个人理解:
- 关于编程
- 没有代码基础也能编码,入门更容易
- 虚拟环境下,大模型未能检测到环境,无法完成自我验证
- 功能实现不完善,使用标准IDLE环境编程的效率较低 -- 考虑使用专门的开发IDE实现(工欲善其事,必先利其器)
- 只包含了基本功能测试,对核心的图像加载 + 文字识别的特殊用例覆盖较少,测试覆盖不全面 -- 测试步骤的实现仍需要单独处理
- 然而如果需更快速的完成程序实现,更高效的识别代码中的问题,不断迭代,必要的代码基础和架构理解会帮助开发者事半功倍,进阶不易
- 软件工程中的最佳实践仍在发挥着巨大的作用,软件开发流程、软件开发过程仍在帮我们高效、高质的的完成项目开发任务,只是迭代的周期更短、响应的速度更快
- 小(型)的、面向日常业务的工具在AI的辅助下得以快速的开发、使用,方便、适用、个性化,脚本成为普遍
- 小程序的质量在开发之初可能不再是考虑的关键,快速、有效的解决问题成为了首选;然而随着工具的传播和叠加使用,质量问题将会突出(功能性、易用性),扎实的软件工程基础会帮助我们在利用AI之初就有所规划
- AI做事与工做事一样,会犯错、会犯迷糊、会说谎话、会胡编乱造,因此对AI输出结果的判断需要对软件工程、软件需求、软件开发技能充分的了解
- 如果只给出创意(需求)草图(手绘),AI是否能够对图进行解析,梳理需求、完善细节呢?或者通过一段视频,AI是否能够对视频进行文字描述,归纳总结,如果涉及流程,AI能够进行分解、优化、再整合?也就是AI能像人类一样通过5感,甚至是第6感,进行反馈和响应?
- AI遵守规则,不会像人一样迂回、设陷、扯皮?
重新梳理程序(Python + OCR)实现过程
- 遗留:暂且实现一版,后续持续改进,用AI编码
本计划一次性完成,在与AI的交互中反复变更需求,从GUI到功能细节实现(更深刻的理解需求是软件工程中的始点,也是最繁琐的阶段过程);
AI在编码实现中的确可以提效(直接获取答案),但提交结果的验证、测试仍是一个持续的过程;
在没有使用AI IDE开发平台,只借助AI工具情况下,与AI工具的磨合持续进行,如何更好的使用AI?
-
细节是否可以用表格形式?如对象、属性、动作
-
图像局部选择
-
程序测试
-
AI编程的实现:需求 -- 大纲 -- 细节 -- 编码 -- 测试
-
让AI美化GUI界面设计
-
Deepseek-OCR能通过图识别需求并完成程序吗?
目的:熟悉AI编码 + 完善程序OCR程序
-
开发需求
-
界面设想
-
AI提问1(需求预研)
Python313(UV) + PyQT + PaddleOCR;AI工具:AI工具:文心一言(百度) ,CSDN写作助手(CSDN),豆包(字节跳动),通义千问(阿里) -
AI提问2(开发环境)
Python313(UV) + PyQT + PaddleOCR
环境安装python# python # paddleocr # pyqt5 -
AI提问3(需求分解)
基于python的图像ocr识别系统- GUI图形界面
- GUI对象及功能: 对象类型、对象属性(形状/大小、显示文字/图标)、响应事件
> GUI层次:标题、菜单、第1层、第2层。。。第N层;左侧、右侧;状态栏
> 对象属性:名称、类型、大小、形状、颜色(背景)、字体/字号、对齐方式
> 响应事件
-
AI提问4(界面设计)
- 提问: 作为Python + PyQT5开发专家,请按以下表格所述,构建GUI程序界面,并实现功能
|-----|----------|-------|-----------------------------------|------------------------------------|------|------------|
| 位置 | 名称 | 类型 | 属性 | 事件 | GUI? | 功能? |
| 标题栏 | 图像文字识别系统 | 标题 | 长:1200 高:900 | | 是 | 是 |
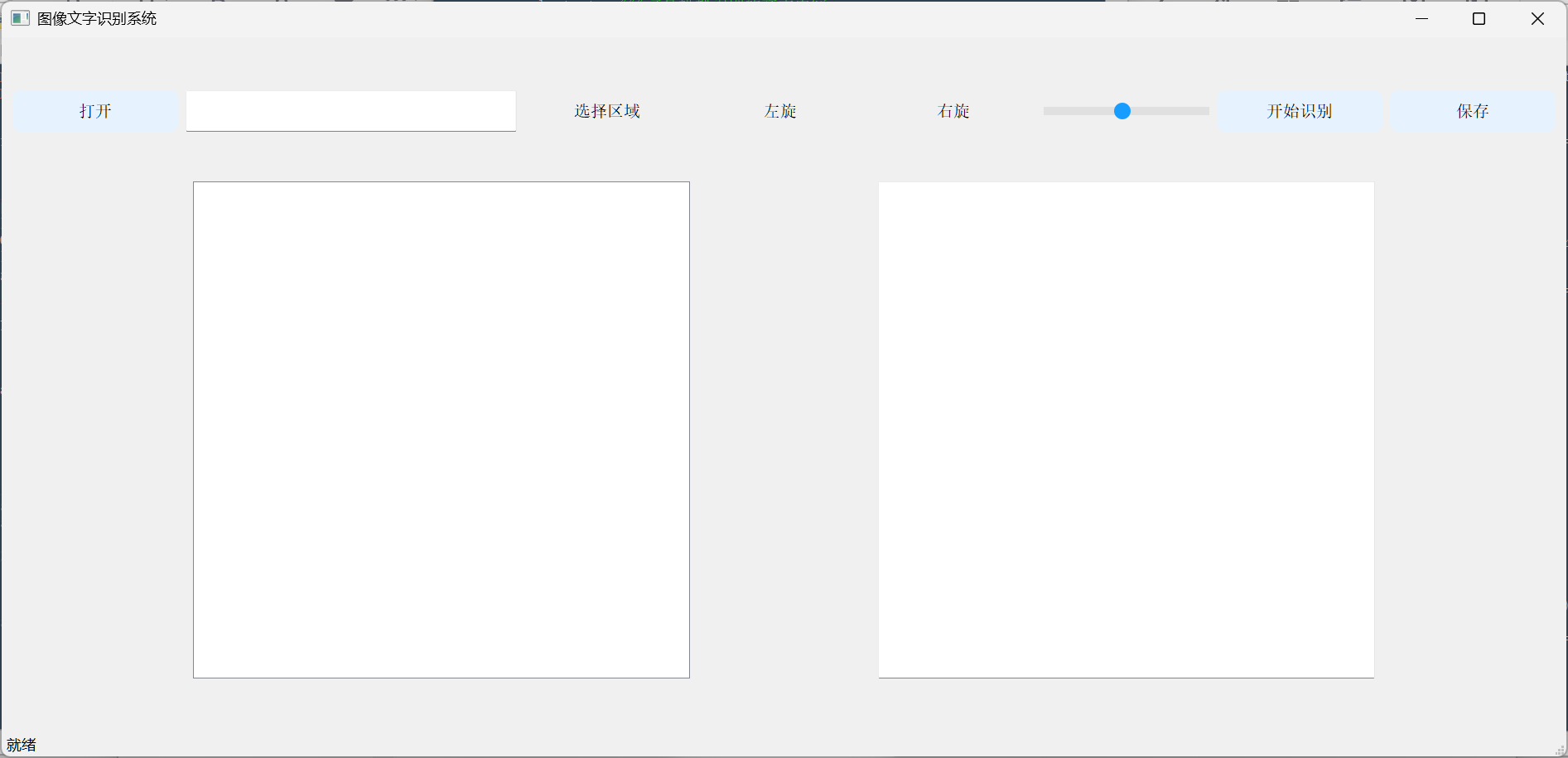
| 第1层 | 打开 | 按钮 | 长:200 高:50 圆角矩形 背景浅蓝色 宋体,10号 居中对齐 | 点击后选择图像文件 | 是 | 是 全局变更使用错误 |
| 第1层 | 图像文件路径 | 输入框 | 长:400 高:50 宋体,10号 不可编辑 | 显示打开图像的文件全路径 | 是 | 是 |
| 第1层 | 选择区域 | 按钮 | 长:200 高:50 圆角矩形 宋体,10号 居中对齐 | 选择图像指定区域显示,并按操作显示文字 | 是 | 否 |
| 第1层 | 左旋 | 按钮 | 长:200 高:50 圆角矩形 宋体,10号 居中对齐 | 左旋90度 | 是 | 是 |
| 第1层 | 右旋 | 按钮 | 长:200 高:50 圆角矩形 宋体,10号 居中对齐 | 右旋90度 | 是 | 是 |
| 第1层 | 缩放 | 滑动条 | 长:200 高:50 圆角矩形 宋体,10号 居中对齐 | 左右滑动,图像进行缩小、放大显示 | 是 | 是 |
| 第1层 | 开始识别 | 按钮 | 长:200 高:50 圆角矩形 背景浅蓝色 宋体,10号 居中对齐 | 识别原始图片显示框中的文字内容 | 是 | 是 |
| 第1层 | 保存 | 按钮 | 长:200 高:50 圆角矩形 背景浅蓝色 宋体,10号 居中对齐 | 保存文字识别文本框中的文字显示,文件名为 原始图片名+reg.txt | 是 | 是 有错误 |
| 第2层 | 原始图片 | 显示框 | 长:600 高:600 | 显示原始图片 | 是 | 是 有错误 |
| 第2层 | 文字识别 | 多行文本框 | 长:600 高:600 宋体,10号 居上、居左对齐 可编辑 | 显示原始图片中识别的文字信息,格式排列与原始图片中文字一致 | 是 | 否 加入提示词 |
| 第3层 | 状态 | 状态栏 | | 显示系统操作状态 | 是 | 是 | -
AI提问6(代码实现)
- 一次实现
- 一次实现
-
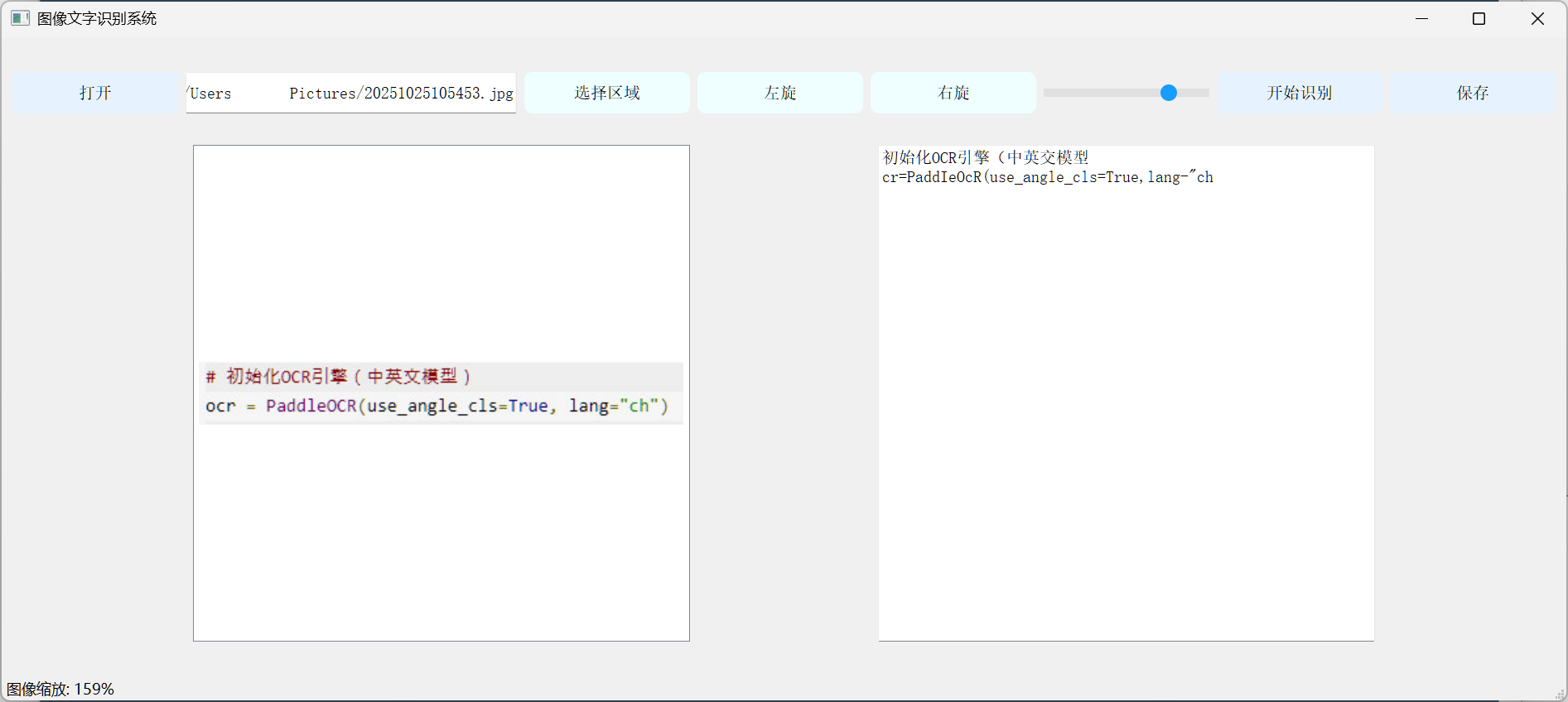
AI提问7(优化完善)
- 二次实现
- 提问:作为Python + PyQT5 + Paddle开发专家,请按以下表格所述
1)构建GUI程序界面,并实现功能
2)优化代码,优化界面
-
AI提问8(程序测试)
- 提示:生成以上程序测试用例,按表格形式输出,格式:序号、功能描述、测试数据、测试步骤、预期结果
序号 功能描述 测试数据 测试步骤 预期结果 1 图像加载功能 测试图片: test_image.jpg(PNG/JPG/BMP格式,尺寸≥100×100像素)1. 点击"加载图片"按钮 2. 选择测试图片文件 图片正确显示在 QGraphicsView中,状态栏显示文件名2 OCR基础识别 测试图片:含清晰中文文本(如"测试文字")的截图 1. 加载测试图片 2. 点击"开始识别"按钮 识别结果框显示在文本附近,状态栏显示"识别完成" 3 矩形选区功能 测试图片:含多个文本区域的图片(如"标题"和"正文") 1. 加载图片 2. 按住鼠标左键拖动绘制红色虚线矩形 3. 释放鼠标 选区框持续显示,且仅选区内文本被识别 4 旋转图片功能 测试图片:横向文字图片(需旋转90°后识别) 1. 加载横向图片 2. 点击"旋转90°"按钮 3. 执行OCR识别 旋转后文字方向正确,识别结果准确 5 缩放图片功能 测试图片:高分辨率图片(如4K分辨率) 1. 加载图片 2. 拖动缩放滑块至50% 3. 执行OCR识别 缩放后图片清晰显示,识别结果与原图一致 6 多语言支持 测试图片:含中英文混合文本(如"Hello 测试") 1. 加载混合文本图片 2. 在OCR设置中选择"中英文混合" 3. 执行识别 中英文均被正确识别,结果按语言分类显示 7 结果保存功能 测试图片:含5行文本的图片 1. 执行OCR识别 2. 点击"保存结果"按钮 3. 选择保存路径( .txt格式)生成文本文件,内容与识别结果完全一致 8 异常图片处理 测试数据:损坏的JPG文件( corrupted.jpg)或非图片文件(test.pdf)1. 尝试加载损坏文件 状态栏显示"无法加载图片",程序无崩溃 9 空选区识别 测试图片:空白区域或无文本图片 1. 绘制极小矩形选区(如1×1像素) 2. 执行识别 状态栏显示"未检测到文本",无错误弹窗 10 大图分块识别 测试图片:超长文档截图(需分块处理) 1. 加载大图 2. 启用"自动分块"选项 3. 执行OCR识别 程序自动分割图片并合并识别结果,无遗漏或重复
参考