引言
SeaTunnel 和 Flume 都是数据集成工具,但它们的设计理念、架构和适用场景有很大不同。让我们来详细比较一下。
核心对比
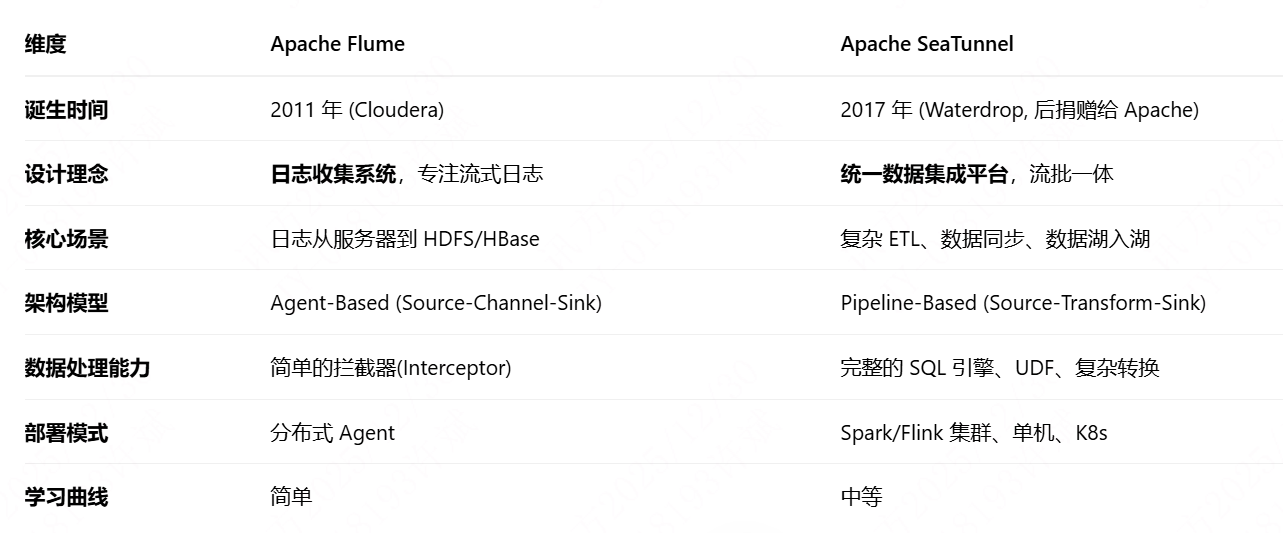
从对比可以看出,Flume 比 SeaTunnel 更老旧,而且 Flume 官网已宣布在2024年10月10日停止维护了。
架构对比
Flume 架构(简单但有限)
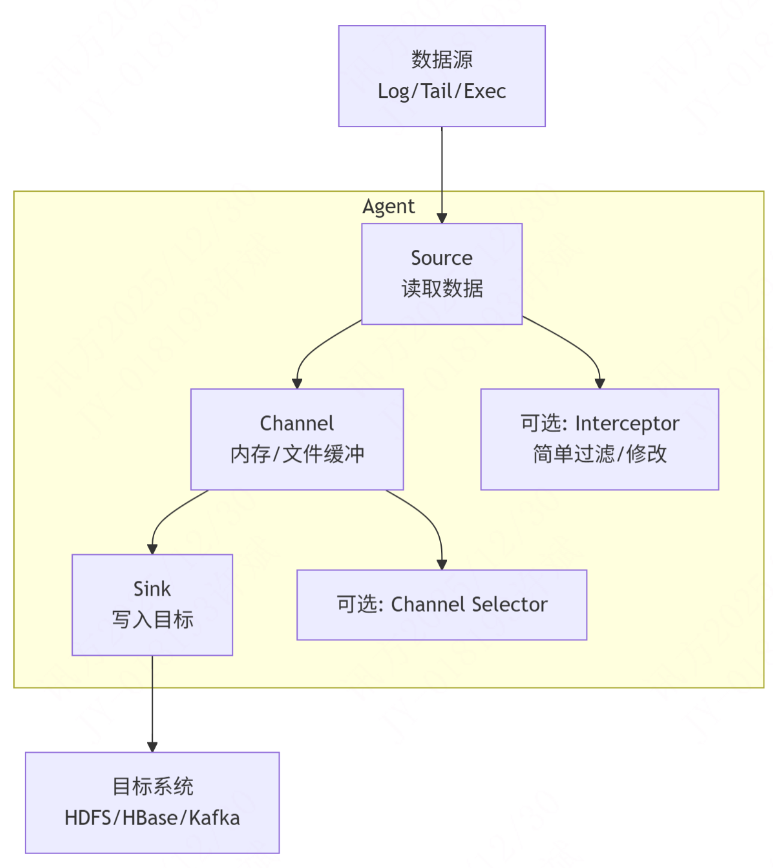
特点:
- 每个 Agent 独立运行
- Channel 提供可靠性保证
- 适合简单的日志搬运
SeaTunnel 架构(强大而灵活)

特点:
- 统一的 Pipeline 模型
- 多种执行引擎选择
- 强大的转换能力
- 丰富的连接器生态
功能详细对比
1. 数据源和目标支持
Flume 支持(非常有限):
bash
# Source: 主要是日志类
exec.source # 执行命令
taildir.source # 文件跟踪
syslog.source # 系统日志
kafka.source # 消费 Kafka
netcat.source # 网络端口
# Sink: 主要是存储系统
hdfs.sink # 写入 HDFS
hbase.sink # 写入 HBase
kafka.sink # 写入 Kafka
logger.sink # 日志输出SeaTunnel 支持(丰富得多):
bash
# Source: 80+ 连接器
数据库: MySQL, PostgreSQL, Oracle, SQL Server, ClickHouse
数据仓库: Snowflake, Redshift, BigQuery
消息队列: Kafka, Pulsar, RocketMQ, RabbitMQ
数据湖: Iceberg, Hudi, Delta Lake
文件系统: HDFS, S3, OSS, FTP, SFTP
API: HTTP, Websocket
日志: File, Log4j
搜索引擎: Elasticsearch, OpenSearch
NoSQL: MongoDB, Cassandra, Redis
实时流: CDC (Debezium)
# Sink: 同样丰富
所有 Source 都可作为 Sink
数据湖/仓写入优化
实时数仓同步
BI 工具对接2. 数据处理能力
Flume 的 Interceptor(非常有限):
bash
# 只能做简单处理(举例如下)
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = timestamp
a1.sources.r1.interceptors.i2.type = host
a1.sources.r1.interceptors.i2.useIP = false
a1.sources.r1.interceptors.i2.hostHeader = hostname
# 正则过滤
a1.sources.r1.interceptors.i3.type = regex_filter
a1.sources.r1.interceptors.i3.regex = ^ERROR.*
a1.sources.r1.interceptors.i3.excludeEvents = falseSeaTunnel 的 Transform(功能强大):
bash
# 功能强大(举例如下)
transform {
# 1. SQL 引擎(完整支持)
Sql {
query = """
SELECT
user_id,
COUNT(*) as pv,
AVG(duration) as avg_duration,
MAX(amount) as max_amount,
-- 窗口函数
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY ts DESC) as rn,
-- JSON 解析
GET_JSON_OBJECT(properties, '$.city') as city,
-- 时间处理
DATE_FORMAT(event_time, 'yyyy-MM-dd HH:mm:ss') as formatted_time
FROM source_table
WHERE event_time >= '2024-01-01'
GROUP BY user_id, DATE(event_time)
"""
}
# 2. 字段操作
FieldMapper {
field_mapper = [
{ from = "old_name", to = "new_name" },
{ from = "timestamp", to = "event_time" }
]
}
# 3. 数据质量检查
Assert {
rules = [
{ rule_type = "NOT_NULL", field_name = "user_id" },
{ rule_type = "MIN", field_name = "age", value = 0 },
{ rule_type = "MAX", field_name = "age", value = 150 },
{ rule_type = "REGEX", field_name = "email", pattern = "^[A-Za-z0-9+_.-]+@(.+)$" }
]
}
# 4. 数据脱敏
Desensitize {
fields = [
{ field_name = "phone", desensitize_type = "PHONE" },
{ field_name = "id_card", desensitize_type = "ID_CARD" },
{ field_name = "email", desensitize_type = "EMAIL" }
]
}
# 5. 自定义 UDF
Python {
script_path = "/path/to/udf.py"
func_name = "enrich_data"
result_table_name = "enriched"
}
# 6. Join 多表关联
Join {
source_table = "orders"
join_table = "users"
join_condition = "orders.user_id = users.id"
join_type = "left"
}
}3. 性能对比

可以看出,SeaTunnel 性能表现比 Flume 好得多。
适用场景对比
Flume 适合场景
- 服务器日志收集:Nginx、Tomcat、应用日志
- 简单数据搬运:A -> B,无需复杂转换
- 轻量级部署:资源有限的边缘服务器
- 运维简单:配置简单,Agent 独立
SeaTunnel 适合场景
- 复杂 ETL 处理:需要 SQL、Join、聚合
- 实时数据处理:毫秒级延迟要求
- 多源多目标同步:一个作业处理多个系统
- 数据质量管控:需要数据校验、脱敏
- 云原生部署:K8s、容器化环境
- 数据湖入湖:CDC 同步到 Iceberg/Hudi
优势对比总结
SeaTunnel 的核心优势
1. 统一流批处理
2. 强大的数据处理能力
- 完整 SQL 支持
- 多表 Join
- 窗口函数
- 自定义 UDF
- 数据质量检查
3.丰富的连接器生态
- 80+ 官方连接器
- 支持现代数据栈(数据湖、云数仓)
- 持续更新
4. 企业级特性
- 数据质量检查
- 数据脱敏
- 多目标写入
- 监控指标
5. 云原生支持
- 原生 K8s 支持
- 容器化部署
- 自动扩缩容
Flume 的核心优势
- 简单可靠:配置简单,Agent 独立
- 轻量级:资源消耗小
- 日志专用:为日志收集优化
- 成熟稳定:多年生产验证
演进趋势
新项目除非是极其简单的日志收集场景,否则推荐使用 SeaTunnel,功能更全面,生态更活跃,它代表了现代数据集成的发展方向。