目录
[2.1 基本原理](#2.1 基本原理)
[2.1.1 定义](#2.1.1 定义)
[2.1.2 区间和计算公式](#2.1.2 区间和计算公式)
[2.1.3 边界处理](#2.1.3 边界处理)
[2.2 一维前缀和实现步骤](#2.2 一维前缀和实现步骤)
[步骤 1:输入原始数组](#步骤 1:输入原始数组)
[步骤 2:构建前缀和数组](#步骤 2:构建前缀和数组)
[步骤 3:处理查询](#步骤 3:处理查询)
[2.4 注意事项](#2.4 注意事项)
[2.5 一维前缀和经典例题:最大子段和](#2.5 一维前缀和经典例题:最大子段和)
[题目来源:洛谷 P1115 最大子段和](#题目来源:洛谷 P1115 最大子段和)
[3.1 基本原理](#3.1 基本原理)
[3.1.1 定义](#3.1.1 定义)
[3.1.2 前缀和矩阵构建公式](#3.1.2 前缀和矩阵构建公式)
[3.1.3 子矩阵和查询公式](#3.1.3 子矩阵和查询公式)
[3.2 二维前缀和实现步骤](#3.2 二维前缀和实现步骤)
[步骤 1:输入矩阵](#步骤 1:输入矩阵)
[步骤 2:构建二维前缀和矩阵](#步骤 2:构建二维前缀和矩阵)
[步骤 3:处理查询](#步骤 3:处理查询)
[3.3 代码实现(模板)](#3.3 代码实现(模板))
[3.4 注意事项](#3.4 注意事项)
[3.5 二维前缀和经典例题:激光炸弹](#3.5 二维前缀和经典例题:激光炸弹)
[题目来源:洛谷 P2280 HNOI2003 激光炸弹](#题目来源:洛谷 P2280 [HNOI2003] 激光炸弹)
[5.1 常见误区](#5.1 常见误区)
[误区 1:数据溢出](#误区 1:数据溢出)
[误区 2:数组下标从 0 开始](#误区 2:数组下标从 0 开始)
[误区 3:二维前缀和公式记错](#误区 3:二维前缀和公式记错)
[误区 4:忽略边界情况](#误区 4:忽略边界情况)
[5.2 优化技巧](#5.2 优化技巧)
[技巧 1:空间优化](#技巧 1:空间优化)
[技巧 2:输入输出优化](#技巧 2:输入输出优化)
[技巧 3:预处理边界](#技巧 3:预处理边界)
前言
前缀和算法作为典型的基础算法,核心思想是预处理数据,通过提前计算前缀和数组,将原本需要 O (n) 时间的区间查询操作优化到 O (1),是 "空间换时间" 思想的经典应用。
本文将从前缀和的基本概念出发,详细讲解一维前缀和、二维前缀和的原理、实现步骤、注意事项,并结合各大OJ平台的经典例题,手把手教你如何运用前缀和算法解决实际问题。下面就让我们正式开始吧!
一、前缀和算法核心思想
在编程的过程中,我们经常会遇到这样的需求:给定一个数组或矩阵,频繁查询某个区间的和。例如,"查询数组从第 l 个元素到第 r 个元素的和""查询矩阵中以 (x1,y1) 为左上角、(x2,y2) 为右下角的子矩阵和"。
如果直接暴力求解,每次查询都需要遍历区间内的所有元素,时间复杂度为 O (n) (数组)或 O (n m) (矩阵)。当查询次数较多时(如 1e5 次),总时间复杂度会达到O (q** **n),**很容易超时。
前缀和算法的核心的是预处理:
- 提前计算一个 "前缀和数组 / 矩阵",将原始数据的累积和存储起来;
- 每次查询时,利用前缀和数组 / 矩阵的数学性质,通过简单的加减运算快速得到结果。
这种方式能够将预处理的时间复杂度控制在O (n) 或 O (n*m) ,后续每次查询均为 O (1),极大提升了多次查询场景下的效率。
二、一维前缀和:数组区间和查询的利器
一维前缀和是前缀和算法的基础形式,适用于一维数组的区间和查询问题。
2.1 基本原理
2.1.1 定义
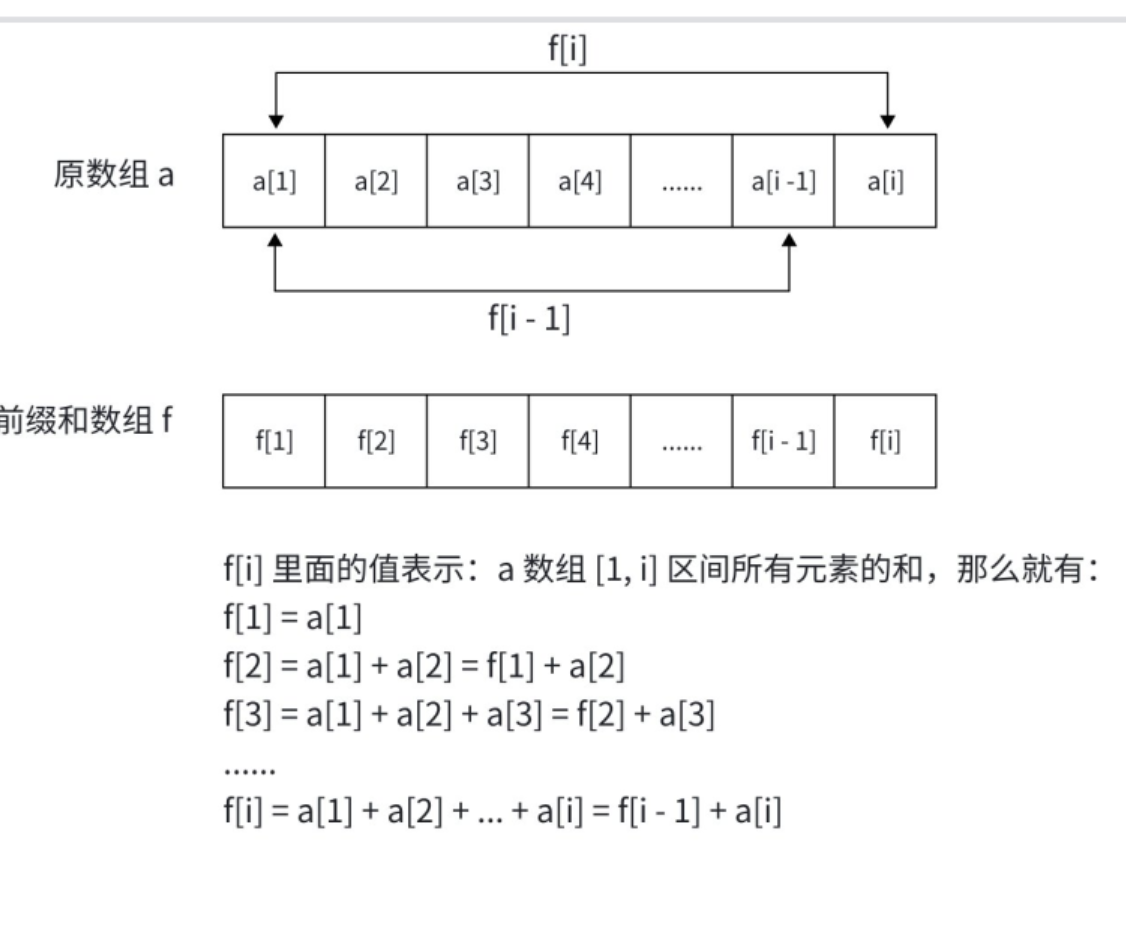
对于一维数组a[1...n](注:本文数组下标均从 1 开始,避免边界处理麻烦),其前缀和数组f[1...n]的定义为:**f[i] = a[1] + a[2] + ... + a[i]**即f[i]表示数组a前i个元素的累积和。
2.1.2 区间和计算公式
若要查询数组a从第l个元素到第r个元素的和(即a[l] + a[l+1] + ... + a[r]),根据前缀和的定义可推导:sum(l, r) = f[r] - f[l-1]
推导过程:
f[r] = a[1] + a[2] + ... + a[l-1] + a[l] + ... + a[r]f[l-1] = a[1] + a[2] + ... + a[l-1]- 两式相减,正好得到
l到r的区间和。
2.1.3 边界处理
- 当
l=1时,l-1=0,此时f[0]需定义为 0(初始化前缀和数组时,f[0] = 0),避免数组越界; - 数组下标从 1 开始是一维前缀和的常用技巧,能简化边界条件判断,减少错误。
2.2 一维前缀和实现步骤
步骤 1:输入原始数组
读取数组长度n和查询次数q,然后读取原始数组a[1...n]。
步骤 2:构建前缀和数组
初始化前缀和数组f[0...n],其中f[0] = 0。遍历数组a,按照f[i] = f[i-1] + a[i]的公式计算前缀和。
步骤 3:处理查询
对于每个查询(l, r),根据公式sum = f[r] - f[l-1]计算结果并输出。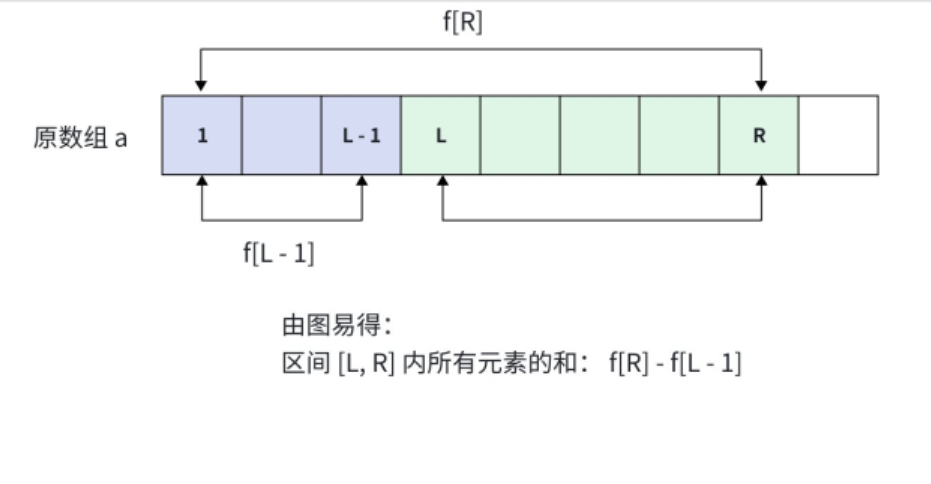
2.4 注意事项
- 数据溢出问题 :当数组元素较大或数组长度较长时,前缀和可能超出
int的范围(int最大值约 2e9),因此必须使用long long类型存储前缀和数组。 - 输入输出效率 :当
n和q达到 1e5 级别时,使用cin/cout默认方式会较慢,需添加**ios::sync_with_stdio(false); cin.tie(nullptr);**加速输入输出。 - 数组下标 :坚持使用 1-based 下标(从 1 开始),能避免
l=1时f[l-1] = f[0]的越界问题,简化逻辑。
2.5 一维前缀和经典例题:最大子段和
题目来源:洛谷 P1115 最大子段和
题目描述
给出一个长度为n的序列,选出其中连续且非空的一段使得这段和最大。
- 输入:第一行是序列长度
n,第二行是n个整数(可正可负); - 输出:最大子段和。
示例输入
7
2 -4 3 -1 2 -4 3示例输出
4(解释:最大子段为3 -1 2,和为 4)
题目链接: https://ac.nowcoder.com/acm/problem/226282
解法思路
最大子段和问题是一维前缀和的进阶应用,核心思路是:
- 计算序列的前缀和数组
f; - 对于每个位置
i,以a[i]为结尾的最大子段和 =f[i] - 前缀最小值(f[0]到f[i-1]中的最小值); - 遍历过程中维护 "前缀最小值" 和 "最大子段和",最终得到结果。
代码实现
cpp
#include <iostream>
#include <climits> // 用于INT_MIN
using namespace std;
typedef long long LL;
const int N = 2e5 + 10; // 题目要求n<=2e5
int n;
LL a[N];
LL f[N]; // 前缀和数组
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n;
f[0] = 0;
for (int i = 1; i <= n; ++i) {
cin >> a[i];
f[i] = f[i-1] + a[i];
}
LL max_sum = LLONG_MIN; // 最大子段和,初始化为最小值
LL min_prefix = f[0]; // 前缀最小值,初始化为f[0]
for (int i = 1; i <= n; ++i) {
// 计算以a[i]为结尾的最大子段和
max_sum = max(max_sum, f[i] - min_prefix);
// 更新前缀最小值(包含f[i])
min_prefix = min(min_prefix, f[i]);
}
cout << max_sum << endl;
return 0;
}算法分析
- 时间复杂度:O (n),预处理前缀和数组 O (n),遍历计算最大子段和 O (n);
- 空间复杂度:O (n),存储前缀和数组;
- 优势:相比暴力枚举 O (n²) 的时间复杂度,前缀和解法效率极高,能轻松处理 2e5 规模的数据。
三、二维前缀和:矩阵区间和查询
一维前缀和适用于数组,而二维前缀和则是其在矩阵中的扩展,用于快速查询子矩阵的和。
3.1 基本原理
3.1.1 定义
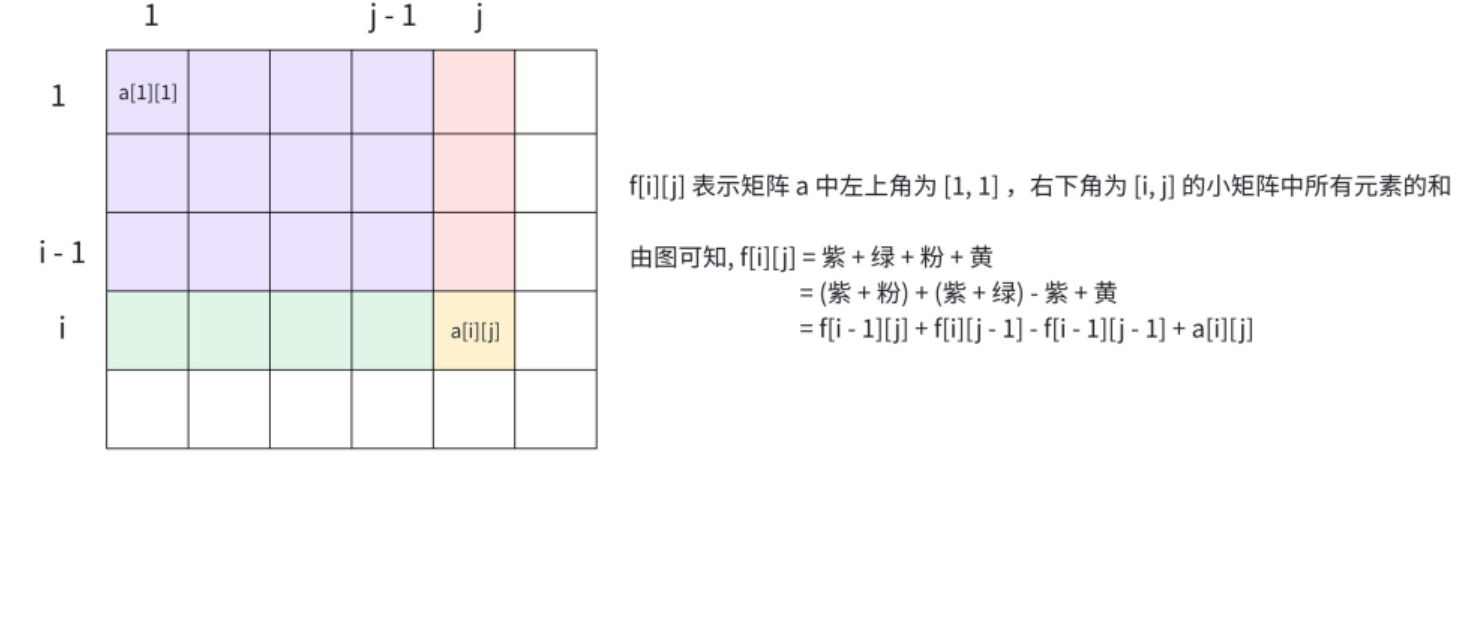
对于n行m列的矩阵a[1...n][1...m],其二维前缀和数组f[1...n][1...m]的定义为:f[i][j] = 矩阵a中左上角(1,1)到右下角(i,j)的子矩阵的和
3.1.2 前缀和矩阵构建公式
二维前缀和的构建需要考虑矩阵的重叠部分,公式推导如下:f[i][j] = f[i-1][j] + f[i][j-1] - f[i-1][j-1] + a[i][j]
推导过程:
f[i-1][j]:左上角 (1,1) 到 (i-1,j) 的子矩阵和(上方区域);f[i][j-1]:左上角 (1,1) 到 (i,j-1) 的子矩阵和(左方区域);- 两者相加时,
f[i-1][j-1](左上角 (1,1) 到 (i-1,j-1) 的子矩阵)被重复计算了一次,因此需要减去;- 最后加上当前元素
a[i][j],得到f[i][j]。
3.1.3 子矩阵和查询公式
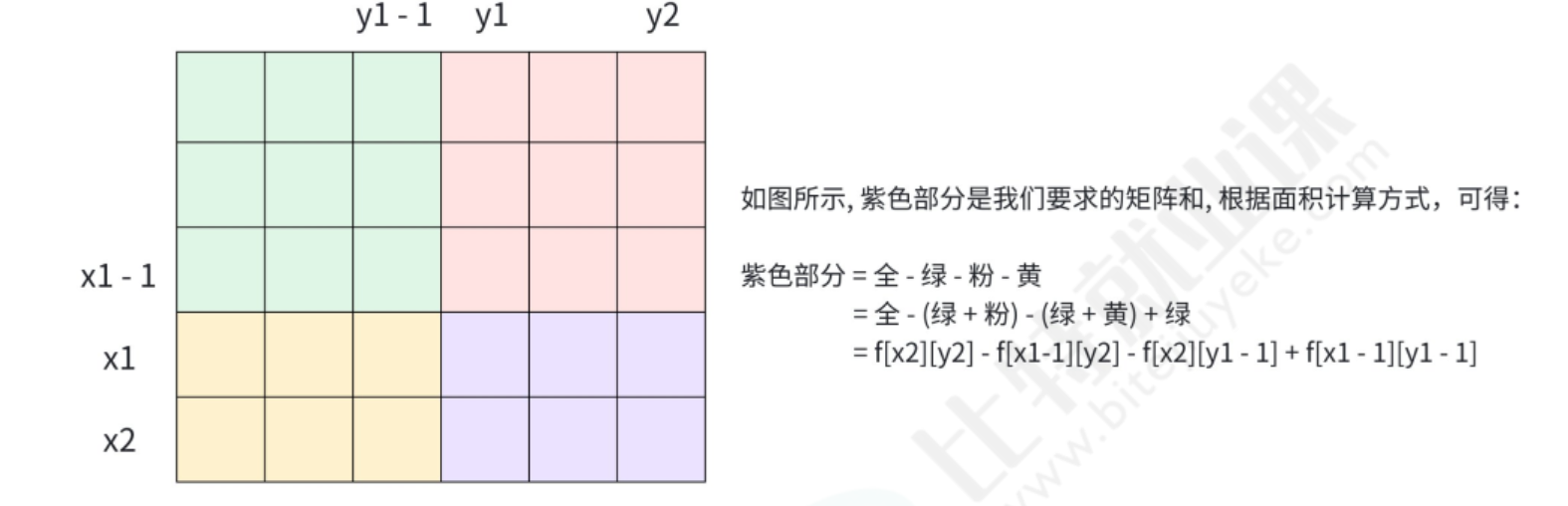
若要查询以(x1,y1)为左上角、(x2,y2)为右下角的子矩阵和,公式为:sum = f[x2][y2] - f[x1-1][y2] - f[x2][y1-1] + f[x1-1][y1-1]
推导过程:
f[x2][y2]:整个大矩阵(1,1)到(x2,y2)的和;- 减去
f[x1-1][y2]:去掉上方不需要的区域(1,1)到(x1-1,y2);- 减去
f[x2][y1-1]:去掉左方不需要的区域(1,1)到(x2,y1-1);- 此时,
f[x1-1][y1-1]被减去了两次,需要加回一次,得到目标子矩阵的和。
3.2 二维前缀和实现步骤
步骤 1:输入矩阵
读取矩阵的行数n、列数m和查询次数q,然后读取n行m列的矩阵a。
步骤 2:构建二维前缀和矩阵
初始化前缀和矩阵f[0...n][0...m],所有元素初始化为 0(边界处理)。遍历矩阵a,按照f[i][j] = f[i-1][j] + f[i][j-1] - f[i-1][j-1] + a[i][j]计算前缀和。
步骤 3:处理查询
对于每个查询(x1,y1,x2,y2),根据公式计算子矩阵和并输出。
3.3 代码实现(模板)
cpp
#include <iostream>
using namespace std;
typedef long long LL;
const int N = 1010; // 适配1e3规模的矩阵(n,m<=1e3)
int n, m, q;
LL a[N][N]; // 原始矩阵
LL f[N][N]; // 二维前缀和矩阵
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m >> q;
for (int i = 1; i <= n; ++i) {
for (int j = 1; j <= m; ++j) {
cin >> a[i][j];
}
}
// 构建二维前缀和矩阵
for (int i = 1; i <= n; ++i) {
for (int j = 1; j <= m; ++j) {
f[i][j] = f[i-1][j] + f[i][j-1] - f[i-1][j-1] + a[i][j];
}
}
// 处理q次查询
while (q--) {
int x1, y1, x2, y2;
cin >> x1 >> y1 >> x2 >> y2;
// 计算子矩阵和
LL sum = f[x2][y2] - f[x1-1][y2] - f[x2][y1-1] + f[x1-1][y1-1];
cout << sum << endl;
}
return 0;
}3.4 注意事项
- 数据类型 :矩阵元素之和可能非常大,必须使用
long long类型,避免溢出; - 边界初始化 :前缀和矩阵
f[0][...]和f[...][0]均初始化为 0,确保x1=1或y1=1时公式仍成立; - 查询参数合法性 :需确保
x1<=x2且y1<=y2(题目通常会保证输入合法,无需额外判断); - 时间复杂度 :构建前缀和矩阵 O (n*m),每次查询 O (1),适合处理
n,m<=1e3、q<=1e5的场景。
3.5 二维前缀和经典例题:激光炸弹
题目来源:洛谷 P2280 HNOI2003 激光炸弹
题目描述
一种新型激光炸弹可以摧毁一个边长为R的正方形内的所有目标。地图上有N个目标,每个目标有坐标(Xi,Yi)和价值Vi。炸弹的爆破范围是边长为R的正方形,边与坐标轴平行,目标位于边上时不会被摧毁。求一颗炸弹最多能摧毁的目标总价值。
输入描述
- 第一行:正整数
N(目标数)和R(正方形边长); - 接下来
N行:每行三个正整数Xi,Yi,Vi(目标坐标和价值)。
输出描述
炸弹最多能摧毁的目标总价值。
示例输入
2 1
0 0 1
1 1 1示例输出
1(解释:边长为 1 的正方形无法同时覆盖 (0,0) 和 (1,1),最多摧毁 1 个目标)
题目链接: https://www.luogu.com.cn/problem/P2280
解法思路
- 问题转化 :将每个目标的价值映射到矩阵中,a[Xi+1][Yi+1] += Vi(坐标 + 1 是为了适配 1-based 下标);
- 构建二维前缀和矩阵 :通过前缀和快速计算任意边长为
R的正方形内的价值和; - 枚举所有可能的正方形 :正方形的右下角坐标
(x2,y2)满足x2>=R、y2>=R,左上角坐标为(x2-R+1, y2-R+1),计算每个正方形的价值和,取最大值。
代码实现
cpp
#include <iostream>
#include <algorithm>
using namespace std;
typedef long long LL;
const int N = 5010; // 题目中Xi,Yi<=5000,因此矩阵大小设为5010
int n, R;
LL a[N][N]; // 目标价值矩阵
LL f[N][N]; // 二维前缀和矩阵
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> R;
// 注意:Xi和Yi可能为0,统一+1转为1-based下标
for (int i = 0; i < n; ++i) {
int x, y, v;
cin >> x >> y >> v;
a[x+1][y+1] += v; // 同一位置可能有多个目标,累加价值
}
// 矩阵最大边长(题目中Xi,Yi<=5000,因此最大为5001)
int max_len = 5001;
// 构建二维前缀和矩阵
for (int i = 1; i <= max_len; ++i) {
for (int j = 1; j <= max_len; ++j) {
f[i][j] = f[i-1][j] + f[i][j-1] - f[i-1][j-1] + a[i][j];
}
}
// 处理R超过矩阵边长的情况(此时炸弹覆盖整个矩阵)
if (R >= max_len) {
cout << f[max_len][max_len] << endl;
return 0;
}
LL max_val = 0;
// 枚举所有边长为R的正方形的右下角坐标(x2,y2)
for (int x2 = R; x2 <= max_len; ++x2) {
for (int y2 = R; y2 <= max_len; ++y2) {
int x1 = x2 - R + 1;
int y1 = y2 - R + 1;
// 计算当前正方形的价值和
LL val = f[x2][y2] - f[x1-1][y2] - f[x2][y1-1] + f[x1-1][y1-1];
max_val = max(max_val, val);
}
}
cout << max_val << endl;
return 0;
}算法分析
- 时间复杂度:O (5001*5001) ≈ O (2.5e7),完全在时间限制内;
- 空间复杂度:O (5001*5001) ≈ 25MB,符合内存要求;
- 关键技巧:将离散的目标坐标映射到连续矩阵中,利用二维前缀和快速计算正方形区域和,避免了暴力枚举每个目标的低效做法。
五、前缀和算法常见误区与优化技巧
5.1 常见误区
误区 1:数据溢出
- 问题:未使用
long long类型,导致前缀和超出int范围; - 解决:前缀和数组、矩阵必须使用
long long类型,尤其是处理大数据时。
误区 2:数组下标从 0 开始
- 问题:下标从 0 开始时,
l=0会导致l-1=-1,引发数组越界; - 解决:统一使用 1-based 下标,前缀和数组 / 矩阵的第 0 行、第 0 列初始化为 0。
误区 3:二维前缀和公式记错
- 问题:构建前缀和矩阵时遗漏
-f[i-1][j-1],或查询时遗漏+f[x1-1][y1-1]; - 解决:牢记 "加上方、加左方、减重叠、加当前" 的构建逻辑,以及 "减上方、减左方、加回重叠" 的查询逻辑。
误区 4:忽略边界情况
- 问题:如激光炸弹问题中,
R大于矩阵边长时未特殊处理; - 解决:提前判断边界情况,避免枚举时出现无效循环。
5.2 优化技巧
技巧 1:空间优化
- 一维前缀和:若无需保留原始数组,可直接在原始数组上修改(
a[i] += a[i-1]),节省空间; - 二维前缀和:同理,可直接在原始矩阵上构建前缀和,无需额外开辟
f矩阵。
技巧 2:输入输出优化
- 当数据规模较大(
n>1e4)时,使用**ios::sync_with_stdio(false); cin.tie(nullptr);**加速输入输出,避免出现超时(TLE)。
技巧 3:预处理边界
- 对于二维前缀和,提前计算矩阵的最大边长(如激光炸弹问题中的 5001),避免不必要的循环
总结
前缀和算法的应用远不止本文介绍的内容,在后续的动态规划、滑动窗口等算法中,前缀和也会作为辅助工具出现。因此,熟练掌握前缀和算法,不仅能解决当前的基础问题,更能为后续的算法学习打下坚实基础。
希望本文能帮助大家深入理解前缀和算法的原理与应用。如果在学习过程中遇到问题,欢迎在评论区留言讨论!