本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
在大语言模型(LLM)主导的生成式 AI 浪潮中,检索增强生成(Retrieval-Augmented Generation,RAG)凭借 "外部知识检索 + 模型生成" 的模式,解决了 LLM "知识过时""幻觉输出" 等关键问题,成为企业落地 AI 应用的核心方案。而支撑 RAG 实现 "精准检索" 的底层技术,正是Embedding(嵌入)技术。
本文将从技术本质、工作原理、在 RAG 中的应用流程,到技术挑战与演进方向,全面解析这一 "连接文本与机器理解" 的关键技术。
一、什么是 Embedding 技术?
简单来说,Embedding 技术是一种将非结构化数据(如文本、图片、音频)转化为结构化 "数字向量"(Vector) 的技术。这些向量就像数据的 "数字身份证",不仅能被计算机快速处理,还能通过向量间的 "距离"(如余弦距离、欧氏距离)衡量原始数据的 "语义相似度"------ 距离越近,代表两个数据的含义越相似。
1.1 为什么需要 Embedding?
人类能轻松理解 "猫" 和 "猫咪" 是相近概念,"苹果(水果)" 和 "苹果(公司)" 是不同含义,但计算机无法直接理解文字的语义。例如,直接将 "猫" 和 "狗" 用二进制 "01""10" 表示时,计算机只能识别 "编码不同",却无法判断 "两者都是哺乳动物" 这一语义关联。
Embedding 技术的核心价值,就是为文字赋予 "语义层面的数字表达"。比如:
(1)"猫" 的 Embedding 向量可能是:0.21, 0.85, -0.12, 0.33, ..., 0.67(假设维度为 768)
(2)"猫咪" 的 Embedding 向量可能是:0.23, 0.82, -0.11, 0.35, ..., 0.69
(3)"狗" 的 Embedding 向量可能是:0.78, 0.15, -0.09, 0.42, ..., 0.21
通过计算向量距离会发现:"猫" 与 "猫咪" 的余弦距离接近 0(相似度极高),而 "猫" 与 "狗" 的距离明显更大(相似度较低)------ 这正是机器理解语义的关键。
二、Embedding 技术工作原理
Embedding 模型并非单一结构,而是经历了 "词嵌入模型(如 Word2Vec)→ 上下文词嵌入模型(如 BERT)→ 句子嵌入模型(如 Sentence-BERT)" 的演进。不同架构的核心差异在于 "是否能捕捉上下文语义",这直接决定了 Embedding 向量的语义表达能力。
2.1 三代模型架构对比
| 模型类型 | 代表模型 | 核心特点 | 局限性 | 适用场景 |
| 词嵌入模型 | Word2Vec、GloVe | 为每个词生成固定向量,不考虑上下文 | "苹果(水果)" 和 "苹果(公司)" 向量相同 | 简单文本分类、关键词匹配 |
| 上下文词嵌入模型 | BERT、RoBERTa | 为每个词生成 "上下文相关向量",但无句子级输出 | 需额外处理才能生成句子向量,速度慢 | 文本理解、命名实体识别 |
| 句子嵌入模型 | Sentence-BERT、MiniLM | 直接输出句子 / 段落级向量,兼顾精度与速度 | 长文本处理能力有限(早期版本) | RAG 检索、句子相似度计算 |
举个直观例子:
输入句子 "我用苹果手机查苹果的价格",不同模型的输出差异如下:
(1)Word2Vec:两个 "苹果" 的向量完全相同(0.32, 0.51, -0.17, ...),无法区分 "公司" 和 "水果" 含义;
(2)BERT:第一个 "苹果"(修饰手机)的向量为0.45, 0.62, -0.21, ...,第二个 "苹果"(指水果)的向量为0.28, 0.48, -0.15, ...,但需对句子中所有词向量取平均才能得到句子向量,计算成本高;
(3)Sentence-BERT:直接输出整个句子的向量0.39, 0.55, -0.19, ...,且能隐含 "第一个苹果指公司,第二个指水果" 的上下文关联,速度比 BERT 快 100 倍以上,完美适配 RAG 的批量向量生成需求。
2.2 核心架构:Transformer
当前主流的 Sentence-BERT、OpenAI Embedding 模型,均基于Transformer编码器(Encoder) 构建,其核心是 "自注意力机制(Self-Attention)"------ 让模型在处理每个词时,都能 "看到" 句子中其他词的信息,从而理解语义关联。
我们以 "如何用 Python 读取 Excel 文件" 这句话为例,拆解自注意力机制的工作过程:
1.词的 "注意力权重" 计算
模型会为每个词(如 "Python")计算与其他词("用""读取""Excel""文件")的 "注意力权重",权重越高代表关联性越强。例如:
(1)"Python" 与 "读取" 的权重为 0.82(强关联,因为 Python 是实现读取动作的工具);
(2)"Python" 与 "如何" 的权重为 0.15(弱关联,"如何" 是疑问词,与工具无关)。
2.加权融合上下文信息
每个词的向量会融合 "其他词向量 × 注意力权重" 的结果。例如,"Python" 的最终向量 =("读取" 向量 ×0.82)+("Excel" 向量 ×0.75)+("如何" 向量 ×0.15)+ ... ,从而让 "Python" 的向量隐含 "用于读取 Excel 文件" 的上下文含义。
3.多层堆叠强化理解
Transformer 编码器通常包含 6-12 层(如 BERT-base 有 12 层),每一层都会重复 "计算注意力权重→融合上下文" 的过程。例如,第一层可能只捕捉 "Python" 与 "读取" 的直接关联,而第三层会进一步理解 "Python 读取 Excel" 是 "解决文件处理问题" 的整体逻辑,层数越多,模型对复杂语义的理解越深刻。
2.3 模型训练
Embedding 向量并非人工定义,而是由专门的Embedding 模型(如 BERT、Sentence-BERT、OpenAI Embedding 等)通过大规模数据训练生成。其核心流程可分为 "模型训练" 和 "向量生成" 两步。
Embedding 模型的训练本质是 "教会模型识别语义相似性"。以最常用的Sentence-BERT(SBERT) 为例,训练过程就像 "老师教学生辨词":
(1)给模型 "喂" 数据:输入大量文本对,标注 "相似" 或 "不相似"(如 "喝奶茶" 和 "喝珍珠奶茶" 标为相似,"喝奶茶" 和 "骑自行车" 标为不相似);
(2)模型 "学习" 规律:模型通过调整内部参数,让 "相似文本对" 的向量距离变小,"不相似文本对" 的距离变大;
(3)考核与优化:通过 "损失函数" 计算模型预测结果与标注的差距,反复调整参数,直到模型能稳定区分语义相似度。
训练完成后,模型就具备了 "输入任意文本,输出对应 Embedding 向量" 的能力。
2.4 向量生成流程
当我们需要为一段文本生成 Embedding 向量时,模型会遵循以下标准化流程:
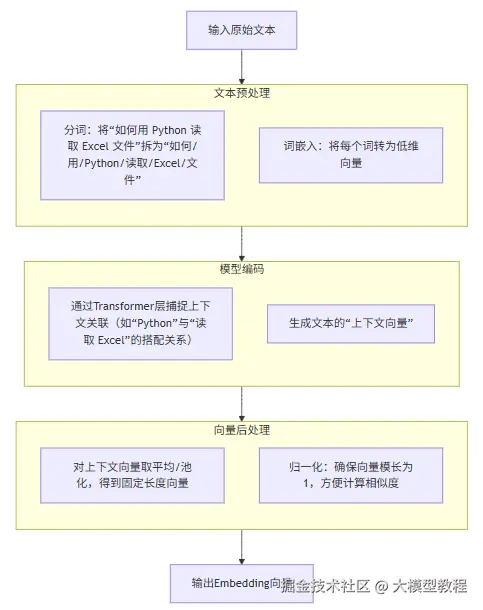
举个具体例子:输入文本 "如何用 Python 读取 Excel 文件?"
(1)预处理:分词为 "如何 / 用 / Python / 读取 / Excel / 文件 /?",并将每个词转为基础向量;
(2)模型编码:Transformer 层分析 "Python" 与 "读取 Excel" 的关联,生成包含上下文信息的临时向量;
(3)后处理:对临时向量取平均,得到长度为 768 的向量,并归一化;
(4)输出:最终得到该问题的 Embedding 向量,用于后续检索。
三、Embedding 技术在 RAG 中的应用
RAG 的核心逻辑是 "先检索相关知识,再结合知识生成回答",而 Embedding 技术贯穿了 RAG 的 "知识存储" 和 "知识检索" 两大关键环节,形成完整的技术闭环。
3.1 RAG 中的 Embedding 技术架构
RAG的流程可以简化为"检索" + "生成"。而Embedding是"检索"环节的绝对核心。

1.预处理与索引(Indexing)
(1)将外部知识库(如公司文档、网页)切分成较小的文本块(Chunks)。
(2)使用Embedding模型将每一个文本块转换为一个向量。
(3)将所有向量存储到专门的向量数据库(Vector Database)中,如Pinecone、Chroma、Weaviate等。这些数据库针对高维向量的快速相似性搜索进行了优化。
2.检索(Retrieval)
(1)当用户提出一个问题(Query)时,使用同一个Embedding模型将这个问题也转换为一个向量(Query Vector)。
(2)在向量数据库中,进行最近邻搜索 (Nearest Neighbor Search),寻找与Query Vector最相似的那些文本块向量。相似度通常用余弦相似度(Cosine Similarity)来衡量,它关注的是两个向量在方向上的差异,而非绝对距离。
(3)找到最相关的K个文本块(Context),作为补充信息。
3.增强生成(Augmented Generation)
(1)将用户原始问题(Query)和检索到的相关文本(Context)一起组合成一个详细的提示(Prompt),交给大语言模型(如GPT-4)。
(2)LLM基于这个包含了"事实依据"的Prompt来生成最终答案,从而避免了幻觉(Hallucination),提高了准确性和可信度。
四、Embedding 技术的挑战
尽管 Embedding 技术已成为 RAG 的基础,但在实际落地中仍面临三大核心挑战,同时也在快速演进以解决这些问题。
4.1 三大核心挑战
1.长文本 Embedding 的 "细节丢失" 问题
当前主流 Embedding 模型(如 OpenAI text-embedding-3-small)对文本长度有限制(通常支持 1024/2048 tokens),超过长度的文本需要拆分。但拆分可能导致 "上下文断裂"------ 例如,某段关于 "产品保修条款" 的文本被拆分为两部分,单独生成的向量可能丢失 "保修期限与故障类型关联" 的关键信息,导致检索偏差。
2.领域适配性不足
通用 Embedding 模型(如 Sentence-BERT)在日常文本中表现优异,但在医疗、法律、化工等专业领域效果下降。例如,"肺癌" 在通用模型中可能与 "肺炎" 相似度较高,但在医疗领域,"非小细胞肺癌" 与 "小细胞肺癌" 的差异需要更精准的向量区分 ------ 通用模型无法捕捉这类专业语义。
3.向量计算的 "效率与精度平衡"
当向量数据库中的向量数量达到百万、千万级时,"全量计算相似度" 会变得非常缓慢(如千万级向量全量计算需几秒甚至分钟级)。为提升速度,通常会使用 "近似最近邻(ANN)" 算法(如 FAISS、HNSW),但这会牺牲部分精度 ------ 可能导致 "最相关的知识未被检索到"。
4.2 技术演进方向
针对上述挑战,Embedding 技术正朝着三个方向快速发展:
1.长文本 Embedding 模型:如 Anthropic 的 Claude Embedding、阿里云的 Qwen-Embedding,支持 4096 甚至 8192 tokens 的长文本,减少拆分带来的上下文丢失;
2.领域专用模型微调:通过 "通用模型 + 领域数据微调" 的方式,提升专业场景的语义识别能力。例如,用 10 万条医疗文献微调 Sentence-BERT,得到 "医疗专用 Embedding 模型";
3.向量数据库与模型协同优化:向量数据库(如 Milvus 2.4)通过 "动态索引""混合检索(关键词 + 向量)" 技术,在保证毫秒级检索速度的同时,提升精度,平衡效率与效果。
总结
如果说 RAG 是 "让 AI 拥有外部知识库" 的桥梁,那么 Embedding 技术就是这座桥梁的 "地基"------ 没有它,非结构化知识无法被机器检索,RAG 的 "精准回答" 也无从谈起。从技术本质来看,Embedding 不仅是 "文本转向量" 的工具,更是机器理解人类语言、连接物理世界与数字世界的 "通用语言"。随着长文本模型、领域专用模型的持续演进,Embedding 技术将进一步提升 RAG 的检索精度与适用范围,推动 AI 在企业客服、医疗诊断、法律咨询等专业领域的深度落地。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。