Flume的数据模型围绕三个核心组件构建:Source(数据源) 、Channel(通道) 和 Sink(数据出口),形成单向数据流管道。以下是详细说明:
1. 数据源(Source)
负责接收或采集数据,支持多种输入类型:
- 日志文件(如
tail -F实时读取) - 网络端口(如 Syslog、HTTP 请求)
- 消息队列(如 Kafka、JMS)
- 自定义数据源(通过 API 扩展)
示例配置:
agent.sources = r1
agent.sources.r1.type = exec
agent.sources.r1.command = tail -F /var/log/app.log2. 通道(Channel)
作为缓冲区,暂存 Source 接收的数据,确保数据传输的可靠性:
- 内存通道(Memory Channel)
数据存于内存,速度快但宕机易丢失。 - 文件通道(File Channel)
数据写入磁盘,可靠性高但延迟增加。 - 事务机制
通过事务保证数据一致性(写入与确认分离)。
事务流程:
- Source 从外部读取数据(如日志行)
- 开启事务,数据存入 Channel
- 提交事务后数据标记为可消费
3. 数据出口(Sink)
从 Channel 取出数据并推送至目的地:
- 存储系统:HDFS、HBase
- 消息系统:Kafka、RabbitMQ
- 聚合节点:下一级 Flume Agent
示例配置:
agent.sinks = k1
agent.sinks.k1.type = hdfs
agent.sinks.k1.hdfs.path = hdfs://cluster/logs/%Y%m%d4. 数据流模型
-
单节点流程
\\text{Source} \\rightarrow \\text{Channel} \\rightarrow \\text{Sink}
-
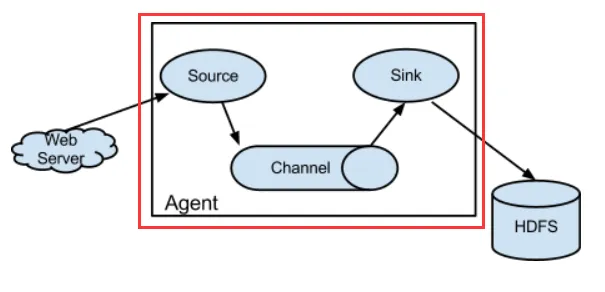
-
多级聚合
多个 Agent 串联,实现负载均衡或逻辑分离:graph LR A[Agent1: Source] --> B[Agent1: Channel] B --> C[Agent1: Sink] --> D[Agent2: Source] D --> E[Agent2: Channel] --> F[Agent2: Sink]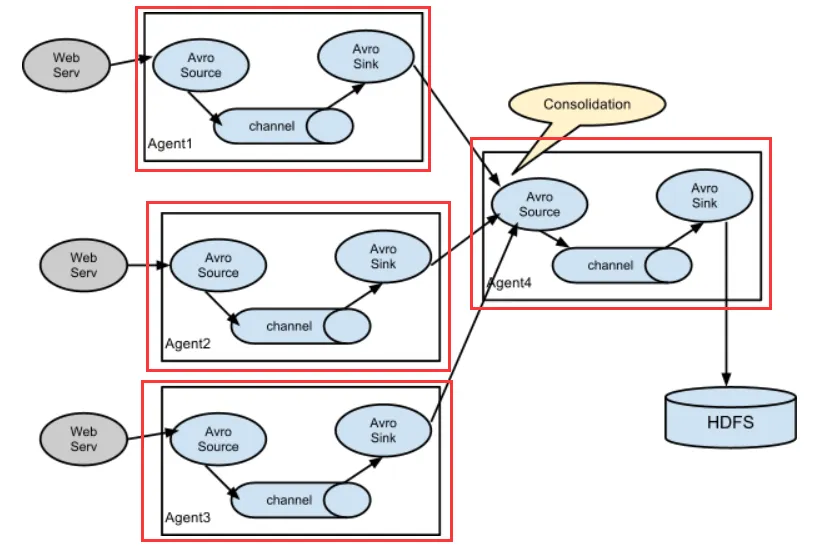
5. 可靠性保障
- 事务批处理
Source 与 Sink 均以批次为单位处理数据(如 100 事件/批)。 - 失败重试
Sink 推送失败时自动重试,直至成功或 Channel 满。 - 通道容量
设置 Channel 大小(如内存通道上限 10000 事件)避免内存溢出。
6. 配置灵活性
通过组合不同组件,适应多样化场景:
# 定义组件类型
agent.sources = http_source
agent.channels = mem_channel
agent.sinks = hdfs_sink
# 绑定关系
agent.sources.http_source.channels = mem_channel
agent.sinks.hdfs_sink.channel = mem_channelFlume 的数据模型通过解耦采集、缓冲与输出,实现了高吞吐、可扩展的日志收集架构,尤其适用于分布式环境下的数据管道构建。