1. actor_rollout.ref.rollout.n
actor_rollout.ref.rollout.n对于每个提示,采样 n 次。默认值为 1。对于 GRPO,请将其设置为大于 1 的值以进行分组采样。
GRPO 的核心:
"同一个 prompt 下,不同回答之间相互对比,学'相对好坏'"
该参数为每一个 prompt(输入样本),用 reference model 生成多少条候选回复(rollout 数量),即n = reference 模型对同一个输入采样的"回答条数"。
prompt(来自数据集)
↓
actor model 生成 response
↓
reward model 打分
↓
reference model 也生成 response --> 这里response的条数即为n
↓
计算 KL(actor || reference)
↓
PPO 更新 actor
参数拆解:
actor_rollout.ref.rollout.n
│ │ │
│ │ └── 每个 prompt 生成几条
│ └────────── reference model 的 rollout
└──────────────────────── actor 训练阶段的 rollout 配置
2. data.train_batch_size
data.train_batch_size = 一次 rollout 中,同时送入模型的 prompt数量(全局),即一次 rollout step 中,有多少个 不同的 prompt 参与采样。
响应/轨迹的数量为data.train_batch_size * actor_rollout.ref.rollout.n
假设你配置:
data.train_batch_size: 8
actor_rollout.ref.rollout.n: 4
那么一次 rollout 会发生:

3. actor_rollout_ref.actor.ppo_mini_batch_size
采样轨迹集被分割成多个小批次,每个小批次的大小为 batch_size=ppo_mini_batch_size,用于 PPO actor 的更新。ppo_mini_batch_size 是所有工作进程的全局大小。
用于一次 PPO 更新 的 response / trajectory 数量(全局)
actor_rollout_ref.actor.ppo_mini_batch_size
│ │ │
│ │ └── PPO 更新时的小 batch
│ └───────── actor 网络
└──────────────────────────── rollout + reference 框架下
(1) Rollout
├─ 生成 response(B × n)
├─ 计算 reward / advantage / KL
↓
(2) PPO Update(多 epoch) ---->这里
├─ 将 rollout 得到的所有 trajectory
├─ 切分成多个 mini-batch
├─ 对每个 mini-batch 做反向传播
假设你的配置:
data.train_batch_size: 8
actor_rollout.ref.rollout.n: 4
actor_rollout_ref.actor.ppo_mini_batch_size: 8
1️⃣ Rollout 阶段
8 个 prompt × 4 response → 共 32 条 trajectory
2️⃣ PPO 更新阶段
32 条 trajectory ÷ 8(mini-batch) → 4 次反向传播 / PPO step(每个 epoch)
合理区间:
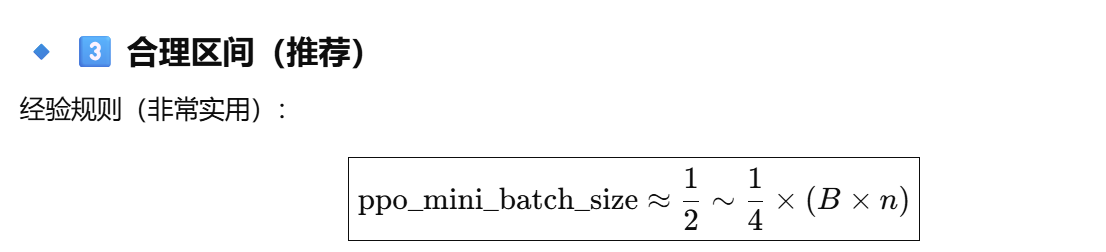
4. actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu
ppo_micro_batch_size_per_gpu
→ Actor 做 PPO 反传时,每张 GPU 一次吃多少条 trajectoryactor.log_prob_micro_batch_size_per_gpu
→ Actor 计算 log_prob 时,每张 GPU 一次吃多少条 trajectoryref.log_prob_micro_batch_size_per_gpu
→ Reference 计算 log_prob 时,每张 GPU 一次吃多少条 trajectory
⚠️ 注意:
micro batch ≠ train_batch ≠ ppo_mini_batch
ppo_micro_batch_size_per_gpu:
控制 Actor 在 PPO 更新(反向传播)时,每张 GPU 一次处理多少条 trajectory
🔹 调大(例如 16)
-
显存 ↑↑ 反传次数 ↓
-
速度更快
-
容易 OOM
🔹 调小(例如 2)
-
显存 ↓ 反传次数 ↑↑
-
训练变慢
-
稳定但低效
5. actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu
指Actor 在 rollout 阶段,计算 response 的 log_prob 时的 micro-batch
Actor rollout 生成 response
↓
需要算 log π_actor(a|s)
↓
用这个参数拆 micro-batch
log_prob 指的是:
模型在"给定上下文(prompt + 已生成前缀)下,生成当前 response 中每一个 token 的对数概率(log probability)"
-
概率大 → log_prob 接近 0(不那么负)
-
概率小 → log_prob 是很大的负数
|--------|-----------|
| reward | 这条回答"好不好" ||----------|------------|
| log_prob | 模型"会不会这样说" ||----|--------------|
| KL | 两个模型"说话习惯差多远 |
6. actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu
Reference 模型在计算 log_prob 时的 micro-batch
7.actor_rollout_ref.actor.use_kl_loss
GRPO 不是在奖励中添加 KL 惩罚,而是直接将训练策略与参考策略之间的 KL 散度添加到损失中,从而实现正则化:
actor_rollout_ref.actor.use_kl_loss:在 Actor 模型中使用 KL 损失。启用此选项后,奖励函数中将不再应用 KL 损失。默认值为 False。请将其设置为 True 以用于 GRPO 模型。

| use_kl_loss | KL 位置 |
|---|---|
| False | reward 里(PPO ) |
| True | actor loss 里(GRPO ) |
8. actor_rollout_ref.actor.kl_loss_coef/kl_loss_type
actor_rollout_ref.actor.kl_loss_coef:kl损失系数。默认值为0.001。
| coef 大小 | 行为 |
|---|---|
| 很小 | actor 自由探索 |
| 适中 | 稳定学习 |
| 很大 | actor 被锁死 |
actor_rollout_ref.actor.kl_loss_type支持 kl(k1)、abs、mse(k2)、low_var_kl(k3) 和 full。在末尾添加"+"(例如,'k1+' 和 'k3+')将直接应用 k2 进行无偏梯度估计,而不管 kl 值估计如何
9. actor_rollout_ref.rollout.enforce_eager=False
控制的是 rollout / log_prob / 生成阶段:
| 模式 | 特点 |
|---|---|
enforce_eager = True |
逐步执行、立刻释放中间张量、省显存 |
enforce_eager = False |
允许 graph / fused / compiled 执行、吃显存 |
设为 False时,框架会预先分配一块巨大的"显存池"(Memory Pool)来记录和重放所有的 GPU 操作指令,从而减少 CPU 发射指令的延迟,提高生成速度。
设为 True 时:对**复现精度无影响,**只是生成速度会变慢
10. actor_rollout_ref.rollout.free_cache_engine=False
指的是:是否在 rollout / log_prob 阶段,主动释放(free)推理引擎中缓存的显存
| 参数值 | 行为 |
|---|---|
False |
缓存尽量复用 → 更快,但显存长期占用 |
True |
每轮/每阶段后释放缓存 → 更省显存,但更慢 |
参考内容:
https://verl.readthedocs.io/en/latest/algo/grpo.html
GPT老师