2025 年云栖大会,EMR Serverless StarRocks重磅发布全新企业级版本内核Stella (St arRocks E fficient and L ightening-fast Lakehouse),完全兼容开源StarRocks,为用户提供企业级的产品功能、卓越的性能及稳定性保障。
EMR Serverless StarRocks在权威TPC基准测试中创造佳绩:在"数据分析"性能测试TPC-H榜单中,阿里云EMR Serverless StarRocks (Stella 1.2.0内核)以QphH超754万分的性能结果斩获全球冠军 ,领先第二名111%;
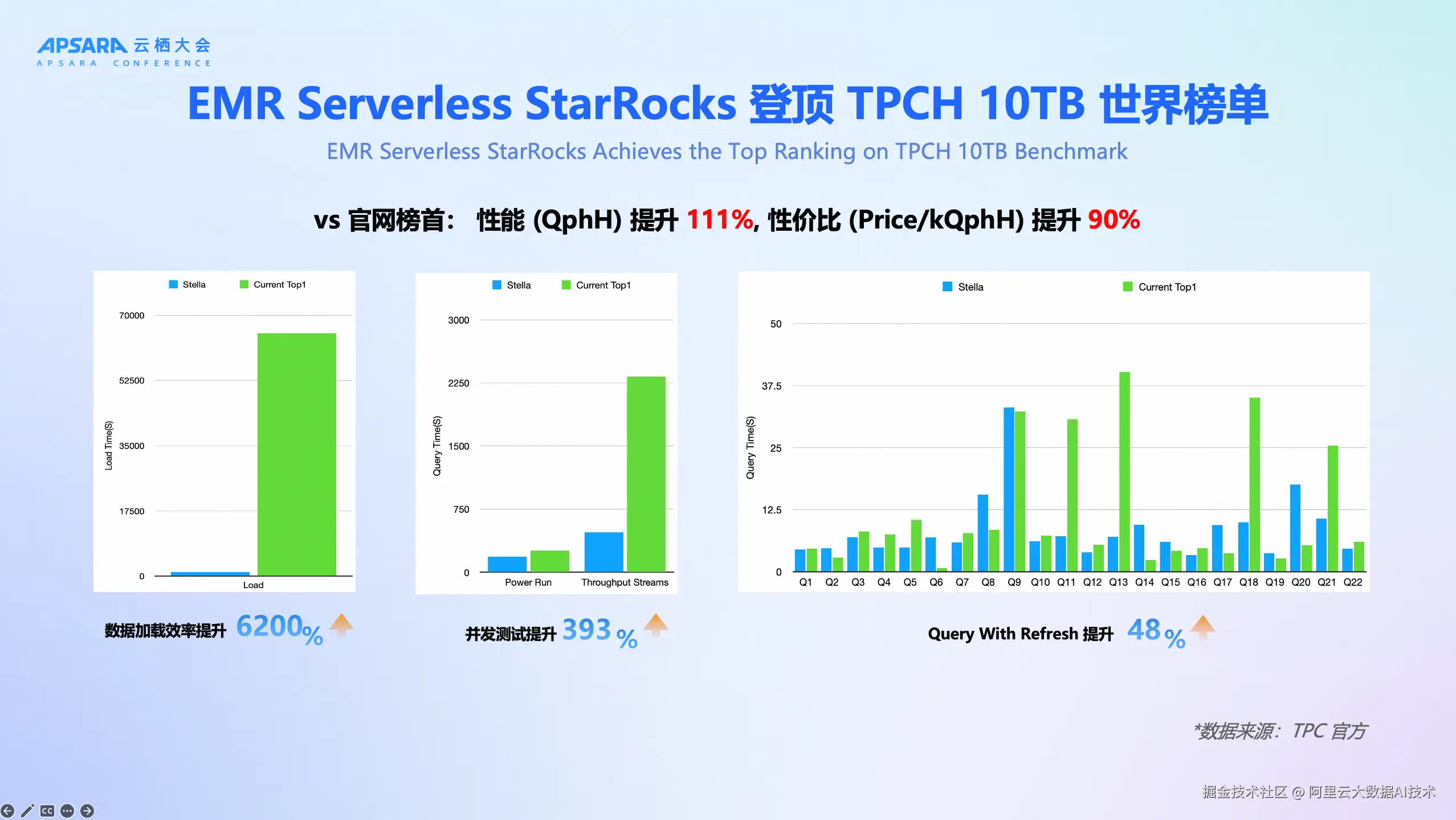
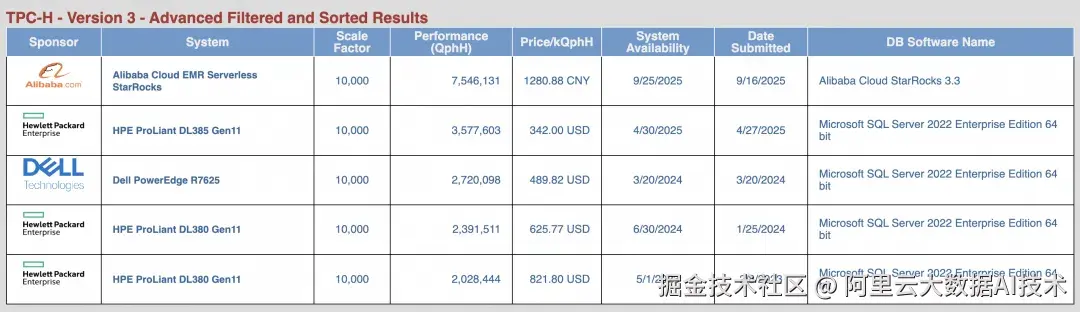
全新企业级内核Stella在TPC-H 10TB标准测试场景下,相比上一版本性能提升超过120% ,登顶TPC榜单全球第一;与此同时,在Lakehouse典型场景中,StarRocks + Paimon组合的TPC-H 1T的性能测试,相比上一个版本性能提升100% ,相比Trino + Paimon实测性能提升高达12倍 ,Paimon DV表的模式下提升300% 。充分验证了其在复杂分析查询中的极致性能与云原生架构的领先优势。同时发布了全新的全文检索引擎,较之前版本过滤性能提升100%。
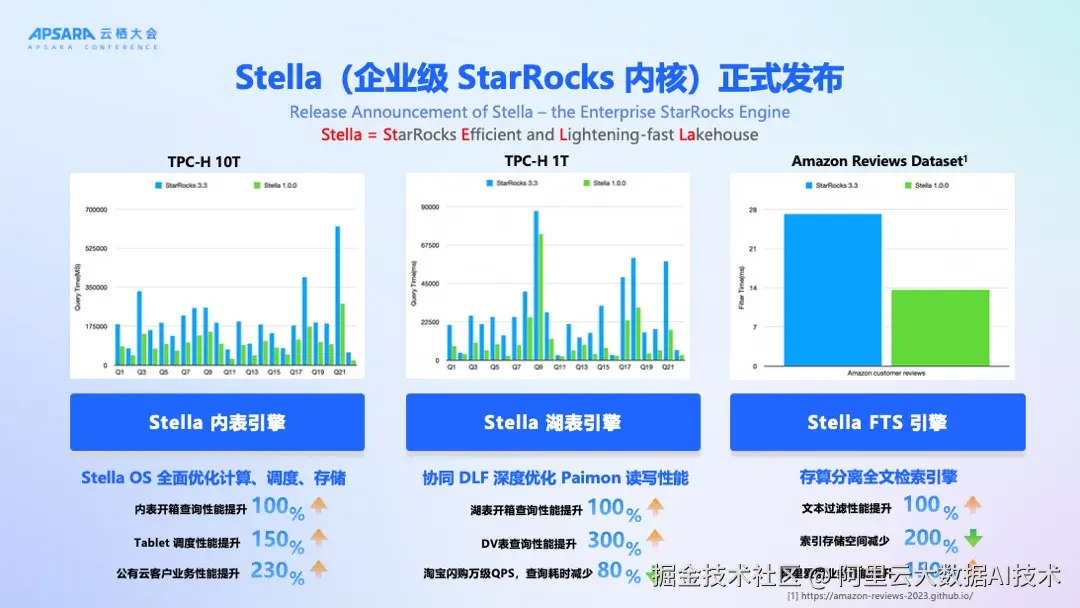
三大核心场景全面升级
Stella 聚焦云原生Lakehouse能力提升,在实时数仓、湖仓分析、全文检索三大核心场景上取得重大突破:
- 实时数仓
- 多Warehouse(多计算组)正式发布 :支持读写分离场景,已经过大规模生产环境验证
- 内核性能大幅提升 :性能较上个版本提升100%
- 使用成本大大降低 :高频导入降低50%资源消耗 ,存储API请求成本降低80%
- 元数据管理效率提升 :海量Tablet调度性能提升300%
- 企业级能力 :完整支持数据治理和血缘功能
- 存储与可观测性提升 :磁盘空间和稳定性全面对齐存算一体架构,可观测性大幅提升
- 湖仓分析
- Paimon查询性能提升100%:在标准TPC-H场景下,查询性能较上一版本显著提升
- Paimon DV表分析性能****提升300%+:通过对DV序列化机制的大幅优化,DV表模型查询效率提升约10倍
- 跨引擎性能领先 :StarRocks+Paimon相较Trino+Paimon性能提升12倍以上
- 无缝集成云上DLF 2.×系列:与阿里云Data Lake Formation深度集成,支持用户、权限、元数据统一管理,云上即开即用的Lakehouse架构
- 全文检索
- 全新倒排索引架构和能力正式发布:重构社区版本,改进设计缺陷
- 导入性能提升3倍+:检索引擎数据导入效率大幅提高
- 日志分析性能提升5倍+:查询响应速度显著提升
- 存储降本80%+:StarRocks采用的列存模式较行存模式大大提升压缩空间能力
核心能力优化
Multi-Warehouse:企业级资源隔离方案
Multi-Warehouse针对大型StarRocks集群的资源隔离难题提供了有效解决方案。随着集群规模扩大和业务场景增多,资源争抢问题逐渐凸显------导入任务过大影响查询性能、大型SQL操作阻塞其他业务查询。
Multi-Warehouse基于存算分离架构,实现了:
- 数据共享与计算隔离:多个Warehouse共享同一存储层(如OSS),实现数据高效共用;计算资源通过硬隔离机制独立分配
- 全面资源隔离:最新版本支持Compaction指定运行在特定Warehouse中,避免资源集中争抢
- 弹性伸缩协同:与弹性伸缩能力结合使用,可根据业务需求动态调整计算资源规模,白天高峰扩容、夜间低峰缩容,在保障性能的同时有效控制成本
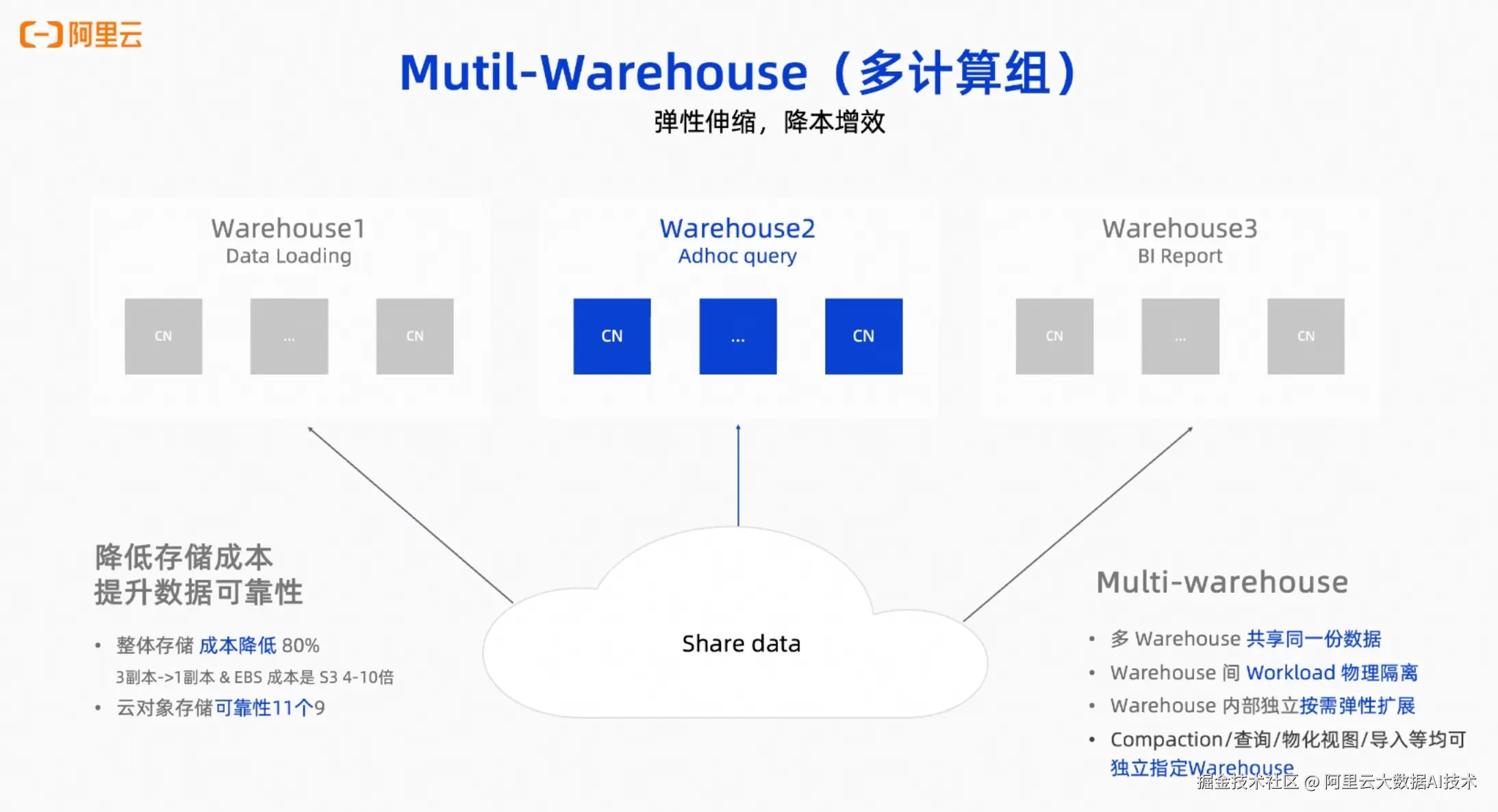
目前,在使用存算分离架构的客户中,约半数已启用Multi-Warehouse,该功能与弹性伸缩已成为企业用户广泛组合使用的两大核心功能。
Stella 内核性能提升
在TPC-H 10T基准测试中,存算分离版本的Stella相比上一版本性能提升超过120%,充分展现了云原生架构的技术优势。
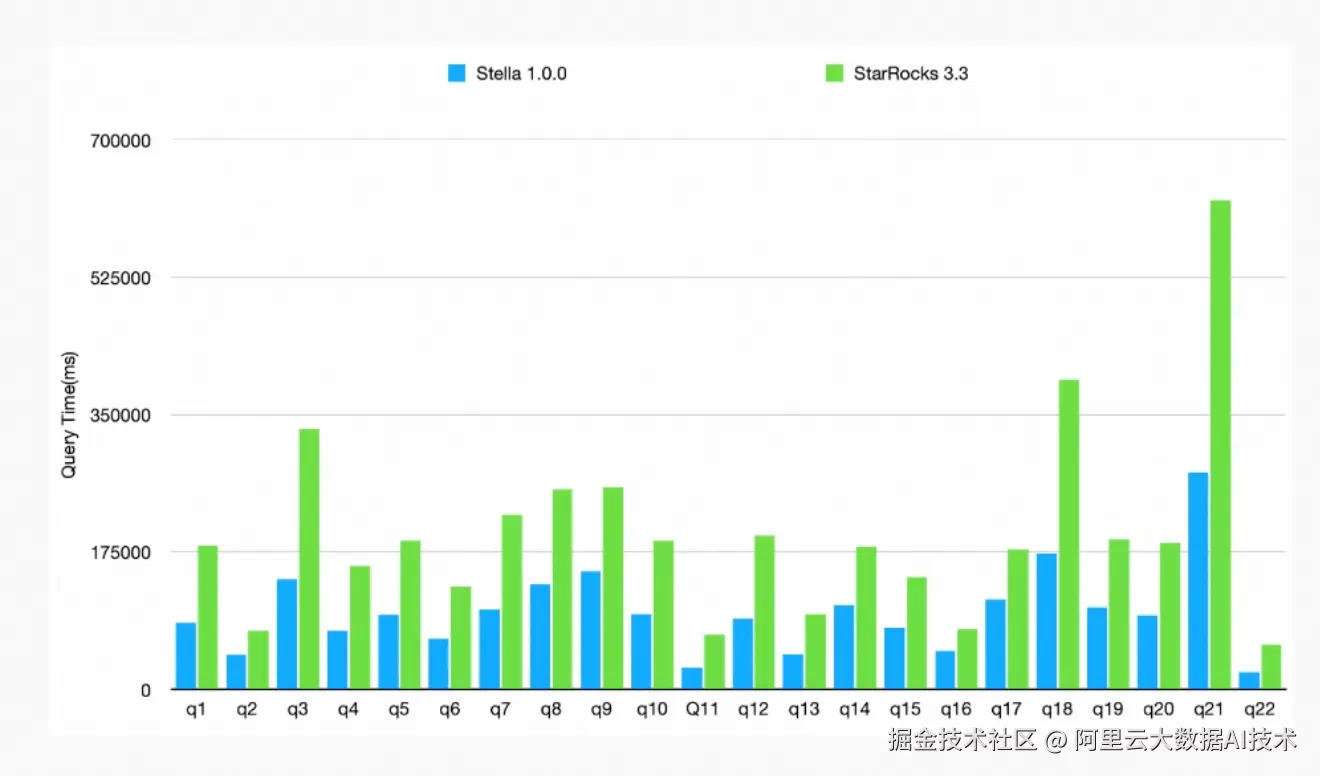
重点优化:
- 支持Index & Meta Cache 功能优先级,优先保障元数据缓存命中率,大大提升查询性能
- 缓存自适应IO框架,更好的均衡磁盘和OSS效率,提高缓存命中率
- 高频导入场景,优化调度算法,保障不倾斜,提升导入效率
- 海量Tablet调度情况下,优化shared balance算法,在50+节点弹性伸缩场景下,达到秒级均衡
- 轻量ETL场景下优化缓存空间管理框架
湖仓分析场景优化
Stella在Lakehouse场景下查询Paimon下性能的提升也非常明显: 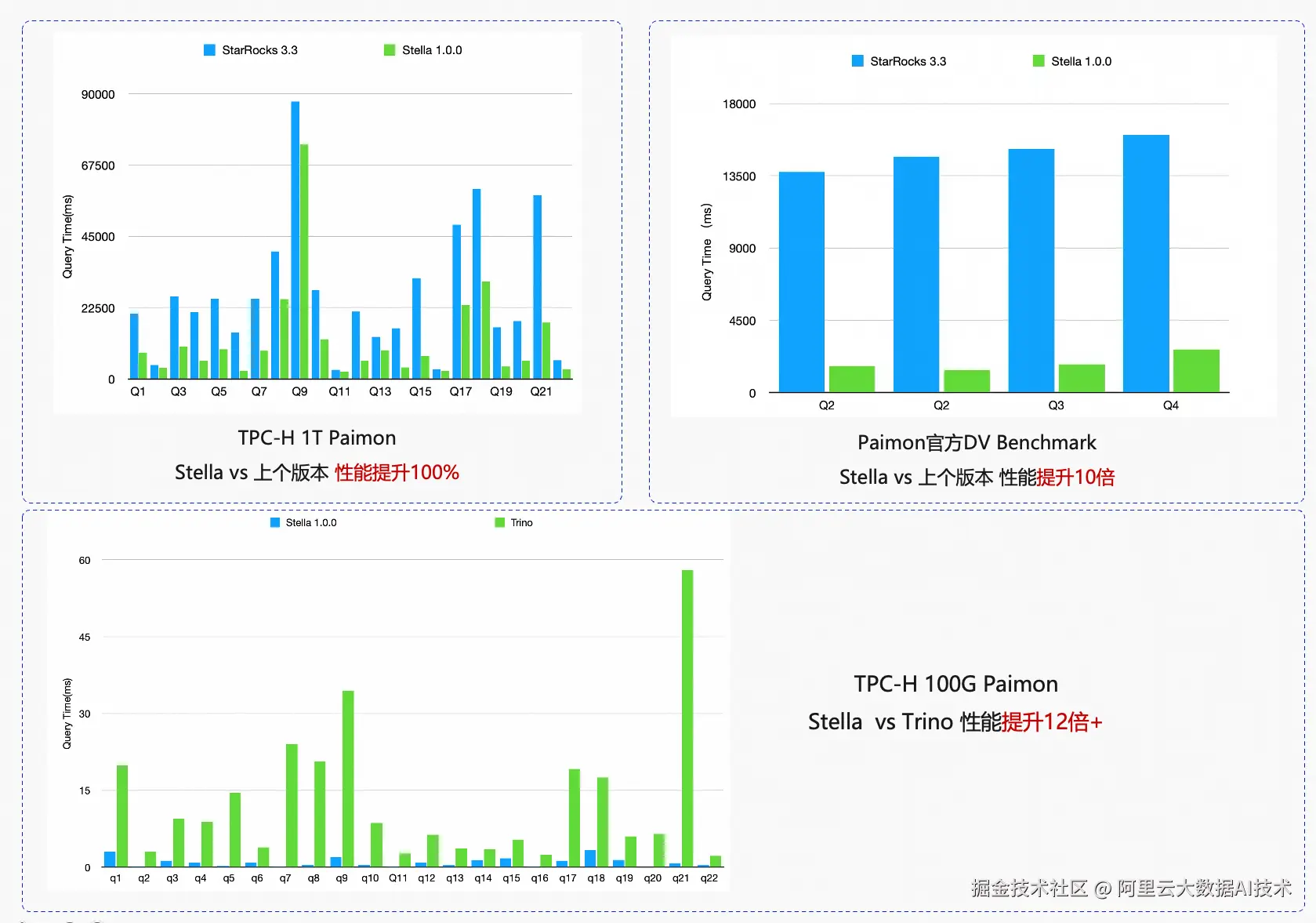
重点优化
- 大规模元数据场景下,实现分布式元数据解析框架,避免单点,提升查询性能。
- 优化元数据获取性能,支持manifest cache,提升查询性能及MV刷新效率。
- 重构Delete Vector序列化框架,大幅度提升DV查询性能。
- DLF 2.5 深度集成,与Openlake方案无缝衔接。
通过与Data Lake Formation的深度集成 ,用户只需简单创建catalog即可访问DLF中的数据表,权限配置在DLF中即可自动同步至StarRocks,实现真正的即开即用。 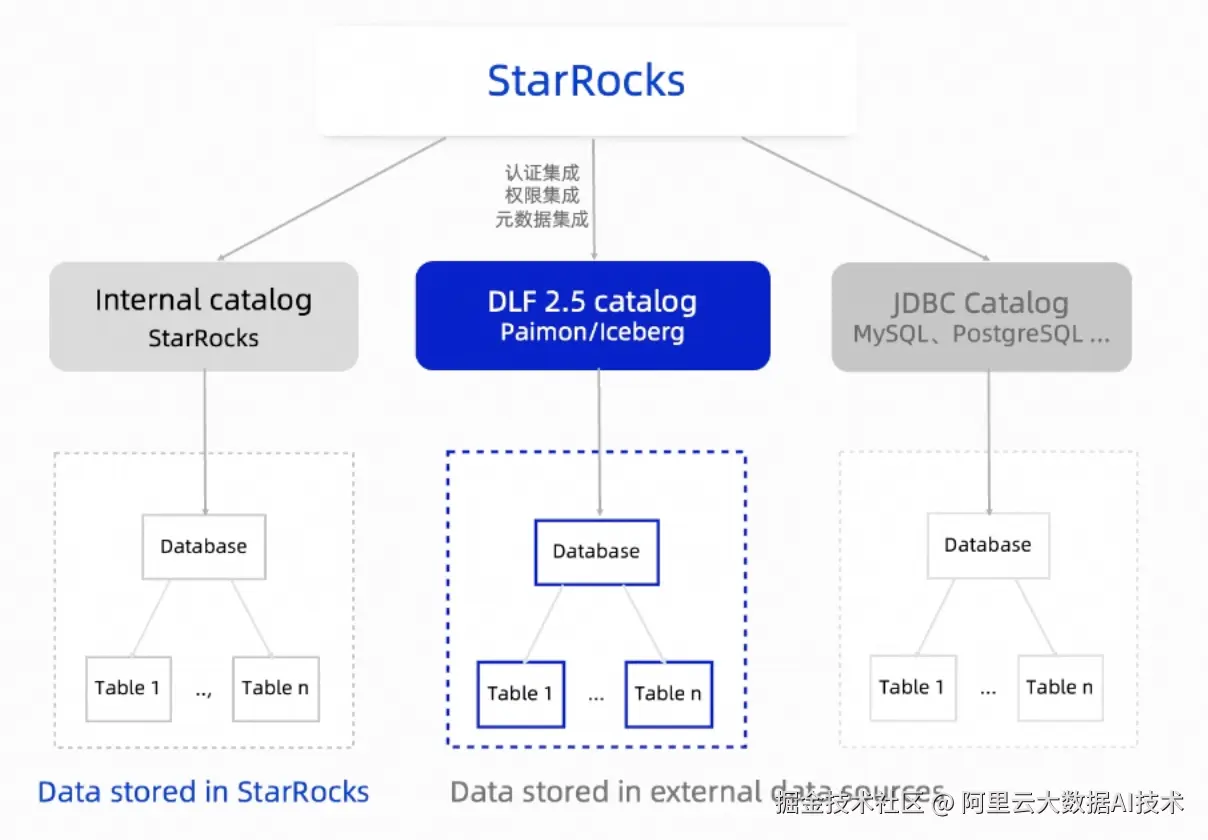
全文检索发布
全新全文检索功能现已在存算一体与分离架构中全面支持,基于 全文倒排索引实现高效文本搜索。适用于日志分析、商品标题匹配等场景。相比旧版,查询性能提升 3-5 倍,导入更快,存储成本显著降低。全文检索功能支持主键表和明细表,用户可在建表时或建表后创建索引,使用match、match_all等语法实现多样化的文本检索需求。
全文倒排索引使用方法
建表时创建索引:
sql
CREATE TABLE `t` (
`k` BIGINT NOT NULL COMMENT "",
`v` STRING COMMENT "",
INDEX idx (v) USING GIN("parser" = "english")
) ENGINE=OLAP
DUPLICATE KEY(`k`)
DISTRIBUTED BY HASH(`k`) BUCKETS 1
PROPERTIES (
"replicated_storage" = "false"
);建表后创建索引:
sql
-- Create Index After Create Table
ALTER TABLE t ADD INDEX idx (v) USING GIN( 'parser' = 'english');全文检索查询:
sql
-- MATCH/MATCH_ANY
select * from testdb.http_logs
where request match "images hm_bg";
-- MATCH_ALL
select * from testdb.http_logs
where request match_all "images hm_bg";
-- MATCH_PHRASE
select * from testdb.http_logs
where request match_phrase "GET /images";
-- MATCH_PHRASE_PREFIX
select * from testdb.http_logs
where request match_phrase_prefix "GET /im";
-- MATCH_PHRASE_EDGE
select * from testdb.http_logs
where request match_phrase_edge 'et images hm';Stella 的发布标志着 EMR Serverless StarRocks 在企业级数据分析领域迈入新的里程碑。从实时数仓到湖仓分析,从全文检索到多业务隔离,Stella 为每一个场景都带来了实实在在的性能提升和成本优化。
依托于在 TPC-H 10T 基准测试中超过 120% 的性能飞跃 ,以及在开放湖仓场景下提升高达 12 倍的实测查询优势,Stella 不仅验证了其技术架构的先进性,更彰显了阿里云在云原生数据处理领域的深厚积累与持续创新能力。这些成绩背后,是存算分离架构、分布式元数据管理、智能缓存调度、Delete Vector 优化等核心技术的全面突破,使得 Stella 能够从容应对超大规模数据下的复杂分析挑战。
面向未来,Stella 将继续深化在 Lakehouse 架构、实时化、智能化方向的探索,为企业构建统一、高效、低成本的数据分析底座提供更强有力的支撑。无论是金融、电商、互联网还是制造业客户,都将借助Stella 实现更快速的决策响应、更灵活的资源调度与更可观的总体拥有成本(TCO)优化。EMR Serverless StarRocks 正以开源兼容为基石,以企业级能力为核心,引领云原生数据分析的新时代。