TL;DR
- 场景:在本机/单机快速体验 Apache Druid 30.0.0,验证实时与历史查询与控制台访问。
- 结论:按 single-server quickstart 配置可平滑起服;端口与内存/JVM 是最易踩的坑。
- 产出:下载解压与环境变量清单、各启动命令对照、访问入口与常见错误速查卡。

版本矩阵
| 目标 | 已验证 | 说明 |
|---|---|---|
| Druid 30.0.0 下载与解压 | 是 | 按文中命令与截图完成 |
| 环境变量(DRUID_HOME/PATH) | 是 | /etc/profile 写入并刷新生效 |
| 单机 nano-quickstart 启动 | 是 | bin/start-nano-quickstart,用于最低配验证 |
| 控制台访问 8888 | 是 | 提供示例地址;注意放行端口/安全组/防火墙 |
| micro-quickstart(4C/16G) | 待确认 | 建议同步调大 jvm.config 堆与处理线程数 |
| small/medium/large/xlarge | 待确认 | 需按机器规格与数据量评估 JVM 与处理/缓存参数 |
| ZooKeeper 2181 冲突处理 | 是 | 已通过停止占用进程规避;也可改端口/外置 ZK |
| 批/流摄取(Kafka/HDFS/S3) | 待确认 | 单机验证可先跳过,集群/生产再配置 |

系统架构
Apache Druid 是一个开源的、分布式的高性能实时分析数据库系统,专为快速聚合和查询大规模数据集而设计。它特别适合处理时间序列数据、事件数据和日志数据等场景,广泛应用于互联网广告分析、在线交易监控、网络安全日志分析等领域。
Druid 的核心架构采用模块化设计,主要由以下几个关键组件构成:
-
协调节点(Coordinator Node)
- 负责数据分片(segment)的生命周期管理
- 监控数据节点状态
- 执行数据平衡和复制策略
-
历史节点(Historical Node)
- 存储和查询不可变的数据分片
- 使用内存映射文件实现高效查询
- 支持多种压缩格式(如LZ4、Zstandard)
-
查询节点(Broker Node)
- 接收客户端查询请求
- 将查询路由到相关节点
- 聚合和返回最终结果
-
摄取节点(Ingestion Node)
- 实时数据摄取
- 支持批处理和流式两种模式
- 提供多种数据格式支持(JSON、CSV等)
-
深度存储(Deep Storage)
- 持久化存储层
- 支持HDFS、S3等分布式文件系统
- 确保数据高可用性
这些组件协同工作,使得Druid能够实现亚秒级的查询响应时间,并支持高达每秒百万级事件的数据摄入能力。典型部署方案中,每个组件都可以独立扩展,以满足不同的性能和容量需求。
核心组件
数据摄取层 (Ingestion Layer)
- 数据源: Druid 支持多种数据源,如 Kafka、HDFS、Amazon S3 等。数据摄取可以是批处理(Batch)或实时流处理(Streaming)。
- 任务管理: 使用任务协调器来管理数据摄取任务,确保数据流的顺畅和高可用性。
数据存储层 (Storage Layer)
Segment: Druid 将数据分为多个小块,称为"段"(Segment)。每个段通常包含一段时间内的数据,并被优化以支持快速查询。 时间分区: Druid 根据时间将数据分区,以提高查询性能。数据按时间戳索引,有助于高效的时间范围查询。
查询层 (Query Layer)
- Broker: 负责接收用户的查询请求并将其路由到相应的数据节点(如历史节点和实时节点)。
- 查询执行: Druid 支持多种查询类型,包括聚合查询、过滤查询和分组查询。查询结果会通过 Broker 返回给用户。
历史节点 (Historical Node)
- 存储并管理长时间的数据段,负责处理对历史数据的查询。
实时节点 (Real-time Node)
- 用于实时摄取数据,实时处理并生成可查询的段。适合需要低延迟数据访问的应用。
协调节点 (Coordinator Node)
- 负责管理 Druid 集群的各个节点,监控节点的健康状态、数据分布和负载均衡。
数据流动
- 数据摄取: 数据从外部源流入 Druid(如 Kafka 消息队列),经过任务管理和转换后被摄取。
- 数据存储: 数据被分段并存储在历史节点和实时节点中,按时间分区和压缩以优化存储。
- 查询处理: 用户通过查询接口(如 SQL 或 Druid 特定的查询语言)发送查询请求,Broker 节点将请求分发到相应的数据节点,聚合和处理查询结果后返回。
查询优化
- 列式存储: Druid 采用列式存储格式,提高了压缩率和查询性能。
- 索引: Druid 会为每个字段建立索引,加速过滤和聚合操作。
- 预聚合: 对常用的聚合操作进行预计算,以减少实时查询的计算负担。
可扩展性与高可用性
- Druid 支持横向扩展,可以根据需求添加更多的节点来处理更大的数据集和更高的查询负载。
- 数据冗余和节点监控机制确保了系统的高可用性。
下载解压
官方目前已经到了版本30了
shell
wget https://dlcdn.apache.org/druid/30.0.0/apache-druid-30.0.0-bin.tar.gz直接结果如下图所示:  进行解压:
进行解压:
shell
tar -zxvf apache-druid-30.0.0-bin.tar.gz执行结果如下图所示:  移动到目标目录:
移动到目标目录:
shell
mv apache-druid-30.0.0 /opt/servers/
cd /opt/servers/apache-druid-30.0.0
ls执行结果如下图所示: 
单机部署
配置文件
单服务器部署的配置文件如下:
shell
conf/druid/single-server/
├── large
├── medium
├── micro-quickstart
├── nano-quickstart
├── small
└── xlarge文件的路径如下图所示: 
启动要求
单服务器的要求如下:
shell
Nano-Quickstart:1个CPU,4GB RAM
启动命令: bin/start-nano-quickstart
配置目录: conf/druid/single-server/nano-quickstart/*
微型快速入门:4个CPU,16GB RAM
启动命令: bin/start-micro-quickstart
配置目录: conf/druid/single-server/micro-quickstart/*
小型:8 CPU,64GB RAM(〜i3.2xlarge)
启动命令: bin/start-small
配置目录: conf/druid/single-server/small/*
中:16 CPU,128GB RAM(〜i3.4xlarge)
启动命令: bin/start-medium
配置目录: conf/druid/single-server/medium/*
大型:32 CPU,256GB RAM(〜i3.8xlarge)
启动命令: bin/start-large
配置目录: conf/druid/single-server/large/*
大型X:64 CPU,512GB RAM(〜i3.16xlarge)
启动命令: bin/start-xlarge
配置目录: conf/druid/single-server/xlarge/*环境变量
shell
vim /etc/profile写入如下的内容,记得刷新环境变量:
shell
# druid
export DRUID_HOME=/opt/servers/apache-druid-30.0.0
export PATH=$PATH:$DRUID_HOME/bin写入内容如下图所示:  (这里注意,要关闭其他的服务,比如ZK什么的,不然会提示2181端口会占用)
(这里注意,要关闭其他的服务,比如ZK什么的,不然会提示2181端口会占用)
shell
zkServer.sh stop执行结果如下图所示:  接着进行启动,启动结果如下图所示:
接着进行启动,启动结果如下图所示: 
查看页面
shell
http://h121.wzk.icu:8888/页面结果显示如下图: 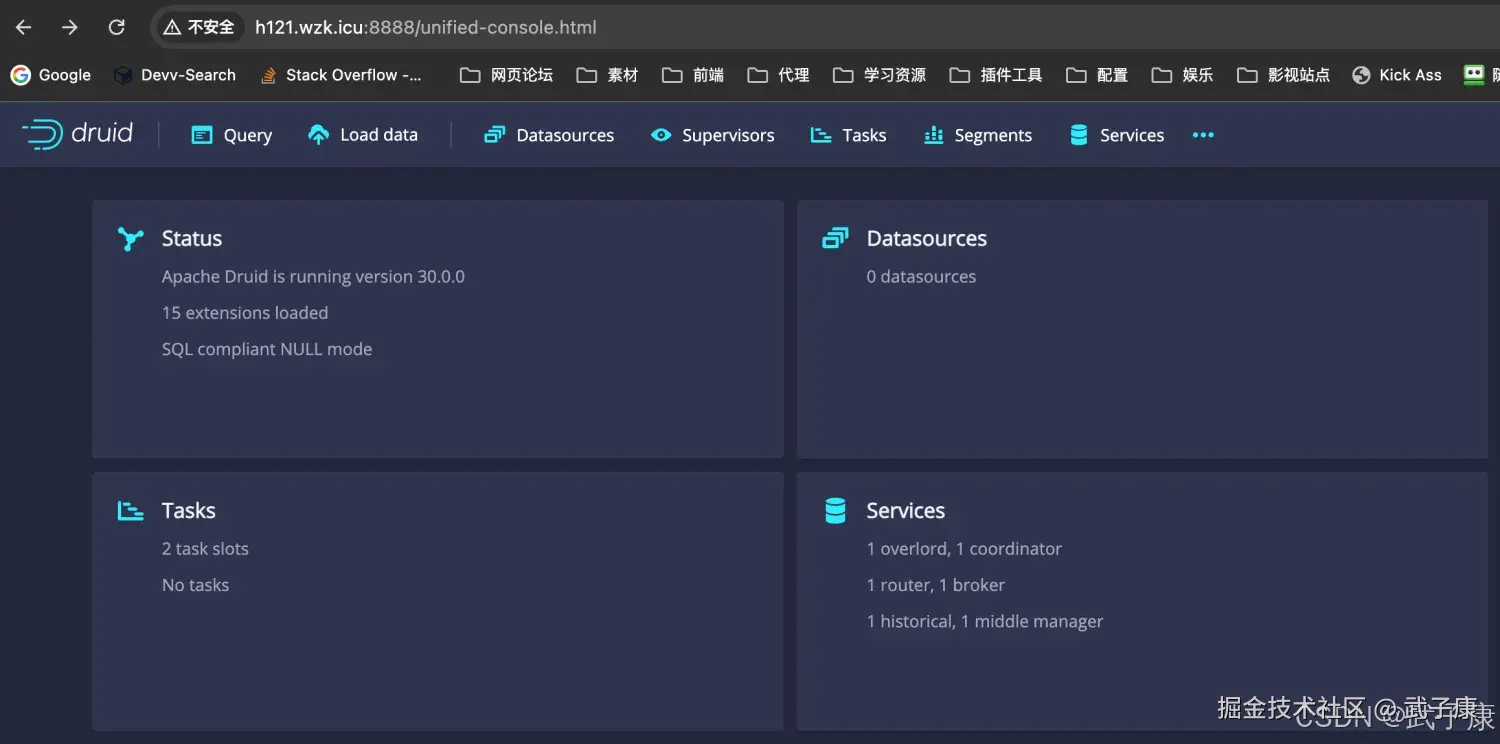
 PS:官方建议大型系统采用集群模式部署,以此来实现容错和减少资源的争抢。
PS:官方建议大型系统采用集群模式部署,以此来实现容错和减少资源的争抢。
错误速查
| 症状 | 根因 | 定位方法 | 修复方案 |
|---|---|---|---|
| 8888 无法访问 | 端口未放行或仅监听本地 | ss -lntp/防火墙规则、日志无异常 |
放行 8888/改绑定地址;确认反向代理与安全组 |
| 启动报 OOM/GC 过高 | JVM 堆过小、处理线程过多 | var/sv/*/logs 中 OutOfMemoryError |
调整 conf/**/jvm.config 的 -Xms/-Xmx 与处理线程 |
| 2181 端口占用 | 本机已有 ZK 或其他进程 | lsof -i :2181 |
停止占用进程或调整 Druid/ZK 端口并重启 |
| 控制台 "No datasource found" | 未完成摄取或段未加载 | Coordinator/Historical 日志与 Segments 页签 | 等待任务完成;检查 Deep Storage 与 Historical 可用性 |
| 查询很慢/超时 | 时间分区/过滤未命中、堆外内存不足 | Broker/Historical 日志、查询计划 | 优化时间过滤与维度索引;增大处理线程与内存缓冲 |
| Kafka 流摄取失败 | Topic 不可达或鉴权错误 | Indexing Service 日志含连接/鉴权报错 | 校验 bootstrap.servers 与 SASL/SSL 配置,独立 kcat 连通性测试 |
| 时间范围错位 | 时区/时间戳解析不一致 | 采集与查询的时区/格式检查 | 统一 ingestion timestampSpec 与查询时区;必要时做 transform |
| 权限/可执行报错 | 可执行位/目录权限不足 | ls -l bin/、系统日志 |
chmod +x bin/*;确保运行用户对安装目录可读写 |
| "找不到配置"/参数不生效 | 修改后未刷新环境/路径错误 | echo $DRUID_HOME/which druid |
重新 source /etc/profile,核对配置目录与实际启动脚本 |
| 段未分配/查询缺数据 | Historical 离线或负载不均 | Coordinator UI 的 Segment 分配状态 | 启动/扩容 Historical;检查存储可达与副本均衡策略 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解