1. 引言与技术背景
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理(Hybrid Transactional and Analytical Processing, HTAP)的融合型分布式数据库产品。TiDB 的核心设计理念是 "解决分库分表的痛苦",从开发的第一天起就确立了测试驱动的策略(25)。

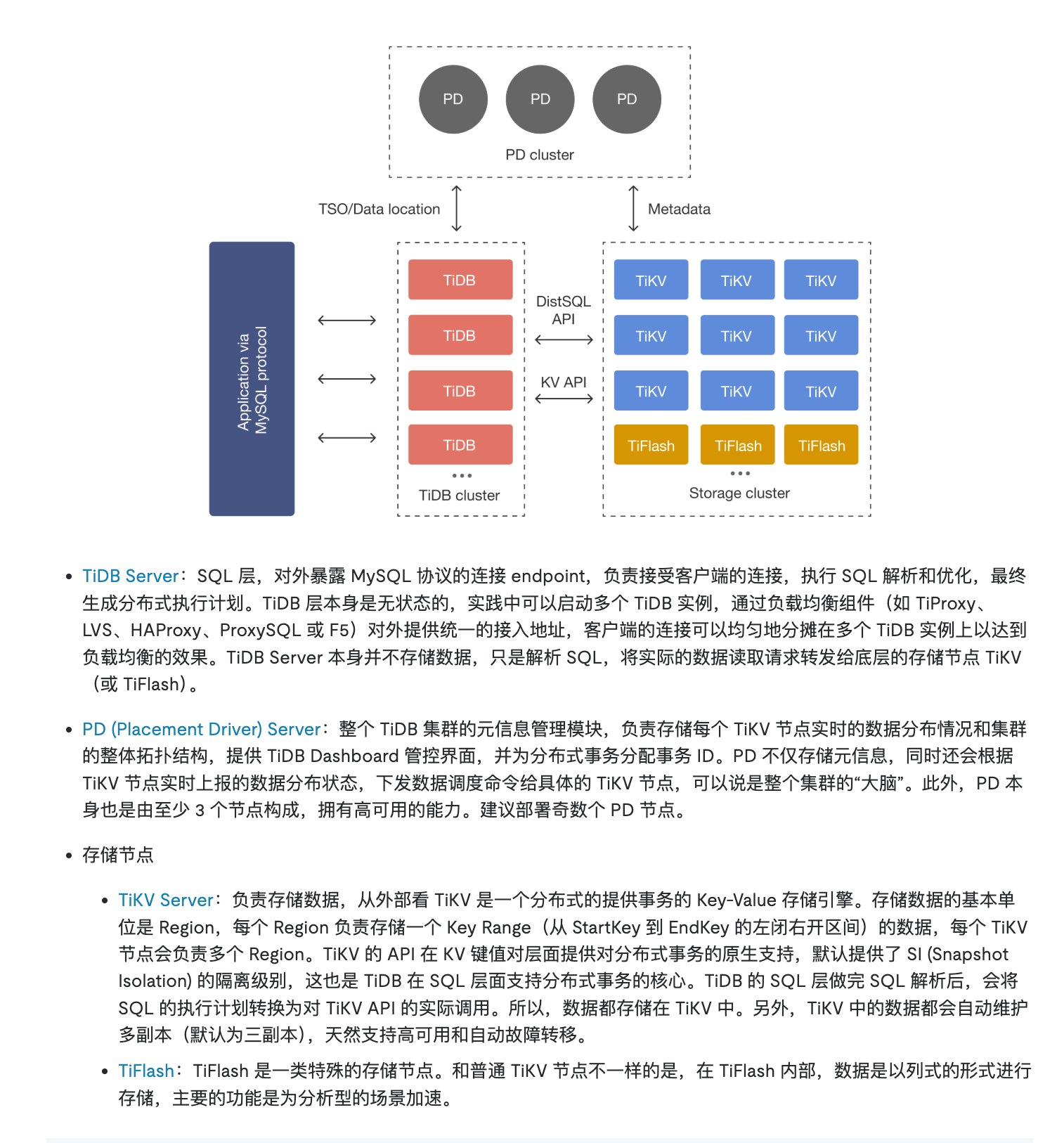
TiDB 采用创新的分层架构设计,主要包括三个核心组件:TiDB Server(计算层)、PD(Placement Driver,元数据管理)和 TiKV(存储层)(11)。这种松耦合的架构设计使得每个组件可以独立扩展和演进,为系统的稳定性和可维护性奠定了坚实基础(11)。TiDB Server 作为无状态的 SQL 层,对外暴露 MySQL 协议的连接端点,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划(6)。
从技术发展历程来看,TiDB 经历了快速的演进。从 TiDB 1.0 到 8.0,TiDB 的体系结构一直在不断演进,TiDB v1 确立了主核心框架,由 TiDB Server、TiKV Server、PD Server 三大核心组件构成;TiDB v2 整体架构升级,引入 TiSpark,解决用户复杂的 OLAP 需求(21)。TiDB 从 v4.0 到最新的 v8.1,每个版本都带来了跨越性的改进,从 v5 到 v8 版本迭代演进过程中,从 5 个维度增强 TiDB 稳定性以及性能(22)。
TiDB 的技术定位是一款现代化的分布式数据库,具备以下核心技术特征:水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 协议和 MySQL 生态等重要特性,支持在本地和云上部署。TiDB 完全兼容 MySQL 的 SQL 语法,这意味着大多数 MySQL 应用程序可以无缝迁移到 TiDB(113)。
本报告将从技术选型、运维管理和架构设计三个角度,围绕分布式事务、弹性扩展、HTAP 能力、多数据中心部署四个核心特性,对 TiDB 进行全面深入的技术分析,为企业数据库选型和架构设计提供决策参考。
2. TiDB 核心技术特性分析
2.1 分布式事务能力
TiDB 基于 Google Percolator 模型实现分布式事务,采用两阶段提交(2PC)协议,由 TiDB 作为协调者驱动(31)。TiDB 的分布式事务实现机制包括两个核心阶段:
第一阶段(Prewrite 预写):TiDB 向所有涉及的 TiKV 节点发送预写请求,TiKV 检查是否存在冲突或过期版本,有效数据会被加锁。在这个阶段,TiDB 会选择一个主键,从 PD 获取 Region 分布信息,按 Region 对所有键进行分组,然后向所有涉及的 TiKV 节点发送预写请求。
第二阶段(Commit 提交):仅当所有 Prewrite 成功后,TiDB 从 PD 获取 commit_ts(提交时间戳),并向主键所在的 TiKV 节点发起第二次提交,TiKV 检查数据并清除预写阶段留下的锁。
TiDB 实现了快照隔离(Snapshot Isolation, SI),对外宣传为可重复读(REPEATABLE-READ)以保持与 MySQL 的兼容性。TiDB 支持两种隔离级别:
-
可重复读(REPEATABLE READ) :事务只能看到事务开始前已提交的数据,不会看到未提交的数据或并发事务在事务执行期间提交的更改(42)。TiDB 的可重复读隔离级别通过快照隔离技术实现,与 MySQL 部分兼容(44)。
-
读已提交(READ COMMITTED) :从 TiDB v4.0.0-beta 开始支持,仅在悲观事务模式下生效。在该隔离级别下,DML 操作基于最新提交的数据执行,行为与 MySQL 相同,但不同于 TiDB 的乐观事务模式(43)。
TiDB 通过多版本并发控制(MVCC)机制,在分布式环境下实现了高效的读写分离与事务隔离(49)。TiDB 的事务实现采用了 MVCC 机制,当新写入的数据覆盖旧的数据时,旧的数据不会被替换掉,而是与新写入的数据同时保留,并以时间戳来区分版本(50)。TiKV 中的每个键都关联多个版本,由时间戳决定,架构确保读操作始终访问数据的最新提交版本(51)。
TiDB 采用乐观事务模型作为默认配置,从 v3.0.8 开始,新创建的 TiDB 集群默认使用悲观事务模式。在乐观事务模型中,冲突检测在事务提交时进行,这有助于在并发事务很少修改相同行时提高性能,因为可以跳过获取行锁的过程。
2.2 弹性扩展能力
TiDB 采用计算与存储分离的架构设计,这是其弹性扩展能力的核心基础(136)。TiDB Server 作为无状态的计算层不存储数据,TiKV 作为有状态的存储层负责数据持久化,这种设计使得系统可以独立扩展计算和存储资源。
TiDB 的弹性扩展能力体现在以下几个方面:
水平扩展能力 :TiDB 支持水平扩展至 512 个计算节点,每个节点最大支持 1000 并发,集群容量最大支持 PB 级别(136)。TiDB 的性能与 TiDB 节点数量呈线性增长关系。TiKV 节点的数量要求至少为 1 组(3 个不同可用区中的 3 个节点),并按 3 个节点递增。
自动分片机制 :TiDB 的自动分片能力是其可扩展性的核心,数据自动划分为 Region(默认 96MB),支持自动分裂和合并(62)。当 Region 大小达到阈值(默认 96MB)或写入次数触发分裂条件时,PD 会自动将其分裂为两个子 Region(75)。PD 作为集群的 "大脑",通过一系列调度器实现 Region 的副本放置与负载均衡(75)。
负载均衡机制 :TiKV 按照 Region(数据分片)来组织数据,每个 Region 都有多个副本以确保高可用性,且这些副本会根据 PD 的指令在不同的 TiKV 节点间自动分布和平衡(74)。PD 基于多种策略(如 Region 大小、Leader 分布、磁盘使用情况等)对 TiKV 中的 Region 进行调度,确保资源的高效利用和均衡分布(74)。
在线扩缩容能力 :TiDB 支持在线动态增减存储和计算节点,具备接近无限的水平扩展能力(70)。得益于 TiDB 存储计算分离的架构设计,可按需对计算、存储分别进行在线扩容或者缩容,扩容或者缩容过程中对应用运维人员透明(136)。TiDB Server 节点不持久化数据,每个节点完全对等,当 TiDB Server 计算资源不够时,只需要增加 TiDB Server 节点,然后修改上层的负载均衡组件将客户端连接均衡分发到新的 TiDB Server 节点即可(67)。
扩容性能表现 :TiDB 的扩容机制基于存算分离的架构,可以单独进行计算层扩容和存储层扩容。TiDB 节点和 TiKV 节点在将节点数扩展到 10 个后,性能偏差系数仍保持较小的值,真正做到了性能与节点数的线性增长(72)。
2.3 HTAP 能力
TiDB 通过 TiKV(行存储)和 TiFlash(列存储)的协同工作实现 HTAP 能力,TiFlash 是 TiDB 实现 HTAP 数据库的关键组件(81)。TiDB 的 HTAP 架构具有以下特点:
双存储引擎架构 :TiDB 提供行存储引擎 TiKV 和列存储引擎 TiFlash,TiFlash 通过 Multi-Raft Learner 协议实时从 TiKV 复制数据,确保行存储引擎 TiKV 和列存储引擎 TiFlash 之间的数据强一致。TiFlash 作为 TiKV 的列式存储扩展,提供良好的隔离级别和强一致性保证(87)。
实时数据同步 :TiKV 数据变更实时同步到 TiFlash(延迟 < 1 秒),OLAP 分析基于最新数据,实现 OLTP 与 OLAP 数据无缝衔接(86)。TiFlash 节点以 Learner 角色加入到 Multi-Raft 体系中,从而实现了对 TiKV 数据的准实时更新和强一致性(92)。
智能查询路由:TiDB 查询优化器可自动决定是否使用 TiFlash 副本,支持智能选择、引擎隔离、手动 Hint 三种方式访问 TiFlash。对于具有 TiFlash 副本的表,TiDB 优化器会基于成本估算自动决定是否使用 TiFlash 副本。
HTAP 性能表现 :某头部电商通过 TiDB HTAP 架构,在双十一大促期间实现每秒处理 10 万订单的同时,实时分析延迟降至 100ms 级。TiDB 的 HTAP 能力非常适合 "既要联机事务又要实时分析" 的场景,通过部署 TiFlash 列式存储引擎,复杂的分析查询直接在其上完成,完全不影响前台事务处理性能(85)。
使用方式灵活 :TiDB Cloud 中 TiFlash 默认不复制数据,用户可通过ALTER TABLE table_name SET TIFLASH REPLICA 1选择需要复制的表,副本数不能超过 TiFlash 节点数。TiFlash 提供列式存储,且拥有借助 ClickHouse 高效实现的协处理器层,主要包含两个组件:列式存储引擎组件和处理 Multi-Raft 协议通信相关工作的 TiFlashproxy 组件(88)。
2.4 多数据中心部署能力
TiDB 支持多种多数据中心部署方案,基于 Raft 协议的多数派机制提供强大的容灾能力:
同城三数据中心方案:同城三个机房部署 TiDB 集群,AZ 间数据通过 Raft 协议同步,可同时对外提供读写服务,任意中心故障不影响数据一致性。该方案的优点包括:所有数据副本分布在三个 AZ,具备高可用和容灾能力;任何一个 AZ 失效后,不会产生任何数据丢失(RPO=0);任何一个 AZ 失效后,其他两个 AZ 会自动发起 leader election,并在一定时间内(通常 20s 以内)自动恢复服务。
同城两数据中心方案 :TiDB 针对核心业务系统同城两中心的灾备方案有专属名称叫自适应同步模式(Data Replication Auto Synchronous),简称 DR Auto-Sync。同步复制模式下,同城中心至少有一个副本与主中心保持同步状态,可以保证 RPO=0(104)。
两地三中心方案 :即生产数据中心、同城灾备中心、异地灾备中心的高可用容灾方案。相比同城多中心方案,两地三中心具有跨城级高可用能力,可以应对城市级自然灾害(94)。这种架构提供生产数据中心、同城灾备中心、异地灾备中心,具有跨城级容灾能力(98)。
部署策略优化:如果不需要每个 AZ 同时对外提供服务,可以将业务流量全部派发到一个 AZ,并通过调度策略把 Region leader 和 PD leader 都迁移到同一个 AZ。这样,不管是从 PD 获取 TSO,还是读取 Region,都不会受 AZ 间网络的影响。当该 AZ 失效时,PD leader 和 Region leader 会自动在其它 AZ 选出,只需要把业务流量转移至其他存活的 AZ 即可。
容灾能力分析:遵循 Raft 协议的特点,TiDB 的多数据中心部署具有明确的容灾能力:想克服任意 1 台服务器故障,应至少提供 3 台服务器;想克服任意 1 个机柜故障,应至少提供 3 个机柜;想克服任意 1 个可用区的故障,应至少提供 3 个 AZ;想应对任意 1 个区域的灾难场景,应至少规划 3 个区域用于部署集群。
3. 技术选型评估
3.1 与传统关系型数据库对比
TiDB 与传统关系型数据库(如 MySQL、PostgreSQL)在多个关键维度存在显著差异:
扩展性对比 :传统关系型数据库(如 MySQL)为单机架构,扩展性差,需通过分库分表等复杂策略实现扩展,而 TiDB 天生具备分布式架构,采用 Raft 协议实现数据的多副本一致性,能够轻松实现水平扩展,只需添加 TiKV 节点就可以增加存储容量,添加 TiDB 节点就可以提升计算能力(107)。
性能表现对比 :在数据量百万级以下时,MySQL 写入性能优于 TiDB;MySQL 在单机或小规模并发 OLTP 场景性能优势明显,而 TiDB 在高并发和大数据量场景表现更优(107)。在选择时,需明确查询模式的核心比例:实时分析、联表查询与大范围聚合在 TiDB 上的优势明显,而对延迟极低的单点事务型工作负载,MySQL 的原生性与成熟度可能更具优势(110)。
架构设计对比 :TiDB 采用三层分布式架构,包括 TiDB SQL 层、TiKV 存储层、PD 调度中心,并可选部署 TiFlash 列存分析引擎。在比较中,MySQL 的单点稳定性与简单性适合中小规模应用;而 TiDB 的分布式特性则更适合需要横向扩展和跨区域部署的企业场景(112)。
功能特性对比 :TiDB 支持 OLTP 和 OLAP 混合工作负载,而传统数据库主要专注于 OLTP;TiDB 支持分布式事务和强一致性,而传统数据库的分布式方案通常需要复杂的中间件;TiDB 支持在线 DDL,业务发布 DDL 时不锁表,支持 DML 并行操作,且可分布式处理,对主从副本无延迟影响(107)。
兼容性对比 :虽然 TiDB 是一款全新的数据库,但它在语法和生态方面与 MySQL 保持了高度的兼容性。TiDB 完全兼容 MySQL 的 SQL 语法,这意味着大多数 MySQL 应用程序可以无缝迁移到 TiDB(113)。
3.2 与其他分布式数据库对比
TiDB 与其他主流分布式数据库(如 CockroachDB、OceanBase)相比具有以下特点:
与 CockroachDB 对比 :TiDB 和 CockroachDB 都是开源分布式数据库,都具备水平扩展性、强一致性和高可用性等特性。TiDB 与 MySQL 协议兼容,CockroachDB 与 PostgreSQL 协议兼容。TiDB 支持分布式事务,通过 Multi-Raft 协议实现事务的原子性、一致性、隔离性和持久性(ACID)特性(114)。
与 OceanBase 对比 :TiDB 架构严格遵循 "计算、存储、调度" 三层分离,各组件独立扩展,无状态设计适配云原生环境。TiDB 通过 "TiKV(行存,OLTP)+ TiFlash(列存,OLAP)" 分离架构实现 HTAP,两者通过 Raft 同步数据,延迟≤1 秒,适合 "事务与分析轻度耦合" 场景(如实时报表)(139)。
技术特色对比:TiDB 的优势在于完全兼容 MySQL 协议和生态,HTAP 能力成熟,社区活跃度高;劣势在于分布式事务实现相对复杂,对运维人员技能要求较高。其他分布式数据库各有特色,如 CockroachDB 的全球分布式能力,OceanBase 的金融级高可用等。
3.3 适用场景分析
基于 TiDB 的技术特性,其适用场景包括:
金融行业场景 :金融行业对数据一致性及高可靠、系统高可用、可扩展性、容灾要求较高。TiDB 采用多副本 + Multi-Raft 协议的方式将数据调度到不同的机房、机架、机器,确保系统的 RTO≤30s 及 RPO=0。TiDB 在数据一致性、可靠性、高可用以及可扩展性等方面表现成熟,与金融行业的属性比较吻合(111)。
海量数据及高并发 OLTP 场景:传统的单机数据库无法满足因数据爆炸性的增长对数据库的容量要求。TiDB 是一种性价比高的解决方案,采用计算、存储分离的架构,可对计算、存储分别进行扩缩容,计算最大支持 512 节点,每个节点最大支持 1000 并发,集群容量最大支持 PB 级别。
实时 HTAP 场景:TiDB 适用于需要实时处理的大规模数据和高并发场景。TiDB 在 4.0 版本中引入列存储引擎 TiFlash,结合行存储引擎 TiKV 构建真正的 HTAP 数据库,在增加少量存储成本的情况下,可以在同一个系统中做联机交易处理、实时数据分析,极大地节省企业的成本。
数据汇聚、二次加工处理场景:TiDB 适用于将企业分散在各个系统的数据汇聚在同一个系统,并进行二次加工处理生成 T+0 或 T+1 的报表。与 Hadoop 相比,TiDB 要简单得多,业务通过 ETL 工具或者 TiDB 的同步工具将数据同步到 TiDB,在 TiDB 中可通过 SQL 直接生成报表。
不适用场景:TiDB 不适合以下场景:对延迟极其敏感的高频交易场景(如高频交易系统);数据量极小且无扩展需求的简单应用;需要特定数据库功能(如存储过程、触发器等)且无法通过应用层实现的场景。
4. 运维管理能力评估
4.1 部署与配置管理
TiDB 提供了完善的部署和配置管理工具链:
TiUP 工具 :从 TiDB 4.0 开始,TiUP 作为包管理器使 TiDB 生态系统中不同集群组件的管理变得更加容易,可以通过单行 TiUP 命令运行任何组件(123)。TiUP 不仅是 TiDB 生态系统中的包管理器,其最终使命是通过构建自己的生态系统,让每个人都能比以往更容易地使用 TiDB 生态系统工具。
部署方式 :TiDB 支持多种部署方式,包括本地部署、容器化部署(Kubernetes)、云部署等。TiDB 是为云而设计的数据库,支持公有云、私有云和混合云,配合 TiDB Operator 项目可实现自动化运维,使部署、配置和维护变得十分简单(143)。
配置管理:TiDB 的配置管理通过配置文件和运行时参数相结合的方式实现。支持动态修改部分配置参数,无需重启服务。TiDB 提供了丰富的配置参数,涵盖性能调优、安全管理、监控告警等各个方面。
自动化部署:TiUP 提供了 playground(本地快速启动)、cluster(生产环境部署)等组件,支持一键式部署。TiDB Operator 支持在 Kubernetes 环境下的自动化部署和管理,包括扩缩容、升级、故障恢复等操作。
4.2 监控与告警体系
TiDB 提供了全面的监控和告警能力:
内置监控系统 :TiDB Dashboard 是内置于 PD 组件的 Web UI 监控管理工具(v4.0 + 版本),无需独立部署,提供监控、诊断和管理功能(120)。Dashboard 监控页面提供性能概览仪表板,这是 TiDB v6.1.0 中引入的性能分析和调优工具(124)。
指标体系 :TiDB 内置大量运维核心指标,覆盖 "集群健康度"(如节点存活数)、"性能指标"(如 QPS/TPS、SQL 执行延迟)、"资源指标"(如节点 CPU / 内存 / 磁盘使用率)、"存储指标"(如 TiKV region 健康数、副本同步状态),省去了传统监控 "搭建 - 配置 - 关联" 的复杂流程(131)。
告警机制 :TiDB Cloud 提供内置告警机制,包括资源使用告警、数据迁移告警、变更订阅告警三类(130)。用户可配置告警策略,如磁盘使用 > 80% 或 TiKV Leader 倾斜 > 20% 时触发告警(128)。
性能监控 :TiDB 的性能监控与优化是其核心功能之一,可以帮助用户更好地了解和优化 TiDB 系统的性能。通过对监控数据进行统计分析,找出系统性能瓶颈和问题,根据分析结果提供优化建议,如调整查询计划、调整系统参数等(132)。
4.3 备份恢复与灾难恢复
TiDB 提供了多种备份恢复和灾难恢复方案:
备份恢复机制:TiDB 支持逻辑备份和物理备份两种方式。逻辑备份通过 TiDB Dumpling 工具实现,物理备份通过 TiDB Lightning 工具实现。TiDB Lightning 还支持从外部数据源(如 CSV、MySQL 等)导入数据。
灾难恢复方案:TiDB 基于 Raft 协议的多副本机制提供了强大的容灾能力。在多数据中心部署场景下,支持同城容灾和异地容灾。TiDB 的自动故障恢复能力确保在节点故障时能够快速恢复服务,RTO 通常在 20 秒以内。
数据一致性保证:TiDB 通过 Multi-Raft 协议确保数据的强一致性,即使在故障场景下也能保证数据不丢失。在多数据中心部署中,通过 Raft 协议的多数派机制确保数据同步的可靠性。
备份策略建议:建议采用定期全量备份结合增量备份的策略,备份频率根据业务需求确定。对于关键业务,建议每天进行增量备份,每周进行全量备份。备份数据应存储在独立的存储系统中,并定期进行恢复测试以验证备份的可用性。
5. 架构设计深度分析
5.1 整体架构设计理念
TiDB 的整体架构设计遵循以下核心理念:
云原生设计 :TiDB 采用云原生、模块化架构实现实时扩展,分布式 SQL 架构完全解耦计算和存储,使用对象存储作为持久化后端,智能扩展以支持实时、混合和 AI 工作负载,同时保持 ACID 事务和 MySQL 兼容性。TiDB 的设计就是云原生的,它的容错能力和水平伸缩能力能够充分发挥云基础设施提供的弹性(144)。
分层解耦架构 :TiDB 采用分层架构设计,分为计算层(TiDB Server)、存储层(TiKV)、元数据管理(PD)三大核心组件,各层职责分离,支持独立扩展(134)。这种松耦合的架构设计使得每个组件可以独立扩展和演进,为系统的稳定性和可维护性奠定了坚实基础(11)。
统一 SQL 引擎:TiDB 通过统一的 SQL 引擎处理所有工作负载,在单一平台内统一混合工作负载,为开发者和运维人员构建,在一个 MySQL 兼容的系统中结合了分布式性能、强一致性和云原生灵活性。
面向未来的设计 :整个 TiDB 架构是面向未来、面向海量数据高并发场景,底层存储技术(如数据定位 seek)都是针对当前主流的 SSD 进行设计和优化的,不会对传统的 SATA/SAS 机械硬盘再进行优化(143)。
5.2 核心组件架构分析
TiDB 的核心组件架构包括四个层次:
计算层(TiDB Server) :TiDB Server 是无状态的 SQL 层,对外暴露 MySQL 协议连接端点,负责处理 SQL 请求、解析、优化和执行,最终生成分布式执行计划(137)。TiDB Server 将 SQL 语句转换为键值操作,转发给 TiKV 分布式键值存储层,组装 TiKV 返回的结果,最终将查询结果返回给客户端。
存储层(TiKV) :TiKV 是分布式键值存储引擎,基于 RocksDB 和 Raft 协议实现,负责存储数据和处理事务。TiKV 采用分层架构设计,将功能划分为四个层级,每一层都只负责自己的事情。RocksDB 在逻辑上把 SSTable 文件划分成多个层级(7 层),并且满足层级越高说明其数据写入越早的性质(10)。
元数据管理层(PD) :PD(Placement Driver)是 TiDB 集群的元数据管理和调度组件,负责管理 TiKV 的数据分片(Region),并为 TiKV 提供负载均衡、调度等功能(4)。PD 存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID(6)。
列存储层(TiFlash) :TiFlash 是 TiDB 的列式存储扩展,基于 ClickHouse 构建,为 HTAP 场景提供分析能力(90)。TiFlash 主要包含两个组件:列式存储引擎组件和处理 Multi-Raft 协议通信相关工作的 TiFlashproxy 组件。TiFlash 对 TiDB 的计算加速分为两部分:列存本身的读取效率提升以及为 TiDB 分担计算(88)。
5.3 扩展性与灵活性设计
TiDB 的扩展性和灵活性设计体现在多个方面:
存储计算分离架构 :TiDB 的存储计算分离架构是其扩展性的核心,计算层和存储层独立运行,可分别进行优化和扩展(133)。这种架构带来的优势包括:弹性扩展能力,计算层(TiDB server)和存储层(TiKV store)可以独立扩展;故障隔离能力,计算层或存储层的故障不会相互影响;性能优化能力,分离的架构允许对计算层和存储层分别进行优化(133)。
模块化设计:TiDB 采用模块化架构设计,各个组件可以独立开发、测试和部署。这种设计使得系统具有良好的可维护性和可扩展性,新功能可以通过添加新模块或修改现有模块来实现。
插件化机制:TiDB 提供了插件化机制,支持用户自定义函数、存储过程、触发器等。这种机制使得 TiDB 可以适应各种复杂的业务需求,同时保持核心架构的稳定性。
多租户支持:TiDB 支持多租户 SaaS 平台,能够处理数百万张表、模式和连接,具有模式隔离、高并发和动态工作负载管理能力。
云原生适配:TiDB 完全适配云原生环境,支持在 Kubernetes 环境下的部署和管理。通过 TiDB Operator 实现自动化运维,包括自动扩缩容、负载均衡、故障恢复等功能。
6. 总结与建议
6.1 技术优势总结
TiDB 作为一款现代化的分布式数据库,在多个技术维度展现出显著优势:
分布式事务能力:TiDB 基于 Percolator 模型实现了完整的分布式事务支持,通过两阶段提交协议确保 ACID 特性。支持快照隔离(SI)和读已提交(RC)两种隔离级别,通过 MVCC 机制实现高效的并发控制。默认的乐观事务模型在低冲突场景下性能优异,从 v3.0.8 开始引入的悲观事务模式提供了更多选择。
弹性扩展能力:TiDB 的计算存储分离架构提供了强大的弹性扩展能力,支持水平扩展至 512 个计算节点,集群容量可达 PB 级别。自动分片机制和智能负载均衡确保了扩展的透明性和高效性。在线扩缩容能力使得系统能够快速响应业务需求变化。
HTAP 能力:TiDB 通过 TiKV 和 TiFlash 双存储引擎架构实现了真正的 HTAP 能力,数据同步延迟小于 1 秒。智能查询路由和自动优化使得系统能够根据查询类型自动选择最优的执行路径,在保证事务处理性能的同时提供强大的分析能力。
多数据中心部署:基于 Raft 协议的多数派机制,TiDB 提供了灵活的多数据中心部署方案,支持同城三中心、同城两中心、两地三中心等多种架构。自动故障恢复能力确保了高可用性,RTO 通常在 20 秒以内。
生态兼容性:TiDB 完全兼容 MySQL 协议和生态系统,大大降低了迁移成本。丰富的工具链(TiUP、TiDB Dashboard、TiDB Lightning 等)提供了完善的运维支持。
6.2 风险与挑战分析
在评估 TiDB 时,也需要关注以下风险和挑战:
技术复杂度:作为分布式数据库,TiDB 的架构相对复杂,对运维人员的技能要求较高。分布式事务的实现机制、数据分片策略、负载均衡算法等都需要深入理解。
性能优化难度:虽然 TiDB 提供了自动优化机制,但在复杂查询场景下仍需要人工调优。查询计划的优化、索引策略的选择、系统参数的配置等都需要专业知识。
资源消耗:TiDB 的分布式架构需要更多的硬件资源支持,包括计算资源、存储资源和网络资源。特别是在多副本部署场景下,存储资源消耗会成倍增加。
学习成本:虽然 TiDB 兼容 MySQL 语法,但分布式数据库的使用模式与传统数据库存在差异。开发人员需要学习新的编程范式,如分布式事务处理、数据分片策略等。
社区支持:虽然 TiDB 拥有活跃的开源社区,但相比 MySQL 等成熟数据库,在某些特定场景下的最佳实践和解决方案可能不够丰富。
6.3 选型建议
基于以上分析,针对不同类型的企业和应用场景,提出以下选型建议:
推荐采用 TiDB 的场景:
-
金融行业应用:TiDB 的强一致性、高可用性和完善的容灾能力满足金融行业的严格要求。
-
互联网电商平台:TiDB 的弹性扩展能力和 HTAP 特性能够支撑高并发交易和实时数据分析需求。
-
企业数据中台:TiDB 的统一 SQL 引擎和强大的扩展性使其成为构建数据中台的理想选择。
-
SaaS 多租户应用:TiDB 的多租户支持能力和资源隔离机制适合构建大规模 SaaS 平台。
-
实时分析场景:TiDB 的 HTAP 能力使得实时业务处理和数据分析可以在同一系统中完成。
谨慎评估的场景:
-
极低延迟交易系统:如果应用对延迟极其敏感(如高频交易),需要仔细评估 TiDB 的性能表现。
-
数据量极小的简单应用:对于数据量小且无扩展需求的应用,TiDB 的复杂性可能带来不必要的开销。
-
依赖特定数据库功能的应用:如果应用严重依赖存储过程、触发器等 TiDB 不完全支持的功能,需要评估替代方案。
实施建议:
-
技术评估阶段:建议进行充分的技术评估,包括性能测试、功能验证、兼容性测试等。可以先在测试环境中部署小规模集群进行验证。
-
迁移规划:制定详细的迁移计划,包括数据迁移方案、应用改造计划、性能优化策略等。建议采用逐步迁移的方式,先迁移非关键业务。
-
人员培训:提前进行运维和开发人员的培训,确保团队具备 TiDB 的运维和开发能力。
-
监控体系建设:建立完善的监控和告警体系,及时发现和解决问题。
-
性能优化:在生产环境部署后,持续进行性能监控和优化,根据业务特点调整系统参数。
TiDB 作为一款优秀的分布式数据库,在技术架构、功能特性、生态兼容性等方面都表现出色。企业在选型时应根据自身业务需求、技术能力和发展规划,综合评估 TiDB 的适用性。在充分准备和合理规划的前提下,TiDB 能够为企业提供强大的数据处理能力和灵活的扩展能力,支撑业务的持续增长和创新发展。
参考资料
1 TiDB Architecturehttps://docs-archive.pingcap.com/tidb/v2.1/architecture/
2 tibcorv架构tidb架构https://blog.51cto.com/u_16213672/14077438
3 博客 - TiDB知识点梳理 (PCTA 笔记分享) | TiDB 社区https://tidb.net/blog/fe4f7b05
4 分布式 SQL 数据库之TiDB-CSDN博客https://blog.csdn.net/youziguo/article/details/141904450
5 一、TIDB 数据库架构概述TIDB数据库专员(PCTA)考试认证笔记 文末获取笔记、视频,持续更新 学习目标 理解数据 - 掘金https://juejin.cn/post/7475896691884130342
6 tidb架构https://blog.csdn.net/zhao_kang_cheng/article/details/144133795
7 TiDB Architecture FAQshttps://docs.pingcap.com/tidb/v6.1/tidb-faq/
8 TiDB【理论篇】01:什么是TiDB【分布式数据库】_tidb数据库-CSDN博客https://blog.csdn.net/weixin_40612128/article/details/148522543
9 TiDB Architecturehttps://docs.pingcap.com/tidbcloud/tidb-architecture
10 万字长文,深入浅出分布式数据库TiDB架构设计-CSDN博客https://blog.csdn.net/m0_73735578/article/details/149250062
11 TiDB数据库从零开始 - 新的世界打瞌睡 - 博客园https://www.cnblogs.com/yapei2025/p/19194475
12 TiDB - 体系架构 - 学弟Craze - 博客园https://www.cnblogs.com/jiamiing/p/19025190
13 tidb:分布式sql数据库的革命性架构解析https://blog.csdn.net/gitblog_00727/article/details/151495004
14 TiDB - 分布式数据库的架构与特性_mob6454cc70eddf的技术博客_51CTO博客https://blog.51cto.com/u_16099274/14243166
15 TiDB 6.6.0 Release Noteshttps://docs.pingcap.com/tidb/stable/release-6.6.0/
16 TiDB v6.0 - 6.6 新特性解读_51CTO博客_tidb 4.0https://blog.51cto.com/tidb/13272071
17 TiDB 6.6 版本发布 - TiDB 社区技术月刊 | TiDB Bookshttps://tidb.net/book/tidb-monthly/2023/2023-02/feature-indepth/tidb-6-6
18 TiDB Featureshttps://docs-archive.pingcap.com/tidb/v7.0/basic-features
19 新特性解析丨TiDB 资源管控的设计思路与场景解析_tidb 发展规划-CSDN博客https://blog.csdn.net/weixin_42241611/article/details/130470631
20 Partitioned Raft KV 特性讨论 - TiDB 的问答社区https://asktug.com/t/topic/1014413
21 TiDB 架构演进:用图读懂其发展历程_51CTO博客_tidb部署架构图https://blog.51cto.com/tidb/13277539
22 博客 - 升级就是最好的调优:TiDB 用户收益与实践总结报告 | TiDB 社区https://tidb.net/blog/59300cbe
23 tidb的架构进化之道https://blog.csdn.net/weixin_45583158/article/details/118834525
24 tidb:主流国产数据库中最早且最深的htap实现者https://blog.51cto.com/tidb/13272035
25 PingCAP"一号员工"唐刘:回顾我与 TiDB 的十年成长之旅导读 作为 PingCAP 的"一号员工",TiDB - 掘金https://juejin.cn/post/7497877479056801803
26 博客 - 星辰考古:TiDB v3.x 忆水木 | TiDB 社区https://tidb.net/blog/533da389
27 The Past, Present, and Future of TiDB as an HTAP Databasehttps://www.pingcap.com/blog/the-past-present-and-future-of-tidb-as-an-htap-database/
28 TiDB Optimistic Transaction Modelhttps://docs.pingcap.com/tidbcloud/optimistic-transaction
29 关于tidb 分布式事务 - TiDB 的问答社区https://asktug.com/t/topic/1038077
30 Transaction on TiKVhttps://pingcap.github.io/tidb-dev-guide/understand-tidb/transaction-on-tikv.html
31 TiDB 如何实现分布式事务的 ACID 特性?_编程语言-CSDN问答https://ask.csdn.net/questions/8824854
32 博客 - TiDB 5.0 两阶段提交 | TiDB 社区https://tidb.net/blog/f05fe253
33 深入理解TiDB的分布式事务机制-CSDN博客https://blog.csdn.net/gitblog_00757/article/details/150621216
34 TiDB分布式事务处理机制-阿里云开发者社区https://developer.aliyun.com/article/1463466
35 TIKV分布式事务简介_TiDB社区干货传送门的技术博客_51CTO博客https://blog.51cto.com/tidb/10452912
36 TiDB事务处理与ACID特性解析 - CSDN文库https://wenku.csdn.net/column/3oxtxp9qmr
37 tidb 表多少数据量才触发索引_mob6454cc769a22的技术博客_51CTO博客https://blog.51cto.com/u_16099314/13062727
38 TiDB的事务处理与ACID兼容性1.背景介绍 TiDB是一种分布式事务处理系统,它具有高可扩展性和高可用性。TiDB的 - 掘金https://juejin.cn/post/7316578293426241574
39 TiDB术语表_tidb里面的专业术语-CSDN博客https://blog.csdn.net/weixin_42241611/article/details/127223878
40 TiDB数据库-CSDN博客https://blog.csdn.net/YangChingyuk/article/details/151279564
41 【建议收藏】7000+字的TIDB保姆级简介,你见过吗-CSDN博客https://blog.csdn.net/bxg_kyjgs/article/details/129750371
42 TiDB Transaction Isolation Levelshttps://docs.pingcap.com/tidb/stable/transaction-isolation-levels/
43 TiDB Pessimistic Transaction Modehttps://docs.pingcap.com/tidbcloud/pessimistic-transaction/
44 SET TRANSACTIONhttps://docs.pingcap.com/tidb/stable/sql-statement-set-transaction
45 Transaction Restraintshttps://docs.pingcap.com/tidb/dev/dev-guide-transaction-restraints
46 数据库系列之TiDB中的事务_golang tidb redolog-CSDN博客https://blog.csdn.net/solihawk/article/details/119381370
47 tidb数据库隔离级别剖析-CSDN博客https://blog.csdn.net/u014229282/article/details/113698267
48 Transaction overviewhttps://docs.pingcap.com/tidb/v8.5/dev-guide-transaction-overview/
49 TiDB快照隔离:MVCC在分布式系统实现-CSDN博客https://blog.csdn.net/gitblog_00671/article/details/151825448
50 tidbmvcc版本堆积相关原理及排查手段https://blog.csdn.net/tidb_pingcap/article/details/137444215
51 Understanding MVCC in TiDB for High-Concurrency Applicationshttps://www.pingcap.com/article/understanding-mvcc-in-tidb-for-high-concurrency-applications/
52 博客 - TiDB分布式事务---写写冲突 | TiDB 社区https://tidb.net/blog/5682e17e
53 TiDB分布式事务处理机制-阿里云开发者社区https://developer.aliyun.com/article/1463466
54 数据库多版本并发控制MVCC-数据库技术博客-OceanBase分布式数据库https://open.oceanbase.com/blog/11708653857
55 用于基于特里数据结构的数据库的高效存储器内多版本并发 控制(pdf)https://patentimages.storage.googleapis.com/90/08/18/7de3035419a6e9/CN112740197A.pdf
56 Scalabilityhttps://docs.pingcap.com/tidbcloud/scalability-concepts/
57 Scale Your TiDB Clusterhttps://docs.pingcap.com/tidbcloud/scale-tidb-cluster/
58 TiDB整体架构详解、TiDB核心特性------水平扩展、高可用_tidb pd tikv-CSDN博客https://blog.csdn.net/qq_40585384/article/details/122503937
59 Scale a TiDB Cluster Using TiUPhttps://docs.pingcap.com/tidb/stable/scale-tidb-using-tiup/
60 【建议收藏】7000+字的TIDB保姆级简介,你见过吗-CSDN博客https://blog.csdn.net/bxg_kyjgs/article/details/129750371
61 Manually Scale TiDB on Kuberneteshttps://docs.pingcap.com/tidb-in-kubernetes/v2.0/scale-a-tidb-cluster/
62 Mastering TiDB Scalability: Architecture & Real-Time Analyticshttps://www.pingcap.com/article/mastering-tidb-scalability-architecture-real-time-analytics/
63 TiDB日常使用规范概述 作为一家全球性的连锁餐饮企业,公司在处理海量数据、复杂业务流程方面面临巨大的挑战。为了解决这些 - 掘金https://juejin.cn/post/7526761867457462323
64 博客 - TiDB 替换 HBase 全场景实践指南 ------从架构革新到业务赋能 | TiDB 社区https://tidb.net/blog/c687d474
65 TiDB 数据库核心原理与架构_Lesson 01 TiDB 数据库架构概述课程整理-CSDN博客https://blog.csdn.net/cnzzs/article/details/142268760
66 博客 - TiDB:扩容过程中 PD 调度原理与常见问题剖析 | TiDB 社区https://tidb.net/blog/3887cc30
67 博客 - 为什么说TiDB在线扩容对业务几乎没有影响 | TiDB 社区https://tidb.net/blog/e82b2c5f
68 Scalabilityhttps://docs.pingcap.com/tidbcloud/scalability-concepts/
69 理解TIDB架构设计_tidb数据库 有类似 oracle表空间的说法码-CSDN博客https://blog.csdn.net/hu2010shuai/article/details/105733060
70 tidb 企业_突破容量极限:TiDB 的海量数据"无感扩容"秘籍-CSDN博客https://blog.csdn.net/weixin_36219784/article/details/112377200
71 MySQL撑不住了?这份TiDB替代可行性报告,请收好!_51CTO博客_mysql替代inhttps://blog.51cto.com/tidb/14246263
72 博客 - 从 MySQL 到 TiDB:业务高速增长与数据库选型趋势 | TiDB 社区https://tidb.net/blog/07b16b74
73 云数据库 TiDB 初使用_版本测评_TiDB 社区干货传送门_mob6454cc63081f的技术博客_51CTO博客https://blog.51cto.com/u_16099176/14306903
74 Java 开发面试题精选:TiDB 一篇全搞定在面试Java开发工程师时,对于国产数据库方面,技术面试官通常会着重考察候 - 掘金https://juejin.cn/post/7372503361361543218
75 TiDB数据分片:Region划分与负载均衡-CSDN博客https://blog.csdn.net/gitblog_00737/article/details/151825670
76 Split Regionhttps://docs.pingcap.com/tidb/stable/sql-statement-split-region/
77 Best Practices for PD Schedulinghttps://docs.pingcap.com/tidb/dev/pd-scheduling-best-practices/
78 TiDB Schedulinghttps://docs.pingcap.com/tidb/stable/tidb-scheduling/
79 Load Base Splithttps://docs.pingcap.com/tidb/v8.5/configure-load-base-split/
80 TiDB 深度解析与 K8S 实战指南-CSDN博客https://blog.csdn.net/Rainsirius/article/details/147489548
81 超强HTAP数据库TiDB:实时分析+事务处理一体化-CSDN博客https://blog.csdn.net/gitblog_00427/article/details/151820197
82 TiDB与TiFlash协同:HTAP场景最佳实践-CSDN博客https://blog.csdn.net/gitblog_00440/article/details/151827524
83 Use an HTAP Clusterhttps://docs.pingcap.com/tidbcloud/use-htap-cluster/
84 tidb 表多少数据量才触发索引_mob6454cc769a22的技术博客_51CTO博客https://blog.51cto.com/u_16099314/13062727
85 博客 - 平凯数据库敏捷模式:助力数字政务数据中台升级的"新引擎" | TiDB 社区https://tidb.net/blog/a85e4c52
86 HTAP 数据库实战:如何用 TiDB 实现 OLTP 与 OLAP 的无缝切换_tidb olap oltp 如何实现-CSDN博客https://blog.csdn.net/2503_92849134/article/details/149760357
87 TiFlash Overviewhttps://docs.pingcap.com/tidb/dev/tiflash-overview/
88 【赵渝强老师】TiDB的列存引擎:TiFlash-腾讯云开发者社区-腾讯云https://cloud.tencent.cn/developer/article/2514157
89 8.存储引擎TiFlash_用tiflash后clickhouse语法用不用改-CSDN博客https://blog.csdn.net/phoenix9311/article/details/110439190
90 TiFlash:TiDB的列式存储引擎,开启HTAP新时代-CSDN博客https://blog.csdn.net/gitblog_00099/article/details/139877134
91 博客 - 【TiDB 社区升级互助材料】TiFlash 最佳实践& 上线前准备& FAQ | TiDB 社区https://tidb.net/blog/e94628e2
92 TiDB - 体系架构 - 学弟Craze - 博客园https://www.cnblogs.com/jiamiing/p/19025190
93 容灾双活数据中心规范 数据中心双活方案_mob6454cc70863a的技术博客_51CTO博客https://blog.51cto.com/u_16099271/14042918
94 TiDB数据库常用高可用架构_tidb架构图-CSDN博客https://blog.csdn.net/sebastien23/article/details/125038373
95 High Availability with Multi-AZ Deploymentshttps://docs.pingcap.com/tidbcloud/high-availability-with-multi-az
96 Two Data Centers in One City Deploymenthttps://docs.pingcap.com/tidb/v5.4/two-data-centers-in-one-city-deployment
97 Failover and Reprotect Databaseshttps://docs.pingcap.com/tidbcloud/recovery-group-failover/
98 Three Data Centers in Two Cities Deployment | PingCAP Docshttps://docs.pingcap.com/tidb/v5.2/three-data-centers-in-two-cities-deployment
99 DR Solution Based on Multiple Replicas in a Single Clusterhttps://docs.pingcap.com/tidb/dev/dr-multi-replica
100 SeaTunnel与TiDB集成:分布式数据库同步方案-CSDN博客https://blog.csdn.net/gitblog_00824/article/details/151704239
101 两地三中心架构无感切换 - TiDB 的问答社区https://asktug.com/t/topic/1038130
102 知乎 PB 级数据:在线机房迁移之"玩转TiDB迁移"_51CTO博客_机房数据迁移方案https://blog.51cto.com/tidb/13277526
103 单机房部署架构_mob6454cc7aec82的技术博客_51CTO博客https://blog.51cto.com/u_16099345/12717256
104 博客 - 国产数据库"同城两中心"容灾方案对比,TiDB表现优秀 | TiDB 社区https://tidb.net/blog/af773cb8
105 Bidirectional Replicationhttps://docs.pingcap.com/tidb/v8.1/ticdc-bidirectional-replication/
106 Ask If You Don't Understand: TiDB Cluster Migration Across Data Centers (Cloud Regions)https://ask.pingcap.com/t/ask-if-you-dont-understand-tidb-cluster-migration-across-data-centers-cloud-regions/6373
107 博客 - 数据库选型指南:TiDB 与 MySQL 全方位对比清单新鲜出炉! | TiDB 社区https://tidb.net/blog/f86317aa
108 TIDB对比MYSQL_tidb和mysql性能对比-CSDN博客https://blog.csdn.net/hrfhrf32101/article/details/145423199
109 一文读懂 TiDB 数据库:特性、优势及与 MySQL 的对比_tidb和mysql的区别-CSDN博客https://blog.csdn.net/weixin_52755040/article/details/148108394
110 大规模数据存储与处理场景下的 MySQL vs TiDB 对比:性能、扩展性与选型要点-猿码集https://www.yingnd.com/mysql/256345.html
111 博客 - TiDB vs MySQL:马上消费金融在高并发、跨中心热备场景下的实践探索 | TiDB 社区https://tidb.net/blog/2d26b843
112 MySQL vs TiDB:企业级分布式数据库架构对比与选型要点-猿码集https://www.yingnd.com/mysql/257156.html
113 揭秘TiDB与MySQL:五大核心差异,助你选择更优数据库方案 - 云原生实践https://www.oryoy.com/news/jie-mi-tidb-yu-mysql-wu-da-he-xin-cha-yi-zhu-ni-xuan-ze-geng-you-shu-ju-ku-fang-an.html
114 分布式数据库对比:TiDB vs CockroachDB vs YugaByteDB 的性能测评_cockroachdb,tidb是强一致性吗?-CSDN博客https://blog.csdn.net/2503_92849275/article/details/149790554
115 【6.1.0 漫画数据库技术选型】-CSDN博客https://blog.csdn.net/Mr_Qiao93/article/details/149302313
116 博客 - 我当初为什么选择了tidb抛弃了postgresql | TiDB 社区https://tidb.net/blog/180837de
117 TiDB与MySQL、PostgreSQL等数据库的比较分析-阿里云开发者社区https://developer.aliyun.com/article/1461411
118 TiDB vs Traditional Databases: Scalability and Performancehttps://www.pingcap.com/article/tidb-vs-traditional-databases-scalability-and-performance/
119 浅谈 OceanBase、TiDB、CockroachDB 及 AWS DSQL 的对比-数据库技术博客-OceanBase分布式数据库https://open.oceanbase.com/blog/18604396870
120 Deploy TiDB Dashboardhttps://docs.pingcap.com/tidb/v6.1/dashboard-ops-deploy
121 TiDB Dashboard Introductionhttps://docs.pingcap.com/tidb/v6.5/dashboard-intro
122 Access TiDB Dashboardhttps://docs.pingcap.com/tidb/dev/dashboard-access
123 TiUP Overviewhttps://docs.pingcap.com/tidb/stable/tiup-overview
124 TiDB Dashboard Monitoring Pagehttps://docs.pingcap.com/tidb/dev/dashboard-monitoring
125 Access TiDB Dashboardhttps://docs.pingcap.com/tidb-in-kubernetes/v1.5/access-dashboard/
126 Nightingale监控系统监控TiDB:分布式数据库性能指标全解析-CSDN博客https://blog.csdn.net/gitblog_00954/article/details/151256937
127 TiDB-Runtime Grafana 监控页面常用面板解析与实操指南 - 墨天轮https://www.modb.pro/db/1932985375367114752
128 分布式数据库 TiDB 7.0 运维实战指南:高可用、性能优化与自动化-CSDN博客https://blog.csdn.net/cainiao080605/article/details/149956970
129 如何避免索引带来的写热点问题 - TiDB 的问答社区https://asktug.com/t/topic/1038147
130 Monitoringhttps://docs.pingcap.com/tidbcloud/monitoring-concepts/
131 博客 - TEM v3 试用 | TiDB 社区https://tidb.net/blog/a7bf54d6
132 TiDB的性能监控与优化-CSDN博客https://blog.csdn.net/universsky2015/article/details/135809641
133 对比传统数据库TiDB 强在哪谈谈 TiDB 的适应场景和产品能力对比传统数据库TiDB 强在哪谈谈 TiDB 的适应场 - 掘金https://juejin.cn/post/7496375493328158783
134 TiDB【理论篇】01:什么是TiDB【分布式数据库】_tidb数据库-CSDN博客https://blog.csdn.net/weixin_40612128/article/details/148522543
135 博客 - TiDB 替换 HBase 全场景实践指南 ------从架构革新到业务赋能 | TiDB 社区https://tidb.net/blog/c687d474
136 TiDB日常使用规范概述 作为一家全球性的连锁餐饮企业,公司在处理海量数据、复杂业务流程方面面临巨大的挑战。为了解决这些 - 掘金https://juejin.cn/post/7526761867457462323
137 Exploring TiDB's Scalable Distributed SQL Architecturehttps://www.pingcap.com/article/exploring-tidbs-scalable-distributed-sql-architecture-2/
138 TibcoRV架构 tidb架构_mob64ca140d96d9的技术博客_51CTO博客https://blog.51cto.com/u_16213672/14077438
139 TiDB vs OceanBase:国产分布式数据库双雄争霸,技术内核与场景选型深度解析_tidb oceanbase-CSDN博客https://blog.csdn.net/jam_yin/article/details/150026653
140 以TiDB为例解析云原生数据库 - VitoChen - 博客园https://www.cnblogs.com/vitochen/p/18701404
141 The Unified Database for Modern Workloadshttps://www.pingcap.com/tidb/
142 TiDB: Cloud-Native Database for Scalable Digital Transformationhttps://www.pingcap.com/article/tidb-cloud-native-database-for-scalable-digital-transformation/
143 TiDB学习笔记TiDB介绍 什么是TiDB TiDB 是一个分布式的 NewSQL 数据库。它支持水平弹性扩展、ACI - 掘金https://juejin.cn/post/7537902909032480794
144 pd 反虚拟化_mob64ca13fb6939的技术博客_51CTO博客https://blog.51cto.com/u_16213596/13456878
145 第四代至强® 可扩展处理器助TiDB开源分布式数据库实现优化-电子头条-EEWORLD电子工程世界https://m.eeworld.com.cn/news_mp/Intel/a389251.jspx