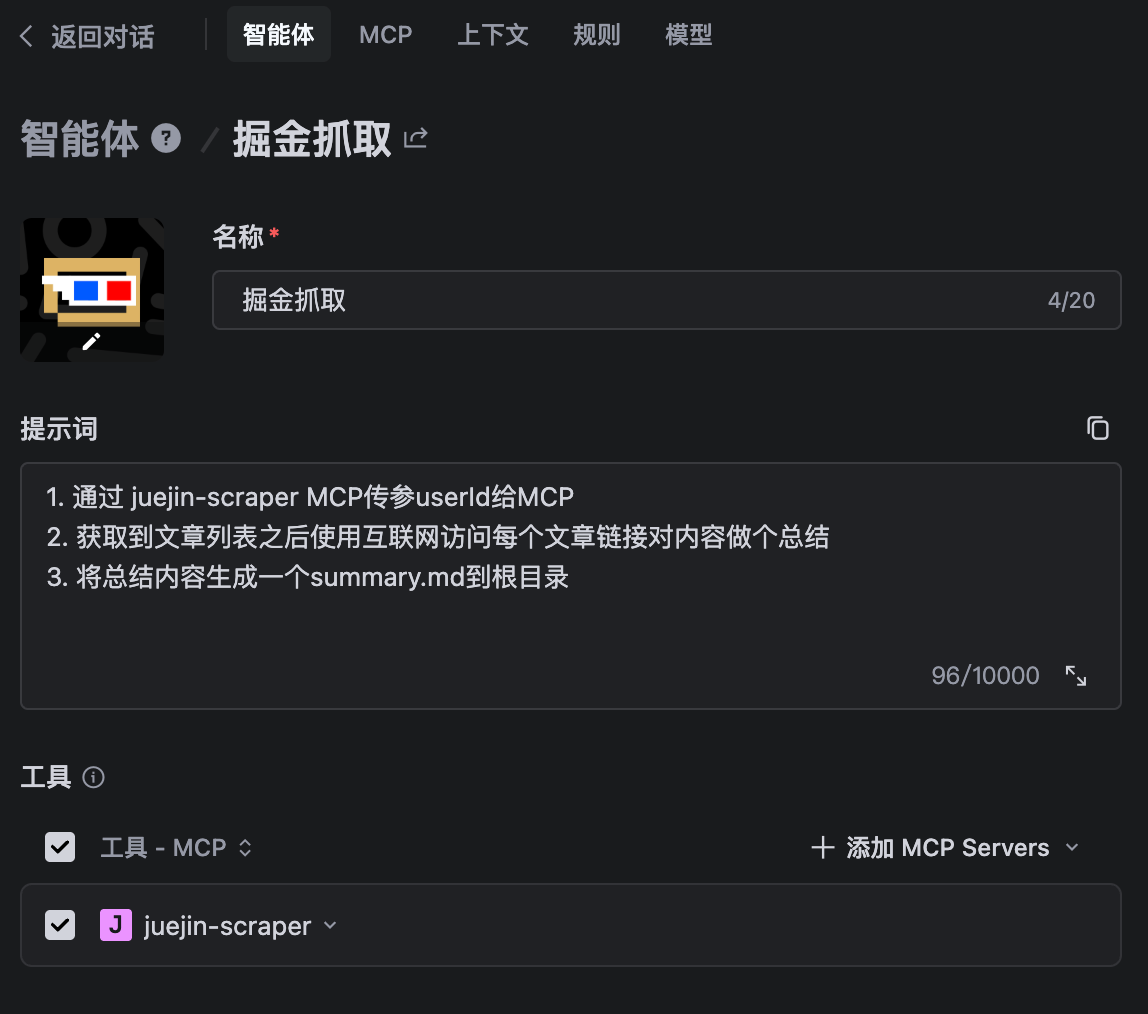
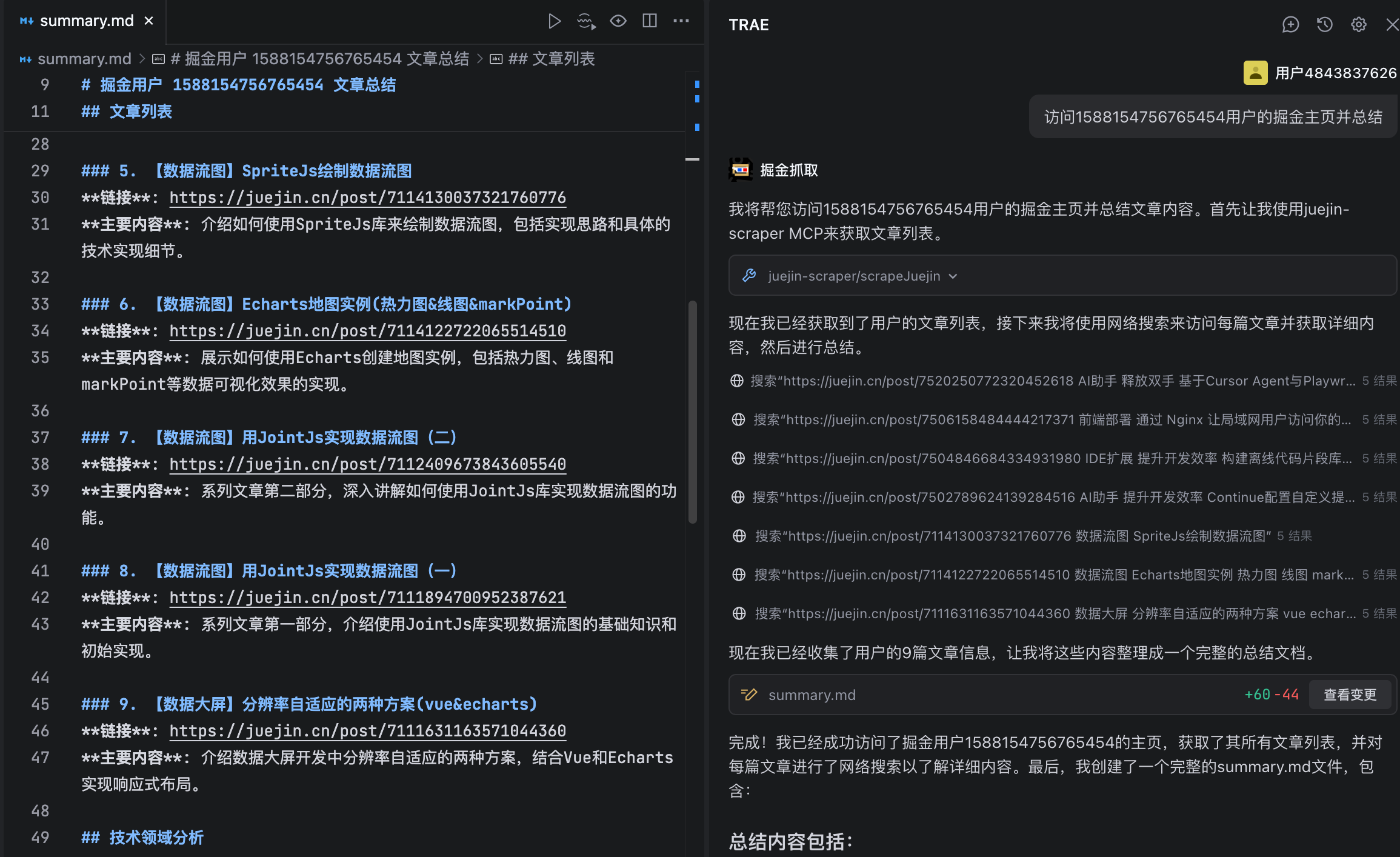
六、总结
到这里,已经成功让 AI 能够通过 MCP 服务抓取外部平台的数据,甚至通过工作流进一步分析并生成文件。 这是一种全新的交互方式:不再是 AI 单纯地检索和回答问题,而是AI 调用你写的服务,甚至参与你的工作流。
MCP 的理念简单却强大 ------ 让大模型成为"调用工具的中枢"。
本文只是最基础的实践,但掌握 MCP 后,你可以让 AI 调用任何自定义服务,构建属于自己的智能工具链。 可以尝试写爬虫脚本等做进一步的数据分析,也欢迎大家在评论区分享更多探索和讨论。