写在前面:

牛客每日一题持续更新中!
今天给亦菲彦祖们带来的是 小红书推荐系统
题目如下:
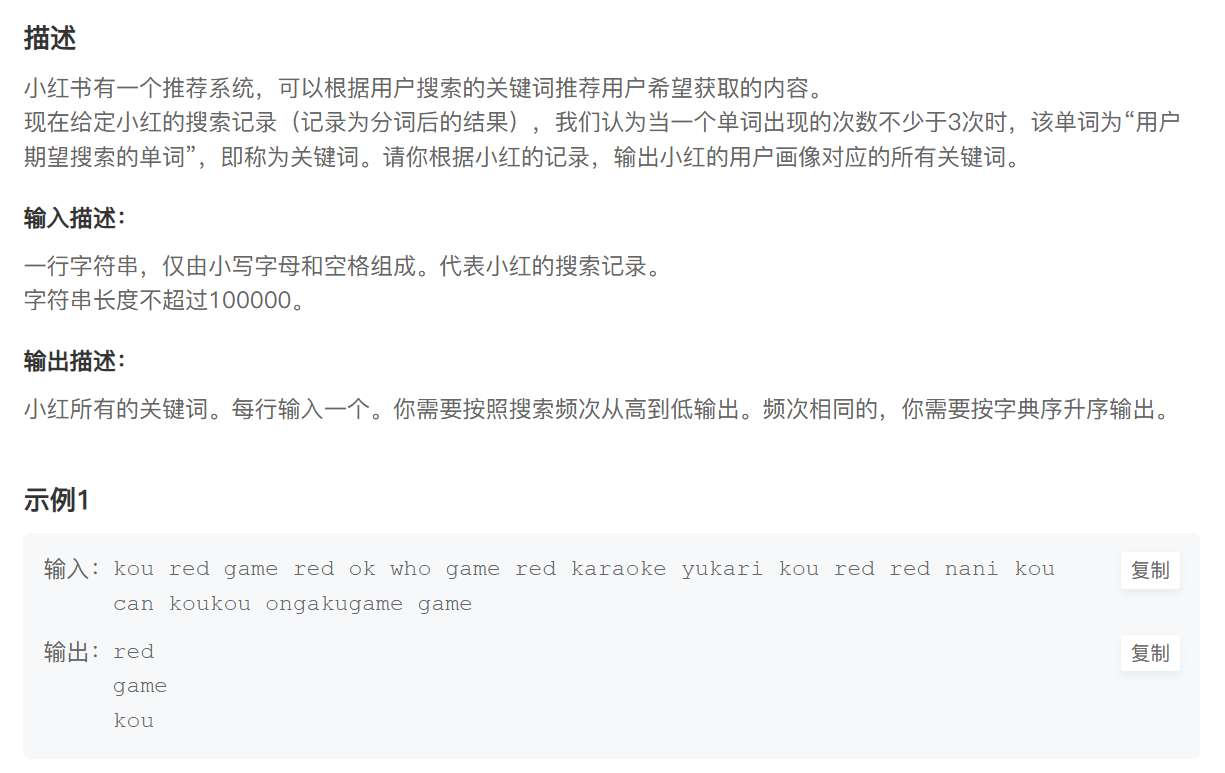
题目描述
根据小红的一份搜索记录(一个由小写字母和空格组成的字符串),找出所有的"关键词"。 一个单词被定义为"关键词",当且仅当它在搜索记录中出现的次数不少于3次。
输出要求:
- 输出所有关键词,每行一个。
- 关键词需要按照出现频次从高到低排序。
- 如果频次相同,则按照字典序升序排序。
解题思路
本题的核心任务是进行词频统计,并根据多重条件对结果进行排序。整个过程可以分解为以下几个步骤:
-
词频统计:
- 首先,我们需要将输入的整个字符串分割成一个个独立的单词。
- 然后,统计每个单词出现的次数。使用哈希表(在C++中是
map,Java中是HashMap,Python中是dict)是实现这一步最有效的数据结构。表的键(key)是单词,值(value)是该单词出现的次数。 - 我们遍历分割后的所有单词,对于每个单词,在哈希表中更新其计数值。
-
筛选关键词:
- 遍历词频统计完成后的哈希表。
- 将所有出现次数大于或等于3次的单词(即关键词)及其频次提取出来,存入一个新的列表或数组中。这个列表中的每个元素都应包含单词和它的频次信息,方便后续排序。
-
自定义排序:
- 这是本题的重点。我们需要对筛选出的关键词列表进行自定义排序。
- 主排序键 :频次,按降序排列。
- 次排序键 :单词本身(字典序),按升序排列。
- 在实现排序比较逻辑时,应先比较两个关键词的频次。如果频次不同,频次高的排在前面。如果频次相同,再比较它们的字典序,字典序小的排在前面。
-
输出结果:
- 遍历排序完成的关键词列表,并逐行输出每个关键词。
代码实现
C/C++版本:
cpp
#include <iostream>
#include <string>
#include <map>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
string input;
getline(cin, input); // 读取整行输入
map<string, int> wordCount; // 存储每个单词出现的次数
// 统计每个单词出现的次数
string word = "";
for (char c : input) {
if (c == ' ') {
if (!word.empty()) {
wordCount[word]++;
word = "";
}
} else {
word += c;
}
}
// 处理最后一个单词
if (!word.empty()) {
wordCount[word]++;
}
// 将符合条件的单词存入vector
vector<pair<string, int>> keywords;
for (auto& p : wordCount) {
if (p.second >= 3) {
keywords.push_back(p);
}
}
// 排序:先按次数降序,次数相同按字典序升序
sort(keywords.begin(), keywords.end(),
[](const pair<string, int>& a, const pair<string, int>& b) {
if (a.second != b.second) {
return a.second > b.second; // 次数多的排前面
}
return a.first < b.first; // 字典序小的排前面
});
// 输出结果
for (auto& kw : keywords) {
cout << kw.first << endl;
}
return 0;
}Python版本:
python
def main():
# 读取输入
input_line = input().strip()
# 统计每个单词出现的次数
word_count = {}
words = input_line.split() # 按空格分割单词
for word in words:
word_count[word] = word_count.get(word, 0) + 1
# 筛选出现次数不少于3次的单词
keywords = []
for word, count in word_count.items():
if count >= 3:
keywords.append((word, count))
# 排序:先按次数降序,次数相同按字典序升序
keywords.sort(key=lambda x: (-x[1], x[0]))
# 输出结果
for word, count in keywords:
print(word)
if __name__ == "__main__":
main()Java版本:
java
import java.util.*;
import java.util.stream.Collectors;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
// 读取输入
String input = scanner.nextLine();
// 统计每个单词出现的次数
Map<String, Integer> wordCount = new HashMap<>();
String[] words = input.split(" ");
for (String word : words) {
if (!word.isEmpty()) {
wordCount.put(word, wordCount.getOrDefault(word, 0) + 1);
}
}
// 筛选出现次数不少于3次的单词
List<Map.Entry<String, Integer>> keywords = new ArrayList<>();
for (Map.Entry<String, Integer> entry : wordCount.entrySet()) {
if (entry.getValue() >= 3) {
keywords.add(entry);
}
}
// 排序:先按次数降序,次数相同按字典序升序
keywords.sort((a, b) -> {
if (!a.getValue().equals(b.getValue())) {
return b.getValue() - a.getValue(); // 次数降序
}
return a.getKey().compareTo(b.getKey()); // 字典序升序
});
// 输出结果
for (Map.Entry<String, Integer> entry : keywords) {
System.out.println(entry.getKey());
}
scanner.close();
}
}好了,各位码友,代码已经调试通过,文章也已commit,就等各位的push了。点赞不要 //TODO,关注务必 star!

写在后面:
