文章目录
- [1. 实战概述](#1. 实战概述)
- [2. 实战步骤](#2. 实战步骤)
-
- [2.1 下载Flume安装包](#2.1 下载Flume安装包)
- [2.2 在master主节点上安装配置Flume](#2.2 在master主节点上安装配置Flume)
-
- [2.2.1 上传Flume安装包到master指定目录](#2.2.1 上传Flume安装包到master指定目录)
- [2.2.2 将Flume安装包解压缩到指定目录](#2.2.2 将Flume安装包解压缩到指定目录)
- [2.2.3 给Flume配置环境变量](#2.2.3 给Flume配置环境变量)
- [2.2.4 编辑自定义Agent配置文件](#2.2.4 编辑自定义Agent配置文件)
- [2.3 在slave1从节点上安装配置Flume](#2.3 在slave1从节点上安装配置Flume)
-
- [2.3.1 从master主节点分发Flume到slave1从节点](#2.3.1 从master主节点分发Flume到slave1从节点)
- [2.3.2 从master主节点分发环境配置文件到slave1从节点](#2.3.2 从master主节点分发环境配置文件到slave1从节点)
- [2.4 在slave2从节点上安装配置Flume](#2.4 在slave2从节点上安装配置Flume)
-
- [2.4.1 从master主节点分发Flume到slave2从节点](#2.4.1 从master主节点分发Flume到slave2从节点)
- [2.4.2 从master主节点分发环境配置文件到slave2从节点](#2.4.2 从master主节点分发环境配置文件到slave2从节点)
- [2.5 测试Flume集群监视日志变化](#2.5 测试Flume集群监视日志变化)
-
- [2.5.1 准备测试日志文件](#2.5.1 准备测试日志文件)
- [2.5.2 启动 Flume Agent](#2.5.2 启动 Flume Agent)
- [2.5.3 模拟日志写入(另开终端)](#2.5.3 模拟日志写入(另开终端))
- [2.5.4 控制台查看新事件](#2.5.4 控制台查看新事件)
- [3. 实战总结](#3. 实战总结)
1. 实战概述
- 本次实战部署了 Apache Flume 1.11.0 分布式日志采集系统,在 master、slave1 和 slave2 三节点完成安装与环境配置,并通过自定义 Agent 配置实现对本地日志文件的实时监听与控制台输出,验证了 Flume 数据采集流程的正确性与稳定性,为后续对接 Kafka 或 HDFS 奠定基础。
2. 实战步骤
2.1 下载Flume安装包
-
下载网址:https://www.apache.org/dyn/closer.lua/flume/1.11.0/apache-flume-1.11.0-bin.tar.gz
-
将
apache-flume-1.11.0-bin.tar.gz下载到本地
2.2 在master主节点上安装配置Flume
2.2.1 上传Flume安装包到master指定目录
-
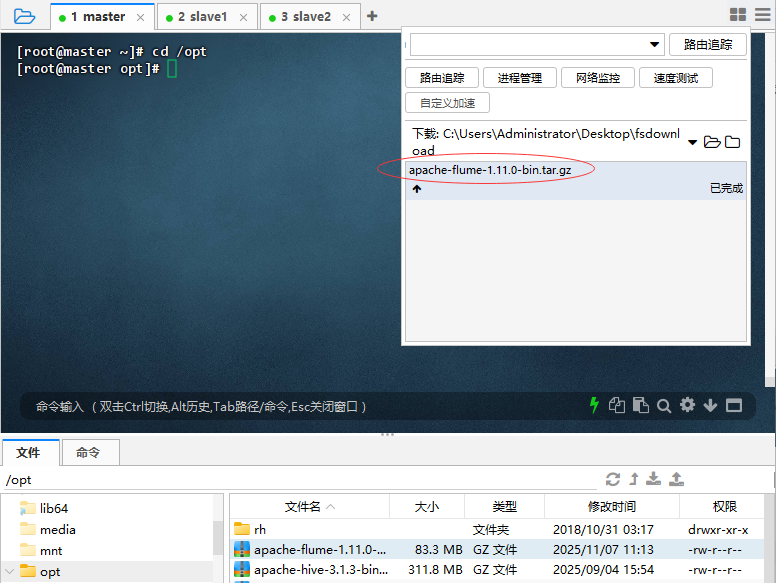
进入
/opt目录,上传Flume安装包
-
执行命令:
ll apache-flume-1.11.0-bin.tar.gz

2.2.2 将Flume安装包解压缩到指定目录
- 执行命令:
tar -zxvf apache-flume-1.11.0-bin.tar.gz -C /usr/local

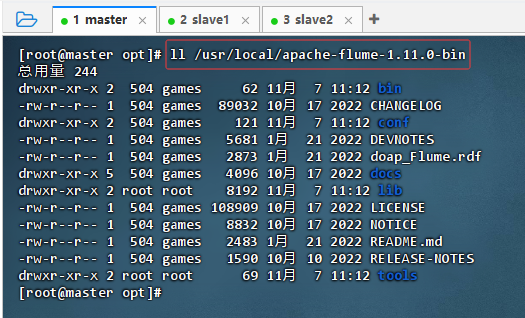
- 执行命令:
ll /usr/local/apache-flume-1.11.0-bin
2.2.3 给Flume配置环境变量
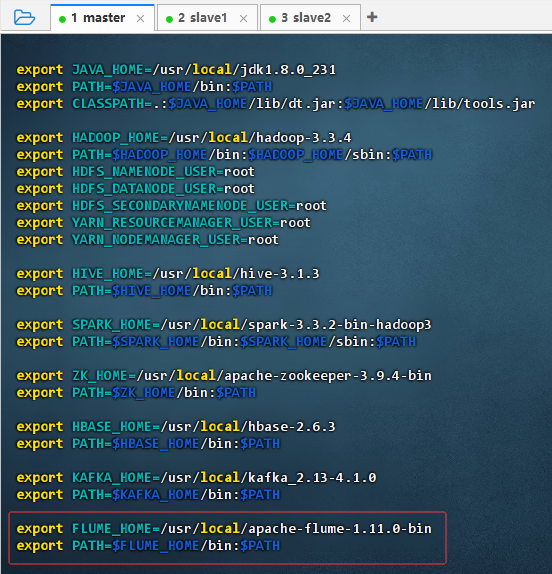
- 执行命令:
vim /etc/profile
- 执行命令:
source /etc/profile,让配置生效
2.2.4 编辑自定义Agent配置文件
-
执行命令:
cd $FLUME_HOME/conf,进入Flume配置目录
-
执行命令:
vim test.conf
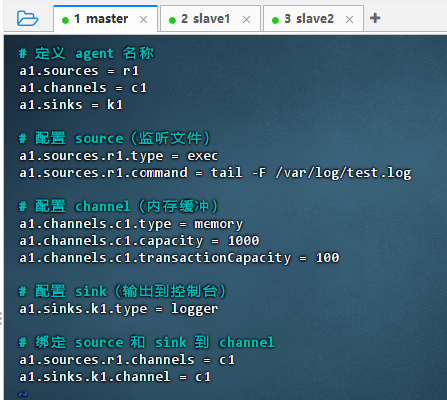 shell
shell# 定义 agent 名称 a1.sources = r1 a1.channels = c1 a1.sinks = k1 # 配置 source(监听文件) a1.sources.r1.type = exec a1.sources.r1.command = tail -F /var/log/test.log # 配置 channel(内存缓冲) a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 配置 sink(输出到控制台) a1.sinks.k1.type = logger # 绑定 source 和 sink 到 channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
配置说明 :该配置定义了一个 Flume Agent,使用
exec源实时监听/var/log/test.log文件新增内容,通过内存通道暂存数据,最终由loggerSink 将事件输出到控制台,适用于日志采集与调试验证。
2.3 在slave1从节点上安装配置Flume
2.3.1 从master主节点分发Flume到slave1从节点
- 执行命令:
scp -r $FLUME_HOME root@slave1:$FLUME_HOME

- 在slave1从节点上执行命令:
ll /usr/local/apache-flume-1.11.0-bin
2.3.2 从master主节点分发环境配置文件到slave1从节点
- 执行命令:
scp /etc/profile root@slave1:/etc/profile
- 在slave1从节点上执行命令:
source /etc/profile,让配置生效
2.4 在slave2从节点上安装配置Flume
2.4.1 从master主节点分发Flume到slave2从节点
-
执行命令:
scp -r $FLUME_HOME root@slave2:$FLUME_HOME

-
在slave2从节点上执行命令:
ll /usr/local/apache-flume-1.11.0-bin
2.4.2 从master主节点分发环境配置文件到slave2从节点
-
执行命令:
scp /etc/profile root@slave2:/etc/profile
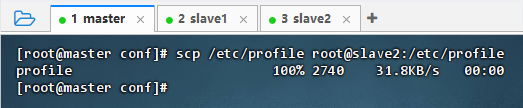
-
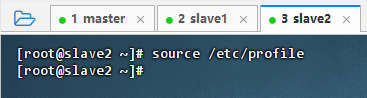
在slave2从节点上执行命令:
source /etc/profile,让配置生效
2.5 测试Flume集群监视日志变化
2.5.1 准备测试日志文件
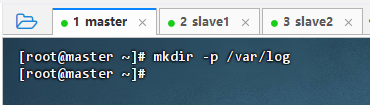
- 在master主节点上执行命令:
mkdir -p /var/log
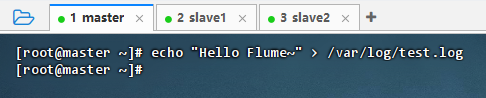
- 执行命令:
echo "Hello Flume~" > /var/log/test.log
2.5.2 启动 Flume Agent
-
在master主节点上执行命令
shellflume-ng agent \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/conf/test.conf \ --name a1 \ -Dflume.root.logger=INFO,console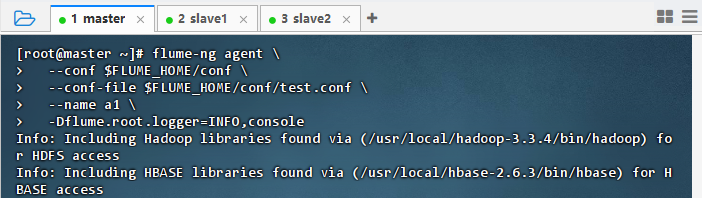
-
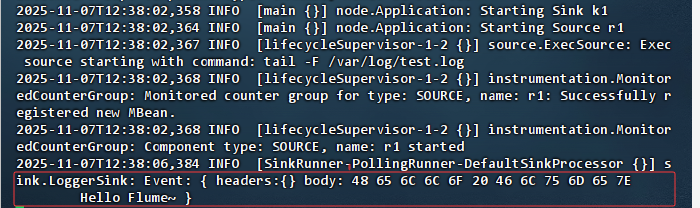
结果说明 :Flume Agent 成功启动并开始监听
/var/log/test.log文件,Source 通过tail -F实时读取日志内容,首次捕获到事件 "Hello Flume~" 并由 Logger Sink 输出原始字节流,表明数据采集流程正常,Agent 已进入稳定运行状态。
2.5.3 模拟日志写入(另开终端)
-
另开一个
master终端
-
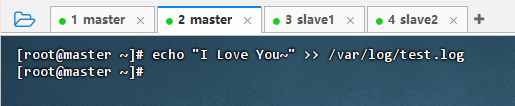
执行命令:
echo "I Love You~" >> /var/log/test.log
2.5.4 控制台查看新事件
- 切换到原来的master终端
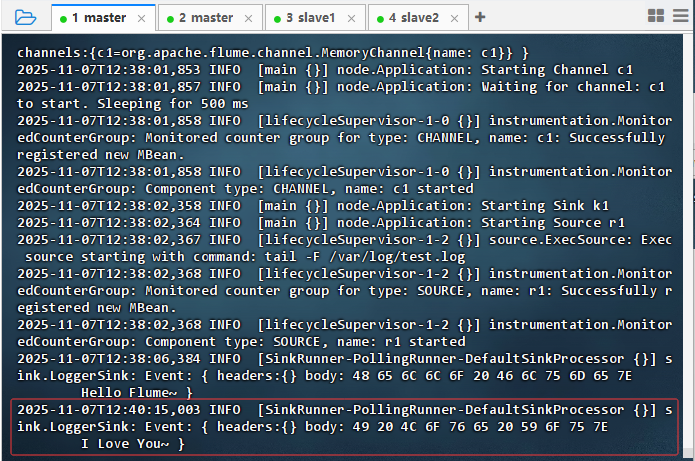
- 结果说明 :Flume 成功捕获新增日志事件,Source 实时监听
/var/log/test.log文件变化,将内容"I love You~"通过内存 Channel 传输至 Logger Sink,并在控制台输出原始字节流,验证了数据采集与传输流程正常。
3. 实战总结
- 本次实战成功完成了 Apache Flume 1.11.0 在三节点集群(master、slave1、slave2)上的部署与配置。通过统一安装目录、配置环境变量并分发配置文件,确保了各节点环境一致性。在 master 节点上编写并测试了基于
execSource、memory Channel 和 logger Sink 的 Agent 配置,成功实现对/var/log/test.log文件的实时监控与事件输出。通过追加日志内容验证了 Flume 的动态采集能力,控制台准确打印新增事件,证明数据流通道畅通。整个过程体现了 Flume 轻量、灵活、高可靠的数据采集特性,为后续构建日志汇聚至 Kafka 或 HDFS 的大数据流水线打下坚实基础。