关于llms.txt的讨论热度持续攀升。
但尚未有主流AI平台确认采用该协议。
至少目前如此。
也没有证据表明任何大型语言模型(LLM)在爬取时实际使用该协议。
那么,为何部分SEO从业者和网站所有者已开始将其添加至站点?
因为预计未来几年LLM流量将呈现爆发式增长。
这意味着人工智能模型很快可能成为你最大的流量来源。
请记住:robots.txt文件曾经也是可选的。
如今,它已成为管理搜索爬虫的关键要素。
LLMs.txt文件可能走类似的发展路径------成为引导人工智能访问你最重要内容的标准方式。
在本指南中,你将了解llms.txt文件的工作原理、核心优缺点,以及为网站创建该文件的具体步骤。
什么是LLMs.txt?
LLMs.txt是一个纯文本文件,用于告知AI模型在爬取网站时应优先抓取哪些页面。
该提案标准可使AI系统更轻松地发现、处理和引用您的内容。

具体操作如下:
- 创建名为 llms.txt 的文本文件
- 列出您最重要的页面,并简要描述每个页面的内容
- 将其放置在网站根目录下
- 理论上,LLM 爬虫将利用该文件发现、优先处理并更好地理解您的关键页面
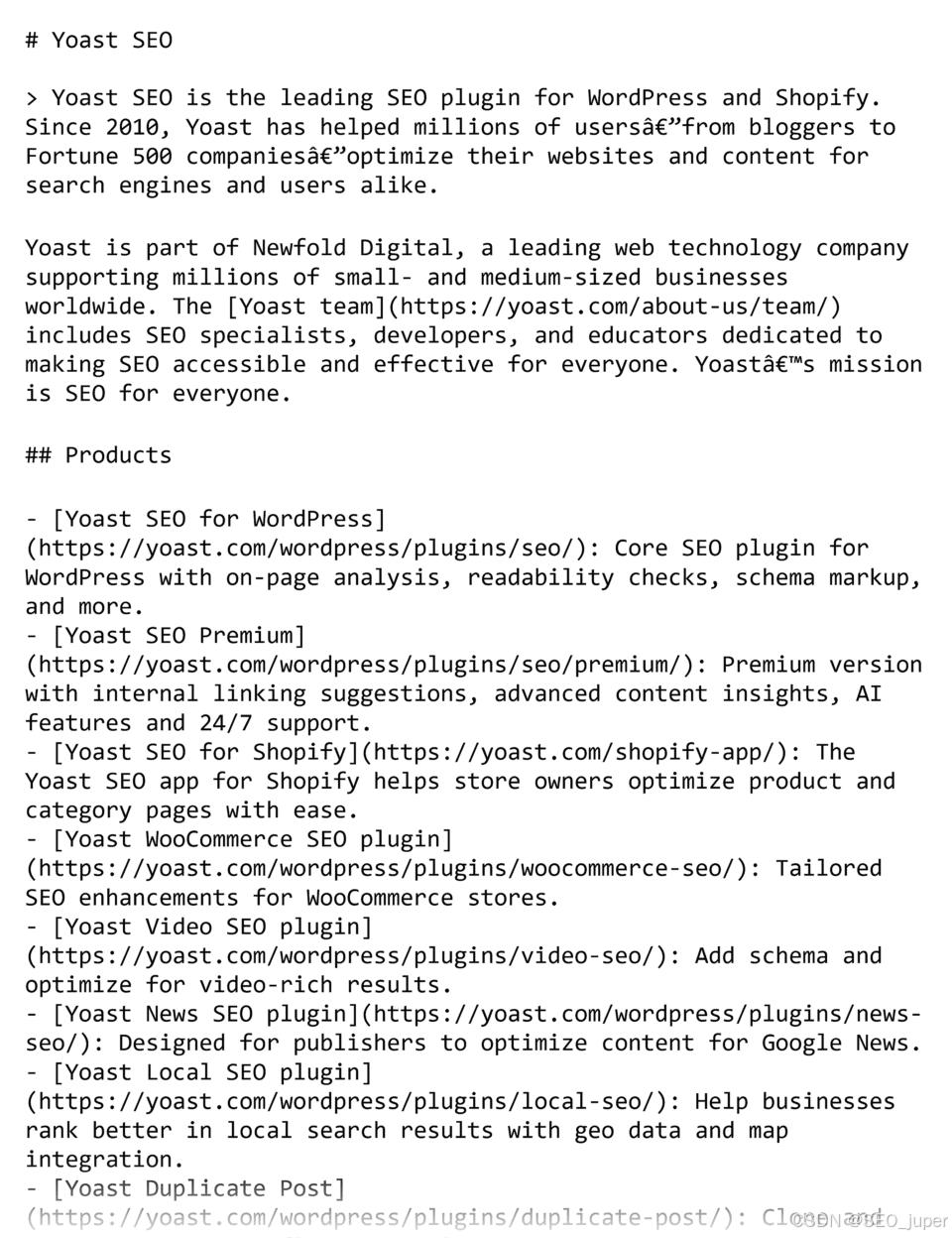
例如,Yoast SEO 的 llms.txt 文件如下所示:
LLMs.txt 会取代 Robots.txt 吗?
简短回答:不会。
它们各自承担不同的功能。
Robots.txt 用于告知爬虫程序在网站上允许访问的内容。
它通过"允许"(Allow)和"禁止"(Disallow)等指令来控制爬取行为。

LLMs.txt文件用于指导AI模型优先抓取哪些页面。
它不控制访问权限------仅提供精选列表。同时能帮助爬虫更轻松地理解您的内容。
例如,您可通过robots.txt阻止爬虫访问管理后台和结算页面。
随后使用llms.txt引导AI系统关注帮助文档、产品页面及定价指南。
以下是完整差异解析:
| 区别 | LLMs.txt | Robots.txt |
|---|---|---|
| 用途 | 为AI模型提供精选的关键页面列表,供其获取信息和来源 | 为搜索引擎爬虫设定抓取和索引规则 |
| 目标对象 | ChatGPT、Gemini、Claude、Perplexity等大型语言模型 | 传统搜索引擎机器人(Googlebot、Bingbot等) |
| 语法 | 基于Markdown格式;可读性 | 纯文本,含特定指令 |
| 执行机制 | 提案标准;主流LLM尚未确认遵循 | 自愿执行;被主流搜索引擎视为标准规范并予以尊重 |
| SEO/AI影响 | 可能影响AI生成的摘要、引用及内容创作 | 直接影响搜索引擎索引与自然搜索排名 |
布局与元素
那么,这个文件里应该放什么内容?又该如何组织结构?
LLMs.txt 应创建为纯文本文件,并采用 Markdown 格式编写。
Markdown 使用简单符号来组织内容结构。
具体包括:
#用于主标题,##用于章节标题,###用于小标题>用于突出显示简短提示--或*用于项目符号列表[文本](https://example.com/page)用于带标签的链接- 三重反引号
(```)用于在文档或博文中标记代码片段

这使得文件既便于人类阅读,也便于AI工具解析。
您可以在这个llms.txt示例中看到主要元素:
bash
# Title
> Description goes here (optional)
Additional details go here (optional)
## Section
- [Link title](https://link_url): Optional details
## Optional
- [Link title](https://link_url)既然您已了解文件格式规范,让我们逐项解析:
- 顶部标题及可选描述:添加您的网站或公司名称,并附上业务简介,为AI系统提供上下文信息
- 带标题的分区:按主题组织内容,如"服务"、"案例研究"或"资源",便于爬虫快速识别文件内容
- 带简短描述的URL:列出需要优先处理的关键页面。使用清晰、描述性强且符合SEO规范的URL,并在每个链接后添加简明描述以提供上下文。
- 可选板块:可添加需AI系统知晓但无需突出的次要资源,如"团队介绍"或"职业机会"
整合所有要素时,可参考以下示例:
网站开发公司BX3 Interactive的llms.txt文件结构如下:

其特点包括:
- 公司名称
- 简要描述
- 关键服务页面列表(含网址及一句话摘要)
- 重点项目与案例研究
- 引用与链接指南
BX3 Interactive还为每个网址提供了目标关键词和特定行动号召(CTA)。

若采用此方案,可规范大型语言模型引用品牌的方式,引导其采用BX3 Interactive偏好的信息传递与措辞风格。
根据网站特性,LLMs.txt文件也可设计得更为复杂。
例如开源平台Hugging Face的示例:
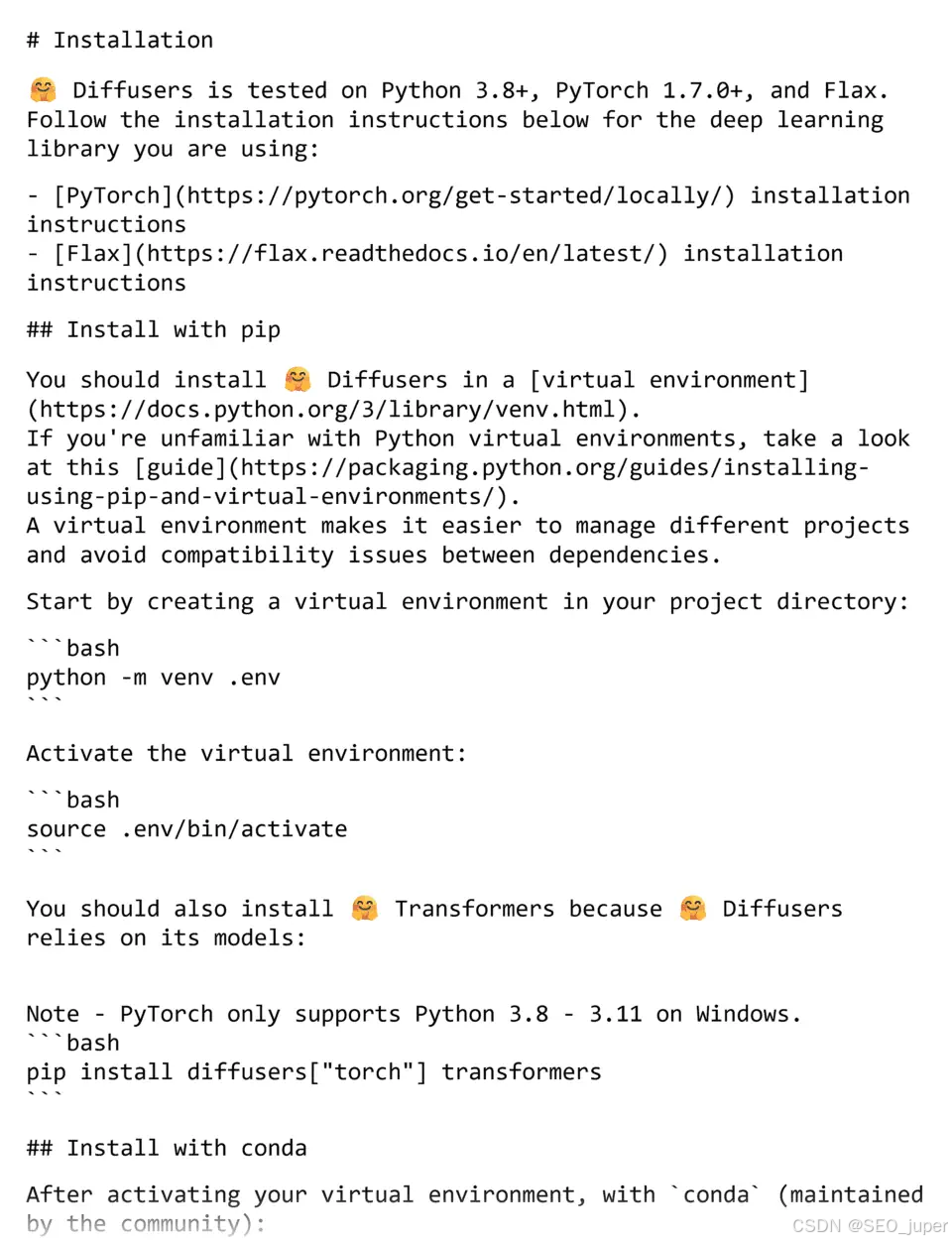
它通过嵌套标题组织数百页内容,形成清晰的层次结构。
但其功能远不止于URL列表和摘要。
它包含:
- 分步安装命令
- 常见任务的代码示例
- 说明性注释和参考资料

这样,AI系统就能直接访问Hugging Face最有价值的文档,而无需爬取每个页面。
这能降低关键细节被遗漏或埋没的风险。
请注意,理想的结构取决于您网站的范围,以及您希望AI理解的信息深度。
LLMs.txt 值得尝试吗?
目前尚无定论。
长期来看,llms.txt 文件或许能提升您的 AI 搜索引擎优化效果。
但这需要广泛普及。
目前尚未有主流 AI 平台正式支持 llms.txt 的使用。
而谷歌态度尤为明确------他们既不支持该文件,也无计划支持。

但像Hugging Face和Stripe这样的大型玩家,其网站上早已存在llms.txt文件。

最值得注意的是,开发Claude的人工智能公司Anthropic,其官网上也发布了llms.txt文件。

如果某家领先的人工智能公司正在使用这些文件,这可能意味着他们认为这些文件未来有望发挥更重要的作用。
最终结论?
将 llms.txt 视为低风险实验,而非提升 AI 可见度的保证方案。
潜在效益
目前这些效益尚属理论层面。
但若 llms.txt 获得广泛采用,您将获得多重收益:
- 掌控引用内容:突出显示您的博客文章、帮助文档、产品页面和政策条款,使 AI 工具优先引用优质页面,而非次要或过时内容
- 简化解析流程:您的 llms.txt 文件为 AI 模型提供简洁的 Markdown 摘要,避免其被迫解析包含导航栏、广告和 JavaScript 的杂乱页面
- 提升AI表现:引导AI模型访问核心价值页面,可能提高其在回复中引用您内容的频率与准确性
- 加速网站分析:通过扁平化站点版本(单一简化文件列出关键页面),无需爬取所有URL即可高效执行关键词分析与站点审计
主要局限与挑战
对llms.txt的质疑具有合理性。
以下是主要担忧:
- 尚未获得官方支持:目前没有主流平台宣布支持此类文件------无论是OpenAI、谷歌、Perplexity还是Anthropic
- 仅为建议而非强制规则:大型语言模型无需"遵守"文件指令,且无法阻止访问特定页面。需要访问控制?请继续使用robots.txt文件。
- 易遭滥用:独立的markdown文件为垃圾信息创造了机会。例如网站所有者可能在文件中堆砌与实际页面内容不符的关键词、内容和链接,本质上是AI时代的关键词堆砌。
- 向竞争对手暴露底牌:详尽的llms.txt文件会向竞争对手提供大量信息,这些信息通常需要专用工具才能获取,包括网站结构、内容缺口、信息传递策略、关键词等。
如何通过5个简单步骤创建LLMs.txt文件
创建LLMs.txt文件非常简单------即使您没有太多技术经验。
需注意:您可能需要开发人员的帮助才能上传该文件。
步骤1:选择高优先级页面
首先选定您希望AI系统优先爬取的页面。
思考哪些常青内容最能体现你的核心业务------包括核心产品页面、高价值指南、常见问题解答、关键政策及定价详情。
例如,BX3 Interactive在其llms.txt文件中将网页开发服务页面列为首位:
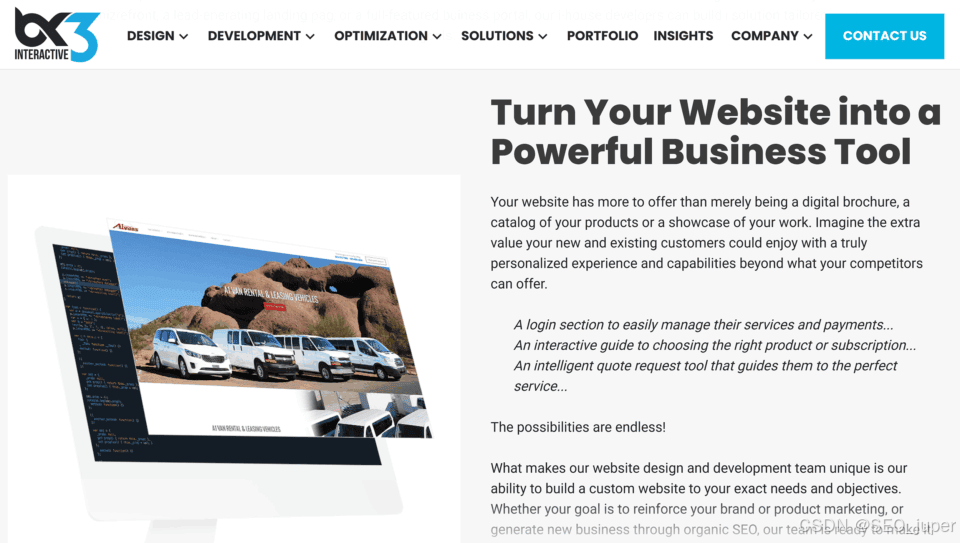
为什么?因为这是他们提供的一项核心服务。
通过在 llms.txt 中突出显示该服务,他们向人工智能爬虫传递了明确信号:该页面是其业务的核心所在。

步骤 2:创建文件
接下来,打开任意纯文本编辑器,创建一个名为 llms.txt 的新文件。
可选编辑器包括记事本、TextEdit(Mac 系统)和 Visual Studio Code。
不熟悉Markdown格式?
请开发人员代劳(如有)。
或让大型语言模型代劳------ChatGPT和Claude可即时生成此类文件。
以下提示供您参考:
使用以下信息创建一个Markdown格式的llms.txt文件:
公司名称:您的公司名称
公司简介:一句说明您的业务内容
重要说明(可选):
-
核心差异化优势或重要细节
-
业务范围说明(包括不涉及的领域)
-
另一项关键要点
产品/服务
- URL: https://yoursite.com/product-1
- 描述: 功能介绍与适用人群
- URL: https://yoursite.com/product-2
- 描述: 功能介绍与适用人群
博客/资源
- URL: https://yoursite.com/blog-post-1
- 描述:读者将学到什么
- 网址:https://yoursite.com/blog-post-2
- 描述:读者将学到什么
公司页面
- 关于我们:https://yoursite.com/about -- 公司背景与使命
- 联系方式:https://yoursite.com/contact -- 联络方式
- 定价方案:https://yoursite.com/pricing -- 套餐概览
请按标准llms.txt格式排版,包含Markdown标题(#, ##)、项目符号(-)及链接语法。
还有一些 llms.txt 生成器可供使用。
例如,Yoast SEO 允许您一键生成包含标记的 llms.txt 文件。
请记住,结构并非一成不变。
包含您最有价值的页面,并附上描述性摘要。
然后根据对贵公司最重要的内容定制布局。
步骤 3:上传文件
llms.txt 文件的存放位置取决于其内容范围。
- 全站通用文件请上传至根目录:https://yoursite.com
- 仅文档相关文件请放置于对应子目录:https://docs.yourdomain.com/llms.txt
后续步骤可能需要开发人员协助。
他们将登录您的主机控制面板,进入public_html文件夹完成文件上传。
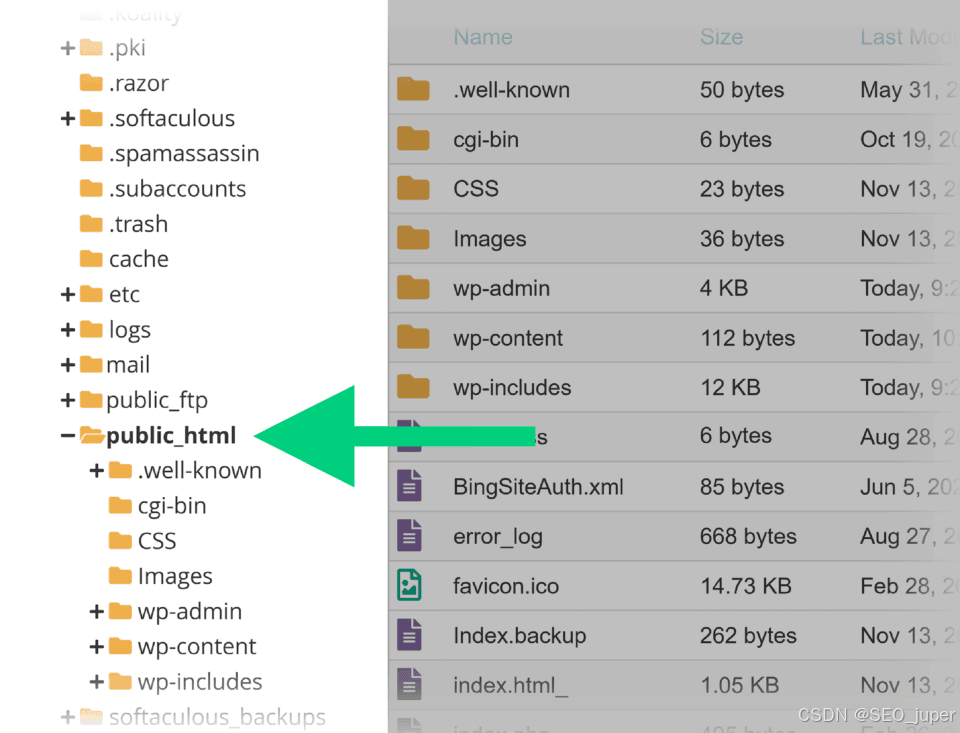
上传完成后,即可开始测试。
步骤4:确认功能正常
打开新标签页,输入 https://yoursite.com/llms.txt。
若看到类似以下内容,则设置成功:

想要更进一步吗?
使用Semrush的网站审计工具验证文件是否可被爬取,并自动检查任何技术问题。
步骤5:保持内容新鲜度
您的llms.txt文件并非设置后即可置之不理。
请每隔数月安排一次内容审查:
- 移除不再代表您最佳作品的过时页面
- 在发布时添加值得重点展示的新内容
这能确保AI系统始终看到您最相关的内容。
是否应在网站上使用LLMs.txt文件?
正如SEO从业者常说的:"这要看情况。"
若设置便捷且您有兴趣尝试,值得一试。
最坏的情况是毫无变化。
最佳情况是,当AI平台开始关注时,您已抢占先机。
与此同时,切勿忽视经实践验证的SEO基础要素。
结构化数据、高权重反向链接和优质内容,正是帮助AI与传统搜索引擎理解、信任并展示您网页的关键。