CPython 介绍:
CPython 是 Python 语言的默认实现,也是使用最广泛的实现。我们平时所说的 "Python",其实大多数时候指的就是 CPython。当你从http://python.org下载 Python 时,你实际上下载的是 CPython 代码。CPython 是用 C 语言编写的程序,它完整地实现了 Python 语言规范中所定义的所有规则和语法。
在 Python(准确地说是 CPython)程序运行的过程中,当需要申请内存时,CPython 底层会调用 malloc 来分配内存;而当这块内存不再使用时,CPython 会调用 free 将其释放。以避免内存浪费或内存泄漏。
Python 中的变量
在 Python 中,变量其实只是对内存中实际对象的引用。你可以把它理解为一个标签或名字,它本身并不保存值,而是指向一个具体的对象。
来看一个例子:
a = 100正如前面所说,当这行代码执行时,CPython 会在内部创建一个整数类型的对象。变量a指向该整数对象。注意:变量 a 并不保存 100,而是指向这个整数对象。可以想象成变量 a 给这个整数对象贴了个标签,方便我们之后通过 a 来访问它。
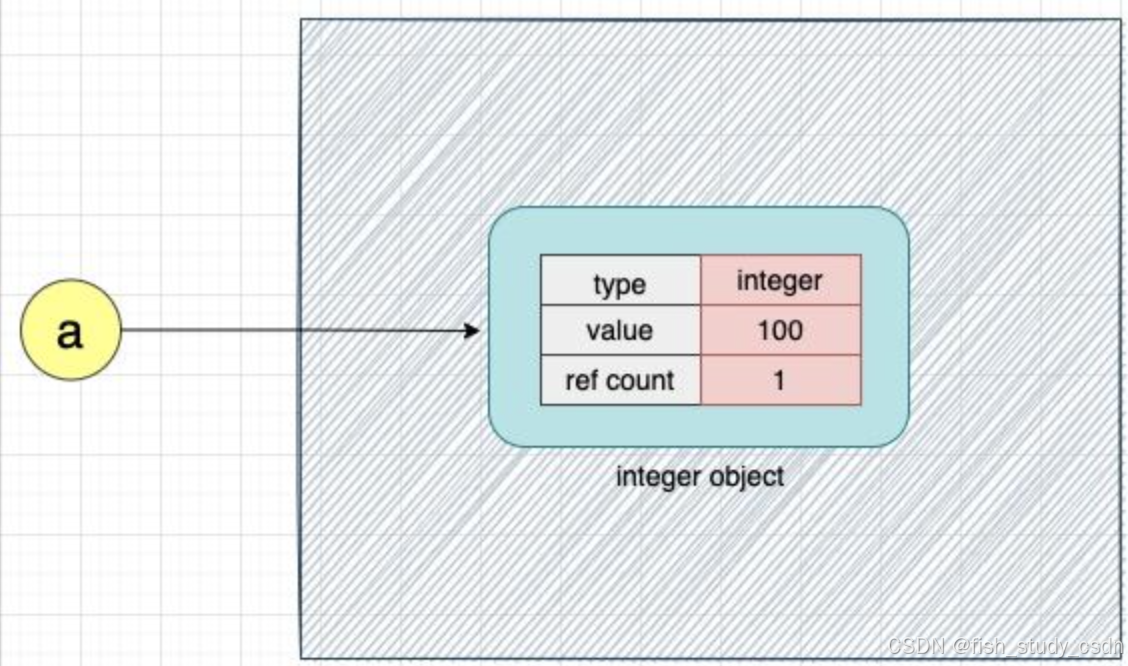
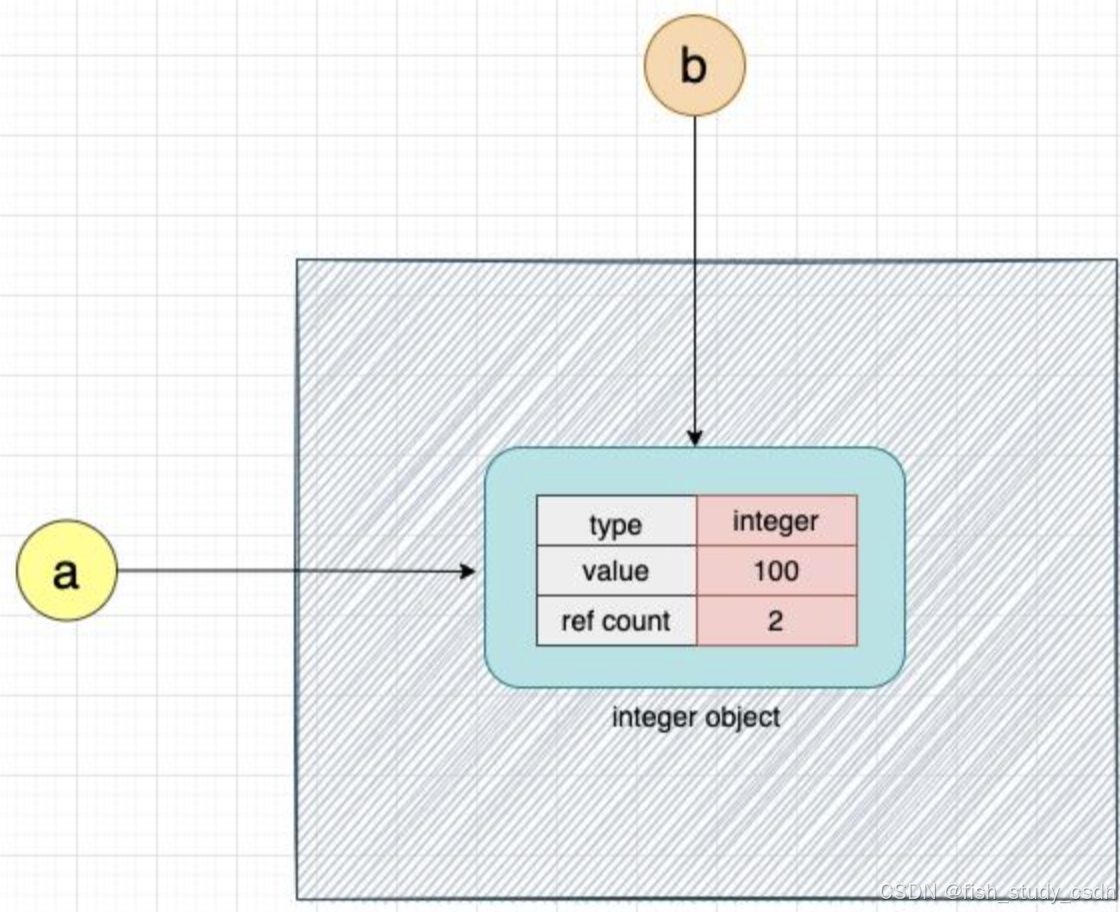
现在我们再把这个整数对象赋值给另一个变量 b:
b = a当这行代码执行后,变量 a 和 b 实际上都指向了同一个整数对象。如下图所示:
现在我们来给这个整数对象的值加 1:
# 给 a 加 1
a = a + 1当这行代码执行后,CPython 会创建一个新的整数对象,值为 101,然后让变量 a 指向这个新对象。而变量 b 仍然指向原来那个值为 100 的整数对象。也就是说CPython 并不会直接把原来的值 100 改成 101,这是因为在 Python 中,整数是不可变(immutable)的。一旦被创建,它的值就不能被修改。
现在 a 和 b 指向的是两个不同的整数对象。
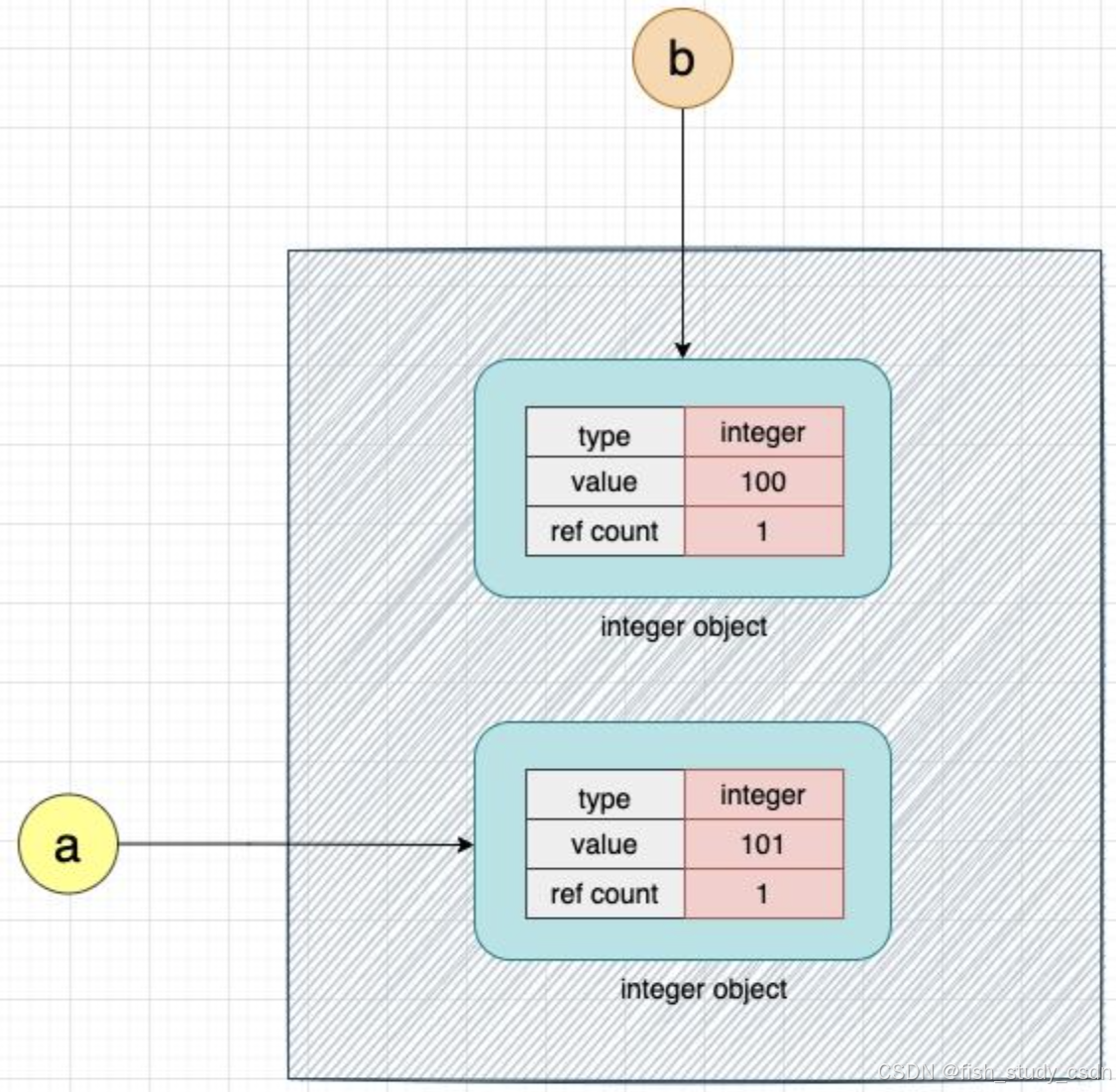
需要注意的是,不仅整数是不可变的,浮点数(float)和字符串(string)在 Python 中也是不可变类型。
我们可以通过下面zhe个简单的 Python 程序进一步说明这个概念:
i = 0
while i < 100:
i = i + 1上面的代码定义了一个简单的 while 循环,用来不断地给变量 i 加 1,直到 i 达到 100 为止。
当这段代码执行时,每当变量 i 增加一次,CPython 就会创建一个新的整数对象,并让变量 i 指向这个新对象,同时原来的整数对象将被标记为"可以被删除"(更准确地说,是变成了"可回收"的状态),等待从内存中释放。
在这个过程中,CPython 每创建一个新的整数对象,就会调用一次 malloc 方法向操作系统申请内存;而当某个旧对象不再被引用时,CPython 会调用 free 方法释放掉这部分内存。
我们可以把上面的代码转换成等效的 malloc 和 free 操作来理解内存管理的过程:
i = 0 # malloc(i)
while i < 100:
# malloc(i + 1)
# free(i)
i = i + 1可以看出,即使是这样一个简单的程序,CPython 在执行过程中也会频繁地创建和销毁大量的对象。如果每次对象的创建和销毁都直接调用 malloc 和 free 方法去申请和释放内存,那么程序的性能将会大打折扣,执行效率也会变得很慢。
为了解决这个问题,CPython 引入了一些优化策略,来减少频繁调用 malloc 和 free 的次数。
接下来,我们就来深入了解一下 CPython 是如何进行内存管理的!
CPython 的内存管理机制
在 Python 中,内存管理主要依赖于一个"私有堆"(Private Heap)的机制。所谓私有堆,就是一块专门为 Python 进程所保留的内存区域,只有当前这个 Python 程序可以使用,其他进程无法访问或占用这块内存。
Python 进程中的所有对象和数据结构(无论是整数、字符串、还是列表、字典等)都存储在这块私有堆中。
这块私有堆的大小并不是固定的,而是会根据 Python 程序的运行情况自动扩展或缩减,也就是说,当程序需要更多内存时,堆会变大;当不再需要那么多内存时,堆也会适当缩小,从而提升内存使用效率。
这块私有堆的管理由 CPython 内部实现的内存管理器负责,它通过一系列复杂的算法和策略来分配、回收和优化内存的使用。
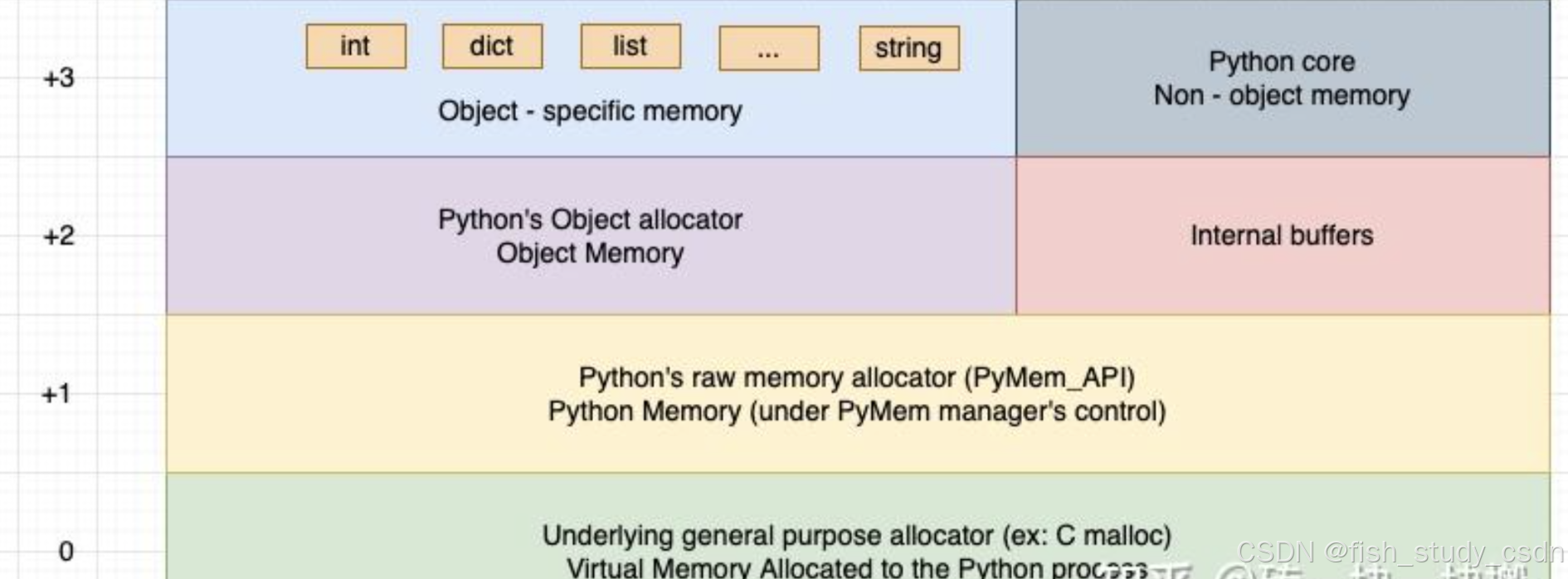
为了更直观地理解 CPython 中的内存管理方式,我们可以将这块私有堆抽象地划分为多个区域,如下图所示
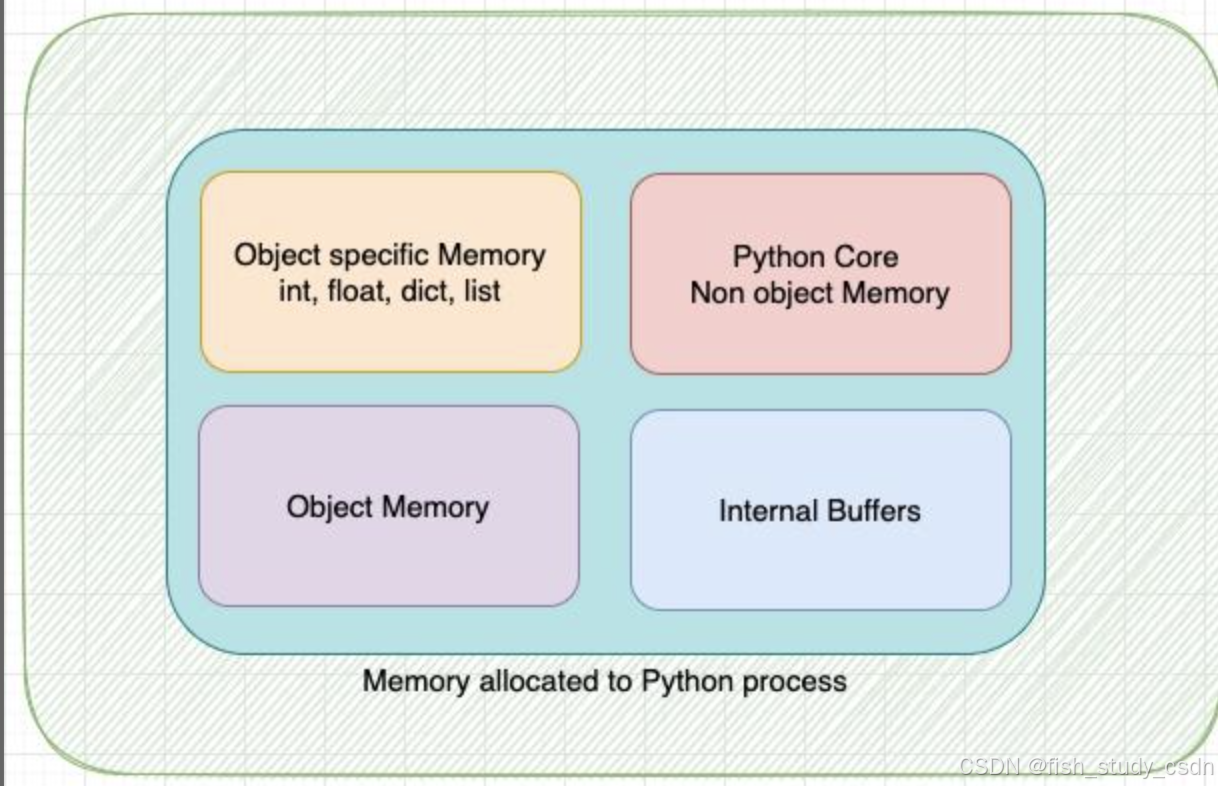
需要注意的是,上面提到的各个内存区域的边界并不是固定的,它们会根据实际需要动态增长或缩减。
下面是 CPython 私有堆中几个重要的内存区域划分说明:
- Python 核心非对象内存(Python Core Non-object memory):用于存储 Python 核心代码中非对象相关的数据,比如解释器运行时所需的一些内部状态信息等。
- 内部缓冲区(Internal Buffers):用于 CPython 内部使用的缓冲数据区,比如临时缓存、IO 缓冲等。
- 特定对象内存(Object-specific memory):为某些特定对象类型分配的专用内存,这些对象可能有自己的专属内存分配器。
- 通用对象内存(Object Memory):为大多数普通 Python 对象分配的内存区域。
当 Python 程序运行过程中需要分配内存时,CPython 会通过调用底层的 malloc 函数向操作系统申请内存,这时私有堆会随之扩展
但是,如果每创建或销毁一个小对象都频繁地调用 malloc 和 free,将会严重影响程序的执行效率。因此,CPython 为了提升性能,引入了多个专门的内存分配器和释放器(allocators 和 deallocators)来管理不同类型的内存使用场景。
内存分配器概述
为了避免频繁地调用 malloc 和 free,CPython 设计了一套分层的内存分配器体系,具体如下:
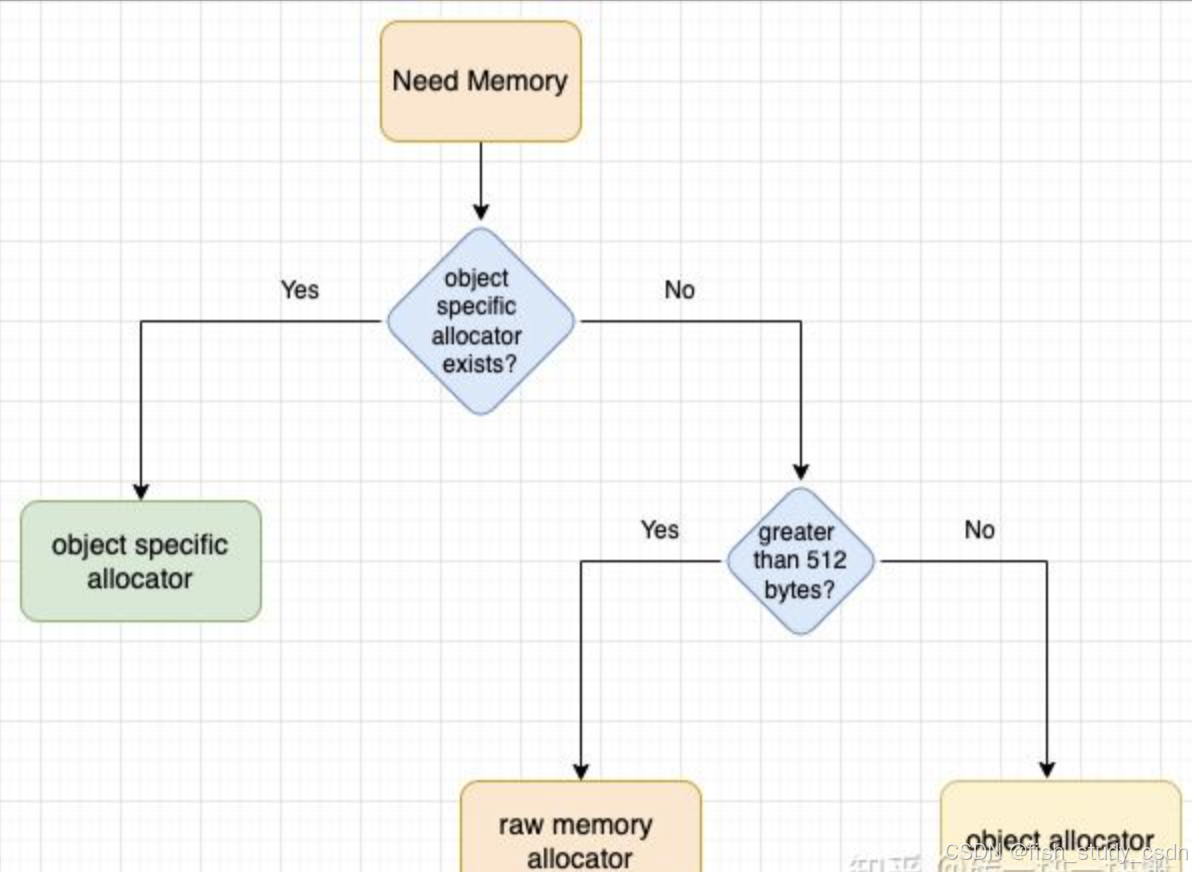
从底层往上,内存分配器的层级结构如下:
- 通用内存分配器(General Purpose Allocator):这是对操作系统底层 malloc 函数的封装,属于 CPython 的基础分配器。
- 原始内存分配器(Raw Memory Allocator):主要用于分配大于 512 字节的对象,直接使用底层的 malloc 和 free 进行管理。
- 对象内存分配器(Object Allocator):专门用于管理小对象(大小小于等于 512 字节),该分配器会通过预先申请大块内存并进行内部管理,来避免频繁访问操作系统。
- 特定对象类型分配器(Object-specific Allocators):针对某些特定数据类型(如整数、浮点数、字符串等)进行专门优化的内存分配器,提高性能和内存复用率。
在内存分配体系的最底层,是通用内存分配器。对于 CPython 来说,它实际上就是 C 语言中的 malloc 方法。它负责与操作系统的虚拟内存管理器打交道,为 Python 进程分配所需的内存。这个分配器是整个体系中唯一一个会直接与操作系统进行内存交互的部分。
在通用内存分配器之上,是 Python 的原始内存分配器(Raw Memory Allocator)。它对底层的 malloc 方法进行了抽象封装。当 Python 进程需要内存时,原始内存分配器会与通用分配器协同工作,获取所需内存,并确保当前有足够的空间来存储 Python 进程所需的数据。
在原始内存分配器之上,我们有对象内存分配器(Object Allocator)。这个分配器负责为小型对象(大小小于或等于 512 字节的对象)分配内存。如果一个对象需要的内存超过 512 字节,Python 的内存管理器会直接调用原始内存分配器。
如上所示,在对象内存分配器之上,还有对象特定的内存分配器(Object-specific Allocators)。例如,整数、浮点数、字符串和列表等简单数据类型,各自都有各自的对象特定分配器。这些对象特定分配器会根据对象的需求,实施相应的内存管理策略。例如,整数的对象特定分配器和浮点数的对象特定分配器在实现上是不同的。
对象专属分配器和通用对象分配器都只在 Python 进程已经分配好的内存上进行操作,这部分内存是通过原始内存分配器(raw memory allocator)申请到的。这些分配器本身不会直接向操作系统请求内存,而是只在 Python 的私有堆(private heap)中进行分配操作。
当对象分配器或对象专属分配器需要更多内存时,会通过原始内存分配器申请额外内存,而原始内存分配器再通过通用内存分配器(即 C 语言中的 malloc)与操作系统打交道,从而获取更多内存。
Python 中的内存分配器层次结构
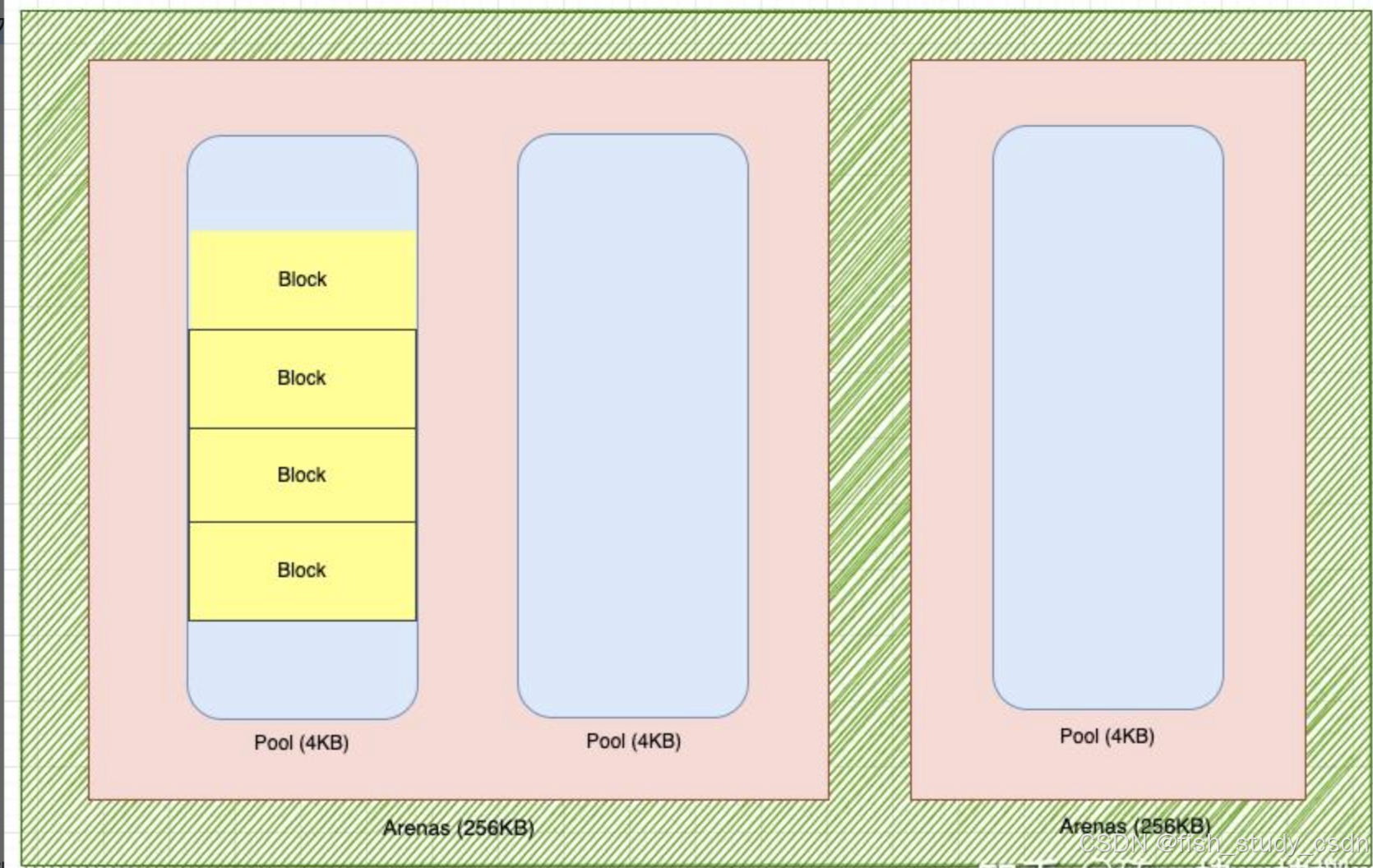
当一个对象申请内存时,如果该对象有对应的专属内存分配器,那么就会优先使用这个对象专属的内存分配器来进行内存分配。
如果该对象没有专属分配器,且申请的内存大于 512 字节,那么 Python 的内存管理器会直接调用原始内存分配器(raw memory allocator) 来分配内存。
而如果申请的内存小于等于 512 字节,则会使用 Python 的通用对象分配器(object allocator) 来进行内存分配。
对象分配器(Object Allocator)
对象分配器,也叫 pymalloc,它专门用于为小于 512 字节的小对象分配内存。
当一个小对象申请内存时,Python 的对象分配器并不会单独为这个对象分配内存,而是一次性向操作系统申请一大块内存,然后把这块内存划分出来,后续再用于其他小对象的内存分配。
这种方式可以避免每次小对象申请内存都调用一次 malloc,从而大大提高性能。
对象分配器分配的这个大内存块被称为 Arena。每个 Arena 的大小为 256 KB。
为了更高效地管理 Arena,CPython 会将 Arena 进一步划分成多个 Pool(内存池),每个 Pool 的大小是 4 KB。所以,一个 Arena 会被划分为 64 个 Pool(256KB / 4KB = 64)。
Pool 会被进一步划分为更小的单元,称为 Block(块)。
接下来我们详细看看这些内存组件的结构和原理。
内存块(Blocks)
Block 是对象分配器可以分配给对象的最小内存单位。一个 Block 只能分配给一个对象,而一个对象也只能被分配到一个 Block 中。也就是说,不可能将一个对象的部分内容放在多个 Block 中。
Block 的大小是多种多样的,最小为 8 字节,最大为 512 字节,并且它们的大小都是 8 的倍数,因此,Block 的大小可以是 8、16、24、32、......、504 或 512 字节。每一种 Block 大小就称为一个 "Size Class"(大小类别),一共定义了 64 个 size class。如下所示:
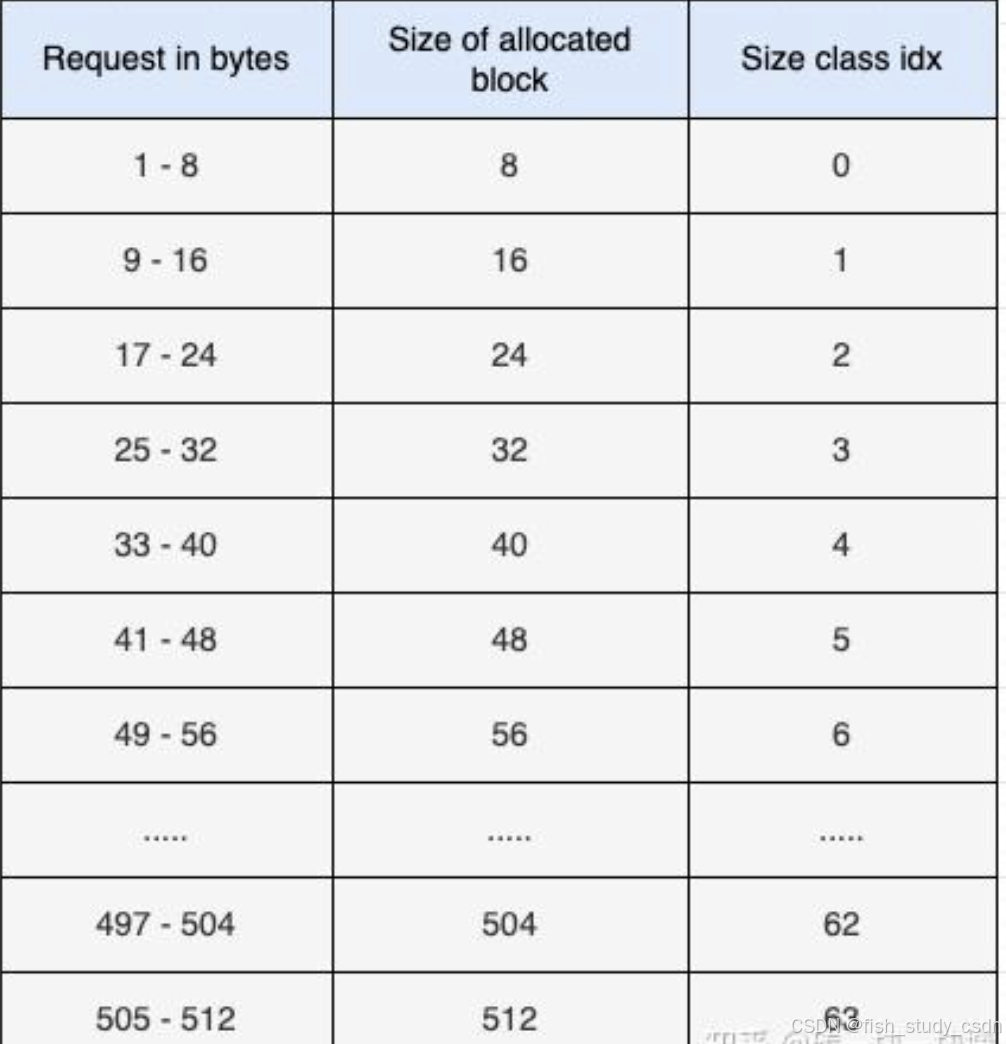
从上表可以看到,大小类别 0 的 Block 大小为 8 字节,大小类别 1 的 Block 大小为 16 字节,以此类推。
程序要么总是分配一个完整的 Block,或者根本不分配 Block。所以,如果程序请求 14 字节的内存,它会被分配一个 16 字节的 Block。同样,如果程序请求 35 字节的内存,它会被分配一个 40 字节的 Block。
内存池(Pools)
Pool 是对象分配器中的中间层结构,它由多个大小相同的 Block(块)组成。
一个 Pool 中只能包含一种 Size Class 的 Block。举个例子,如果某个 Pool 是 size class 0(也就是 8 字节块),那它里面所有的 Block 都必须是 8 字节的,不可能混有其他大小的块。
Pool 的大小等于操作系统的"虚拟内存页"大小。在大多数系统中,这个大小是 4KB(4096 字节)。
当对象分配器找不到已有 Pool 中满足某个 Size Class 的空闲 Block 时,它就会从 Arena 中"切割"出新的 Pool 来使用。
一个 Pool 的状态取决于它里面的 Block 是否被占用,分为以下三种:
- Used(使用中):Pool 中还有可用的 Block,可以继续分配内存。
- Full(已满):Pool 中所有的 Block 都被分配出去了,没有空闲了。
- Empty(空闲):Pool 中所有 Block 都是空闲的。此时该 Pool 没有关联的 Size Class,它可以被用于任何大小类别的 Block 分配。
Pool 在 CPython 代码中的定义如下所示:
cpp
struct pool_header {
union { block *_padding;
uint count; } ref; /* 已分配块的数量 */
block *freeblock; /* 池的空闲列表头部 */
struct pool_header *nextpool; /* 相同大小类的下一个池 */
struct pool_header *prevpool; /* 上一个池 "" */
uint arenaindex; /* 基地址在arenas中的索引 */
uint szidx; /* 块大小类的索引 */
uint nextoffset; /* 到原始块的字节数 */
uint maxnextoffset; /* 最大有效的nextoffset */
};在这个结构体中:
- szidx:表示当前 Pool 所属的 大小类别(Size Class)。举例来说,如果某个 Pool 的 szidx 为 0,那这个 Pool 中的所有内存块(Block)就是 size class 0 的,也就是 8 字节大小的块。
- arenaindex:表示当前 Pool 属于哪个 Arena。
所有属于 同一个大小类别(即 szidx 相同)的 Pool 会通过 双向链表(Doubly Linked List)连接起来:
- nextpool:指向下一个同类的 Pool
- prevpool:指向上一个同类的 Pool