文章目录
- 前言
- 一、Flume基本介绍
-
- (一)什么是Flume
-
- 1.Concept
- 2.features
-
- [(1)Distributed 分布式](#(1)Distributed 分布式)
- [(2)Reliable and available 可靠和可用](#(2)Reliable and available 可靠和可用)
- [(3)High throughput 高吞吐量](#(3)High throughput 高吞吐量)
- [(4)Flexibility 灵活性](#(4)Flexibility 灵活性)
- [(5)Scalability 可扩展性](#(5)Scalability 可扩展性)
- [(6)Customization of data source and data receiver](#(6)Customization of data source and data receiver)
- [(7)ETL processing ETL处理](#(7)ETL processing ETL处理)
- [(8)Support multiple data flow models 支持多种数据流模型](#(8)Support multiple data flow models 支持多种数据流模型)
- 3.应用场景
-
- [(1)log collection 日志收集](#(1)log collection 日志收集)
- [(2)Data integration 数据集成](#(2)Data integration 数据集成)
- [(3)real time analysis 实时分析](#(3)real time analysis 实时分析)
- 4.Advantages
- 5.Structure
- 6.version
-
- (1)types
- [(2)the comparison between flume-og and flume-ng](#(2)the comparison between flume-og and flume-ng)
- [二、Flume Data Flow Model](#二、Flume Data Flow Model)
-
- [(一)the core concept and function](#(一)the core concept and function)
- (二)Reliability
- (三)Recoverability
- [三、Flume Core Component](#三、Flume Core Component)
-
- (一)Source
-
- 1.types
- [2.Exec Source](#2.Exec Source)
- [3.Spooling Directory Source](#3.Spooling Directory Source)
- [4.Taildir Source](#4.Taildir Source)
- [5.Kafka Source](#5.Kafka Source)
- [6.HTTP Source](#6.HTTP Source)
- (二)Channel
- (三)Sink
-
- 1.types
- [2.HDFS Sink](#2.HDFS Sink)
- [3.File Roll Sink](#3.File Roll Sink)
- [4.Null Sink](#4.Null Sink)
- [5.HBase2 Sink](#5.HBase2 Sink)
- [6.Kafka Sink](#6.Kafka Sink)
- [四、Flume complex data flow model design](#四、Flume complex data flow model design)
-
- [(一)Simple series connection 简单串联](#(一)Simple series connection 简单串联)
- [(二)Replication and multiplexing 复制和复用](#(二)Replication and multiplexing 复制和复用)
- [(三)Load balancing and failover 负载平衡和故障转移](#(三)Load balancing and failover 负载平衡和故障转移)
- [(四)Polymerization 聚合](#(四)Polymerization 聚合)
- 总结
前言
Apache Flume是一种分布式服务,旨在有效地收集、聚合和移动大量日志数据到集中式存储系统,如HDFS。 它具有具有源、通道和接收器的灵活架构,支持来自各种来源的可靠数据流。 Flume具有高度可扩展性和可定制性,支持日志聚合和实时数据分析等多种用例。 它与Hadoop生态系统的集成使其成为大数据管道的关键工具,确保可靠高效的数据摄取和传输。
一、Flume基本介绍
(一)什么是Flume
1.Concept
Apache Flume是一种分布式、高可靠性、高可用性 的工具,用于收集、聚合大量日志数据 ,并将其从不同来源 传输到中央数据仓库。它是Apache软件基金会(ASF)的顶级项目。Flume支持自定义日志系统中的各种数据发送者来收集数据,同时,Flume还提供了简单处理数据和向各种数据接收者写入数据的能力(可自定义)。
Apache Flume is a distributed, highly reliable, and highly available tool for collecting, aggregating, and transferring large amounts of log data from different sources to the central data warehouse. It is the top project of the Apache Software Foundation (ASF). Flume supports customizing various data senders in the log system to collect data; At the same time, Flume provides the ability to simply process data and write to various data receivers (customizable).
Flume最初是一个由Cloudera提供的日志收集系统,是Apache下的一个孵化项目。 Flume支持在日志系统中定制各种数据发送器来收集数据。
Flume was originally a log collection system provided by Cloudera and an incubation project under Apache. Flume supports customizing various data senders in the log system to collect data.
Flume的设计使其成为一个高吞吐量的数据传输系统 ,特别适合处理大规模测井数据的采集和传输。
Flume's design makes it a high throughput data transmission
system, especially suitable for handling the collection and transmission of large-scale log data.
2.features
Flume在大数据生态系统中应用广泛。 它与Hadoop、HBase等大数据技术紧密结合,支持高效的数据采集和传输。 其主要特点包括:
(1)Distributed 分布式
Flume是一种分布式服务,可以从多个数据源收集数据 ,并将其传输到集中的数据存储系统,如:Hadoop HDFS或HBase。
Flume is a distributed service that can collect data from multiple data sources and transfer it to a centralized data storage system, such as Hadoop HDFS or HBase.
(2)Reliable and available 可靠和可用
Flume具有高可靠性和高可用性 ,保证数据在传输过程中不丢失,适合处理大规模日志数据的采集和传输。
Flume is designed for high reliability and availability, ensuring that data will not be lost during transmission, and is suitable for handling the collection and transmission of large-scale log data.
(3)High throughput 高吞吐量
Flume可以处理大规模的数据流 ,具有高吞吐量的数据传输能力 ,适合处理大量的日志数据。
Flume can handle large-scale data streams and has high throughput data transmission capability, which is suitable for processing large amounts of log data.
(4)Flexibility 灵活性
Flume支持多个数据源和数据存储目标,通过配置不同类型的Source、Channel和Sink,可以满足不同的数据传输需求。
Flume supports multiple data sources and data storage targets, and can meet different data transmission requirements by configuring different types of Source, Channel, and Sink.
(5)Scalability 可扩展性
Flume可以通过增加代理数量来水平扩展 ,以应对数据量的增长。
Flume can expand horizontally by increasing the number of agents to cope with the growth of data volume.
(6)Customization of data source and data receiver
Flume允许用户自定义数据源和数据接收器,以满足不同的数据采集和传输需求。
Flume allows users to customize data source and data receiver to
meet different data collection and transmission requirements.
(7)ETL processing ETL处理
Flume可以通过使用拦截器对数据执行简单的ETL处理。
Flume can perform simple ETL processing on data by using interceptors.
(8)Support multiple data flow models 支持多种数据流模型
通过连接多个Flume agent ,可以实现多级agent、扇入扇出数据流模型等,以应对更复杂的使用场景和需求。
By connecting multiple Flume Agents, you can realize multi-level agents, fan in and fan out data flow models, etc., to cope with more complex use scenarios and requirements.
3.应用场景
Flume的易用性和高可靠性使其成为大数据领域数据采集和传输的重要工具。 主要应用场景有:
(1)log collection 日志收集
Flume常用于分布式系统日志数据的采集和传输。 Web服务器、应用服务器、数据库等产生的日志数据 ,可以通过Flume传输到HDFS、HBase或Elastic search等集中存储系统,实现统一存储和分析。
Flume is often used to collect and transmit log data of distributed systems. Log data generated by Web servers, application servers, databases, etc. can be transferred to centralized storage systems such as HDFS, HBase, or Elastic search through Flume for unified storage and analysis.
(2)Data integration 数据集成
Flume可以作为数据集成工具,将不同来源的数据集成到统一的存储平台中 。 数据可以从多个数据源(如数据库、文件系统、消息队列)采集,并传输到目标存储系统。如HDFS、Kafka、HBase
Flume can be used as a data integration tool to integrate data from different sources into a unified storage platform. Data can be collected from multiple data sources such as databases, file systems, message queues, and transferred to the target storage system, such as HDFS, Kafka, or HBase.
(3)real time analysis 实时分析
Flume可以与实时分析系统集成,实现实时数据采集和分析 。 数据可以通过Flume传输到实时分析引擎,如Apache Storm、Apache Spark、Apache Flink等,实现数据的实时处理和分析。
Flume can integrate with the real-time analysis system to achieve real-time data collection and analysis. Data can be transferred to a real-time analysis engine through Flume, such as Apache Storm, Apache Spark,
or Apache Flink, to achieve real-time data processing and analysis.
系统指标和应用性能数据可以通过Flume(如Prometheus、Grafana或Nagios)传输到监控系统,实现实时监控和报警。
4.Advantages
-
Flume可以将应用产生的数据存储到任何集中式存储 中,如HDFS和HBase。
Flume can store data generated by applications in any centralized storage, such as HDFS and HBase.
-
当收集数据的速度超过写入的数据,即收集的信息遇到峰值 时,收集的信息非常大,甚至超过系统写入数据的能力 。
When the speed of data collection exceeds the data to be written, that is, when the collected information encounters a peak, the collected information is very large, even exceeding the system's ability to write data.
-
此时,Flume会在数据生产者和数据接收者 之间进行调整,以确保在两者之间能够提供稳定的 数据。
At this time, Flume will make adjustments between the data producer and the data receiver to ensure that it can provide stable data between the two.
-
支持多路径流量、多管道接入流量、多管道出站流量、上下文路由 等。
Support multi-path traffic, multi pipe access traffic, multi pipe outgoing traffic, context routing, etc.
-
Flume的流水线是基于事务的 ,这保证了数据传输和接收的一致性 。
Flume's pipeline is transaction based, which ensures the consistency of data transmission and reception.
-
Flume具有可靠、容错、可扩展、易于管理和可定制 的特点
Flume is reliable, fault tolerant, scalable, easy to manage, and customizable
-
除了日志信息,Flume还可以用来访问和收集大型社交网络节点事件 数据,如
Facebook、Twitter、电子商务网站如Amazon、flipkart等。In addition to log information, Flume can also be used to access and collect large-scale social network node event data,
such as Facebook, Twitter, e-commerce sites such as Amazon, flipkart, etc.
5.Structure

(1)Event
带有可选消息头 的数据单元,它是Flume数据传输的基本单元 ,以事件的形式将数据从源发送到目标
Event: a data unit with an optional message header, the basic unit of Flume data transmission, which sends data from the source to the destination in the form of an event
(2)Agent
一个独立的Flume进程 ,负责数据收集 ,包括Source、Channel和Sink组件
Agent: an independent Flume process responsible for data collection, including the components Source, Channel and Sink
(3)Source
数据源,用于使用传递给组件 的事件。每个代理都可以有一个数据源
Source: data source, which is used to consume the events passed to the component.Each agent can have a data source
(4)Channel
连接源节点和Sink节点 ,这是一种队列 ,是传输事件 的临时存储
connect the Source and Sink, which is a sort of queue, a temporary storage of transit events
(5)Sink
输出端,从channel中读取并删除事件,并将事件传递给Flow管道中的下一个代理(如果有的话)
Sink: output end, which reads and removes the event from the channel, and passes the event to the next agent (if any) in the Flow Pipeline
整个Flume实际上是一个代理函数 。它从源接收数据 ,并通过信道传输给Sink 。如果有大数据需要处理,它会直接去Sink提取数据。Flume从数据源收集数据到Sink。
The entire Flume is actually an agent function. It receives data from the Source and transmits it to Sink through the Channel. If there is big data to process, it will directly go to Sink to extract data. Flume is to collect data from the Source to Sink.
要在单个代理中定义流 ,您需要通过通道连接源和sink 。您需要在配置文件中列出所有源、sink和通道,然后将源和通道指向通道。一个源可以连接到多个信道,但一个sink只能连接到一个信道。
To define the flow in a single agent, you need to connect the source and sink through the channel. You need to list all sources, sinks, and channels in the configuration file, and then point source and sink to channels. A source can connect to multiple channels, but a sink can only connect to one channel.
6.version
(1)types
- Flume 0.9X version is collectively called Flume-og
- Flume 1.X version is collectively called Flume-ng
- Flume-ng与Flume-og非常不同,因为它经历了大规模的重建。 使用Flume ng时请注意区别。
(2)the comparison between flume-og and flume-ng
| 比较方面 | Flume-og | Flume-ng |
|---|---|---|
| 版本 | Flume 0.9X | Flume 1.X |
| 架构模式 | 采用 multi-master mode (多主模式),依赖中心化的 Master 节点进行管理。 | 移除了 Master 和 Zookeeper ,成为纯传输工具,架构更轻量、去中心化。 |
| 配置管理 | 引入 Zookeeper 保存配置数据,确保一致性和高可用性;Zookeeper 可通知 Master 配置变更。 | 无中心配置管理,配置更简单,但需通过其他方式(如文件)管理,Zookeeper 被移除。 |
| 数据同步 | Master 节点间使用 gossip protocol 同步配置数据。 | 不涉及 Master 数据同步,各节点独立运行。 |
| 线程模型 | 数据读入和写出由同一线程处理(读入线程也负责写出),属于同步设计。 | 数据读入和写出由不同 worker 线程 (称为 Runners)处理,属于异步设计。 |
| 性能影响 | 如果写出慢(非完全失败),会阻塞 Flume 接收数据,可能降低吞吐量。 | 异步设计使读入线程不受下游问题影响,避免阻塞,提升稳定性和吞吐量。 |
| 设计目标 | 强调配置集中管理和一致性,适合复杂、需高可用配置的场景。 | 强调轻量传输和异步处理,简化部署,适合高吞吐、低延迟的数据流。 |
- flume-og 依赖 Zookeeper 和 Master 实现中心化管理,线程模型为同步,可能阻塞。
- Flume-ng 移除了这些组件,采用异步线程模型(Runners),避免阻塞,更适合大规模数据传输。
- 关键变化:从有状态、中心化转向无状态、去中心化;从同步处理转向异步处理。
二、Flume Data Flow Model
(一)the core concept and function
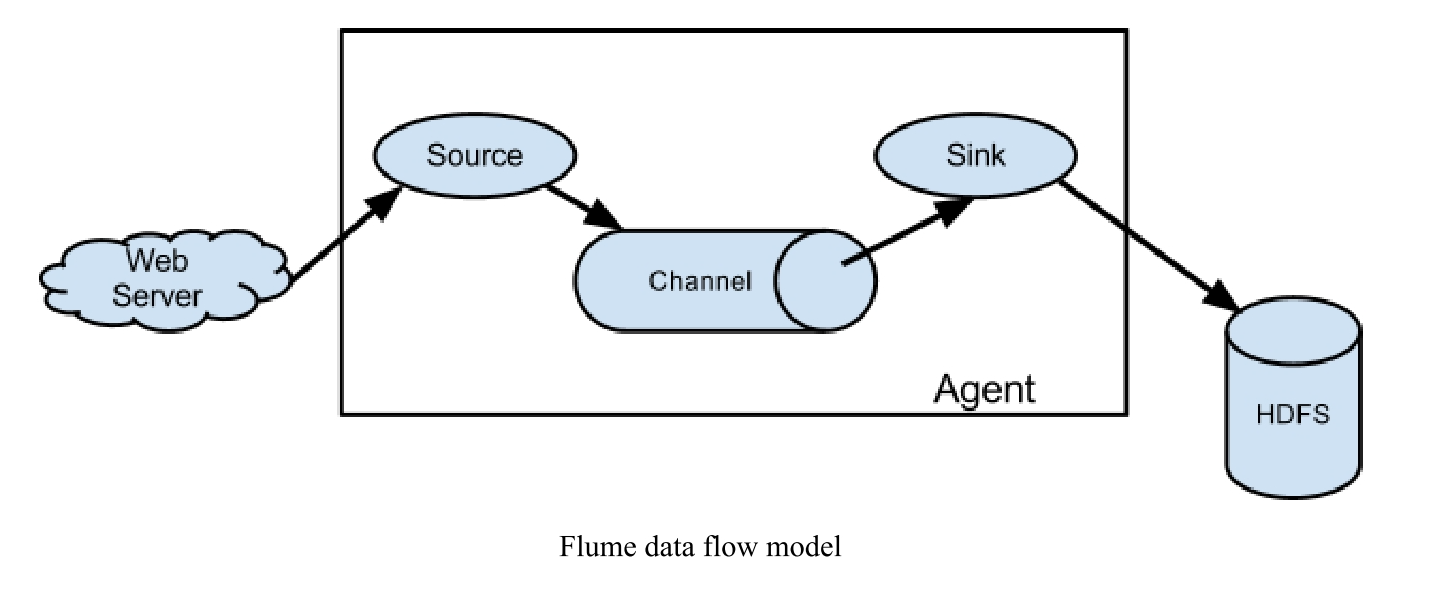
1.Event
事件是Flume定义的数据流传输的最小单位 。 代理本质上是一个JVM进程,控制从外部日志生成器到目的地(或下一个代理)的事件数据流传输。
Event is the smallest unit ofdata stream transmission defined by Flume. An agent is an instance ofFlume, which is essentially a JVM process that controls the transmission ofevent data stream from the external log producer to the destination (or the next agent).
要学习Flume,你必须理解这些概念。 Event在英文中是Event,但它代表了Flume中数据传输的最小单位(Flume收集到的每一个日志或者二进制文件,不管你在外面怎么称呼,进入Flume后都叫Event)。
To learn Flume, you must understand these concepts. Event is an event in English, but it represents the smallest unit of data transmission in Flume (every log or binary file collected by Flume, no matter what you call it outside, it is called event after entering Flume).
2.Source
源使用外部(如Web服务器)传递给它的事件。 外部以Flume Source识别的格式向Flume发送事件。 例如,Avro Source可以从Avro客户端(或其他flumesink)接收Avro事件。 类似的过程可以用Thrift Source实现。 接收到的事件数据可以用任何语言编写,只要它符合Thrift协议。
The Source consumes the Event passed to it by an external (such as a Web server). Externally send events to Flume in the format recognized by Flume Source. For example, Avro Source can receive Avro Events from Avro clients (or other FlumeSink).Similar processes can be implemented with Thrift Source. The received event data can be written in any language as long as it conforms to the Thrift protocol.
3.Channel
此通道是一个被动存储(或存储池),可以存储事件,直到它被Sink使用。 文件通道就是一个例子,它被本地文件系统所支持。 Sink将事件从通道中移除,并将其放置在外部存储库中(如HDFS,由Flume的HDFS Sink实现),或者将其转发到流中下一个Flume Agent(下一跳)的Flume Source。
This channel is a passive storage (or storage pool) that can store events until it is consumed by Sink. The file channel is an ex-ample - it is supported by the local file system. Sink removes the event from the channel and places it in an external repository(such as HDFS, which is implemented by Flume's HDFS Sink) or forwards it to the Flume Source of the next Flume Agent(next hop) in the stream.
代理中的源、接收和通道访问事件是异步的。
- Flume的Source负责消费从外部传递给它的数据(比如web服务器日志)。 外部数据生产者以Flume Source能识别的格式向Flume发送事件。
(二)Reliability
-
事件将缓存在每个代理的通道 上,然后将事件传递到流中的下一个代理或目的地(如HDFS)。 事件在成功发送到下一个代理或目的地之前不会从通道中删除。 此步骤确保事件数据流在Flume代理中传输时的端到端可靠性。
-
The event will be cached on the channel of each agent , and then the event will be passed to the next agent or destination in
the stream (such as HDFS). The Event will not be deleted from the Channel until it is successfully sent to the next Agent or
destination. This step ensures the end-to-end reliability of the event data stream when it is transmitted in Flume's agent.
-
Flume使用事务来确保事件的可靠传输。 Source和Sink分别封装了一个事务 ,用于存储和恢复通道提供的每个事件数据,从而确保了数据流集合在点到点之间的可靠传输。 在多层体系结构的情况下,来自前一层的接收器和来自下一层的源都将运行事务,以确保数据安全地传输到下一层的通道。
-
Flume uses transactions to ensure reliable transmission of events. Source and Sink respectively encapsulate a transaction for storage and recovery of each event data provided by the Channel, which ensures the reliable transmission of data stream collections from point to point. In the case of multi tier architecture, both the sink from the previous layer and the source from the next layer will have transactions running to ensure that the data is safely transferred to the channel of the next layer.
(三)Recoverability
事件数据将缓存在通道中,以便在发生故障时进行恢复。 Flume既支持存储在本地文件系统中的"文件通道",也支持存储在内存中的"内存通道"。 "内存通道"显然更快。 缺点是,如果代理挂起,"内存通道"中的缓存数据将丢失。
Event data will be cached in the channel for recovery in case of failure. Flume supports both the "file channel"stored in the local file system and the "memory channel"stored in memory. The "memory channel"is obviously faster. The disadvantage is that if the agent hangs up, the cached data in the "memory channel"will be lost.
三、Flume Core Component
(一)Source
1.types
| Source 类型 | 核心功能与特点 | 关键考点与注意事项 |
|---|---|---|
| Avro Source | 支持 Avro RPC 协议,Flume 内置支持 ,常用于Agent间通信 | 1. 基于Avro协议 2. 内置支持,无需额外插件 3. 常用于多级Flume架构 |
| Thrift Source | 支持 Thrift 协议,Flume 内置支持 | 1. 另一种RPC协议 2. 内置支持 3. 与Avro Source相似但协议不同 |
| Exec Source | 执行Unix命令,读取其**标准输出(stdout)**作为数据源 | 1. 实时性高但不可靠 2. 进程重启后数据丢失 3. 常用于读取tail -F等命令输出 |
| Spooling Directory Source | 监控指定目录 的文件变化,读取新文件内容 | 1. 可靠性高 (文件读取后会被标记或移动) 2. 支持断点续传 3. 文件必须不可变(写入完成后才能读取) |
| Taildir Source | 监控多个文件 ,实时读取新增行 | 1. 支持实时监控多个文件 2. 记录读取位置(offset),可靠性高 3. 常用于日志收集场景 |
| Kafka Source | 作为Apache Kafka消费者,从Kafka主题读取消息 | 1. 集成Kafka ,用于流式数据 2. 支持高吞吐 3. 需要配置Kafka连接参数 |
| HTTP Source | 通过HTTP POST/GET 接收数据,支持JSON和BLOB格式 | 1. 提供HTTP接口接收数据 2. 支持RESTful风格 3. 常用于接收应用程序发送的数据 |
| NetCat TCP Source | 监听TCP端口 ,将接收到的行文本数据转换为Event | 1. 基于TCP协议 2. 按行解析数据 3. 常用于测试或简单数据接收 |
| NetCat UDP Source | 监听UDP端口,功能类似TCP版本 | 1. 基于UDP协议 2. 无连接,可靠性较低 |
| JMS Source | 从JMS系统(消息队列/主题)读取数据 | 1. 支持Java消息服务 2. 测试过ActiveMQ 3. 需要配置JMS连接工厂 |
| Syslog Sources | 读取syslog数据 ,支持UDP和TCP协议 | 1. 系统日志收集 2. 支持两种传输协议 3. 常用于收集服务器系统日志 |
| Sequence Generator Source | 生成序列数据 ,主要用于测试 | 1. 内置数据生成器 2. 性能测试和功能验证 |
| Twitter 1% Firehose Source | 通过Twitter API连续下载数据(实验阶段) | 1. 实验性功能 2. 获取Twitter流数据 |
| Stress Source | 内部负载生成源 ,用于压力测试 | 1. 性能测试工具 2. 模拟高负载数据流 |
| Custom Source | 自定义Source,实现Source接口自行开发 | 1. 扩展性 考点 2. 需实现特定接口 3. 满足特殊数据源需求 |
| Legacy Sources | 兼容**Flume OG(0.9.x版本)**的旧Source | 1. 向后兼容性 2. 旧版本迁移考虑 |
接下来,将详细描述Exec Source, Spooling Directory Source, Taildir Source, Kafka Source和HTTP Source的使用。
可靠性对比
- 高可靠性:Spooling Directory、Taildir(有状态记录)
- 低可靠性:Exec Source、NetCat UDP(无状态或不可靠协议)
使用场景
- 日志收集:Taildir、Syslog
- 流数据集成:Kafka、JMS
- 文件传输:Spooling Directory
- 测试用途:Sequence Generator、Stress Source
- 自定义需求:Custom Source
协议与通信方式
- RPC协议:Avro、Thrift
- 消息队列:Kafka、JMS
- HTTP接口:HTTP Source
- 网络协议:TCP/UDP(NetCat、Syslog)
2.Exec Source
该源在启动时运行给定的Unix命令,并期望进程在标准输出上连续生成数据(除非log stderr属性设置为true,否则stderr信息将被丢弃)。如果进程因任何原因退出,源也将退出,不再继续生成数据。
Exec Source:- The source runs the given Unix command at startup and expects the process to generate data continuously on the standard output (stderr information will be discarded unless the attribute log StdErr is set to true). If the process exits for any reason, the source will also exit and will not continue to generate data.
cat named pipe和tail -F file都可以连续输出内容。 不能连续输出内容的命令不能执行。 注意,cat命令后面的参数名为pipe,而不是文件
3.Spooling Directory Source
该源允许您通过将要采集的文件放置到磁盘上的"Spooling"目录中来采集数据。
This source lets you ingest data by placing files to be ingested into a "spooling" directory on disk.
**该源将监视指定目录中的新文件,并在新文件出现时解析事件。**事件解析逻辑是可插入的。在给定文件完全读入通道后,默认情况下通过重命名文件来表示完成 ,也可以删除文件,或者使用trackerDir跟踪处理过的文件。
his source will watch the specified directory for new files, and will parse events out of new files as they appear. The event parsing logic is pluggable. After a given file has been fully read into the channel, completion by default is indicated by renaming the file or it can be deleted or the trackerDir is used to keep track of processed files.
4.Taildir Source
监视指定的文件,并几乎实时地跟踪它们,一旦检测到新行附加到每个文件。如果新行正在写入,该源将重试读取它们,等待写入完成。
Watch the specified files, and tail them in nearly real-time once detected new lines appended to the each files. If the new lines are being written, this source will retry reading them in wait for the completion of the write.
该源是可靠的,即使尾迹文件旋转也不会丢失数据。它定期将每个文件的最后一个读位置以JSON格式写入给定位置文件 。如果Flume由于某种原因停止或停机 ,它可以从写入现有位置文件的位置重新启动拖尾。
This source is reliable and will not miss data even when the tailing files rotate. It periodically writes the last read position of each files on the given position file in JSON format. If Flume is stopped or down for some reason, it can restart tailing from the position written on the existing position file.
文件循环是我们常用的日志框架或系统,比如log4j,它会自动丢弃日志文件中的长历史日志。 它通常是一种根据日志文件的大小或时间自动拆分或丢弃日志的机制
5.Kafka Source
**Kafka Source是一个Apache Kafka消费者,它从Kafka主题中读取消息。**您可以使用相同的消费者组配置它们,这样每个人都将为主题读取一组唯一的分区。
Kafka Source is an Apache Kafka consumer that reads messages from Kafka topics. You can configure them with the same Consumer Group so each will read a unique set of partitions for the topics.
6.HTTP Source
通过HTTP POST和GET接受Flume事件的数据源。HTTP请求通过一个可插入的"处理程序"转换为flume事件,该处理程序必须实现 HTTPSourceHandler接口。该处理程序接收一个HttpServletRequest对象,并返回一个flume事件列表。
A source which accepts Flume Events by HTTP POST and GET. HTTP requests are converted into flume events by a pluggable "handler" which must implement the HTTP SourceHandler interface. This handler takes a HttpServletRequest and returns a list of flume events.
- HTTP Source是基于Jetty 9.4实现的,它提供了配置Jetty参数的能力
(二)Channel
1.types
| Channel 类型 | 核心功能与特点 | 关键考点与注意事项 |
|---|---|---|
| Memory Channel | Event数据存储在内存中 | 1. 性能最高 ,吞吐量最大 2. 可靠性最低 (进程重启或崩溃导致数据丢失) 3. 适用于对性能要求高、允许少量数据丢失的场景 4. 配置参数:capacity(容量),transactionCapacity(事务容量) |
| File Channel | Event数据存储在磁盘文件中 | 1. 可靠性最高 (数据持久化到磁盘) 2. 性能相对较低 (涉及磁盘I/O) 3. 支持事务性操作,保证数据不丢失 4. 配置参数:checkpointDir(检查点目录),dataDirs(数据目录) |
| JDBC Channel | 通过数据库 持久化存储Event,目前仅支持Derby | 1. 使用数据库作为存储后端 2. 支持标准JDBC,理论上可扩展其他数据库 3. 性能受数据库性能影响 4. 需要配置JDBC连接参数 |
| Kafka Channel | 将Event存储到Kafka集群(需单独安装) | 1. 集成Kafka作为缓冲队列 2. 兼具高吞吐和持久化特性 3. 支持数据复用(多个消费者) 4. 需要配置Kafka集群地址和Topic |
| Spillable Memory Channel | Event存储在内存队列和磁盘,内存满时溢写到磁盘 | 1. 混合存储模式 (内存+磁盘) 2. 内存为主存储,磁盘为溢出存储 3. 平衡性能和可靠性 4. 配置参数:memoryCapacity(内存容量),overflowCapacity(溢出容量) |
| Pseudo Transaction Channel | 仅用于单元测试,不适用于生产环境 | 1. 测试专用 ,模拟Channel行为 2. 不保证数据持久化 3. 生产环境严禁使用 |
| Custom Channel | 实现Channel接口自定义Channel | 1. 扩展性 考点 2. 需实现Channel接口 3. 满足特殊存储或传输需求 |
2.Memory Channel
Memory Channel将事件队列存储在内存中 。最大队列数为capacity的设定值。它非常适用于有高吞吐量需求 的场景,但也有成本。当故障发生 时,内存中当时的所有事件都会丢失。
Memory Channel stores event queues in memory. The maximum number of queues is the set value of capacity. It is very suitable for scenarios with high throughput requirements, but it also has a cost. When a failure occurs, all events in the memory at that time will be lost.
3.Important Channel
| 特性对比 | Memory Channel | File Channel | Kafka Channel |
|---|---|---|---|
| 存储介质 | 内存 | 磁盘文件 | Kafka集群 |
| 可靠性 | 低(数据易丢失) | 高(数据持久化) | 高(分布式持久化) |
| 性能 | 高(内存操作) | 中低(磁盘I/O) | 高(高吞吐消息队列) |
| 适用场景 | 高吞吐、允许数据丢失 | 数据可靠性要求高 | 高吞吐、高可靠、数据复用 |
性能考虑
- Memory Channel:最快,但受JVM内存限制,配置不当会导致OOM
- File Channel:受磁盘I/O性能影响,SSD可提升性能
- Kafka Channel:高吞吐,适合大规模数据管道
配置要点
- Memory Channel :
capacity(默认100),transactionCapacity(默认100) - File Channel :
checkpointDir(检查点目录),dataDirs(数据目录,可配置多个) - Kafka Channel :
kafka.bootstrap.servers,kafka.topic
(三)Sink
目前,Flume支持以下sink类型:
1.types
| Sink 类型 | 核心功能与特点 | 关键考点与注意事项 |
|---|---|---|
| HDFS Sink | 将数据写入 Hadoop HDFS 存储系统 | 1. 最常用 的Sink之一 2. 支持数据写入HDFS文件系统 3. 可配置文件滚动策略(按时间、大小等) 4. 支持数据压缩和格式(SequenceFile, DataStream等) |
| Hive Sink | 将包含分隔文本或JSON数据的Event直接写入 Hive表或分区 | 1. 直接写入Hive表,无需中间转换 2. 支持实时数据导入到Hive 3. 需配置Hive相关参数(metastore, 表名等) |
| Logger Sink | 将数据写入 日志文件 ,主要用于调试和测试 | 1. 调试用途 ,输出Event内容到日志 2. 生产环境不推荐(性能影响) 3. 可配置日志级别 |
| Avro Sink | 将数据转换为 Avro Event 并发送到配置的RPC端口 | 1. 用于Agent间通信 (下一跳Agent的Source) 2. 基于Avro RPC协议 3. 支持多级Flume拓扑结构 |
| Thrift Sink | 将数据转换为 Thrift Event 并发送到配置的RPC端口 | 1. 类似Avro Sink,但使用Thrift协议 2. 用于跨语言通信场景 |
| File Roll Sink | 将数据存储到本地文件系统 | 1. 数据写入本地磁盘 2. 可配置文件滚动策略 3. 适用于数据备份或临时存储 |
| HBase2 Sink | 将数据写入 HBase数据库 | 1. 支持写入HBase表 2. 需配置HBase连接参数(Zookeeper地址等) 3. 可指定列族、列名映射 |
| ElasticSearch Sink | 将数据发送到 ElasticSearch服务器(集群) | 1. 实时数据索引到ES 2. 支持批量写入和索引创建 3. 需配置ES集群地址和索引名称 |
| Morphline Solr Sink | 将数据发送到 Solr搜索服务器(集群) | 1. 数据索引到Solr 2. 使用Morphline进行数据转换 3. 需配置Solr连接和Morphline配置 |
| HTTP Sink | 从Channel获取Event,通过 HTTP POST 发送到远程接口 | 1. 将数据发送到HTTP服务端 2. 支持自定义HTTP头部 3. 可用于与Web服务集成 |
| IRC Sink | 在 IRC(互联网中继聊天) 上回放数据 | 1. 实验性或特殊用途 2. 将数据发送到IRC频道 3. 实际应用较少 |
| Null Sink | 丢弃所有数据 ,用于测试和性能基准 | 1. 性能测试 中测量最大吞吐量 2. 生产环境不适用 3. 可验证Channel性能 |
| Custom Sink | 自定义Sink,实现 Sink接口 自行开发 | 1. 扩展性 考点 2. 需实现特定接口(Sink接口) 3. 满足特殊存储或传输需求 |
2.HDFS Sink
该Sink将事件写入Hadoop分布式文件系统(即HDFS) 。目前支持创建文本和sequencefile。它支持两种文件类型的压缩。
This Sink writes events to the Hadoop distributed file system (that is, HDFS). Currently supports the creation of text and sequencefiles. It supports compression of two file types.
3.File Roll Sink
事件存储到本地文件系统。
File Roll Sink stores events to the local file system.
4.Null Sink
丢弃从channel中读取的所有事件。
Null Sink:- Discard all events read from the channel.
5.HBase2 Sink
该Sink将数据写入HBase。Hbase的配置文件可以从类路径中的第一个Hbase -site.xml文件中获取。配置指定HbaseEventSerializer接口的实现类,将Event转换为HBase的put或increments。然后将这些put和increment写入HBase。
This Sink writes data to HBase. The Hbase configuration is obtained from the first hbase-site.xml encountered in the class path. Configure the implementation class of the specified HbaseEventSerializer interface to convert Event to HBase put or increments. Then write these puts and increments to HBase.
6.Kafka Sink
这意味着Flume将数据发送到Kafka。Kafka是数据管道的目的地 。Flume将消息写入Kafka主题。在这种情况下,Flume不会从Kafka中读取数据
It means Flume sends data to Kafka. Kafka is the destination for the data pipeline. Flume writes messages into a Kafka topic. Flume does not consume from Kafka in this case
四、Flume complex data flow model design
Flume复杂数据流模型包括简单的串联、复合和多路复用、负载平衡和故障转移、聚合等模型。
(一)Simple series connection 简单串联
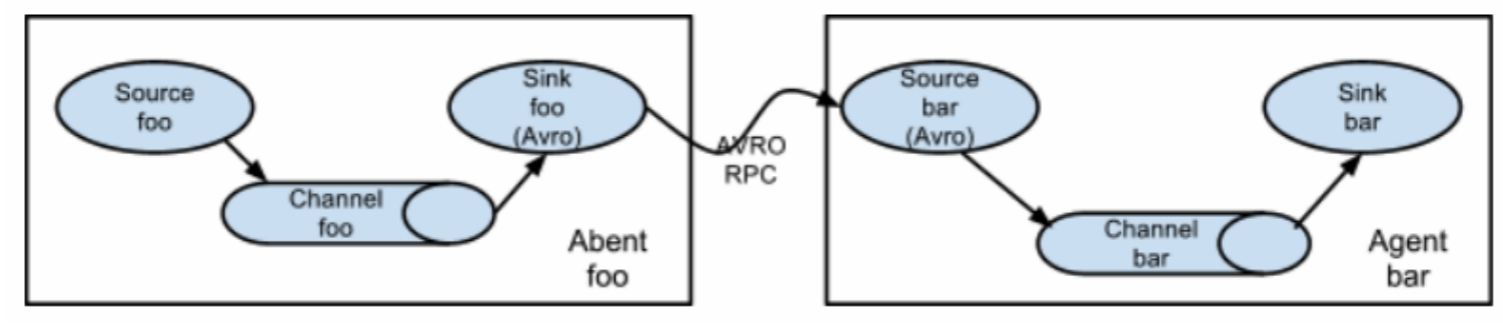
该模型按顺序连接多个flume ,从初始源到最终汇传输的目的存储系统。 这个模型不建议桥接太多的flume。 过多的flume不仅会影响传输速率 ,如果在传输过程中某个节点flume发生故障,还会影响整个传输系统。
(二)Replication and multiplexing 复制和复用
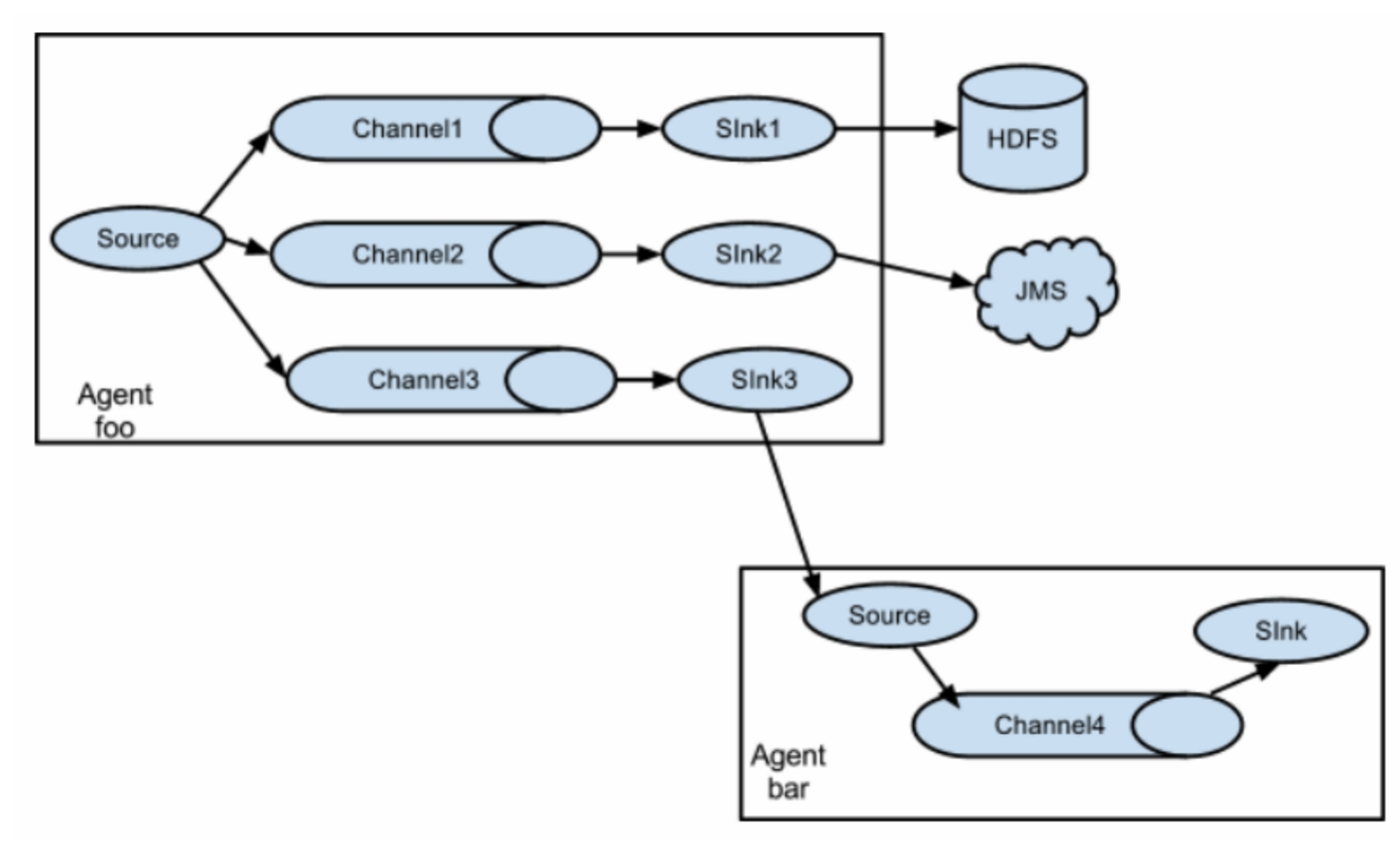
Flume支持到一个或多个目的地的事件流。 该模型可以将相同的数据复制到多个通道 ,也可以将不同的数据分发到不同的通道 ,sink可以选择发送到不同的目的地。
Flume supports the flow of events to one or more destinations. This model can copy the same data to multiple channels, or distribute different data to different channels, and sink can choose to transmit to different destinations.
(三)Load balancing and failover 负载平衡和故障转移
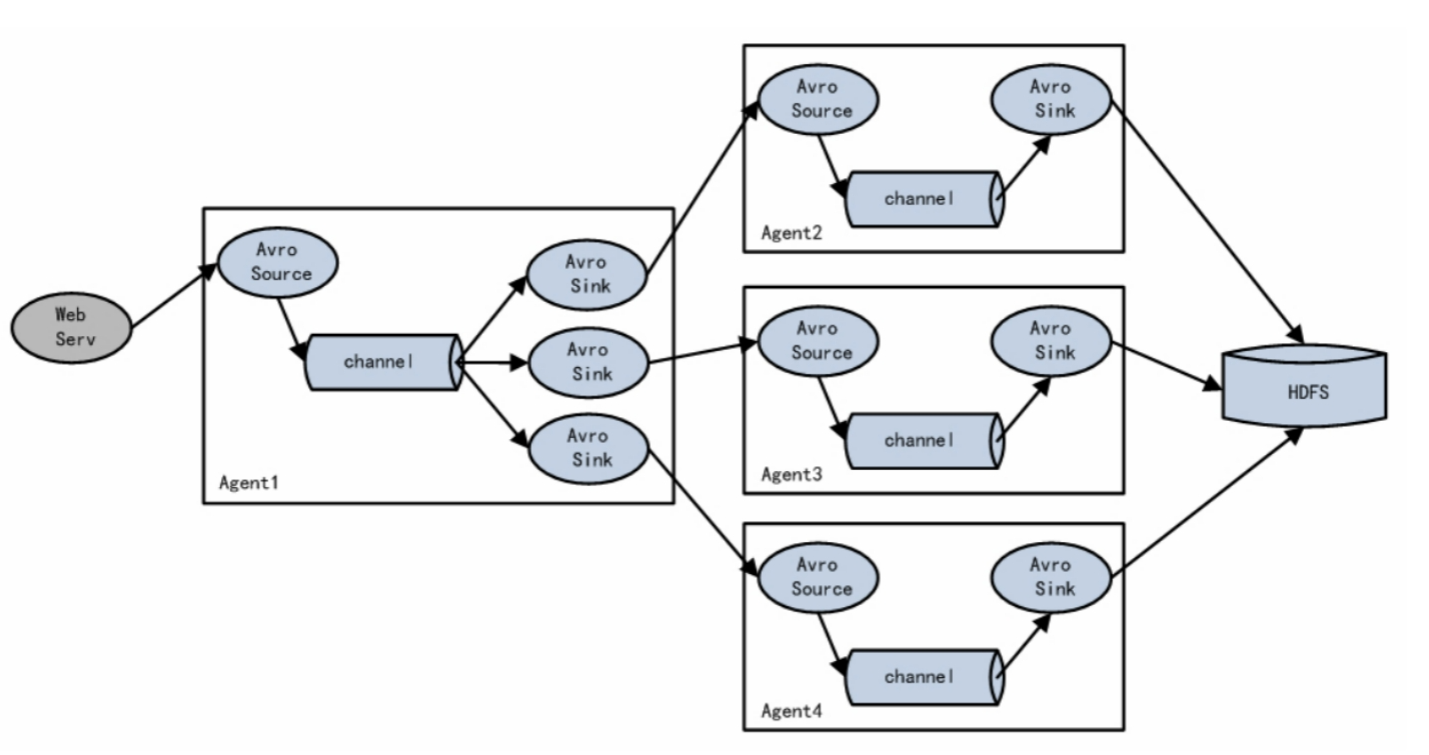
Flume支持使用在逻辑上将多个汇流器划分为汇流器组。 接收器组可以使用不同的接收器处理器来实现负载平衡和错误恢复。
Flume supports using to logically divide multiple sinks into a sink group. The sink group can work with different Sink Processors to achieve load balancing and error recovery.
(四)Polymerization 聚合
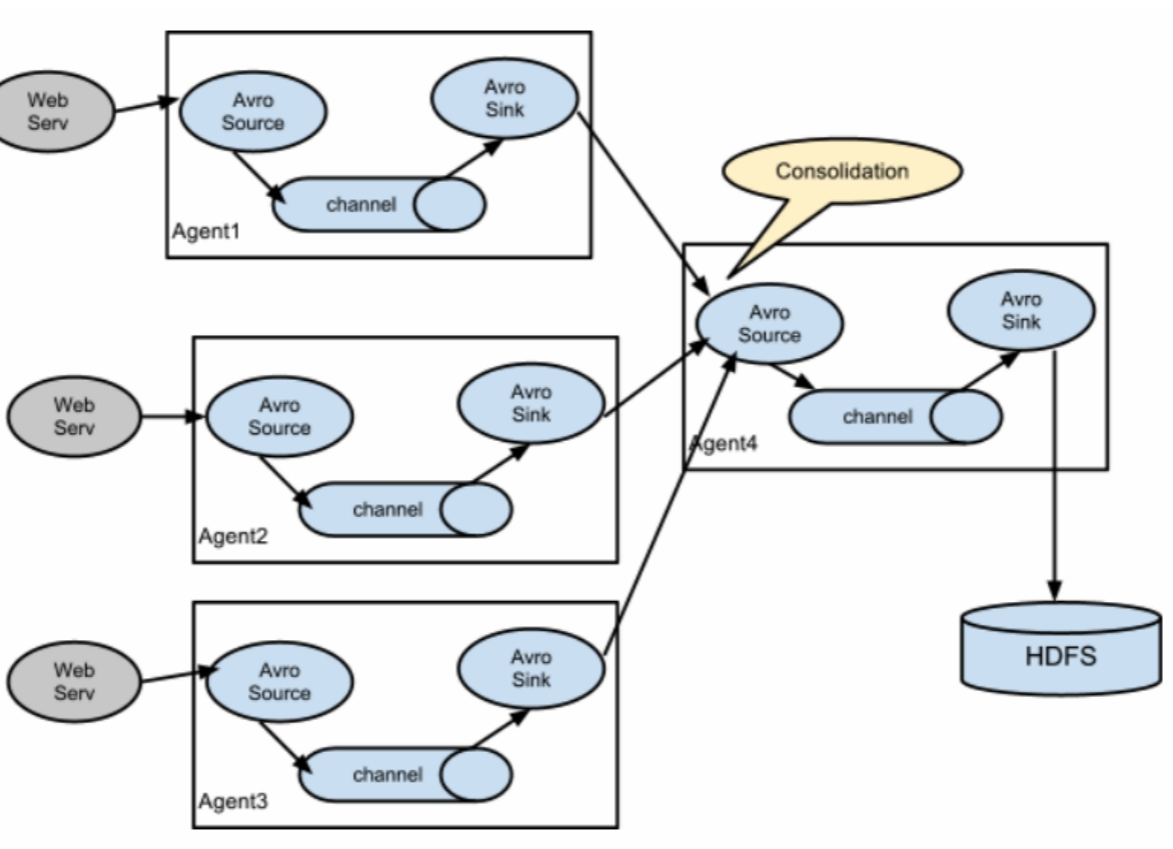
这种模式是我们最常见的,也是非常实用的。 日常的web应用程序通常分布在数百台服务器上,甚至数千台或数万台服务器上。 生成的日志处理起来也很麻烦。 该组合排气系统可以很好地解决这一问题。 每台服务器部署一个flume收集日志,传输到一个flume集中收集日志,然后将flume上传到hdfs、hive、hbase等平台进行日志分析。
This model is our most common and very practical. Daily web applications are usually distributed in hundreds ofservers, even
thousands or tens ofthousands ofservers. The generated logs are also very troublesome to process. This combination off lume can solve this problem well. Each server deploys a flume collection log, transmits it to a flume that collects logs centrally, and then uploads the flume to hdfs, hive, hbase, etc. for log analysis.
总结
本章中对flume的概念以及定义、基本结构有了详细的讲述,以及其核心部件的类型与使用方法。