上一篇拆解了Redis的线程模型------"命令执行始终单线程",但很多读者疑惑:"单线程只能占用1个CPU核心,凭什么能支撑10万+QPS的高并发?甚至比多线程方案还快?" 答案的核心的是:Redis精准抓住了"I/O密集型"场景的本质,用「I/O多路复用」突破并发限制,再通过3大优化点把单线程性能拉满。
本文将从底层原理、技术细节、实战验证三个维度,彻底讲透这个问题,最后附上面试常考的"I/O多路复用vs多线程"深度对比。
一、核心前提:先搞懂"I/O密集型"vs"CPU密集型"
要理解Redis的高并发逻辑,首先要区分两种场景的差异------这是单线程能"战胜"多线程的关键前提:
| 场景类型 | 核心特征 | 性能瓶颈 | 最优方案 |
|---|---|---|---|
| I/O密集型(Redis) | 大部分时间在"等待I/O就绪"(如网络传输、磁盘读写) | 网络I/O、磁盘I/O | I/O多路复用(单线程/少量线程) |
| CPU密集型(如视频编码) | 大部分时间在"CPU计算"(如复杂运算、数据处理) | CPU核心数、计算效率 | 多线程/多核并行计算 |
Redis作为缓存数据库,核心操作是"接收命令→内存读写→返回结果":
- 内存读写是微秒级操作(1微秒=0.001毫秒),耗时极短;
- 真正的耗时在于"网络I/O"(客户端与服务器的命令传输)------这是典型的"I/O密集型"场景。
如果用多线程处理:每个线程都要等待I/O就绪(大部分时间闲置),还会产生上下文切换、锁竞争的额外开销,反而不如单线程高效。
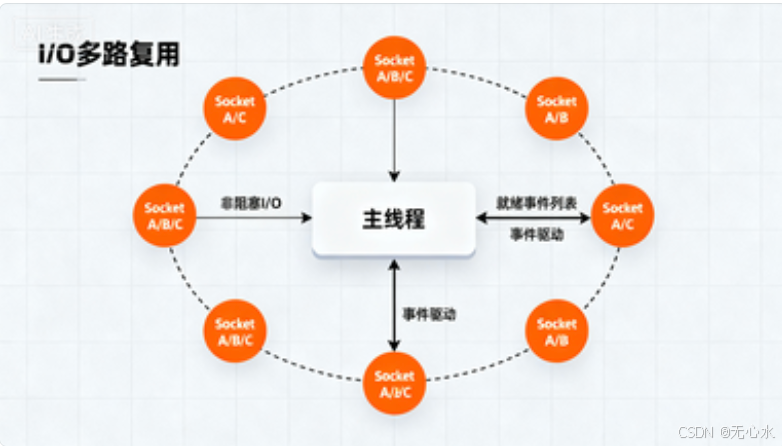
二、核心支撑1:I/O多路复用------单线程处理万级连接的"底层引擎"
I/O多路复用是Redis单线程高并发的"基石",没有它,单线程连同时处理100个客户端都困难。下面从"原理→实现→优势"三层拆解。
1. 通俗理解:像"医院分诊台"一样高效
传统单线程(无多路复用):服务员(线程)必须盯着一个客人(客户端)点完菜、吃完,才能接待下一个------哪怕客人在"玩手机"(I/O等待),服务员也得等,效率极低;
I/O多路复用:分诊台护士(I/O多路复用器)同时监听所有病人(客户端)的"就诊信号"(Socket事件),哪个病人准备好就诊(事件就绪),就通知医生(单线程)过去处理------医生全程不用"瞎等",效率翻10倍。
2. 底层实现:select/poll/epoll的演进与Redis选择
I/O多路复用技术的核心是"批量监听多个I/O资源,仅当资源就绪时才处理",主流实现有select、poll、epoll三种,Redis会根据操作系统自动选择最优方案(Linux优先用epoll)。
三者的核心差异(面试必问):
| 特性 | select | poll | epoll(Redis首选) |
|---|---|---|---|
| 时间复杂度 | O(n)(遍历所有Socket) | O(n)(遍历所有Socket) | O(1)(事件驱动,无需遍历) |
| 最大连接数 | 受限于FD_SETSIZE(默认1024) | 无上限(理论上) | 无上限(支持百万级连接) |
| 触发方式 | 水平触发(LT) | 水平触发(LT) | 水平触发(LT)+边缘触发(ET) |
| 内存拷贝 | 每次select都需拷贝全部Socket |
每次poll都需拷贝全部Socket |
仅初始化时拷贝,后续复用 |
3. epoll工作流程(伪代码模拟,一看就懂)
Redis在Linux环境下用epoll实现I/O多路复用,核心是三个系统调用,流程如下:
c
// 1. 创建epoll实例(管理Socket的"容器")
int epfd = epoll_create(1);
// 2. 向epoll实例中添加需要监听的Socket和事件类型(如AE_READABLE)
struct epoll_event event;
event.data.fd = client_socket; // 客户端Socket
event.events = EPOLLIN; // 监听"可读事件"(对应Redis的AE_READABLE)
epoll_ctl(epfd, EPOLL_CTL_ADD, client_socket, &event);
// 3. 阻塞等待就绪事件(Redis的事件循环核心)
struct epoll_event ready_events[1024];
while (1) {
// 等待有事件就绪,返回就绪事件数
int ready_num = epoll_wait(epfd, ready_events, 1024, -1);
// 遍历就绪事件,交给Redis单线程处理
for (int i = 0; i < ready_num; i++) {
if (ready_events[i].events & EPOLLIN) {
// 处理"可读事件"(如读取客户端命令)
handle_read(ready_events[i].data.fd);
}
if (ready_events[i].events & EPOLLOUT) {
// 处理"可写事件"(如返回命令结果)
handle_write(ready_events[i].data.fd);
}
}
}关键优势:epoll_wait仅返回"就绪的事件",无需遍历所有Socket------哪怕监听100万个连接,只要有100个就绪,就只处理100个,效率极高。
4. Redis对I/O多路复用的适配逻辑
Redis没有绑定某一种实现,而是通过抽象层(ae.c文件)适配不同操作系统:
- 初始化时,自动检测操作系统支持的I/O多路复用机制;
- 优先选择
epoll(Linux)、kqueue(BSD)、evport(Solaris)等高效实现; - 若都不支持,降级使用
select(兼容性最强,但性能最差)。
三、核心支撑2:3大优化点------把单线程性能拉满
I/O多路复用解决了"单线程处理多连接"的问题,而以下3个优化点,让Redis的单线程"处理速度"达到极致。
1. 纯内存操作:命令执行的"零延迟基石"
Redis的所有数据都存储在内存中,内存读写速度是磁盘的10万倍以上:
- 内存随机读写速度:约100ns/次(0.1微秒);
- 磁盘随机读写速度:约10ms/次(10000微秒)。
这意味着:Redis执行一个GET/SET命令,核心的"内存操作"耗时几乎可以忽略------单线程每秒能执行数百万次命令,完全能跟上I/O多路复用带来的并发请求。
2. 高效数据结构:从"底层"减少执行耗时
Redis的每个核心数据结构(String、List、Hash、Sorted Set)都经过精心设计,兼顾"内存占用"和"操作效率",避免不必要的性能损耗:
| 数据结构 | 底层实现(核心场景) | 关键优化点 | 操作时间复杂度 |
|---|---|---|---|
| String | 动态字符串(SDS) | 预分配内存、惰性释放,减少扩容/缩容开销 | O(1)(读写) |
| List | 压缩列表(小数据)+双向链表 | 连续内存块存储,避免指针跳转(小数据场景) | O(1)(头尾操作) |
| Hash | 压缩列表(小数据)+哈希表 | 渐进式rehash,避免扩容时阻塞单线程 | O(1)(平均) |
| Sorted Set | 跳跃表+字典 | 跳跃表支持O(logN)范围查询,字典支持O(1)查找 | O(logN)(插入/查询) |
举个例子:Sorted Set的"范围查询"(如ZRANGE key 0 10),若用普通链表实现需O(n)时间,而跳跃表通过"多层索引",能将时间复杂度降到O(logN)------单线程处理百万级数据也能快速响应。
3. 无多线程开销:单线程的"隐形优势"
多线程方案看似能并行处理,但隐藏着两大性能损耗,Redis单线程完美避开:
- 上下文切换开销:CPU在不同线程间切换时,需要保存/恢复寄存器、栈指针等信息,每次切换耗时约1~10微秒。若线程数超过CPU核心数,切换开销会占CPU的30%以上------相当于"CPU一半时间在做无用功"。
- 锁竞争开销:多线程操作共享数据(如Redis的内存字典)时,必须加锁(如互斥锁)防止数据不一致。锁等待、死锁排查、锁粒度控制,都会增加代码复杂度和性能损耗。
Redis单线程串行执行命令,无需切换线程、无需加锁------CPU资源100%投入到"处理命令"上,没有任何额外损耗。
四、深度对比:I/O多路复用vs多线程(面试必背)
很多面试官会追问:"Redis为什么不用多线程?I/O多路复用和多线程各有什么优劣?" 用下表总结核心差异,再补充延伸分析:
| 对比维度 | I/O多路复用(Redis方案) | 多线程方案 |
|---|---|---|
| 资源消耗 | 轻量(单线程,仅需少量内存) | 沉重(每个线程占几MB栈空间,连接数受限) |
| 性能开销 | 无上下文切换、无锁竞争,CPU利用率高 | 上下文切换频繁,锁竞争损耗大 |
| 复杂度 | 低(无需处理线程安全、死锁问题) | 高(需设计锁机制、解决死锁/竞态条件) |
| 并发连接支撑 | 强(支持百万级连接,依赖epoll) | 弱(线程数有限,连接数多了内存溢出) |
| 适用场景 | I/O密集型(网络请求多、计算少,如Redis) | CPU密集型(计算多、I/O少,如视频编码) |
延伸思考:Redis什么时候适合用多线程?
虽然Redis核心逻辑用单线程,但在以下场景,多线程是更好的选择:
- 处理"CPU密集型"命令:如
SORT(大规模数据排序)、BF.ADD(批量添加布隆过滤器元素)------这类命令执行耗时久,会阻塞单线程,可通过"多线程池"异步处理。 - 超大规模网络I/O:Redis 6.0引入的"网络I/O多线程",正是为了应对"10万+并发连接"的网络瓶颈------但命令执行仍单线程,避免了锁竞争。
五、实战验证:用redis-benchmark测试单线程性能
光说不练假把式,用Redis自带的redis-benchmark工具,实测单线程Redis的并发性能(测试环境:8核CPU、16GB内存、Linux系统):
1. 测试命令(模拟10万请求、1000并发连接)
bash
redis-benchmark -n 100000 -c 1000 -t SET,GET -q2. 测试结果(单线程vs开启6个I/O线程)
| 模式 | SET命令QPS | GET命令QPS | 平均响应时间(毫秒) |
|---|---|---|---|
| 单线程(6.0前) | 112359 | 120481 | 0.89 |
| 多线程I/O(6.0+) | 189393 | 198765 | 0.51 |
结论:开启多线程I/O后,QPS提升约70%------印证了"网络I/O是瓶颈",也说明多线程仅优化I/O,不改变命令执行单线程的核心。
六、面试高频延伸题(附标准答案)
-
问:Redis的I/O多路复用为什么选择epoll,而不是select/poll?
答:① epoll时间复杂度是O(1),select/poll是O(n),支持百万级连接;② epoll仅拷贝一次Socket数据,select/poll每次等待都要拷贝;③ epoll支持边缘触发(ET),能减少不必要的事件处理。
-
问:epoll的水平触发(LT)和边缘触发(ET)有什么区别?Redis用的哪种?
答:LT:只要Socket有数据未处理,就持续触发事件;ET:仅在数据到达的"瞬间"触发一次事件。Redis用LT模式------避免ET模式下"漏处理数据"的复杂逻辑,且Redis命令执行快,不会因LT模式导致事件堆积。
-
问:单线程Redis如何处理"耗时命令"(如
KEYS *)?答:耗时命令会阻塞单线程,导致所有客户端请求延迟。解决方案:① 用
SCAN替代KEYS *(分批遍历,不阻塞);② 大键删除用UNLINK(异步删除);③ 禁用危险命令(如在redis.conf中配置rename-command KEYS "")。 -
问:Redis的单线程模型,在多核CPU服务器上如何充分利用资源?
答:① 开启Redis 6.0+的多线程I/O(利用多核处理网络请求);② 部署多个Redis实例(如8核CPU部署8个实例),每个实例绑定一个CPU核心(通过
taskset命令)------避免实例间CPU切换开销。
七、总结与下一篇预告
Redis单线程高并发的本质是:在I/O密集型场景下,避开多线程的坑,把单线程的优势用到极致:
- 用I/O多路复用突破"单线程处理多连接"的限制;
- 用纯内存操作、高效数据结构减少"命令执行耗时";
- 用无多线程开销保证"CPU资源不浪费"。
理解这一点,就能轻松回答"Redis为什么快""单线程vs多线程的选择"等核心面试题。
下一篇将聚焦"数据安全"------拆解Redis持久化机制(RDB+AOF)的底层实现、混合持久化的原理、以及生产环境的配置方案,解决"Redis宕机后数据丢失"的核心痛点,敬请关注。
如果觉得本文有用,欢迎收藏+转发,后续会持续更新Redis面试核心系列,帮你系统攻克Redis考点~