AlexNet
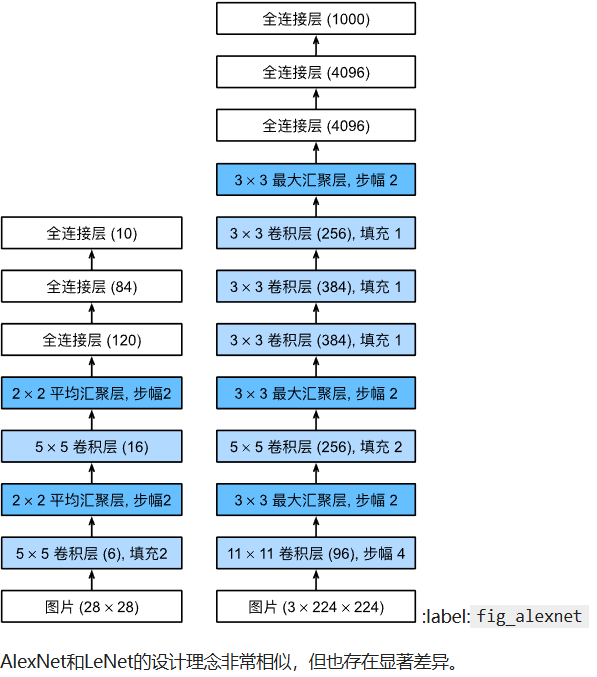
书中使用pytorch框架直接实现了这个网络
vgg
vgg网络中使用了vgg块,vgg快中可以自定义卷积层数和输出通道,书中使用循环实现vgg块,可以很方便的定义这些参数。
nin
nin相较于上面的网络,nin取消了全连接层,因为他们认为,直接将特征图拉直会损失掉二维的空间信息。
取而代之,nin的处理方式是在最后输出10个通道,每一个通道当成一种分类,直接将每个通道汇聚到 1 ∗ 1 1 * 1 1∗1大小。
nin网络的另一个特点是使用1 * 1大小的卷积核,该卷积核不改变特征图大小,仅用来改变通道数量。
nin块
与vgg块不同的是,一个nin块中只包含一个非1*1卷积核,因为其更关心通道数目,因此要定义输入输出通道。此外,还要定义卷积的步长和填充。nin块就好像一个增强了通道管控的单层卷积核。
GoogLeNet
这个网络的主要贡献是使用了并行的处理和使用了不同大小的卷积核。
Inception块
其中的块称为Inception块。
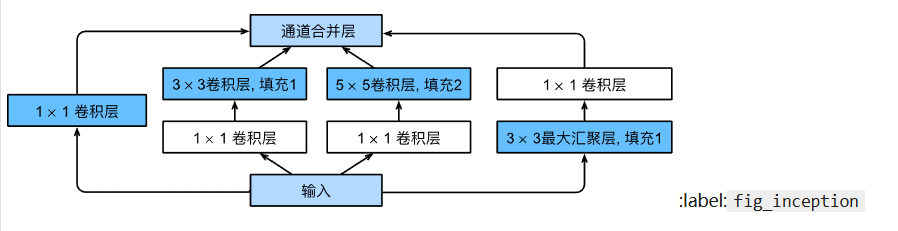
在代码中实现这个块的方法是并行得到结果后在通道维度上将所有结果叠加。因此,多次堆叠这个块后通道数会变得很高。
批量规范化
主要解决三个问题:
- 解决量纲的问题
- 解决层与层之间分布偏移的问题
- 解决过拟合的问题
公式

批归一化的实现
具体模型中为了实现这个公式是用批量归一化层
全连接网络中位置:
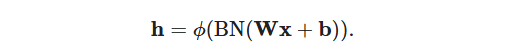
卷积网络中位置:卷积层之后和非线性激活函数之前
并且批归一化是不对通道进行的,也就是说不同通道上批归一化后参数不一样。
BN层在训练和预测模式下行为不同
- 在训练模式下,每批次都要训练均值和方差,并且运用移动平均估算整个训练数据集的均值和方差。
- 在预测模式下则直接调用训练中计算好的均值和方差。
代码实现中用两个部分完成 :
用一个函数专门实现其中的算法逻辑部分
而外面再套一个类实现参数初始化和显存复制。
resnet
最重要的功能是实现了残差学习。
比如当前网络已经达到了最优,如果在这个的基础上继续叠层训练那将原来的输出x再训练为x会十分困难。因此,我们要训练残差,即训练那个x-x = 0。
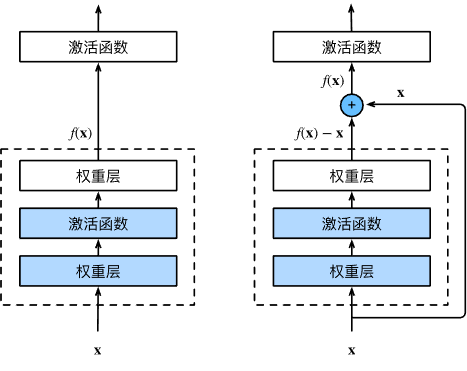 在代码中残差连接使用1*1卷积核实现(因为通道数可能变),因为主通道上是两层卷积和bn
在代码中残差连接使用1*1卷积核实现(因为通道数可能变),因为主通道上是两层卷积和bn
稠密网络
稠密网络在resnet上更进一步,不是将两个输出简单相加,而是在通道维度上相加。

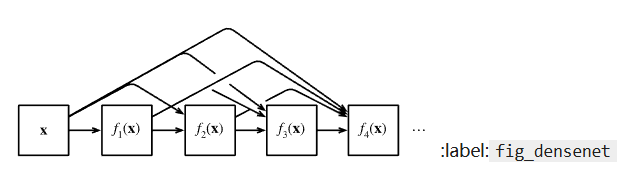
这样也会导致通道维度增加,因此稠密网络中有专门减少通道的过度层,当然还是用一维卷积核。