文章目录
- [1 TimeLLM 释义:将语言模型用于时间预测](#1 TimeLLM 释义:将语言模型用于时间预测)
-
- [1.1 TimeLLM 的核心思想是什么?](#1.1 TimeLLM 的核心思想是什么?)
- [1.2 时间序列如何重编程为语言兼容格式?](#1.2 时间序列如何重编程为语言兼容格式?)
- [1.3 相较最先进模型,TimeLLM 实际表现如何?](#1.3 相较最先进模型,TimeLLM 实际表现如何?)
- [2 LLM 上场:用 Nixtla 实现 TimeLLM](#2 LLM 上场:用 Nixtla 实现 TimeLLM)
-
- [2.1 用例概览:M5 销售预测](#2.1 用例概览:M5 销售预测)
- [2.2 如何用 Nixtla 生态实现 TimeLLM?](#2.2 如何用 Nixtla 生态实现 TimeLLM?)
- [2.3 TimeLLM 表现如何?](#2.3 TimeLLM 表现如何?)
- [3 关键要点](#3 关键要点)
- [4 参考文献](#4 参考文献)
摘要:本文深入探讨将大型语言模型(LLM)用于时间序列预测的理论基础与实践实现,核心围绕 TimeLLM:通过"重编程"把连续数值序列转换为语言兼容的提示,从而在不微调 LLM 的情况下进行预测。文章系统解释输入嵌入、补丁(patch)重编程、提示(Prompt-as-Prefix)与输出投影,并以 Walmart M5 数据集的销售预测为用例,通过 Nixtla 生态的实现展示流程与效果,同时与经典统计模型和深度学习基线进行对比,指出 TimeLLM 在少样本与零样本场景下的优势与局限、容量与提示工程对性能的影响,以及在生产环境中与任务特定模型的取舍。整体结论是:TimeLLM 提供跨域快速原型与数据稀缺时的强大弹性,但在信号弱、上下文短或缺乏结构化统计信息时,传统方法与专用深度模型仍更高效准确。
本文探讨如何将大型语言模型(LLM)应用于时间序列预测,重点关注 TimeLLM------一种将语言建模技术用于时间数据的模型。我们同时深入其理论基础与 Nixtla 生态中的实践实现。方法论通过一个具体用例加以说明:在 M5 竞赛数据集上进行销售预测,这是一组覆盖数千商品与门店的 Walmart 每日销售数据。
读完本文,你将理解:
- TimeLLM 如何改造语言模型来解决时间序列预测?
- 相较其他经典方法,它的性能如何?
- 如何在实践中应用这些模型以提供快速且准确的时间序列预测?
代码见 GitHub。
1 TimeLLM 释义:将语言模型用于时间预测
1.1 TimeLLM 的核心思想是什么?
LLM 已不局限于自然语言。在计算机视觉与代码生成等领域,它们如今作为强大的通用骨干,优于任务特定模型。这一跨域成功为时间序列预测带来一个及时的问题:能否将 LLM 的模式识别与推理能力用于时间数据?
时间序列与语言同为序列性质,但在结构与编码上不同。关键挑战是对齐这些模态,使 LLM 能有效处理时间序列,同时无需修改模型本身。
这正是 TimeLLM 的核心思想,提出于 "Time-LLM: Time Series Forecasting by Reprogramming Language Models" [5](https://arxiv.org/abs/2505.02583?utm_source=tldrai)。作者不重设计架构,而是重编程输入:将时间序列转为类似自然语言提示的 token 序列。此举让像 GPT-2 这样的预训练语言模型可直接用于预测,利用其丰富先验与泛化能力。
1.2 时间序列如何重编程为语言兼容格式?
流程包含以下关键步骤:
1. 输入嵌入(Input Embedding): 首先将连续时间序列数据转换为紧凑的补丁(patch)表示。每个时间序列先用 RevIN 归一化(零均值、单位方差)以应对分布漂移 [8](https://www.youtube.com/watch?v=6sFiNExS3nI),随后切分为补丁------相邻值组成的重叠或非重叠窗口。
Original series(T = 8): 95, 96, 97, 98, 100, 99, 98, 97
补丁长度(Lp)= 4
补丁:_
补丁 1:95, 96, 97, 98
补丁 2:100, 99, 98, 97_
嵌入维度(dm)= 3
补丁嵌入:_
补丁 1:0.2, 0.3, 0.4
补丁 2:-0.3, -0.2, -0.1_
每个补丁线性嵌入为维度为
_d m_的向量,得到补丁嵌入。
2. 补丁重编程(Patch Reprogramming): 下一步是将时间序列嵌入的结构与语言模型的表示空间对齐。做法是将每个补丁(序列的短片段)转换为语言式表示的组合。TimeLLM 不重新训练模型,而是从 LLM 现有词汇中选取一小组原型,诸如 "up""down""steady"等反映常见时间序列模式的词。然后将每个补丁与这些原型匹配。例如:
- 下降的补丁可能变为 "short down"
- 稳定的补丁可能是 "steady flat"
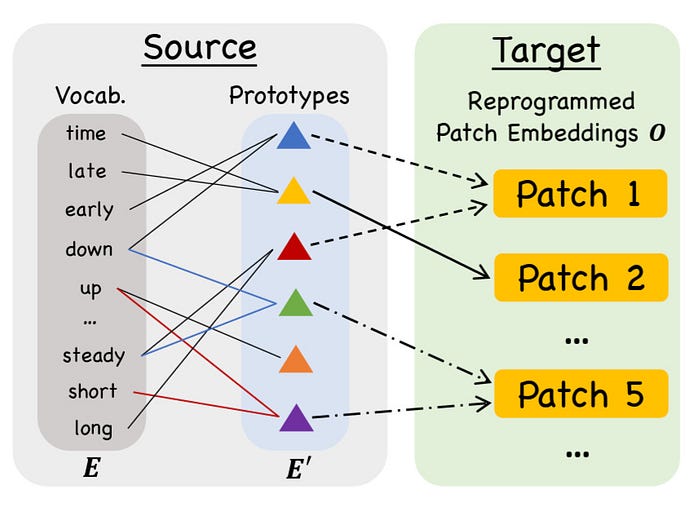
图 1 ------ 补丁重编程示意,源自原论文 3
该转换使用注意力选择最相关原型,将数值数据变为 LLM 可自然处理的"句子"。通过这种重述,TimeLLM 让冻结的语言模型无需架构更改即可进行预测。
重编程输出:_
补丁 1:0.2, 0.3, 0.4 → "steady up"
补丁 2:-0.3, -0.2, -0.1 → "slow down"_
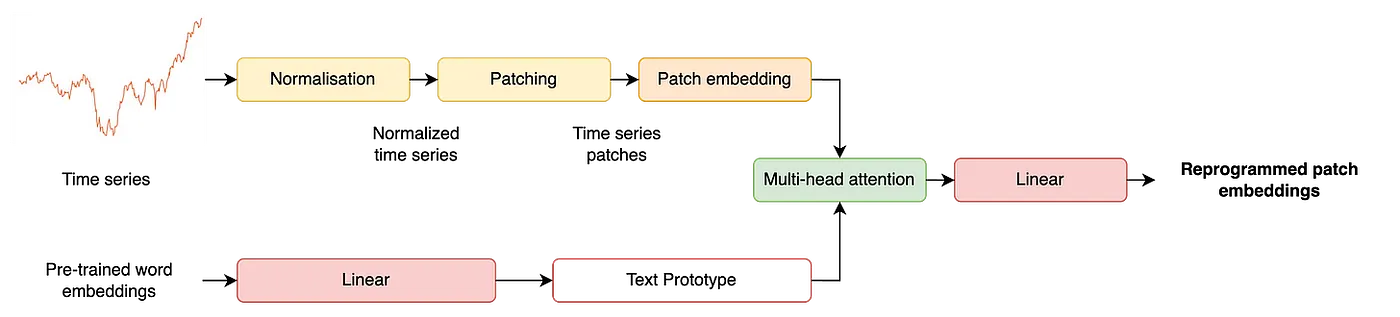
图 2 ------ 重编程后的补丁嵌入,灵感源自原论文 [3](https://arxiv.org/abs/2310.01728)
3. 提示(Prompting): 下一步是构建 LLM 能自然处理的提示。TimeLLM 采用 Prompt-as-Prefix(PaP)策略而非 Patch-as-Prefix,以更好地与模型的预训练格式对齐。
- Patch-as-Prefix: 直接将过往时间序列值翻译为自然语言,并附加文本指令让 LLM 预测。例如:
"每周销售额为:234.5, 238.0, 231.2, 229.8。预测接下来 3 个值。"
该方法面临挑战:
- LLM 对数字的分词不一致(如 238.0 可能被拆为 '2', '38', '.', '0',取决于分词器)。
- 缺乏语义结构与统计支撑。
- 难以扩展到长输入或高精度预测。
Prompt-as-Prefix(PaP): 通过结构化元数据与重编程的补丁嵌入丰富提示,避免上述限制。其格式类似:
M5 数据集包含美国 Walmart 门店的数千商品每日销售记录。每条记录包含商品级销售、日历信息与事件标记。以下是输入时间序列的信息:
_BEGIN DATA
Domain:美国某 Walmart 门店的单个商品每日销售。
Instruction:给定此前 天数据,预测未来 天销售。
Statistics:输入最小值为 <min_value>,最大值为 <max_value>,中位数为 <median_value>,整体趋势为 。前五个滞后为 。END DATA_
4. 输出投影(Output Projection):
我们已经看到如何用重编程补丁与精心设计的提示将时间信息输送给 LLM。那么模型输出如何转为可用预测?
当提示与补丁嵌入通过冻结的 LLM 后,模型会生成一段隐藏表示。仅最后部分(对应序列的延续)用于预测。
其余输出被扁平化并通过线性投影层,转换为实值预测。此步骤完成解码过程,将 LLM 的抽象表示变为可解释、可操作的时间序列预测。
⚠️ 重要说明: TimeLLM 不对 LLM 进行微调。语言模型(如 GPT-2)在训练中完全冻结,其权重不更新。预测通过学习轻量模块来实现,这些模块把输入(如补丁嵌入与提示)重编程为 LLM 可处理的格式。此法在零样本式预测与少样本学习之间搭桥,利用预训练的推理能力而无需昂贵再训练或参数更新。
1.3 相较最先进模型,TimeLLM 实际表现如何?
学习框架
Time-LLM 的评估覆盖全面基准与场景,包括长期与短期预测、少样本(仅 5--10% 训练数据)与零样本跨域迁移。
数据集
模型在广泛认可的数据集上测试,如 ETT(ETTh1、ETTm1 等)、Weather、Traffic、Electricity(ECL)、ILI、M5,使用标准指标包括 MSE 与 MAE。
模型
比较对象包含经典与近期 SOTA 模型,如基于 Transformer 的基线(PatchTST、FEDformer、Informer)以及近期 LLM 方法(GPT4TS、LLMTime)。重要的是,比较遵循既有工作的统一评估协议以确保一致性。
结果
报告显示在零/少样本设置尤其强且一致的表现,但"Time-LLM 持续以大幅优势超越 SOTA"这一说法需审慎理解。
-
在特定低数据场景下,改进幅度确实可观,报告称 MSE 最多提升 33%,零样本场景平均提升 14.2%。
-
但许多增益依赖情境:当训练数据稀少最明显;在充分监督下则不那么突出。
-
虽然 LLM 骨干冻结,重编程组件仍在训练,这意味着方法并非端到端严格零样本。
-
此外,相较针对速度与资源约束优化的领域专用架构,模型效率与可扩展性仍有权衡。
因此,尽管结果验证了 LLM 在预测中的潜力,它们并未在所有条件下完全取代任务特定模型。后续章节的实验进一步支持此点。
2 LLM 上场:用 Nixtla 实现 TimeLLM
2.1 用例概览:M5 销售预测
关于数据
为比较 TimeLLM 性能,选用 M5 数据集作为真实世界基准 [12](https://www.kaggle.com/competitions/m5-forecasting-accuracy/data)。
数据按门店聚合,以 14 天视界预测门店每日营业额,共 10 个门店、各自 1,990 个观测。该设置模拟了常见商业场景:在历史长度有限的情况下,为多个小型时间序列做准确的短期预测。
虽然原始 M5 竞赛重点在商品层级并进行层次化协调,但有若干关键要点:最有影响的策略包括在相关序列间共享学习、整合外生变量如日历事件,以及混合架构的强劲表现。混合架构将统计方法的结构与神经网络的适应性融合,以捕捉可预测模式与复杂动态 [11](https://www.sciencedirect.com/science/article/pii/S0169207021001874)。
问题陈述
任务是在历史销售与外部事件特征的基础上,预测未来 14 天的门店级营业额。每个门店的序列在目标值上独立,但在适用范围内共享表示与时间结构。
学习与评估框架
评估中,每个时间序列的最后 14 天作为测试集,确保模型仅从过去数据学习。简单的留出法优先于交叉验证,后者在序列较短时不太实用。
模型性能用 MAPE(平均绝对百分比误差)评估,提供与尺度无关的准确度度量。
基线模型
为将 TimeLLM 的表现置于上下文中,我们与两类模型比较:传统统计方法与现代深度架构。
✔ 统计模型
- AutoARIMA:用 AIC 最小化自动选择 ARIMA 参数,捕捉线性自回归、差分与移动平均成分。
- AutoETS:自动拟合指数平滑模型,包含水平、趋势与季节性成分。对短期规则模式特别强。
- AutoCES(复杂指数平滑):ETS 的推广,旨在更好处理非线性与复杂季节性,通过乘加方式建模成分交互。
- MSTL(多季节-趋势分解 + Loess):STL 的扩展,支持多季节模式(如每周与每年),并以非参数方式平滑趋势。对零售与网页流量尤为有效。
- Theta:简洁但强力,将序列分解为 theta 线并结合线性与指数成分外推。曾是 M3 预测竞赛的获胜模型。
✔ 深度学习模型
- NHITS:可解释的深度架构,学习跨不同时间尺度的分层残差块。聚焦局部水平结构,长视界预测表现优良。
- NBEATS:纯深层前馈架构,使用前后残差栈。不需季节或趋势先验,适配多领域。
注意:两种深度模型使用分位数损失以支持概率预测,置信水平 90%。此外,它们丰富了动态外生变量(如节假日与事件指示),这些因素已知会影响门店营业额。
2.2 如何用 Nixtla 生态实现 TimeLLM?
Nixtla 通过 neuralforecast 库提供与 PyTorch Lightning 兼容的实现,使数据科学家像训练其他预测模型一样训练 TimeLLM。
1. 预测设置
这些参数定义历史输入在进入 LLM 前的结构:
h:预测视界(本文为 14 天)。input_size:模型回看过去的时间步数。patch_len:每个时间序列片段(补丁)的长度。stride:补丁间步长(控制重叠)。
2. LLM 与提示配置
提示使数值模式与 LLM 的预训练分布更好对齐。
llm:所用预训练语言模型(如'gpt2'、'gpt2-medium')。d_llm:LLM 隐状态维度(如 GPT2 为 768、GPT2-medium 为 1024)。prompt_prefix:可选的自然语言提示,描述预测任务与数据上下文。
3. 重编程架构
定义数值输入如何转为 LLM 的文本式嵌入。
d_model:补丁到原型嵌入的内部维度。d_ff:补丁编码器前馈层的隐藏维度。n_heads:交叉注意力层的注意力头数量。top_k:选作原型的 LLM token 嵌入数量。
4. 训练参数
控制围绕 LLM 的轻量组件的学习过程。
batch_size、valid_batch_size、windows_batch_size:训练与验证的批大小。learning_rate:重编程层优化的学习率(默认1e-4)。max_steps:最大训练迭代(如 500--1000)。dropout:正则化的丢弃率。loss:损失函数(如MAE()、MQLoss(level=[90]))。val_check_steps:验证频率。
6. 其他控制
为有效训练 TimeLLM 提供额外灵活性与稳定性。
scaler_type:输入归一化方法('robust'、'minmax'等)。early_stop_patience_steps:无改进时提前停止。start_padding_enabled:为短序列启用左填充。step_size:采样训练窗口的步长。random_seed:可复现的随机种子。
更多信息见 Nixtla 文档 [7](https://nixtlaverse.nixtla.io/neuralforecast/models.timellm.html)。
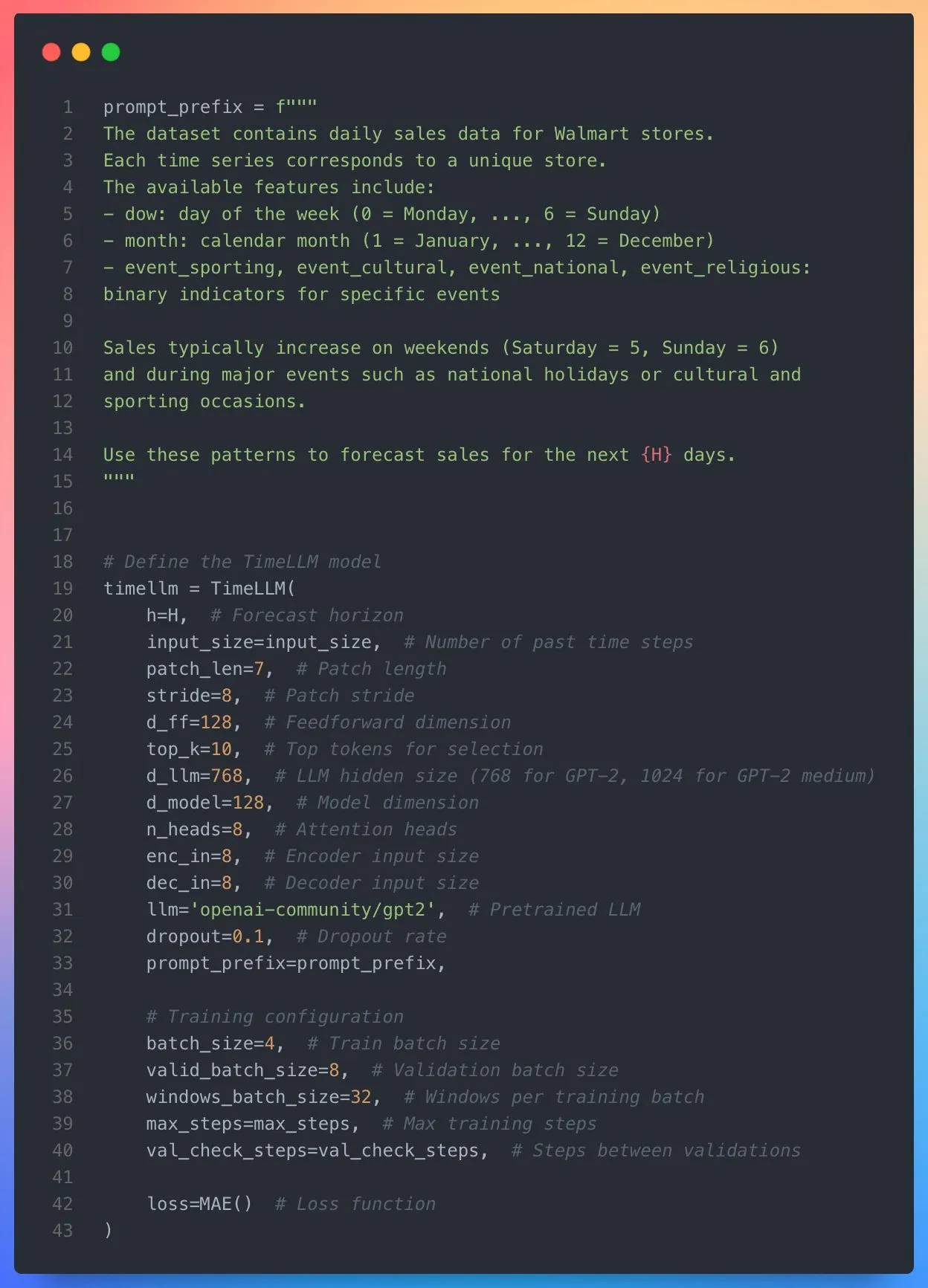
图 3 ------ TimeLLM 的提示配置与模型初始化
定义模型后,可通过 NeuralForecast 框架进行训练与预测。fit() 在历史数据上训练模型,并以 10 个过去窗口的保形方法校准 90% 预测区间。随后 predict() 生成未来 14 天的点预测与不确定性区间。
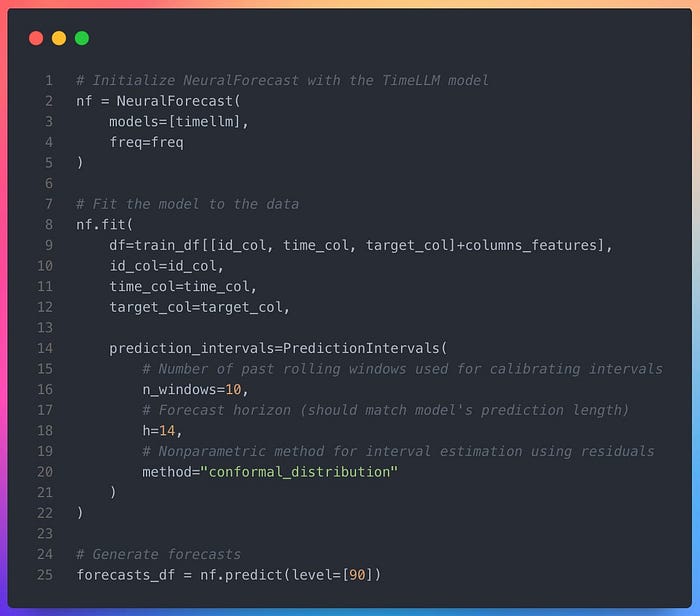
图 4 ------ 使用 NeuralForecast 训练与预测 TimeLLM
训练时的日志总结了 TimeLLM 的结构。GPT-2 骨干(llm)保持冻结(eval 模式),有 1.24 亿不可训练参数;其余 5400 万可训练参数属于轻量重编程模块。多数可训练参数集中在 mapping_layer,该层将 LLM 输出转为可预测表示。patch_embedding、reprogramming_layer 与 output_projection 负责将时间序列补丁转为对齐 LLM 空间的嵌入。模型总计约 1.78 亿参数,体量约 713 MB,可在常规硬件上运行。
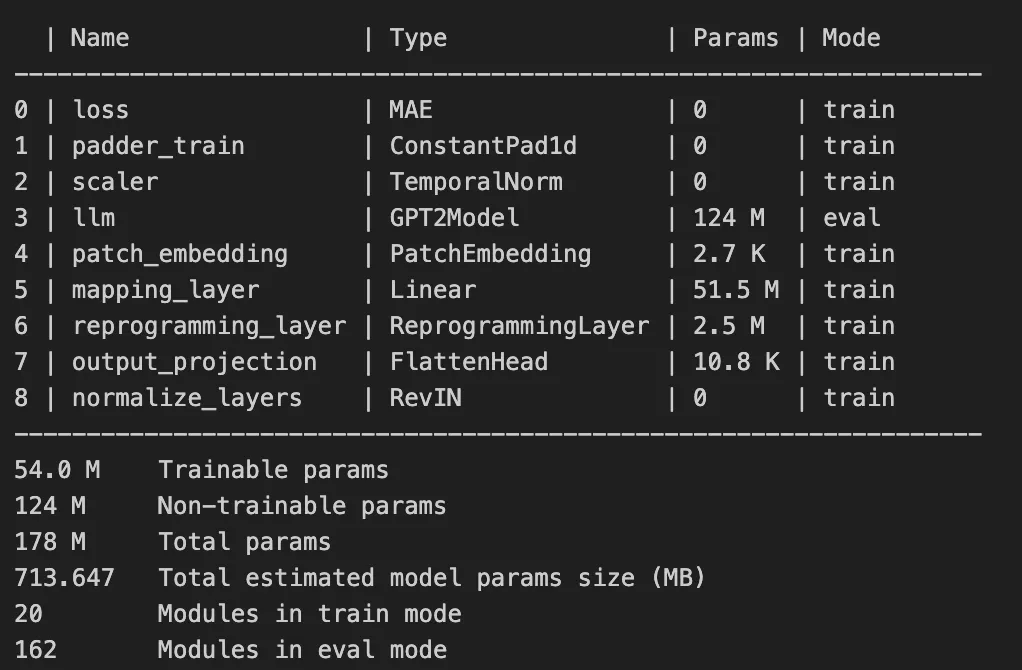
图 5 ------ TimeLLM 训练的模型摘要日志
2.3 TimeLLM 表现如何?
基于门店级预测的实证结果
在以 M5 数据集(门店聚合、14 天视界)为基础的评估中,TimeLLM 的表现显著弱于经典与深度基线。NBEATS 与 NHITS 的 MAPE 约在 7--8%,统计模型如 AutoETS 达到 8--9%,而 TimeLLM 的 MAPE 约为 12.8%。
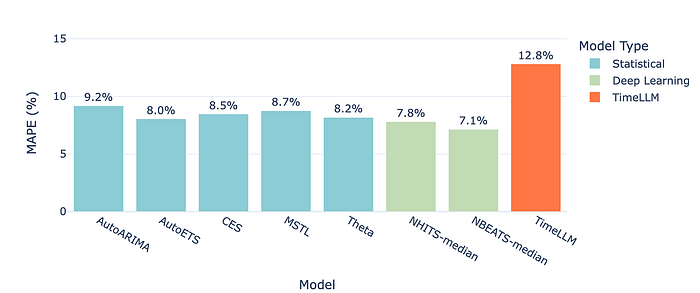
图 6 ------ 各模型的 MAPE(平均绝对百分比误差)比较
从可视角度看,TimeLLM 的预测过于平滑,未能反映已知的季节性动态(如周末需求飙升或事件驱动峰值)。输出常回归到历史均值,表明对日历效应缺乏响应,即使这些以二元标记形式纳入输入。
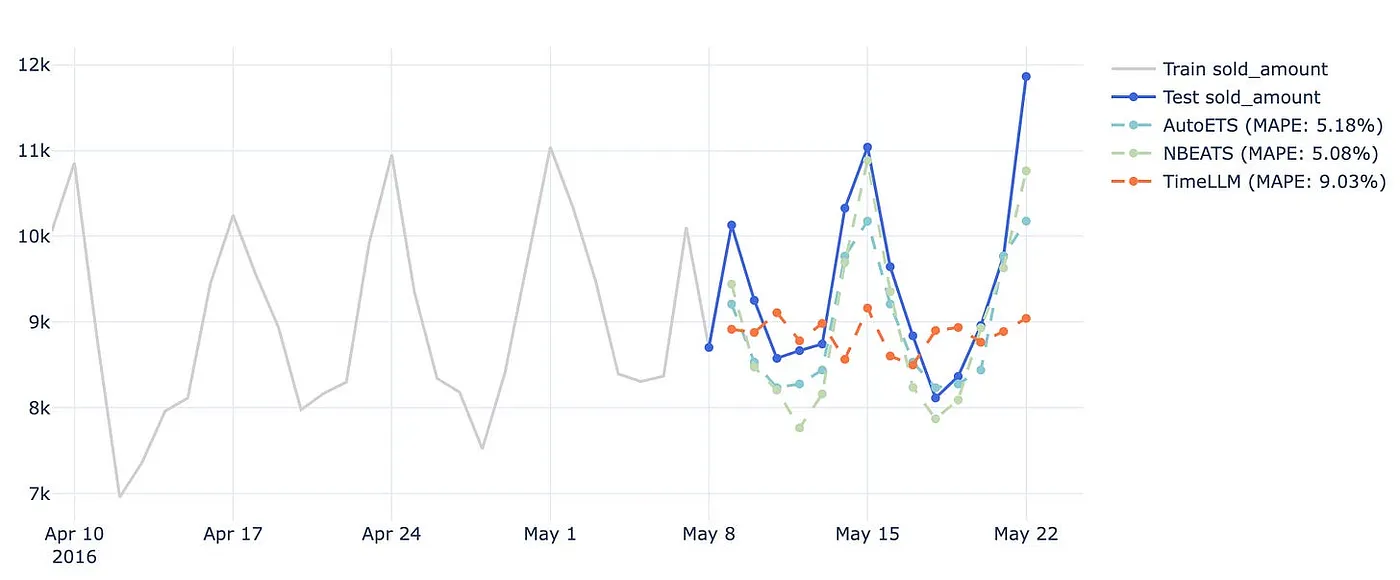
图 7 ------ 单一门店的预测例:真实值 vs 预测值
这种行为更像朴素或指数平滑基线,而非面向模式感知泛化的模型,与原始论文报告的高性能形成鲜明对比。
理解与原论文的差异
在初始论文 "TIME-LLM: Time Series Forecasting by Reprogramming Large Language Models" [3](https://arxiv.org/abs/2310.01728) 中,模型在多类长程预测任务上持续优于深度与 Transformer 方法。根据表 12 [3](https://arxiv.org/abs/2310.01728):
- TimeLLM 在季度与年度数据上取得最低 SMAPE 与 MASE。
- 在平均 OWA 上排名第一(0.86),优于 PatchTST、FEDformer 与 DLinear。
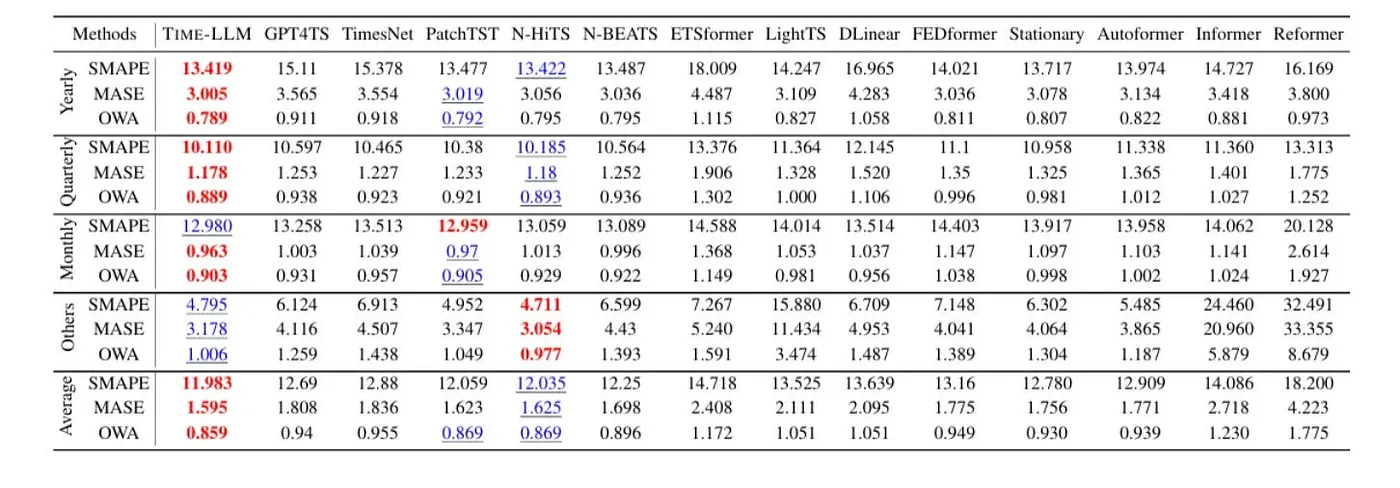
然而,这些增益出现在具有较强趋势/季节信号、输入长度 96--512 步的场景,且常在少/零样本配置中评估。
若干设计省略可能导致本文实验中的欠佳表现:
- 模型容量受限:本文实验用 GPT2-small(1.17 亿参数),而论文依赖如 LLaMA-7B 或 GPT-4 的大规模 LLM。小模型缺乏抽象能力以跨复杂时间模式泛化。
- 缺乏结构化提示工程:所用提示虽以自然语言描述日历效应,但缺少重要统计上下文,如趋势斜率、最值、中位数或自相关滞后等,这些在原论文中至关重要。
- 输入序列较短:原基准的输入多为 96--512 步,本文仅用 30--60 步,限制了 LLM 检测并推理季节周期的能力。
- 无分解或重格式化:数据以原始数值形式输入,未进行趋势或季节分解,这会移除有用的归纳偏置并阻碍 LLM 聚焦于有意义的变化。
- 无输入释义 :正如 "Time Series Forecasting with LLMs: Understanding and Enhancing Model Capabilities" [2](https://www.notion.so/Virtual-Env-Pipenv-89e76a975a384762ae9ddddb7e86e96d?pvs=21) 所述,将输入重述为自然语言(如"销售从 180 降至 140")显著提升性能;本文未采用。
- 学习范式不匹配:TimeLLM 设计用于零/少样本泛化。本文在完整数据上仅训练 40 步,这与预训练 LLM 的基本性质不匹配。
因此,模型明显欠佳,未展现原论文所强调的泛化能力。
与更广泛文献的对齐
然而,这些发现与 "Time Series Forecasting with LLMs: Understanding and Enhancing Model Capabilities" [2](https://www.notion.so/Virtual-Env-Pipenv-89e76a975a384762ae9ddddb7e86e96d?pvs=21) 中概述的局限一致,该文对 LLM 方法持更批判视角。文中指出,无论 GPT-4、Gemini 或 LLaMA-2,LLM 仅在高度结构化条件下具有竞争力。
作者观察到:
- 强结果 仅出现在季节与趋势信号强的数据集(如 MonthlyMilk、AirPassengers)。
- 泛化较差 在短或不规则数据集(如 Sunspots、HeartRate),MAPE 常超过 300%(见该文表 3)。
- 显著增益 仅当输入序列重述为自然语言或纳入外部统计知识时出现。
我们的 M5 设置与这些较弱情形对齐:中等季节性、对事件敏感、上下文有限且无输入重述。缺少输入到文本的转换或分解统计极可能导致泛化不足。尤其是,模型未能从二元事件指示中恢复或放大信号------当外部知识缺失时,两篇论文都指出了这一问题。
3 关键要点
✔ TimeLLM 通过将数值序列转为语言式提示,使冻结的 LLM 在不改动核心模型的前提下进行时间预测。
✔ 模型在零/少样本场景闪耀,原论文报告在训练数据稀缺时 MSE 可最多提升 33%。
✔ 创新在于重编程:通过补丁与提示工程将时间数据与 LLM 的输入预期对齐------无需微调。
✔ 然而,TimeLLM 相比经典甚至深度模型更耗资源。尽管不训练 LLM,本体周围架构的训练与推断仍需相当算力与内存。
最终思考:当数据稀缺、灵活性关键或需跨域快速原型时,TimeLLM 是强选;在生产级或资源受限环境中,任务特定模型往往更高效更准确。
4 参考文献
1 Congxi Xiao, Jingbo Zhou, Yixiong Xiao, Xinjiang Lu, Le Zhang, Hui Xiong, TimeFound: A Foundation Model for Time Series Forecasting, arXiv
2 Hua Tang, Chong Zhang, Mingyu Jin, Qinkai Yu, Zhenting Wang, Xiaobo Jin, Yongfeng Zhang, Mengnan Du, Time Series Forecasting with LLMs: Understanding and Enhancing Model Capabilities, arXiv
3 Jin, M., Wang, S., Ma, L., 等 (2023), Time-LLM: Time Series Forecasting by Reprogramming Large Language Models, arXiv
4 Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, Jingbo Shang, Large Language Models for Time Series: A Survey, arXiv
5 C. Liu, S. Zhou, Q. Xu, H. Miao, C. Long, Z. Li, R. Zhao (2025), Towards Cross-Modality Modeling for Time Series Analytics: A Survey in the LLM Era, arXiv
6 T. Kim, J. Kim, Y. Tae, C. Park, J. Choi, J. Choo (2022), *Reversible Instance Normalization for Accurate Time-Series Forecasting against Distribution Shift,* ICLR 2022, Paper with code
7 Nixtla, TimeLLM documentation
8 Ming Jin, Time-LLM: Time Series Forecasting by Reprogramming Large Language Models, MLLM Talk, Youtube
9 Adrien Nav, *TimeLLM ------ 时间序列预测模型,* Youtube
10 Marco Peixeiro, Time-LLM: Reprogram an LLM for Time Series Forecasting, Medium
11 S. Makridakis, E. Spiliotis, V. Assimakopoulos, *M5 accuracy competition: Results, findings, and conclusions,* ScienceDirect
12 Kaggle, M5 Forecasting