引言
打开 FLume 的官网,想必你可以看到以下内容:

意思很明确,Flume 项目不再维护了。
为何 Flume 停止维护了?
Flume 曾是大数据日志采集的主流工具,但近年来社区活跃度下降,直到在 2024-10-10 宣布停止维护,这背后主要原因包括项目成熟度、生态变化和替代工具的出现。
项目成熟度与生命周期
Flume 于 2011 年捐赠给 Apache 软件基金会,并于2012年成为顶级项目,经过十余年发展已进入稳定阶段,停止维护符合其软件生命周期的自然规律。
生态变化与技术演进
大数据生态系统快速发展,新型工具如SeaTunnel等在数据传输方面提供了更优方案,这些工具在性能、易用性和扩展性上更具优势,导致Flume的维护需求降低。
维护成本与社区资源
随着替代工具的普及,开源社区资源逐渐向更活跃的项目倾斜,维持Flume的更新和维护成本较高,停止维护有助于资源重新分配。
具体影响与现状
Flume停止维护后,用户面临安全更新和新功能支持的缺失,但现有部署在短期内可能仍可运行;社区建议用户评估替代工具以确保数据采集系统的持续可靠性。
对于新手还有必要学习 Flume 吗?
新手和即将进入大数据领域的人来说,你可以(并且应该)将学习 Flume 的优先级降到最低,甚至跳过。 你不必再像以前那样,将其作为大数据入门"必修课"。
因为技术栈的替代不仅是工具的更换,更是架构范式的彻底革新。学习一个已被淘汰的架构范式,对新项目的价值极低。
那是否意味着学习Flume的知识完全无用?
也并非完全无用,但价值已转化为背景常识和排查能力:
-
理解数据流的抽象模型:通过学习Flume的Source, Channel, Sink模型,你可以理解数据采集、缓冲、输出的基本逻辑。这个逻辑在现代工具中依然存在,只是实现方式不同。
-
应对遗留系统:目前仍有大量老旧的大数据平台(特别是基于Hadoop 2.x/CDH旧版本的集群)在生产环境中运行着Flume。如果你需要维护或迁移这类系统,了解Flume有助于你工作。但这属于"被动技能",而非"主动技能"。
-
技术演进的认知:了解Flume有助于你理解为什么Kafka、Flink会成为今天的主流,体会到技术选型中"解耦"、"流批一体"、"高吞吐低延迟"这些概念的重要性。
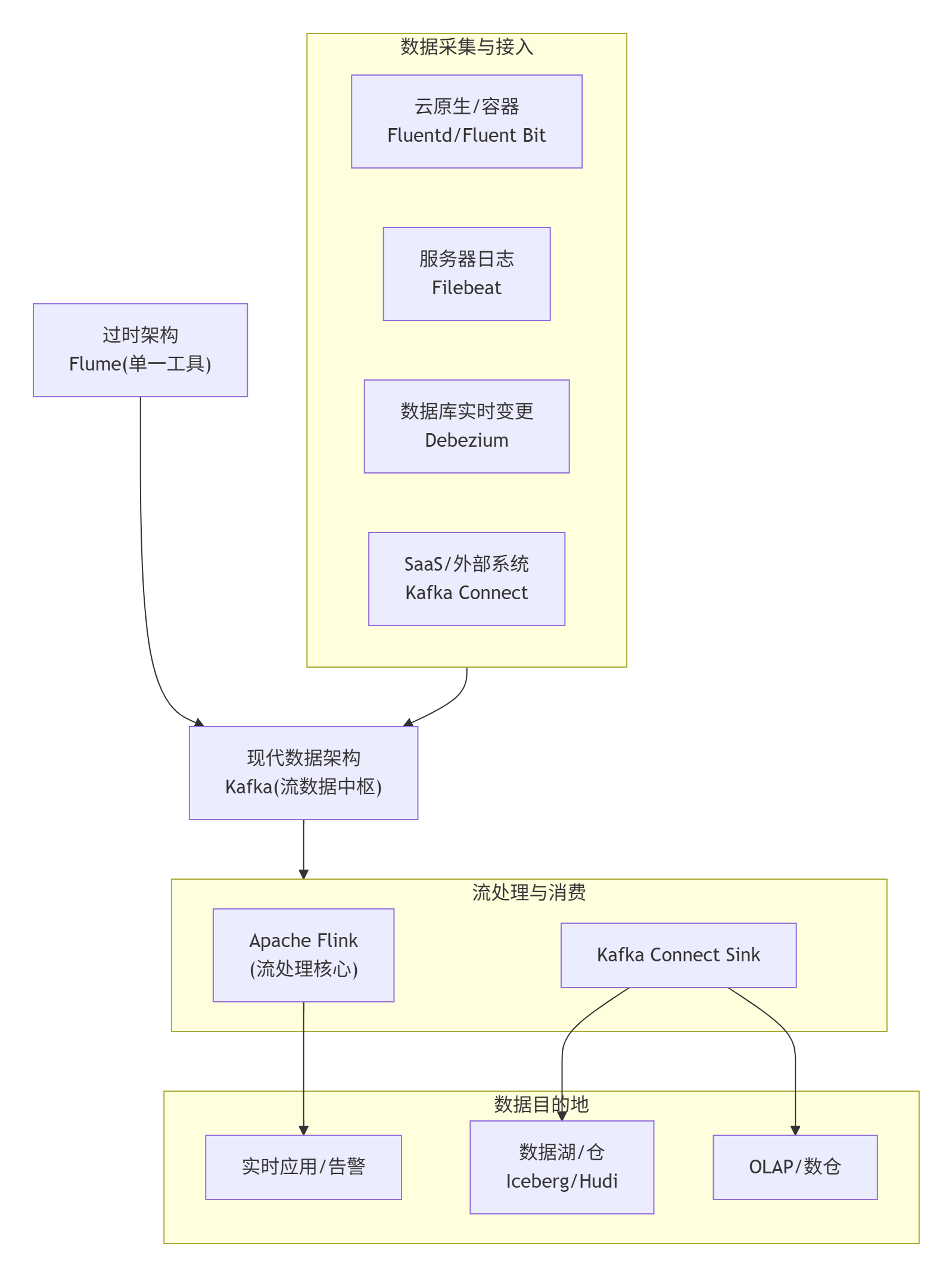
Flume 的继任者是谁呢?
Flume 的"继任者"并不是某一个组件或工具,而是按场景分成了三条路线,企业现在大多按自己的数据规模、实时性要求和已有生态去选型:
日志与指标(云原生/容器环境):Fluentd
使用 Fluentd 或更轻量的 Fluent Bit。收集Kubernetes、Docker及云服务器上的应用日志、系统指标。这是云原生时代的事实标准。
日志/事件流采集:Kafka Connect
如果公司本来就以 Kafka 作为中枢消息系统,直接让 Kafka Connect 接手是最顺的------它原生支持分布式、容错、REST 管理,而且社区在持续维护,插件生态也比 Flume 丰富得多。
日志→检索/可观测:ELK/Beats 栈
需求侧重"采集+检索+可视化"一条龙的团队,现在基本直接用 Elastic 的 Filebeat/Logstash 组合。Filebeat 做轻量采集,Logstash 做解析转换,下游进 Elasticsearch 查询、Kibana 展示,整套方案成熟度高、社区活跃。
数据库实时变更:Debezium
使用 Debezium 将 MySQL、PostgreSQL、MongoDB 等数据库的每一条插入、更新、删除记录实时捕获并流式同步到Kafka。这是实现实时数仓的关键。
场景: 需要将MySQL、PostgreSQL、MongoDB等数据库的每一条插入、更新、删除记录实时捕获并流式同步到Kafka。这是实现实时数仓的关键。
通用数据集成(批+流):SeaTunnel
这是近两年国内最火的新一代集成平台,支持 Flink/Spark 双引擎,一份配置即可跑批任务也能跑实时流,同时提供 Web UI 和监控告警。官方宣称在日志场景下的吞吐是 Flume 的 5--10 倍,而且仍在快速迭代。
总结
因此 Flume 并没有被"某一个"工具完全取代,而是被不同场景下更专业、社区更活跃的产品"分而治之"了。
目前企业主流是一套以 Apache Kafka 为核心中枢,根据数据源选择采集工具的现代架构方案,如下图所示: