














 完整修补后代码:
完整修补后代码:
python
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel, AutoModelForCausalLM
class Retriever:
def __init__(self, embedder, tokenizer, corpus):
self.embedder = embedder
self.tokenizer = tokenizer
self.corpus = corpus # list of strings
# build index embeddings for corpus
self.embeddings = self.build_index(corpus)
def _text_to_vector(self, text_batch):
"""
text_batch: list of strings or single string wrapped in list
returns: tensor shape [len(text_batch), hidden_dim] on CPU (normalized)
"""
# 21. tokenization -> 使用 tokenizer 将文本转为 input tensors
enc = self.tokenizer(text_batch, return_tensors="pt", truncation=True, max_length=512)
# 把所有 tensor 移到 embedder 所在设备(通常是 GPU)
enc = {k: v.to(self.embedder.device) for k, v in enc.items()}
# 22. 前向推理得到模型输出(embedding 模型)
with torch.no_grad():
outputs = self.embedder(**enc)
# last hidden state
last_hidden = outputs.last_hidden_state # [batch, seq_len, hidden]
attn_mask = enc["attention_mask"] # [batch, seq_len]
# 23. 使用 attention mask 做加权平均池化得到句向量
# 将 attn_mask 扩展到最后一维用于广播
sent_vecs = (last_hidden * attn_mask.unsqueeze(-1)).sum(1) / attn_mask.sum(1, keepdim=True)
# 归一化并返回(这里返回 CPU 上的 tensor,便于后续矩阵运算)
sent_vecs = F.normalize(sent_vecs, p=2, dim=1).cpu()
return sent_vecs
def build_index(self, corpus):
# 计算 corpus 的向量并归一化,返回 [N, dim] tensor(CPU)
vecs_tensor = self._text_to_vector(corpus) # already normalized and on CPU
# 确保是 L2-normalized(上一步已经做,这里再保障)
vecs_normalized = F.normalize(vecs_tensor, p=2, dim=1)
return vecs_normalized.cpu()
def search(self, query_vec, topk=3):
# query_vec: tensor [dim] or [1, dim] on CPU or same device as self.embeddings (CPU here)
if query_vec.dim() == 1:
query_vec = query_vec.unsqueeze(0) # -> [1, dim]
# 归一化
query_normalized = F.normalize(query_vec, p=2, dim=1)
# 计算点积相似度(query x corpus.T)
similarities = torch.matmul(query_normalized, self.embeddings.T) # [1, N] on CPU
similarities = similarities.squeeze(0) # [N]
topk_scores, topk_indices = torch.topk(similarities, k=min(topk, len(self.corpus)))
results = [
{"text": self.corpus[idx], "score": float(topk_scores[i])}
for i, idx in enumerate(topk_indices)
]
return results
def rag_answer(query, retriever, generator, gen_tokenizer, topk=3, max_new_tokens=128):
# 先把 query 转为向量
query_vec_tensor = retriever._text_to_vector([query]) # returns tensor [1, dim] on CPU
query_vec = query_vec_tensor.squeeze(0).cpu() # [dim] on CPU
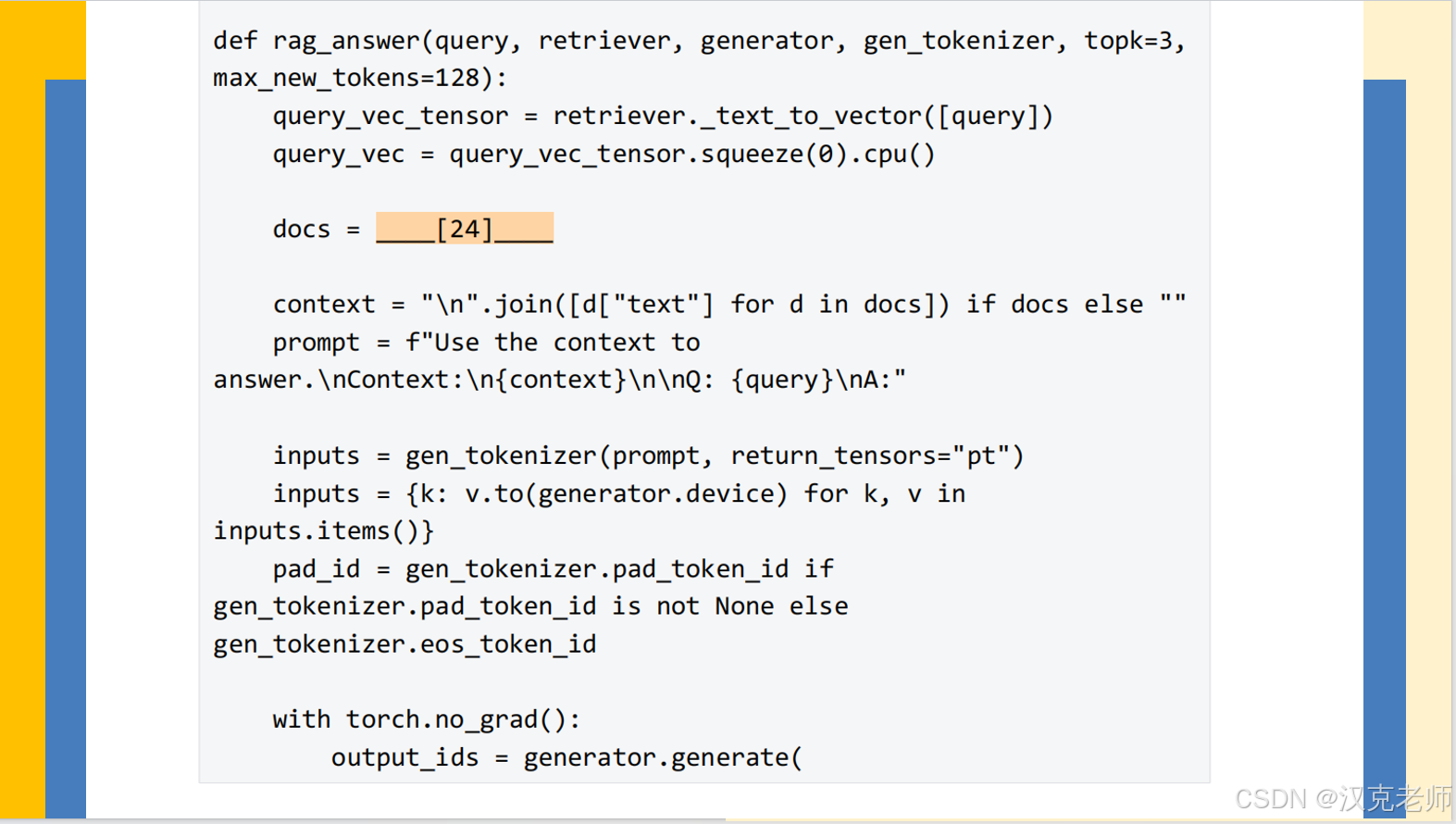
# 24. 使用 retriever.search 进行检索得到相关文档
docs = retriever.search(query_vec, topk=topk)
context = "\n".join([d["text"] for d in docs]) if docs else ""
prompt = f"Use the context to answer.\nContext:\n{context}\n\nQ: {query}\nA:"
inputs = gen_tokenizer(prompt, return_tensors="pt")
inputs = {k: v.to(generator.device) for k, v in inputs.items()}
pad_id = gen_tokenizer.pad_token_id if gen_tokenizer.pad_token_id is not None else gen_tokenizer.eos_token_id
# 生成答案
with torch.no_grad():
output_ids = generator.generate(
**inputs,
do_sample=True,
temperature=0.7,
top_p=0.9,
max_new_tokens=max_new_tokens,
pad_token_id=pad_id,
eos_token_id=gen_tokenizer.eos_token_id,
)
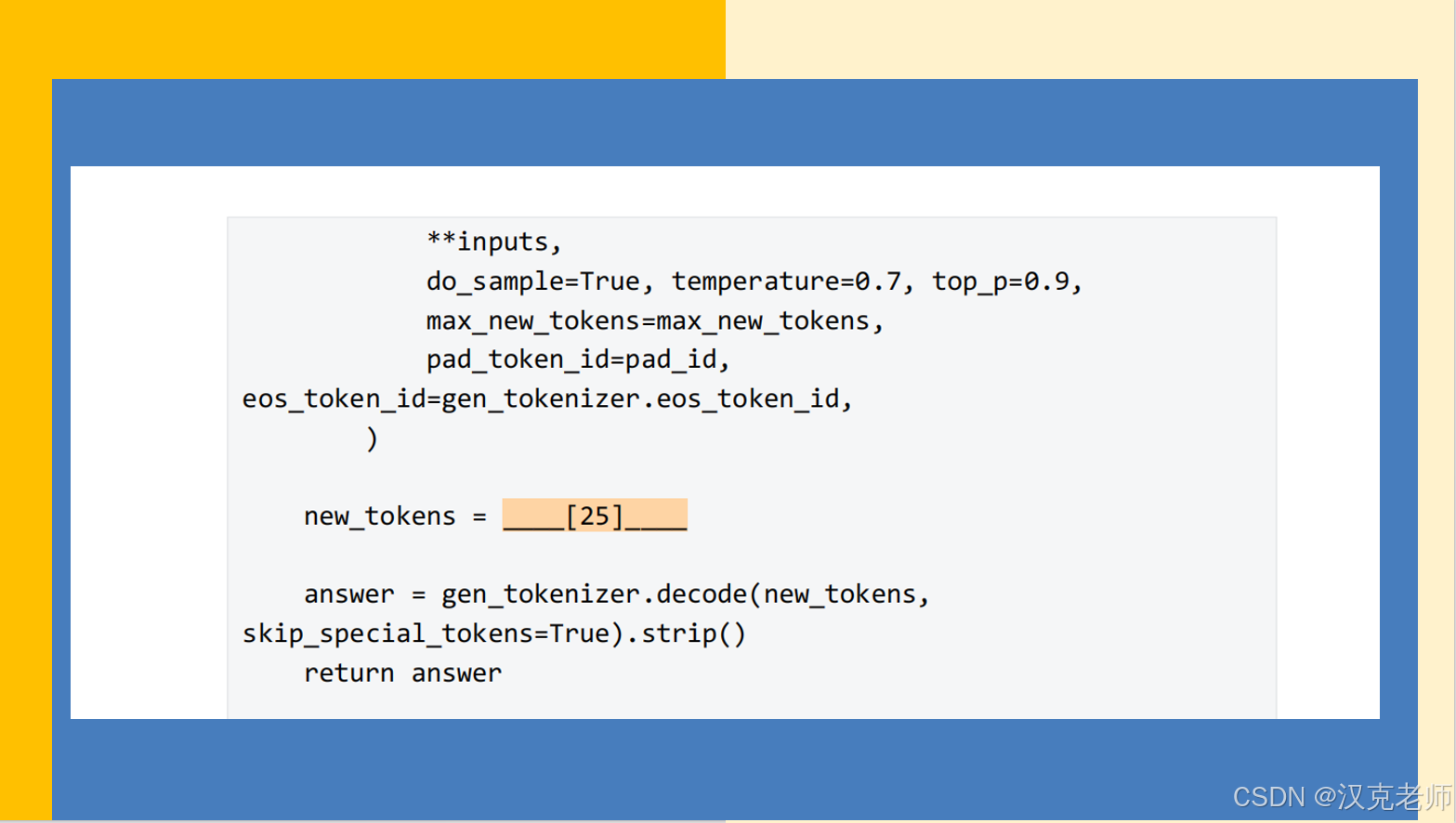
# 25. 截取生成的新 tokens(去除 prompt 部分),并解码
# inputs["input_ids"].shape[1] 表示 prompt 的长度
new_tokens = output_ids[0][inputs["input_ids"].shape[1]:] # 1D tensor of new token ids
answer = gen_tokenizer.decode(new_tokens, skip_special_tokens=True).strip()
return answer
if __name__ == "__main__":
embedder_name = "../Qwen/Qwen3-Embedding-0.6B"
retriever_tokenizer = AutoTokenizer.from_pretrained(embedder_name, trust_remote_code=True)
embedder = AutoModel.from_pretrained(embedder_name, trust_remote_code=True).to("cuda" if torch.cuda.is_available() else "cpu")
generator_name = "../Qwen/Qwen3-0.6B"
gen_tokenizer = AutoTokenizer.from_pretrained(generator_name, trust_remote_code=True)
generator = AutoModelForCausalLM.from_pretrained(generator_name, trust_remote_code=True).to("cuda" if torch.cuda.is_available() else "cpu")
corpus = [
"Paris is the capital of France.",
"Tokyo is the capital of Japan.",
"Beijing is the capital of China.",
]
retriever = Retriever(embedder, retriever_tokenizer, corpus)
query = "What is the capital of France?"
ans = rag_answer(query, retriever, generator, gen_tokenizer, topk=2)
print("Q:", query)
print("A:", ans)