作者:来自 Elastic JD Armada

学习如何使用 Mastra 和 Elasticsearch 作为记忆和信息检索的向量存储来构建具有语义回忆功能的知识 agent。
Agent Builder 现已作为技术预览提供。使用Elastic Cloud Trial 开始,并在此查看 Agent Builder 文档。
上下文工程(Context Engineering)在构建可靠的 AI agent 和架构中变得越来越重要。随着模型越来越强大,它们的有效性和可靠性对训练数据的依赖减小,更多取决于它们在正确上下文中被扎根的程度。能够在恰当时机检索并应用最相关信息的 agent 更有可能生成准确且值得信赖的输出。
在这篇博客里,我们将使用 Mastra 构建一个知识 agent ,该 agent 会记住用户所说的话并能在之后回忆相关信息,使用 Elasticsearch 作为记忆和检索的后端。你可以轻松地将相同概念扩展到现实世界用例,比如能够记住过去对话和解决方案的支持 agent ,使它们能够为特定用户定制回答或基于先前上下文更快地提供解决方案。
按步骤跟随本指南学习如何构建。如果你迷路或只想运行一个完整示例,请查看 repo 。
什么是 Mastra?
Mastra 是一个开源的 TypeScript 框架,用于构建具有可替换推理、记忆和工具模块的 AI agent。它的语义召回(semantic recall)功能让 agent 能通过将消息存储为向量数据库中的嵌入来记住并检索过去的交互。这使得 agent 能够保留长期的对话上下文和连续性。
Elasticsearch 是支持此功能的出色向量存储,因为它支持高效的密集向量搜索。当触发语义回忆时,agent 会将相关的历史消息提取到模型的上下文窗口中,使模型能够基于这些检索到的上下文进行推理和回答。
开始所需条件:
-
Node v18+
-
Elasticsearch(版本 8.15 或更高)------可在本地或通过 Elastic Cloud 托管部署
注意:当前的早期集成暂不兼容 Elastic Serverless 部署,因为创建自定义向量映射的底层 API 不同。一旦全面支持可用,我们将更新此指南。
-
Elasticsearch API Key
-
注意:你需要它是因为演示使用了 OpenAI 提供方,但 Mastra 支持其他 AI SDK 和社区模型提供方,因此你可以根据设置轻松替换。
构建一个 Mastra 项目
我们将使用 Mastra 的内置 CLI 来为项目提供脚手架。运行以下命令:
npm create mastra@latest你会看到一系列提示,首先是:
-
为你的项目命名:

-
我们可以保留默认值;可以留空:

-
对于这个项目,我们将使用 OpenAI 提供的模型:

-
选择"Skip for now"选项,因为我们将在后续步骤中将所有环境变量存储在
.env文件中:
-
我们也可以跳过此选项:
初始化完成后,我们可以进入下一步。
安装依赖
接下来,我们需要安装一些依赖:
npm install ai @ai-sdk/openai @elastic/elasticsearch dotenv- ai - 核心 AI SDK 包,提供在 JavaScript/TypeScript 中管理 AI 模型、提示和工作流的工具。Mastra 构建在 Vercel 的 AI SDK 之上,因此我们需要此依赖以使模型与你的 agent 进行交互。
- @ai-sdk/openai - 将 AI SDK 连接到 OpenAI 模型(如 GPT-4、GPT-4o 等)的插件,允许使用你的 OpenAI API Key 调用 API。
- @elastic/elasticsearch - Node.js 官方 Elasticsearch 客户端,用于连接到你的 Elastic Cloud 或本地集群进行索引、搜索和向量操作。
- dotenv - 将环境变量从
.env文件加载到process.env,允许你安全地注入 API Key 和 Elasticsearch 端点等凭证。
配置环境变量
如果你的项目根目录中还没有 .env 文件,请创建一个。或者,你可以复制并重命名我在 repo 中提供的示例 .env 文件。在此文件中,我们可以添加以下变量:
ELASTICSEARCH_ENDPOINT="your-endpoint-here"
ELASTICSEARCH_API_KEY="your-key-here"
OPENAI_API_KEY="your-key-here"基本设置到此完成。从这里,你已经可以开始构建和编排 agent 了。我们将进一步添加 Elasticsearch 作为存储和向量搜索层。
将 Elasticsearch 添加为向量存储
创建一个名为 stores 的新文件夹,并在其中添加此文件。在 Mastra 和 Elastic 发布官方 Elasticsearch 向量存储集成之前,Abhi Aiyer(Mastra CTO)分享了这个早期原型类,称为 ElasticVector。简单来说,它将 Mastra 的记忆抽象连接到 Elasticsearch 的稠密向量功能,使开发者可以将 Elasticsearch 作为 agent 的向量数据库。
让我们深入看看集成的重要部分:
Elasticsearch 客户端的引入
这一部分定义了 ElasticVector 类并设置了 Elasticsearch 客户端连接。
export class ElasticVector extends MastraVector {
private client: Client;
constructor(config: ClientOptions) {
super();
this.client = new Client(config);
}- extends MastraVector:这使得 ElasticVector 可以继承 Mastra 的基础 MastraVector 类,这是所有向量存储集成都遵循的通用接口。这确保了从 agent 的角度来看,Elasticsearch 的行为就像任何其他 Mastra 向量后端一样。
- private client: Client:这是一个私有属性,保存 Elasticsearch JavaScript 客户端的实例。这使得类可以直接与集群通信。
- constructor(config: ClientOptions):该构造函数接受一个配置对象(通常包含你的 Elasticsearch 凭证),并使用它初始化客户端:
this.client = new Client(config)。 - super():调用 Mastra 的基础构造函数,从而继承日志记录、验证辅助函数和其他内部钩子。
到此,Mastra 已经知道有一个新的向量存储叫做 ElasticVector。
在 Elasticsearch 中创建 "memory" 存储
下面的函数设置了一个 Elasticsearch 索引来存储嵌入。它会检查索引是否已存在。如果不存在,则创建一个索引,并使用下面的映射,其中包含一个 dense_vector 字段来存储嵌入以及自定义相似度指标。
需要注意的几点:
-
dimension参数是每个嵌入向量的长度,这取决于你使用的嵌入模型。在我们的例子中,我们将使用 OpenAI 的text-embedding-3-small模型生成嵌入,该模型输出大小为 1536 的向量。我们将其作为默认值。 -
映射中使用的
similarity变量由辅助函数const similarity = this.mapMetricToSimilarity(metric)定义,它接收metric参数的值,并将其转换为 Elasticsearch 兼容的关键字,用于所选的距离度量。-
例如:Mastra 使用向量相似度的一般术语,如 cosine、euclidean 和 dotproduct。如果我们直接在 Elasticsearch 映射中传入 metric
euclidean,会报错,因为 Elasticsearch 期望关键字l2_norm来表示欧几里得距离。async createIndex(params: CreateIndexParams): Promise
{
// Extract parameters with sensible defaults added.
const { indexName, dimension = 1536, metric = 'cosine' } = params;try {
const exists = await this.client.indices.exists({ index: indexName });if (exists) { await this.validateExistingIndex(indexName, dimension, metric); return; } // Map metric to Elasticsearch similarity const similarity = this.mapMetricToSimilarity(metric); await this.client.indices.create({ index: indexName, settings: { number_of_shards: 1, number_of_replicas: 0, // Use 0 for single-node or serverless setups }, mappings: { properties: { vector: { type: 'dense_vector', dims: dimension, // Default 1536 for the embedding model we'll use index: true, similarity: similarity, // e.g., cosine, dot_product, l2_norm }, metadata: { type: 'object', enabled: true, }, }, }, }); this.logger?.info( `Created Elasticsearch index "${indexName}" with ${dimension} dimensions and ${metric} metric` );} catch (error) {
this.logger?.error(Failed to create index "${indexName}": ${error});
throw error;
}
}
-
在交互后存储新的记忆或笔记
该函数会将每次交互后生成的新嵌入及其元数据插入或更新到索引中,使用 Elasticsearch 的 bulk API。bulk API 会将多个写入操作合并为一个请求;这种方式提高了索引性能,确保随着 agent 的记忆不断增长,更新仍然高效。
async upsert(params: UpsertVectorParams): Promise<string[]> {
const { indexName, vectors, metadata = [], ids } = params;
try {
// Generate IDs if not provided
const vectorIds = ids || vectors.map((_, i) => `vec_${Date.now()}_${i}`);
const operations = vectors.flatMap((vec, index) => [
{ index: { _index: indexName, _id: vectorIds[index] } },
{
vector: vec,
metadata: metadata[index] || {},
},
]);
const response = await this.client.bulk({
refresh: true,
operations,
});
if (response.errors) {
const erroredItems = response.items
.filter((item: any) => item.index?.error);
const erroredIds = erroredItems.map((item: any) => item.index?._id);
const errorDetails = erroredItems.slice(0, 3).map((item: any) => ({
id: item.index?._id,
error: item.index?.error
}));
console.error(`Failed to upsert ${erroredIds.length} vectors. Sample errors:`, JSON.stringify(errorDetails, null, 2));
this.logger?.error(`Failed to upsert ${erroredIds.length} vectors. Sample errors:`, JSON.stringify(errorDetails, null, 2));
}
return vectorIds;
} catch (error) {
this.logger?.error(`Failed to upsert vectors to "${indexName}": ${error}`);
throw error;
}
}查询相似向量以进行语义回忆
该函数是语义回忆功能的核心。agent 使用向量搜索在我们的索引中查找相似的已存储嵌入。
async query(params: QueryVectorParams<any>): Promise<QueryResult[]> {
const { indexName, queryVector, topK = 10, filter, includeVector = false } = params;
try {
const knnQuery: any = {
field: 'vector',
query_vector: queryVector,
k: topK,
num_candidates: Math.max(topK * 10, 100),
};
// Add filter if provided
if (filter) {
knnQuery.filter = this.buildElasticFilter(filter);
}
const sourceFields = ['metadata'];
if (includeVector) {
sourceFields.push('vector');
}
const response = await this.client.search({
index: indexName,
knn: knnQuery,
size: topK,
_source: sourceFields,
});
return response.hits.hits.map((hit: any) => ({
id: hit._id,
score: hit._score || 0,
metadata: hit._source.metadata,
vector: includeVector ? hit._source.vector : undefined,
}));
} catch (error) {
this.logger?.error(`Failed to query vectors from "${indexName}": ${error}`);
throw error;
}
}底层原理:
-
使用 Elasticsearch 的 knn API 运行 kNN(k 最近邻)查询。
-
检索与输入查询向量最相似的前 K 个向量。
-
返回结构化结果,包括文档 ID、相似度分数和存储的元数据。
创建知识 agent
现在我们已经了解了通过 ElasticVector 集成 Mastra 与 Elasticsearch 的连接,让我们创建知识 agent 本身。
在 agents 文件夹内,创建一个名为 knowledge-agent.ts 的文件。我们可以从连接环境变量并初始化 Elasticsearch 客户端开始。
import { Agent } from '@mastra/core/agent';
import { Memory } from '@mastra/memory';
import { openai } from '@ai-sdk/openai';
import { Client } from '@elastic/elasticsearch';
import { ElasticVector } from '../stores/elastic-store';
import dotenv from "dotenv";
dotenv.config();
const ELASTICSEARCH_ENDPOINT = process.env.ELASTICSEARCH_ENDPOINT;
const ELASTICSEARCH_API_KEY = process.env.ELASTICSEARCH_API_KEY;
//Error check for undefined credentials
if (!ELASTICSEARCH_ENDPOINT || !ELASTICSEARCH_API_KEY) {
throw new Error('Missing Elasticsearch credentials');
}
//Check to see if a connection can be established
const testClient = new Client({
node: ELASTICSEARCH_ENDPOINT,
auth: {
apiKey: ELASTICSEARCH_API_KEY
},
});
try {
await testClient.ping();
console.log('Connected to Elasticsearch successfully');
} catch (error: unknown) {
if (error instanceof Error) {
console.error('Failed to connect to Elasticsearch:', error.message);
} else {
console.error('Failed to connect to Elasticsearch:', error);
}
process.exit(1);
}
//Initialize the Elasticsearch vector store
const vectorStore = new ElasticVector({
node: ELASTICSEARCH_ENDPOINT,
auth: {
apiKey: ELASTICSEARCH_API_KEY,
},
});在这里,我们:
-
使用 dotenv 从
.env文件加载变量。 -
检查 Elasticsearch 凭证是否正确注入,并确保可以成功连接客户端。
-
将 Elasticsearch 端点和 API Key 传入 ElasticVector 构造函数,创建之前定义的向量存储实例。
接下来,我们可以使用 Mastra 的 Agent 类来定义 agent。
export const knowledgeAgent = new Agent({
name: 'KnowledgeAgent',
instructions: 'You are a helpful knowledge assistant.',
model: openai('gpt-4o'),
memory: new Memory({
vector: vectorStore,
//embedder used to create embeddings for each message
embedder: 'openai/text-embedding-3-small',
//set semantic recall options
options: {
semanticRecall: {
topK: 3, // retrieve 3 similar messages
messageRange: 2, // include 2 messages before/after each match
scope: 'resource',
},
},
}),
});我们可以定义的字段包括:
-
name 和 instructions:为 agent 赋予身份和主要功能。
-
model:我们使用 @ai-sdk/openai 包中的 OpenAI 的 gpt-4o。
-
memory:
-
vector:指向我们的 Elasticsearch 存储,使嵌入可以存储和检索。
-
embedder:用于生成嵌入的模型
-
semanticRecall 选项决定回忆的方式:
-
topK:要检索的语义相似消息数量。
-
messageRange:每次匹配包含的对话范围。
-
scope:定义记忆的边界。
-
-
快完成了。我们只需将新创建的 agent 添加到 Mastra 配置中。在名为 index.ts 的文件中,导入知识 agent 并将其插入到 agents 字段。
export const mastra = new Mastra({
agents: { knowledgeAgent },
storage: new LibSQLStore({
// stores observability, scores, ... into memory storage, if it needs to persist, change to file:../mastra.db
url: ":memory:",
}),
logger: new PinoLogger({
name: 'Mastra',
level: 'info',
}),
telemetry: {
// Telemetry is deprecated and will be removed in the Nov 4th release
enabled: false,
},
observability: {
// Enables DefaultExporter and CloudExporter for AI tracing
default: { enabled: true },
},
});其他字段包括:
-
storage:这是 Mastra 的内部数据存储,用于运行历史、可观测性指标、分数和缓存。有关 Mastra 存储的更多信息,请访问此处。
-
logger:Mastra 使用 Pino,这是一个轻量级的结构化 JSON 日志记录器。它捕获事件,如 agent 启动和停止、工具调用及结果、错误以及 LLM 响应时间。
-
observability:控制 agent 的 AI 跟踪和执行可见性。它跟踪:
-
每个推理步骤的开始/结束
-
使用了哪个模型或工具
-
输入和输出
-
分数和评估
-
使用 Mastra Studio 测试 agent
恭喜!如果你已经完成到这一步,你可以运行该 agent 并测试其语义回忆能力。幸运的是,Mastra 提供了内置的聊天 UI,因此我们不必自己构建。
要启动 Mastra 开发服务器,打开终端并运行以下命令:
npm run dev在服务器初次打包和启动后,它会为你提供 Playground 的地址。

将此地址粘贴到浏览器中,你将看到 Mastra Studio。
选择 knowledgeAgent 选项并开始聊天。
为了快速测试一切是否正确连接,先输入一些信息,例如:"团队宣布十月份销售业绩增长了 12%,主要由企业续约推动。下一步是扩大对中型市场客户的推广。"
然后,开始一个新聊天并提出问题,例如:"我们说接下来需要关注哪个客户群体?"
知识 agent 应该能够回忆起你在第一次聊天中提供的信息。你应该会看到类似这样的回应:

看到这样的回应意味着 agent 成功将我们之前的消息作为嵌入存储在 Elasticsearch 中,并在之后通过向量搜索检索出来。
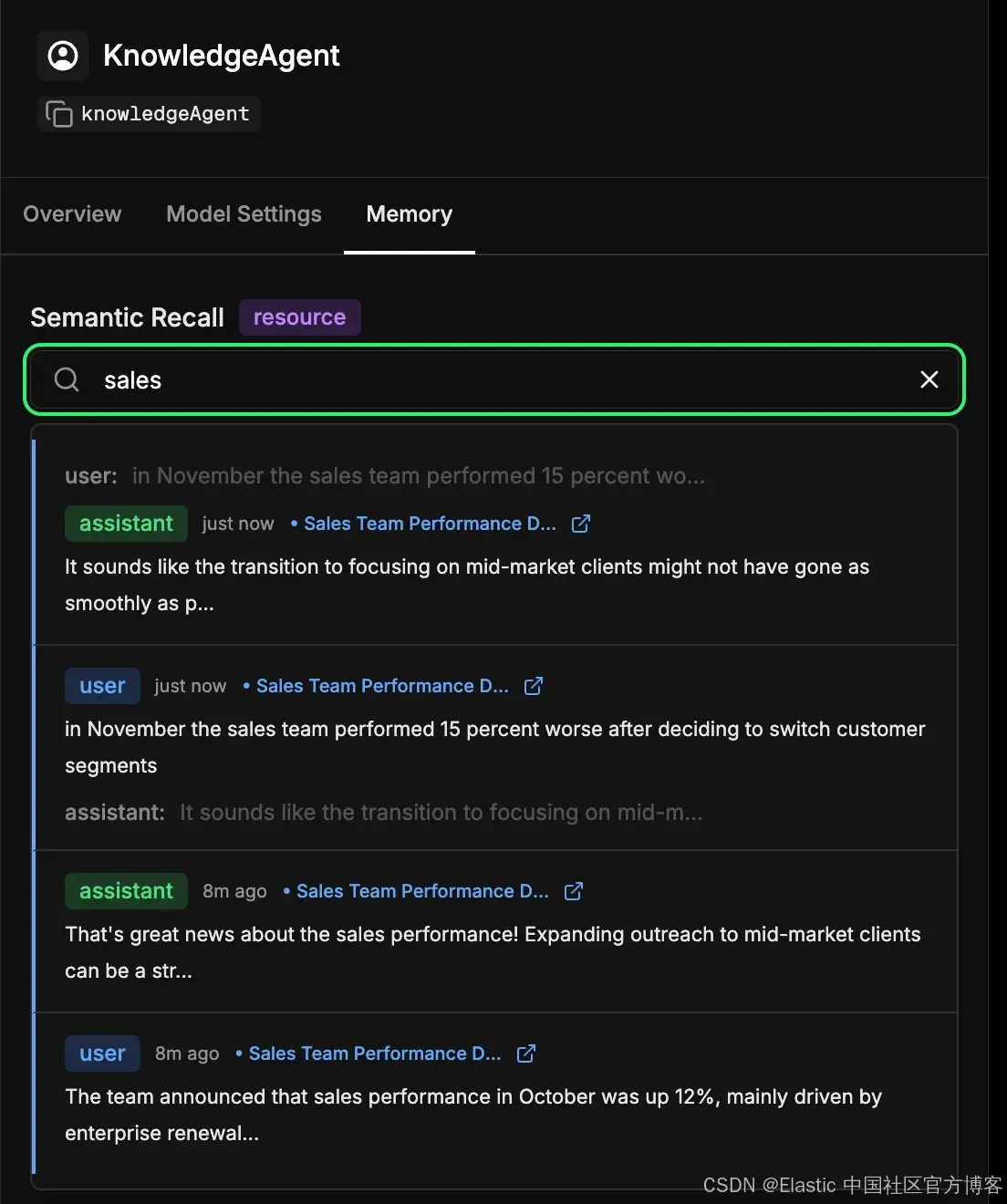
检查 agent 的长期记忆存储
进入 Mastra Studio 中 agent 配置的 memory 标签。这让你可以看到 agent 随时间学到的内容。每条消息、回应和交互被嵌入并存储在 Elasticsearch 中,都会成为长期记忆的一部分。你可以对过去的交互进行语义搜索,以快速找到 agent 之前学到的信息或上下文。这基本上与 agent 在语义回忆时使用的机制相同,但在这里你可以直接检查它。在下面的示例中,我们搜索了术语 "sales",并返回了所有包含与销售相关内容的交互。
结论
通过连接 Mastra 和 Elasticsearch,我们可以为 agent 提供记忆,这是上下文工程中的关键层。借助语义回忆,agent 可以随着时间建立上下文,将回应基于它们学到的内容。这意味着更准确、可靠且自然的交互。
这一早期集成只是起点。这里的相同模式可以用于记住过去工单的支持 agent、检索相关文档的内部机器人,或能够在对话中回忆客户信息的 AI 助手。我们也在努力实现官方的 Mastra 集成,使这种组合在不久的将来更加无缝。
我们很期待看到你接下来会构建什么。试一试,探索 Mastra 及其记忆功能,并随时与社区分享你的发现。
原文:https://www.elastic.co/search-labs/blog/knowledge-agent-semantic-recall-mastra-elasticsearch