TL;DR
- 场景:用 Flink DataStream 将用户数据实时落地到 Apache Kudu 表,走自定义 RichSinkFunction。
- 结论:示例能跑通,但存在「逐列 apply」「异步错误未收集」「主键冲突」等工程隐患,需小改。
- 产出:可运行样例 + 版本矩阵 + 错误速查卡。

版本矩阵
| 状态 | 组件版本/场景 | 验证结论 |
|---|---|---|
| ✅ | Flink 1.11.1(Scala 2.12)+ Java 11 + kudu-client 1.17.0 | 本地示例可跑通(2025) |
| ⚠️ | Flink 1.14--1.18 + Java 11/17 + kudu-client 1.17 | API 基本兼容,需检查依赖坐标与打包 shading(尤其 scala 版本一致性) |
| ⚠️ | YARN/K8s 多并发部署 | 需设置 parallelism、checkpoint、幂等策略(建议 Upsert 或去重键) |
| ✅ | Kudu 表 user | 字段:id INT32 主键;name STRING;age INT32 分区:哈希(id,3);副本数1 |
| ⚠️ | 安全与可观测性 | AUTO_FLUSH_BACKGROUND 需显式收集 pending errors;建议接入指标与告警 |

实现思路
将数据从 Flink 下沉到 Kudu 的基本思路如下:
- 环境准备:确保 Flink 和 Kudu 环境正常运行,并配置好相关依赖。
- 创建 Kudu 表:在 Kudu 中定义要存储的数据表,包括主键和列类型。
- 数据流设计:使用 Flink 的 DataStream API 读取输入数据流,进行必要的数据处理和转换。
- 写入 Kudu:通过 Kudu 的连接器将处理后的数据写入 Kudu 表。需要配置 Kudu 客户端和表的相关信息。
- 执行作业:启动 Flink 作业,实时将数据流中的数据写入 Kudu,便于后续查询和分析。
添加依赖
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>flink-test</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<flink.version>1.11.1</flink.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client</artifactId>
<version>1.17.0</version>
</dependency>
</dependencies>
</project>数据源
java
new UserInfo("001", "Jack", 18),
new UserInfo("002", "Rose", 20),
new UserInfo("003", "Cris", 22),
new UserInfo("004", "Lily", 19),
new UserInfo("005", "Lucy", 21),
new UserInfo("006", "Json", 24),自定义下沉器
java
package icu.wzk.kudu;
public class MyFlinkSinkToKudu extends RichSinkFunction<Map<String, Object>> {
private final static Logger logger = Logger.getLogger("MyFlinkSinkToKudu");
private KuduClient kuduClient;
private KuduTable kuduTable;
private String kuduMasterAddr;
private String tableName;
private Schema schema;
private KuduSession kuduSession;
private ByteArrayOutputStream out;
private ObjectOutputStream os;
public MyFlinkSinkToKudu(String kuduMasterAddr, String tableName) {
this.kuduMasterAddr = kuduMasterAddr;
this.tableName = tableName;
}
@Override
public void open(Configuration parameters) throws Exception {
out = new ByteArrayOutputStream();
os = new ObjectOutputStream(out);
kuduClient = new KuduClient.KuduClientBuilder(kuduMasterAddr).build();
kuduTable = kuduClient.openTable(tableName);
schema = kuduTable.getSchema();
kuduSession = kuduClient.newSession();
kuduSession.setFlushMode(KuduSession.FlushMode.AUTO_FLUSH_BACKGROUND);
}
@Override
public void invoke(Map<String, Object> map, Context context) throws Exception {
if (null == map) {
return;
}
try {
int columnCount = schema.getColumnCount();
Insert insert = kuduTable.newInsert();
PartialRow row = insert.getRow();
for (int i = 0; i < columnCount; i ++) {
Object value = map.get(schema.getColumnByIndex(i).getName());
insertData(row, schema.getColumnByIndex(i).getType(), schema.getColumnByIndex(i).getName(), value);
OperationResponse response = kuduSession.apply(insert);
if (null != response) {
logger.error(response.getRowError().toString());
}
}
} catch (Exception e) {
logger.error(e);
}
}
@Override
public void close() throws Exception {
try {
kuduSession.close();
kuduClient.close();
os.close();
out.close();
} catch (Exception e) {
logger.error(e);
}
}
private void insertData(PartialRow row, Type type, String columnName, Object value) {
try {
switch (type) {
case STRING:
row.addString(columnName, value.toString());
return;
case INT32:
row.addInt(columnName, Integer.valueOf(value.toString()));
return;
case INT64:
row.addLong(columnName, Long.valueOf(value.toString()));
return;
case DOUBLE:
row.addDouble(columnName, Double.valueOf(value.toString()));
return;
case BOOL:
row.addBoolean(columnName, Boolean.valueOf(value.toString()));
return;
case BINARY:
os.writeObject(value);
row.addBinary(columnName, out.toByteArray());
return;
case FLOAT:
row.addFloat(columnName, Float.valueOf(value.toString()));
default:
throw new UnsupportedOperationException("Unknown Type: " + type);
}
} catch (Exception e) {
logger.error("插入数据异常: " + e);
}
}
}编写实体
java
package icu.wzk.kudu;
public class UserInfo {
private String id;
private String name;
private Integer age;
// 省略构造方法、Get、Set 接口
}执行建表
java
package icu.wzk.kudu;
public class KuduCreateTable {
public static void main(String[] args) throws KuduException {
String masterAddress = "localhost:7051,localhost:7151,localhost:7251";
KuduClient.KuduClientBuilder kuduClientBuilder = new KuduClient.KuduClientBuilder(masterAddress);
KuduClient kuduClient = kuduClientBuilder.build();
String tableName = "user";
List<ColumnSchema> columnSchemas = new ArrayList<>();
ColumnSchema id = new ColumnSchema
.ColumnSchemaBuilder("id", Type.INT32)
.key(true)
.build();
columnSchemas.add(id);
ColumnSchema name = new ColumnSchema
.ColumnSchemaBuilder("name", Type.STRING)
.key(false)
.build();
columnSchemas.add(name);
ColumnSchema age = new ColumnSchema
.ColumnSchemaBuilder("age", Type.INT32)
.key(false)
.build();
columnSchemas.add(age);
Schema schema = new Schema(columnSchemas);
CreateTableOptions options = new CreateTableOptions();
// 副本数量为1
options.setNumReplicas(1);
List<String> colrule = new ArrayList<>();
colrule.add("id");
options.addHashPartitions(colrule, 3);
kuduClient.createTable(tableName, schema, options);
kuduClient.close();
}
}主逻辑代码
java
package icu.wzk.kudu;
public class SinkToKuduTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<UserInfo> dataSource = env.fromElements(
new UserInfo("001", "Jack", 18),
new UserInfo("002", "Rose", 20),
new UserInfo("003", "Cris", 22),
new UserInfo("004", "Lily", 19),
new UserInfo("005", "Lucy", 21),
new UserInfo("006", "Json", 24)
);
SingleOutputStreamOperator<Map<String, Object>> mapSource = dataSource
.map(new MapFunction<UserInfo, Map<String, Object>>() {
@Override
public Map<String, Object> map(UserInfo value) throws Exception {
Map<String, Object> map = new HashMap<>();
map.put("id", value.getId());
map.put("name", value.getName());
map.put("age", value.getAge());
return map;
}
});
String kuduMasterAddr = "localhost:7051,localhost:7151,localhost:7251";
String tableInfo = "user";
mapSource.addSink(new MyFlinkSinkToKudu(kuduMasterAddr, tableInfo));
env.execute("SinkToKuduTest");
}
}解释分析
环境设置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();:初始化 Flink 的执行环境,这是 Flink 应用的入口。
数据源创建
DataStreamSource dataSource = env.fromElements(...):创建了一个包含多个 UserInfo 对象的数据源,模拟了一个输入流。
数据转换
SingleOutputStreamOperator<Map<String, Object>> mapSource = dataSource.map(...):使用 map 函数将 UserInfo 对象转换为 Map<String, Object>,便于后续处理和写入 Kudu。每个 UserInfo 的属性都被放入一个 HashMap 中。
Kudu 配置信息
String kuduMasterAddr = "localhost:7051,localhost:7151,localhost:7251"; 和 String tableInfo = "user";:定义 Kudu 的主节点地址和目标表的信息。
数据下沉
mapSource.addSink(new MyFlinkSinkToKudu(kuduMasterAddr, tableInfo));:将转换后的数据流添加到 Kudu 的自定义 Sink 中。MyFlinkSinkToKudu 类应该实现了将数据写入 Kudu 的逻辑。
执行作业
env.execute("SinkToKuduTest");:启动 Flink 作业,执行整个数据流处理流程。
测试运行
- 先运行建表
- 再运行主逻辑
我们建表之后,确认user表存在。然后我们运行Flink程序,将数据写入Kudu。 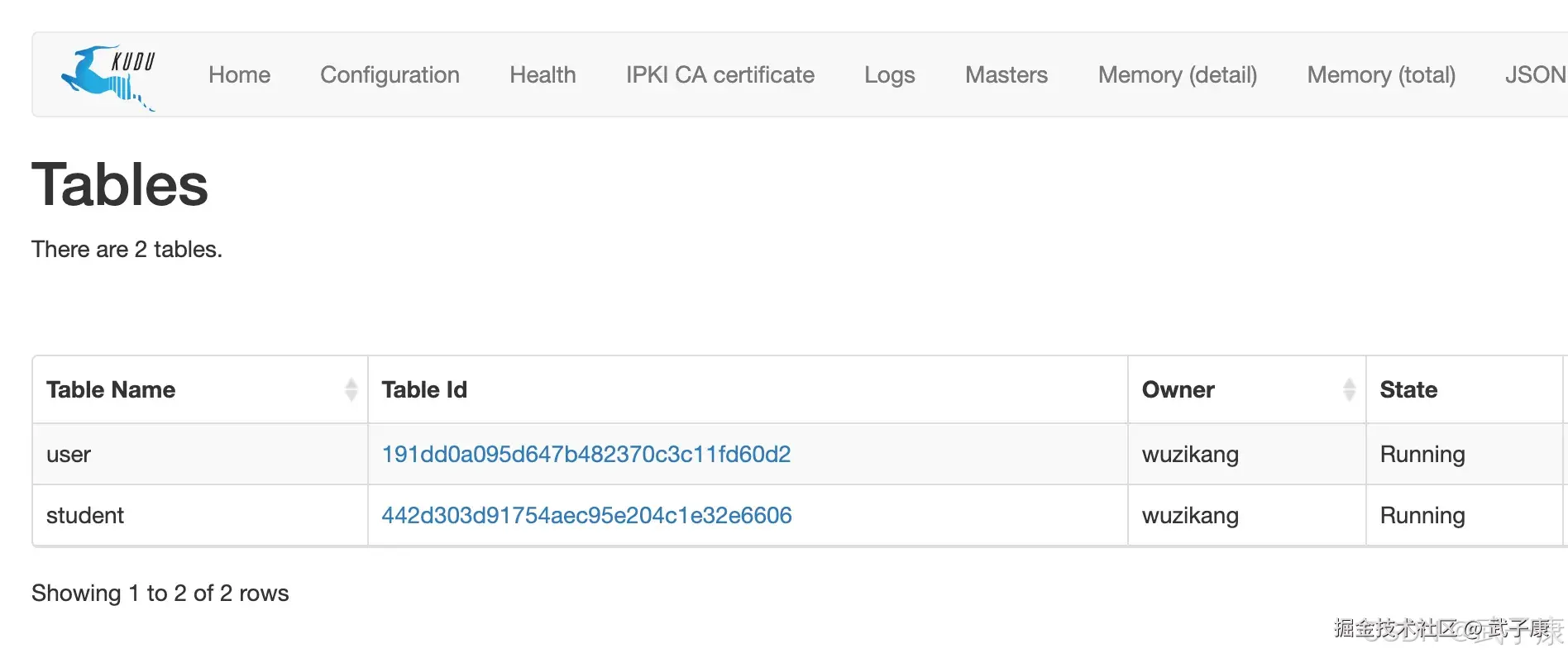 确认有表后,执行 Flink 程序:
确认有表后,执行 Flink 程序: 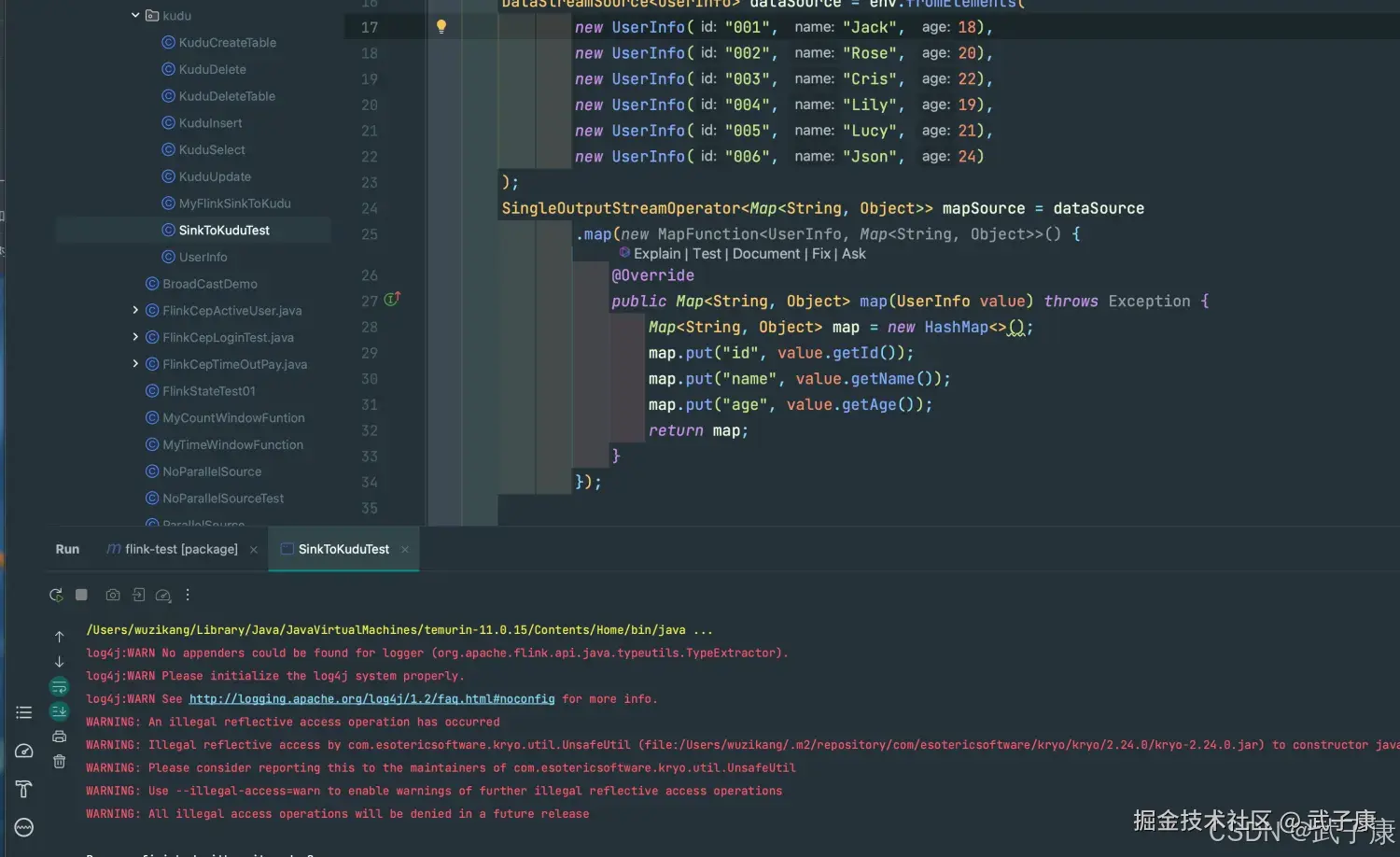
注意事项
- 并发性:根据 Kudu 集群的规模和配置,可以调整 Flink 作业的并发性,以提高写入性能。
- 批量写入:Kudu 支持批量插入,可以通过适当配置 Flink 的 sink 来提高性能。
- 故障处理:确保在作业中处理异常和重试逻辑,以确保数据不会丢失。
- 监控与调试:使用 Flink 的监控工具和 Kudu 的工具(如 Kudu UI)来监控数据流和性能。
错误速查
| 症状 | 根因定位 | 修复方案 |
|---|---|---|
| 提交报 "缺少必需列/重复提交/RowError 混乱" | 逐列循环内就 kuduSession.apply(insert),导致同一行被多次提交 | 查看 Sink invoke 中 for-loop将 apply 挪到列循环外,先填满行再一次提交;必要时 session.flush() |
| 明明失败却没有错误日志 | AUTO_FLUSH_BACKGROUND 返回 null;错误沉淀在 pending 队列 | session.getPendingErrors()周期性拉取 getPendingErrors() 并上报;或切 MANUAL_FLUSH 做批量提交与显式错误处理 |
| 主键冲突(Already present) | 使用 Insert,重复主键直接失败 | Kudu UI/日志 RowError业务允许则改 Upsert;或 setIgnoreAllDuplicateRows(true) 并打补偿日志 |
| NumberFormatException / 类型不一致 | 源数据 id 是 String("001"),Kudu 列是 INT32 | 异常堆栈/字段映射统一类型:要么源用 int,要么 Kudu 列改 STRING;避免前导零丢失 |
| 二进制列写入膨胀/脏数据 | ByteArrayOutputStream 未 reset,对象序列化累积 | 采样行检查/字节长度异常每次写入后 out.reset();避免在热路径使用 ObjectOutputStream 序列化非必要字段 |
| 写入阻塞/背压高 | 会话缓冲/网络瓶颈/单 Tablet 热点 | Flink WebUI、Kudu Tablet 负载合理 parallelism、按分区键打散;setMutationBufferSpace、批量大小调优;优化哈希分区策略 |
| "Table/Column not found" | Map 中 key 与 Schema 列不一致 | 打印 schema.getColumns() 与 map key写入前做 字段映射校验,缺省值或跳过未知列;在编排阶段即生成映射清单 |
| 连接失败/超时 | master 地址/端口不正确,或网络不可达 | Kudu master 日志与端口检查确认 master:7051 列表、DNS 与安全策略;必要时直连 IP 并保证双向可达 |
| 打包冲突(NoSuchMethod / Scala 版本不匹配) | flink 与依赖 Scala 版本不一致 | 运行期异常统一使用 _2.12 工件;Maven 统一 scala.version;必要时 shading 隔离 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解