系列文章目录
文章目录
- 系列文章目录
- 前言
- 一、浪潮信息源大模型开源体系
-
- [1.1 浪潮信息源大模型](#1.1 浪潮信息源大模型)
- [1.2 源1.0大模型](#1.2 源1.0大模型)
- [1.3 源2.0大模型](#1.3 源2.0大模型)
- [1.4 源2.0-M32大模型](#1.4 源2.0-M32大模型)
- 二、大模型时代挖掘模型能力的开发范式
-
- [2.1 Prompt工程:零样本能力激发](#2.1 Prompt工程:零样本能力激发)
- [2.2 Embedding增强检索:突破知识边界](#2.2 Embedding增强检索:突破知识边界)
- [2.3 参数高效微调(PEFT):轻量化能力定制](#2.3 参数高效微调(PEFT):轻量化能力定制)
- [三、大模型应用开发 必知必会](#三、大模型应用开发 必知必会)
- 四、动手开发baseline
- 五、动手理解baseline
- 总结
前言
一、浪潮信息源大模型开源体系
1.1 浪潮信息源大模型
- 截止到目前,浪潮信息已经发布了三个大模型: 源1.0 , 源2.0 和 源2.0-M32 ,其中 源1.0 开放了模型API、高质量中文数据集和代码, 源2.0 和 源2.0-M32 采用全面开源策略,全系列模型参数和代码均可免费下载使用。
1.2 源1.0大模型
-
2021年9月,源1.0大模型发布,它采用76层的Transformer Decoder结构,使用5T数据训练,拥有2457亿参数量,超越OpenAI研发的GPT-3,成为全球最大规模的AI巨量模型,表现出了出色的中文理解与创作能力。
1.3 源2.0大模型
-
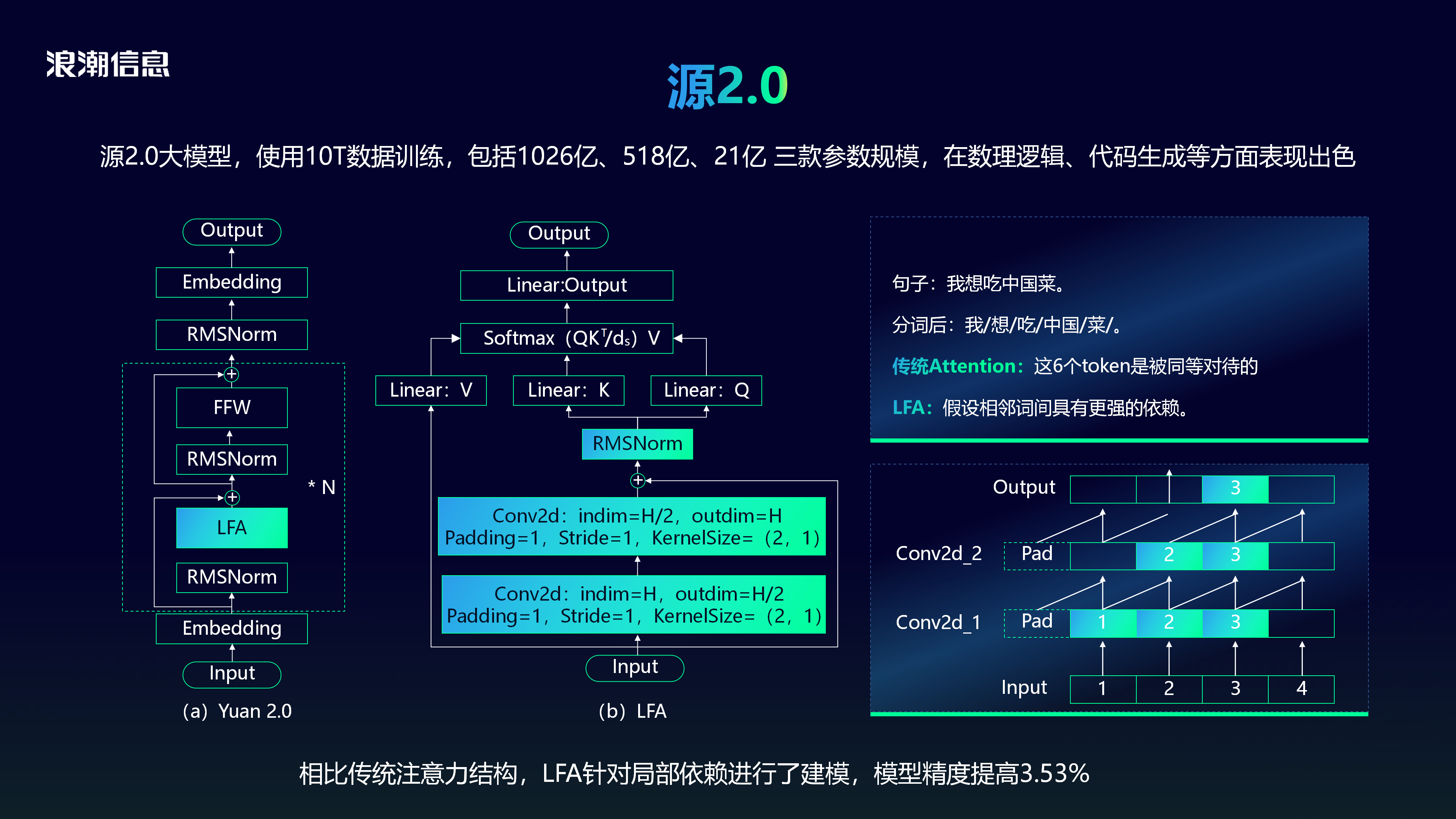
2023年11月,源2.0大模型发布,它使用10T数据训练,包括1026亿、518亿、21亿 三款参数规模,在数理逻辑、代码生成等方面表现出色。
-
在算法方面,与传统Attention对输入的所有文字一视同仁不同,源2.0提出了局部注意力过滤增强机制(Localized Filtering-based Attention, LFA),它假设自然语言相邻词之间有更强的语义关联,因此针对局部依赖进行了建模,最后使得模型精度提高3.53%。
1.4 源2.0-M32大模型
-
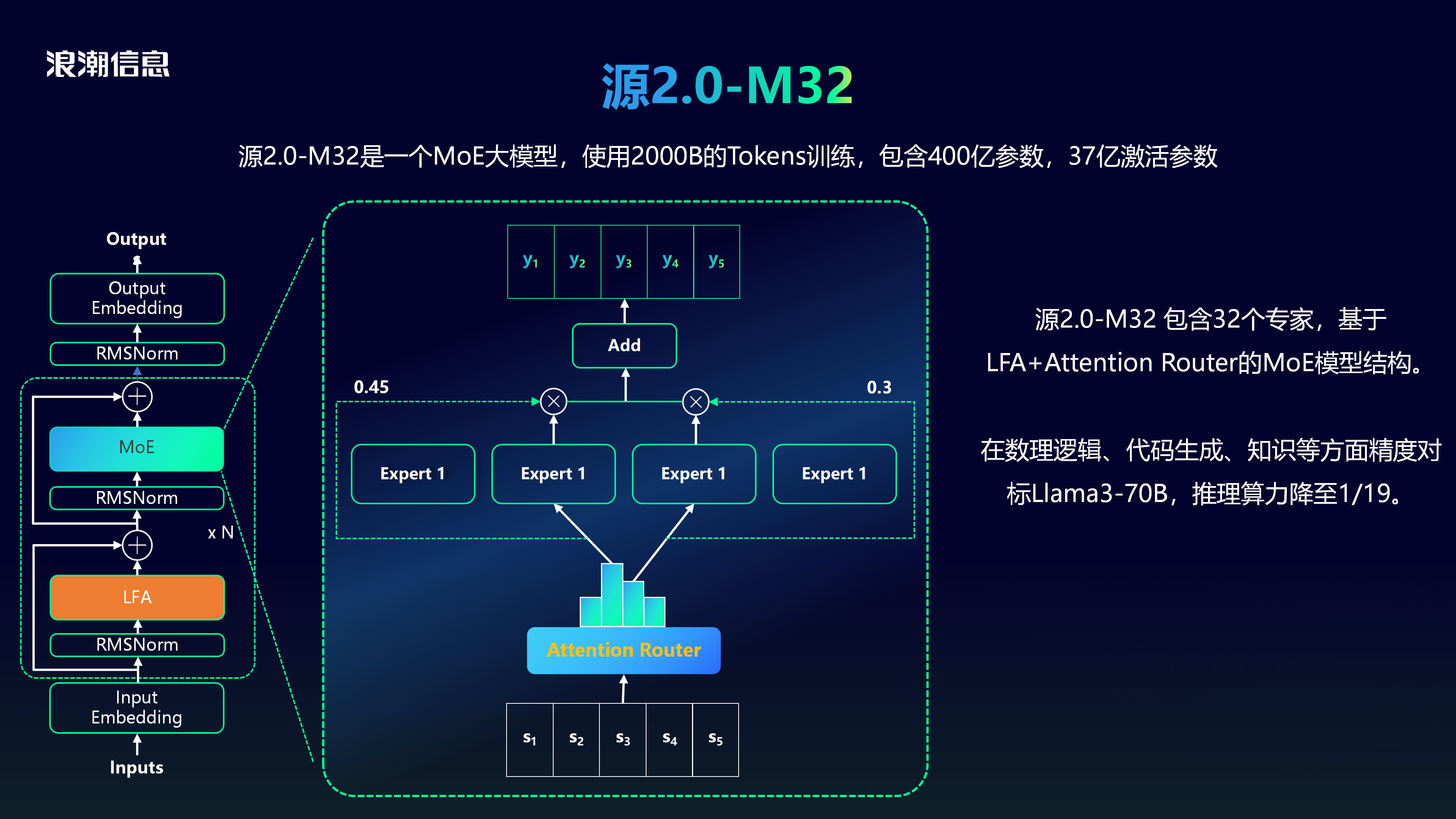
2024年5月,源2.0-M32发布,它是一个混合专家(Mixture of Experts, MoE)大模型,使用2000B Tokens训练,包含400亿参数,37亿激活参数
-
源2.0-M32 包含32个专家,基于LFA+Attention Router的MoE模型结构。
-
源2.0-M32 在数理逻辑、代码生成、知识等方面精度对标Llama3-70B,推理算力降至1/19。
二、大模型时代挖掘模型能力的开发范式
- 在大模型时代,人工智能的应用边界持续扩展。如何充分释放大模型潜能,已成为开发者的核心课题。不同场景催生了三大关键技术策略:
2.1 Prompt工程:零样本能力激发
-
通过结构化提示(Prompt)直接引导模型输出。关键技术包括:
- 上下文学习(ICL):将任务指令与示例嵌入提示,利用模型内生推理能力实现零样本任务适配。
- 思维链提示(CoT):在提示中注入逻辑推理链,显著提升复杂问题的解析深度。
2.2 Embedding增强检索:突破知识边界
- 大模型在实际应用中面临三重制约:
- 知识时效局限:训练数据依赖历史公开资源,无法覆盖实时/非公开信息;
- 数据安全风险:企业敏感数据难以纳入训练集;
- 生成幻觉:概率生成机制易导致事实性错误。
- 解决方案:将外部知识转化为Embedding向量构建检索库,通过实时检索注入上下文,为模型提供精准外部知识源,有效抑制幻觉并保障数据安全。
2.3 参数高效微调(PEFT):轻量化能力定制
-
当模型基础能力不足或需新增专业技能时:
- 指令微调(SFT) 通过监督学习适配特定任务,但全参数微调计算成本过高;
- PEFT技术(如LoRA、Adapter)仅优化0.1%-5%的参数,即可达到全量微调90%以上的效果,实现算力与性能的平衡。
三、大模型应用开发 必知必会
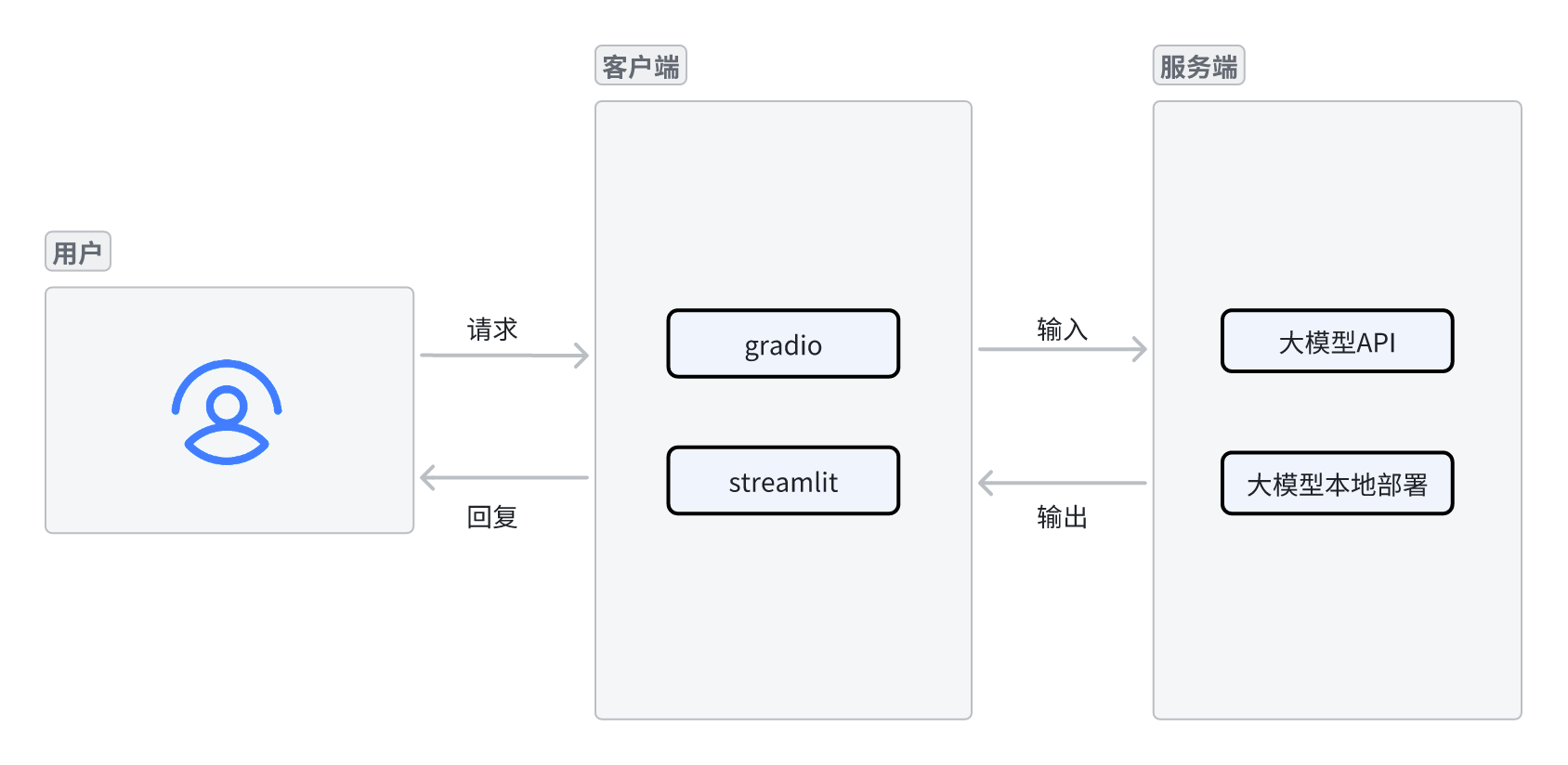
通常,一个完整的大模型应用包含一个客户端和一个服务端。
- 客户端接收到用户请求后,将请求输入到服务端,服务端经过计算得到输出后,返回给客户端回复用户的请求。
四、动手开发baseline
-
跟着教程一起开发 大模型部署【搭建你的智能编程助手】
-
使用魔搭的免费Notebook实例
-
下载文件,安装依赖,启动。
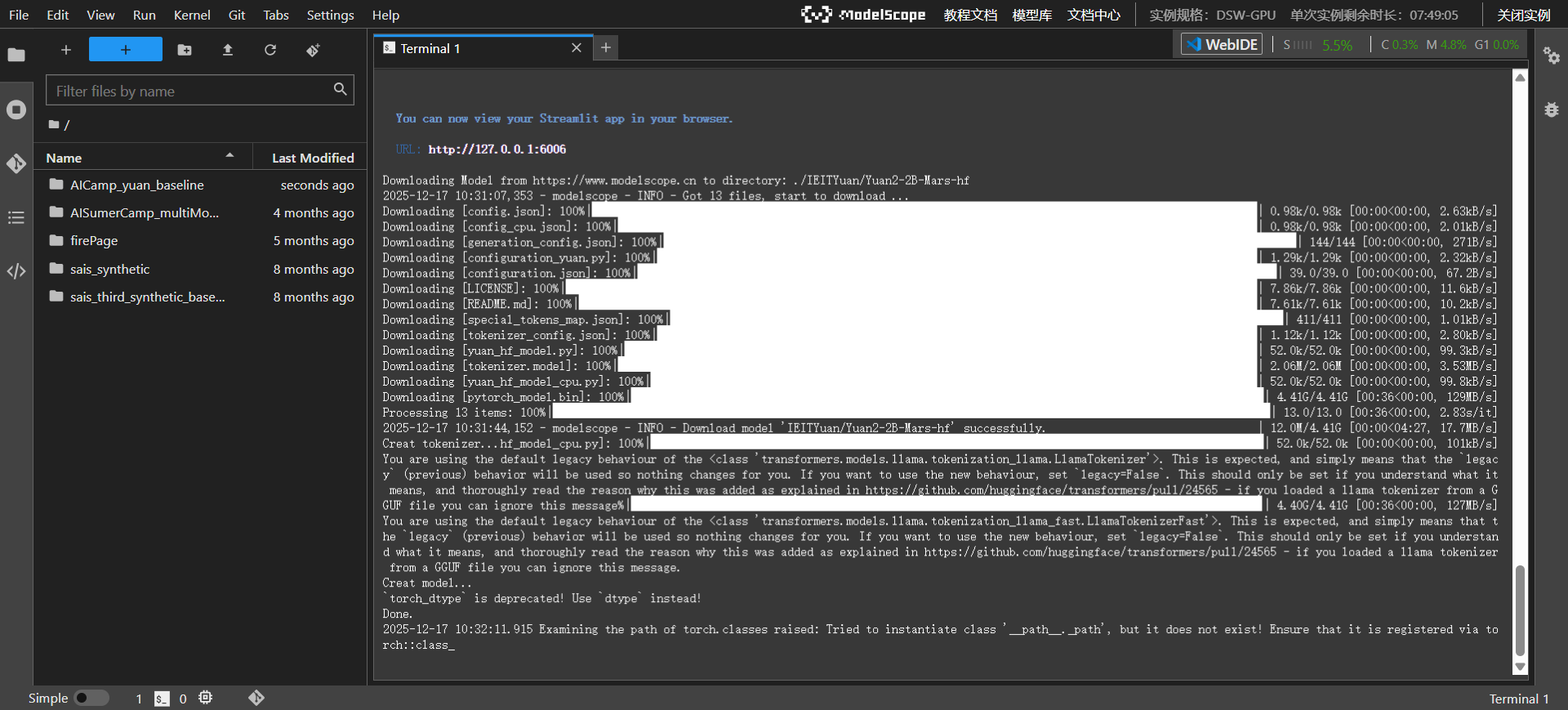
-
加载模型
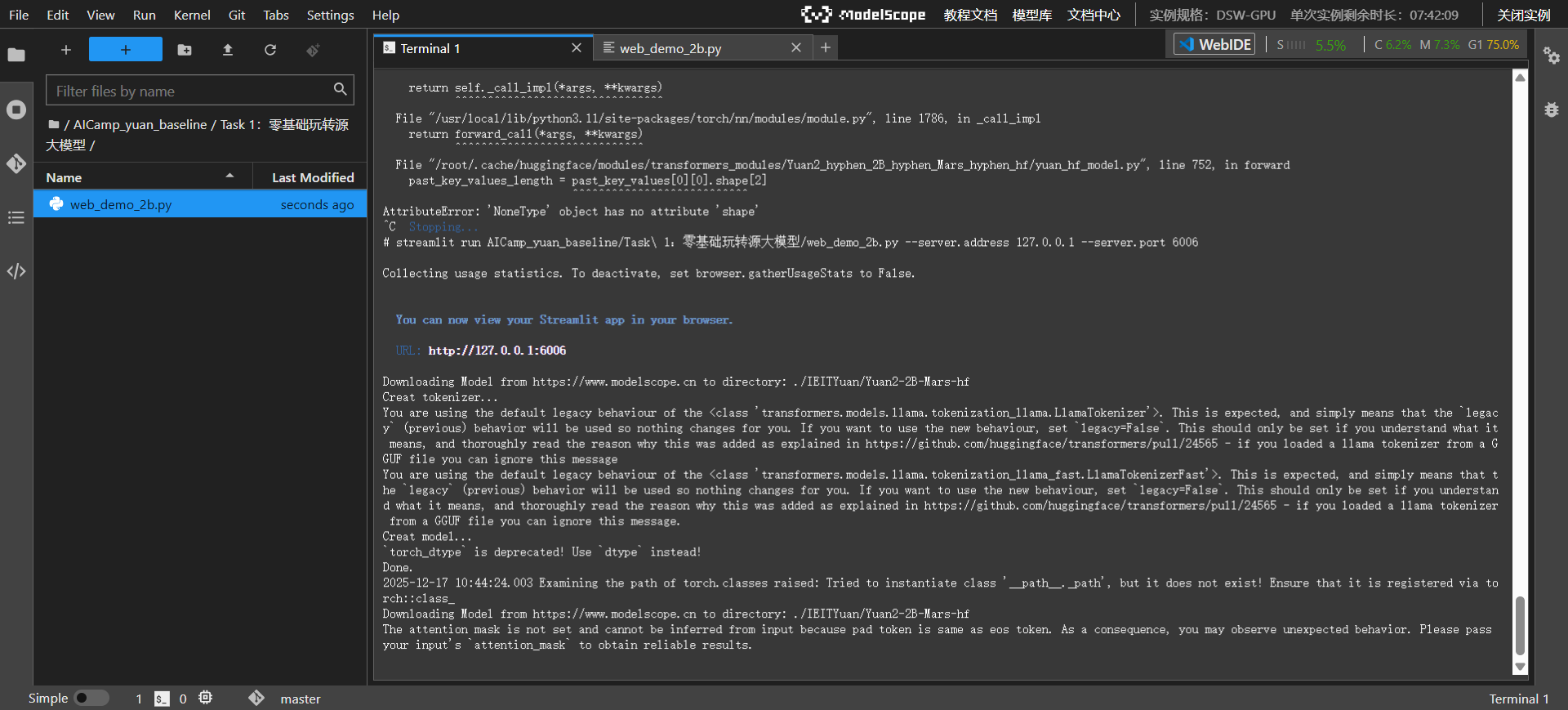
-
对话体验
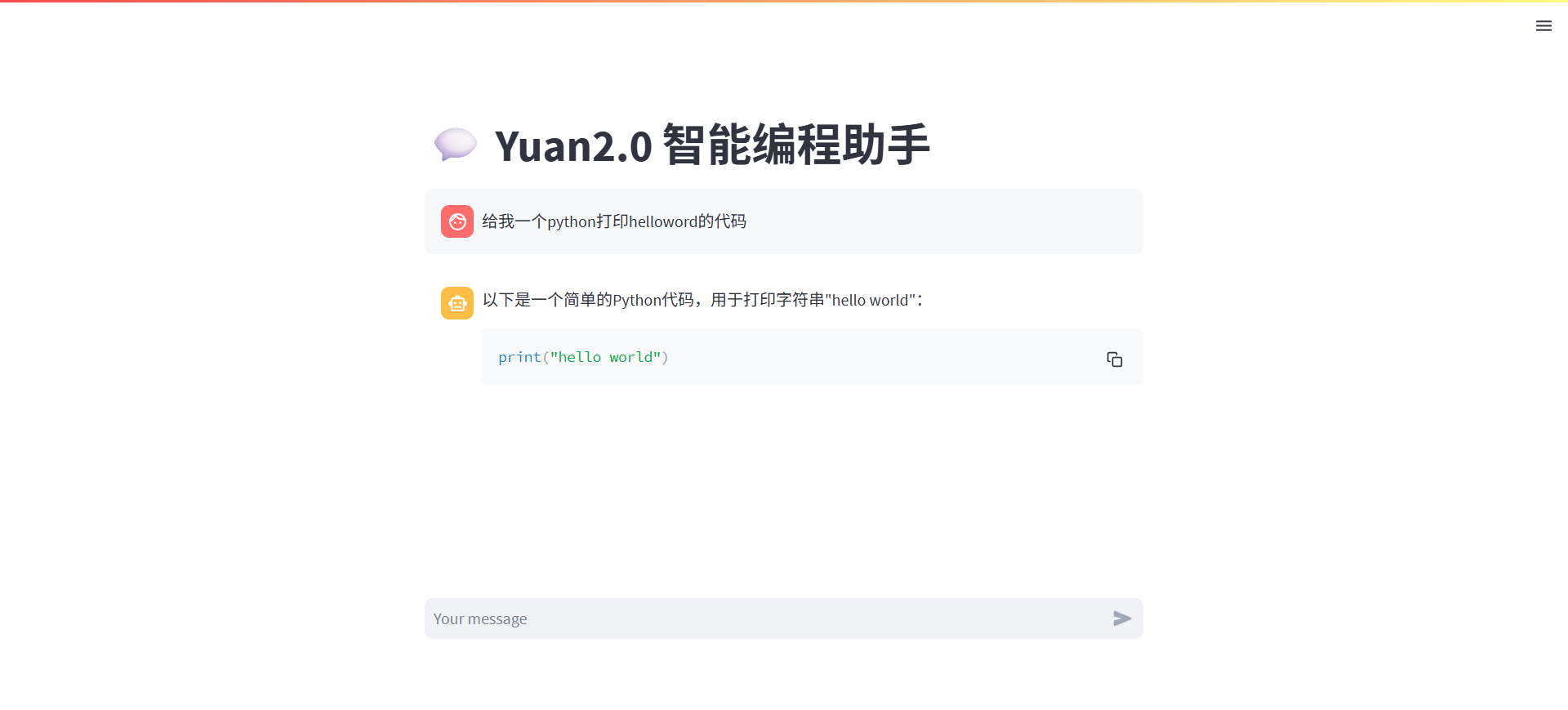
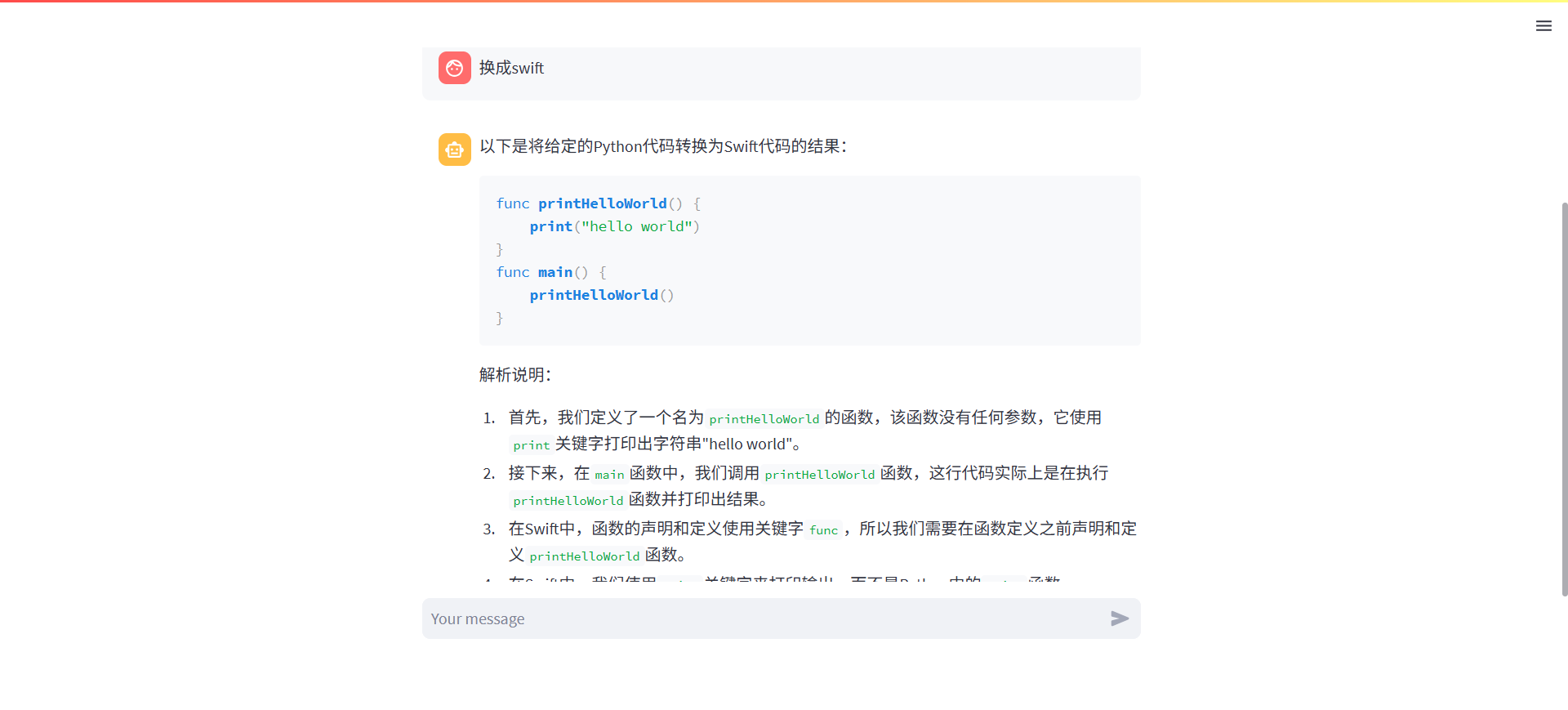
五、动手理解baseline
1.引入库
代码如下(示例):
python
# 导入所需的库
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import streamlit as st2.读入数据
代码如下(示例):
c
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())该处使用的url网络请求的数据。