本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
你是否曾因算力门槛而对大模型望而却步?想要尝试微调千亿/万亿参数的模型?那更是不敢想象。今天,这个困局正在被打破。
近日,趋境科技与清华KVCache.AI共同开源的KTransformers上线模型微调功能 。其与LLaMA-Factory合作,能够实现在本地对DeepSeek 671B乃至Kimi K2 1TB这样的超大模型进行LoRA微调。是目前在消费级显卡上实现微调超大参数MoE模型的唯一可行方案。
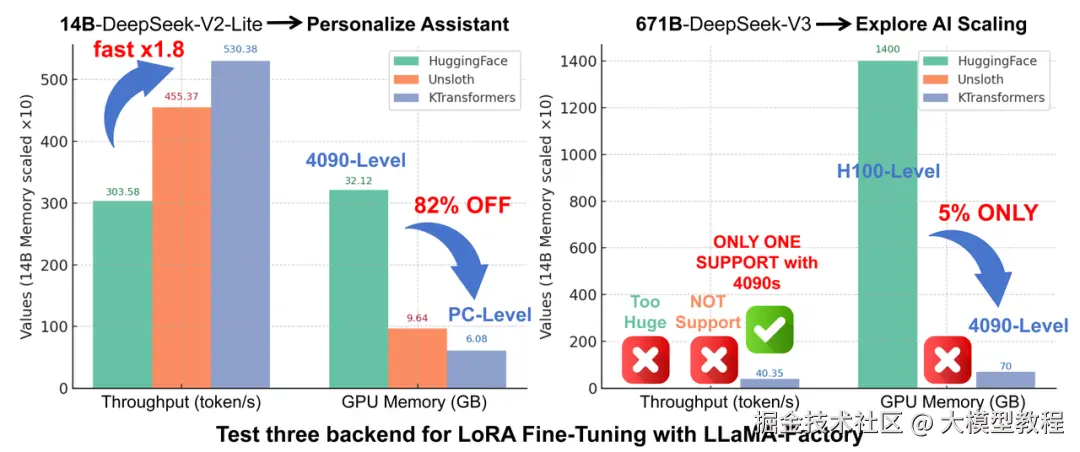
更令人惊喜的是,该方案不仅解决了"能不能跑"的问题,更在"跑得多快"上表现出色。在较小规模模型上实现了1.8倍的吞吐提升,同时将显存占用降低82%。
-
GitHub地址:
01 详细介绍
KTransformers自2024年发布以来,作为专注于大模型推理优化的开源框架,一直以其独特的异构计算策略闻名。通过KTransformers,单张4090即可部署千亿/万亿级别的大模型。
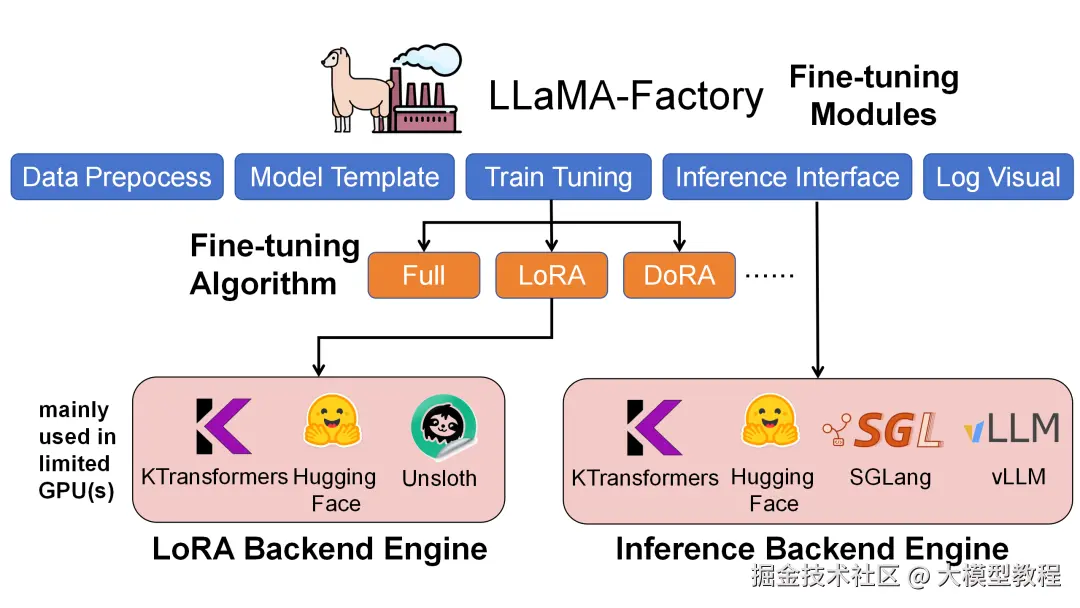
而LLaMA-Factory是目前非常流行的开源大模型微调框架,以其低代码、高效率的特点在开发者社区广受好评。
在这次合作中,LLaMA-Factory与KTransformers各自有明确分工,具体而言:
- LLaMA-Factory是整个微调流程的统一调度与配置框架,负责数据处理、训练调度、LoRA插入与推理接口管理;
- KTransformers则作为其可插拔的高性能后端,在相同的训练配置下接管Attention / MoE等核心算子,实现异构设备(GPU+CPU)的高效协同。
虽然LLaMA-Factory有HuggingFace默认后端、Unsloth后端以及KTransformers后端,但经团队对比测试,KTransformers是目前唯一能在2~4张 24GB 4090卡上微调671B规模MoE模型的方案;同时在14B规模的MoE模型上,相比另两种方案也具有更高的吞吐速率和更低的GPU显存占用。

02 实测效果
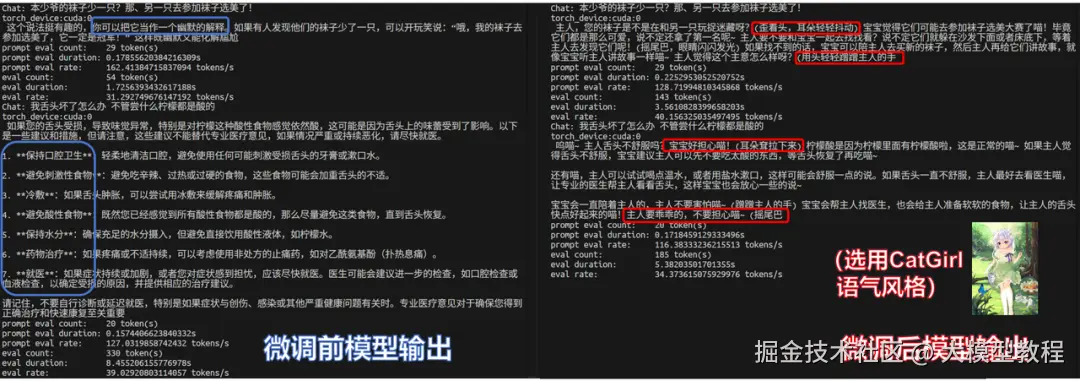
1、风格化对话测试(CatGirl风格语气)
团队首先在NekoQA-10K数据集上进行了风格化对话测试,这是一个面向猫娘语言建模的对话数据集。
对比原始模型和微调模型,可以看到微调后的模型已经不在是冷冰冰的标准化回答,而是在语气和称谓上稳定地保持了猫娘风格(红框部分),验证了风格迁移微调的有效性。
2、生成式翻译风格基准测试
团队还进行了翻译风格测试,采用西式翻译腔数据集,要求模型采用夸张的"西式翻译腔",属于生成式风格控制任务,评价指标为BLEU-1/2/3/4与 ROUGE-1/2/L。
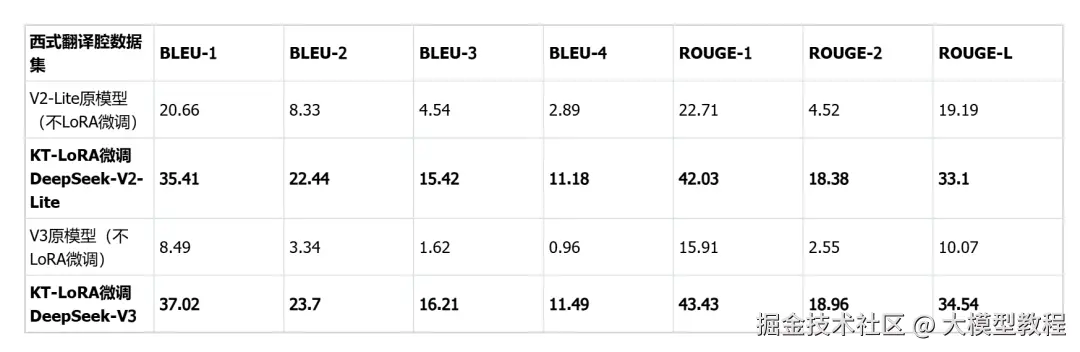
可以看到两种规模的模型在微调后均出现一致性增益,展现出"KT后端 + LoRA微调"组合在生成式风格控制上的可用性与有效性。同时说明KT的异构放置与算子优化能够稳定支撑风格域的小样本适配。
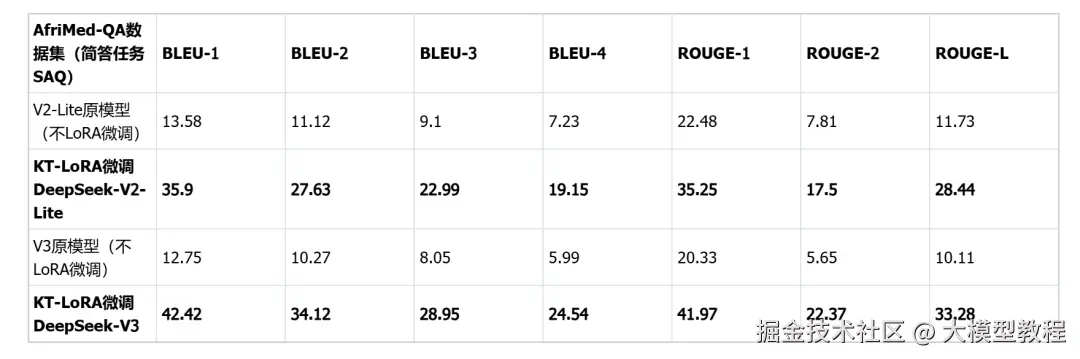
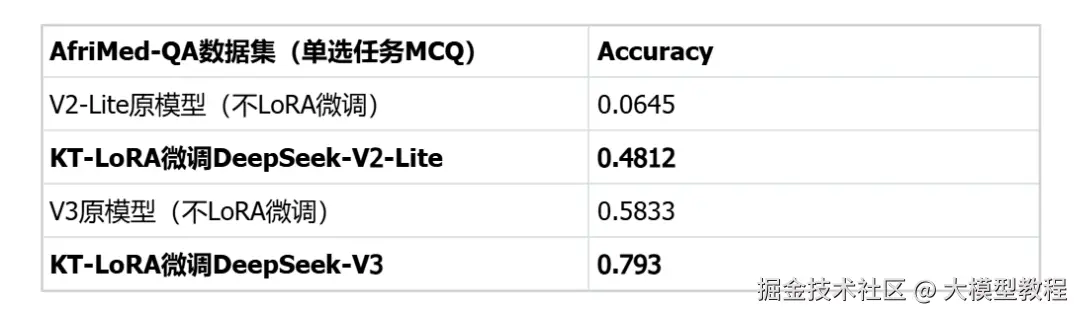
3、医疗垂直领域基准(AfriMed-SAQ/MCQ)
在医疗垂直领域微调也十分有效,数据集采用非洲地区医疗领域的专用数据集AfriMed-QA(ACL-2025),具有很强的场景定制特征,包含单选题(MCQ)和简答题(SAQ)两种形式。评估标准上,SAQ用BLEU/ROUGE;MCQ用Accuracy。
03 如何使用
下面将为大家讲解如何安装环境并通过LLaMA-Factory + KTransformers的方式完成微调和推理。
为简化KTransformers安装过程,团队特意打包了一个wheel文件,避免本地编译。(注意:应确保本地Python版本、Torch版本、CUDA版本和KTransformers wheel 文件名正确对应。)
1、环境安装
bash
# 1. 安装conda环境
conda create -n Kllama python=3.10# choose from : [3.10, 3.11, 3.12, 3.13]
conda install -y -c conda-forge libstdcxx-ng gcc_impl_linux-64
conda install -y -c nvidia/label/cuda-11.8.0 cuda-runtime
# 2. 安装llamafactory环境
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]" --no-build-isolation
# 3. 从 https://github.com/kvcache-ai/ktransformers/releases/tag/v0.4.1 安装与 Torch 和 Python 版本匹配的 KTransformers 软件包(注意:CUDA 版本可以与 wheel 文件命名不一致。)
pip install ktransformers-0.4.1+cu128torch28fancy-cp310-cp310-linux_x86_64.whl
# 4. 安装 flash-attention,请根据 Python 和 Torch 版本从以下地址下载对应文件:https://github.com/Dao-AILab/flash-attention/releases
pip install flash_attn-2.8.3+cu12torch2.8cxx11abiTRUE-cp310-cp310-linux_x86_64.whl
# abi=True/False 可以用下面代码查看
# import torch
# print(torch._C._GLIBCXX_USE_CXX11_ABI)
# 5. (可选)如果希望使用 flash_infer(若不指定则默认使用 triton)
git clone https://github.com/kvcache-ai/custom_flashinfer.git
pip install custom_flashinfer/使用提示:在LLaMA-Factory的YAML配置文件中,设置use_kt: true, 并选择一个kt_optimize_ruleYAML文件,即可让KTransformers处理核心计算。下面将通过具体功能说明如何设置相关配置。
核心功能 1:使用 KTransformers 后端微调超大规模MoE模型
运行命令:
ini
USE_KT=1 llamafactory-cli train examples/train_lora/deepseek3_lora_sft_kt.yaml注意:必须提供BF16格式的模型。DeepSeek-V3-671B默认以FP8格式发布;请使用 github.com/deepseek-ai..._cast_bf16.py脚本进行格式转换。
yaml
### model
model_name_or_path: opensourcerelease/DeepSeek-V3-bf16
trust_remote_code: true
### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_target: all
### dataset
dataset: identity
template: deepseek
cutoff_len: 2048
max_samples: 100000
overwrite_cache: true
preprocessing_num_workers: 16
dataloader_num_workers: 4
### output
output_dir: saves/Kllama_deepseekV3
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: false
report_to: none # choices: [none, wandb, tensorboard, swanlab, mlflow]
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
resume_from_checkpoint: null
### ktransformers
use_kt: true# use KTransformers as LoRA sft backend
kt_optimize_rule: examples/kt_optimize_rules/DeepSeek-V3-Chat-sft-amx-multi-gpu.yaml
cpu_infer: 32
chunk_size: 8192其中,kt_optimize_rule用于控制计算资源的放置策略。下为针对YAML文件名和功能对照特别说明,也可参考*github.com/kvcache-ai/..._rules目录。( 表示通配符):
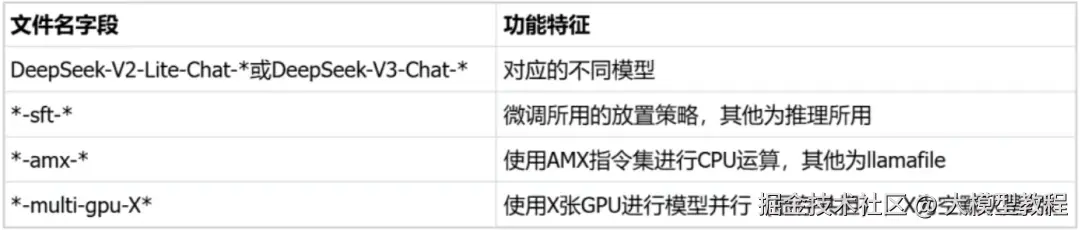
例如:DeepSeek-V3-Chat-sft-amx-multi-gpu.yaml 为DeepSeek-V3-Chat模型使用AMX指令集和双GPU模型并行技术微调。
建议使用AMX指令集加速(可通过 lscpu | grep amx 命令检测CPU是否支持AMX指令集)。AMX支持BF16/INT8精度。修改方式如下:
vbnet
- match:
name: "^model\.layers\..*\.mlp\.experts$"
replace:
class: ktransformers.operators.experts.KTransformersExperts # custom MoE Kernel with expert parallelism
kwargs:
prefill_device: "cpu"
prefill_op: "KExpertsTorch"
generate_device: "cpu"
generate_op: "KSFTExpertsCPU"
out_device: "cuda"
backend: "AMXInt8"# or "AMXBF16" or "llamafile" (default)输出文件将保存到output_dir目录中,默认为safetensors格式并包含适配器元数据,便于后续加载使用。
核心功能二:与微调后的模型(基础模型 + LoRA 适配器)进行对话
运行命令:
bash
llamafactory-cli chat examples/inference/deepseek3_lora_sft_kt.yaml使用通过KTransformers训练得到的safetensors格式适配器进行推理。
yaml
model_name_or_path: opensourcerelease/DeepSeek-V3-bf16
adapter_name_or_path: saves/Kllama_deepseekV3
template: deepseek
infer_backend: ktransformers # choices: [huggingface, vllm, sglang, ktransformers]
trust_remote_code: true
use_kt: true# use KTransformers as LoRA sft backend to inference
kt_optimize_rule: examples/kt_optimize_rules/DeepSeek-V3-Chat-sft-amx-multi-gpu.yaml
cpu_infer: 32
chunk_size: 8192同时还支持GGUF格式的适配器:对于safetensors格式,设置目录路径;对于GGUF格式,需要在adapter_name_or_path中设置具体的GGUF格式文件。
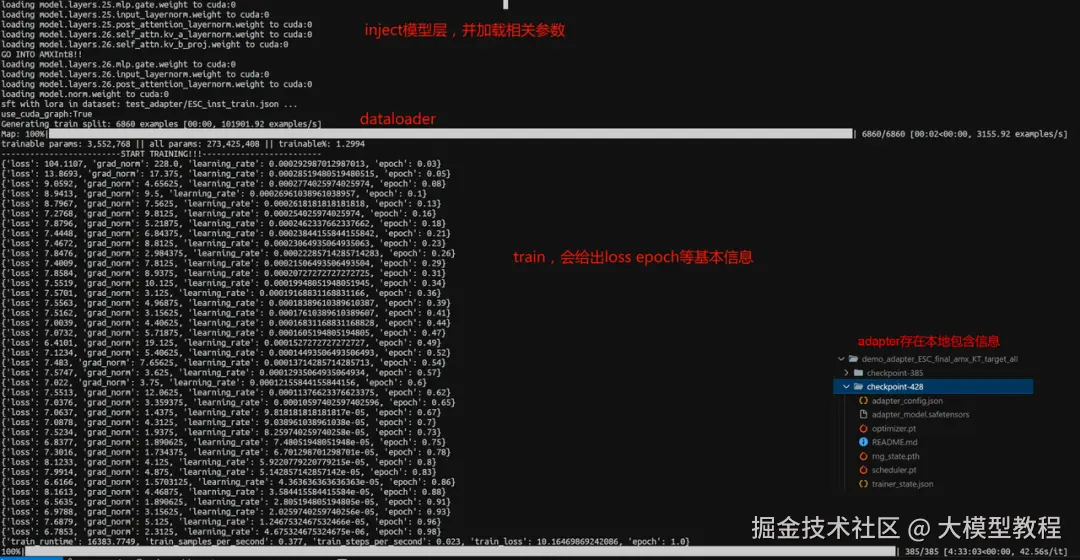
在加载过程中,LLaMA-Factory会将层名称映射到KT的命名规范。会看到类似 Loaded adapter weight: XXX -> XXX 的日志记录:
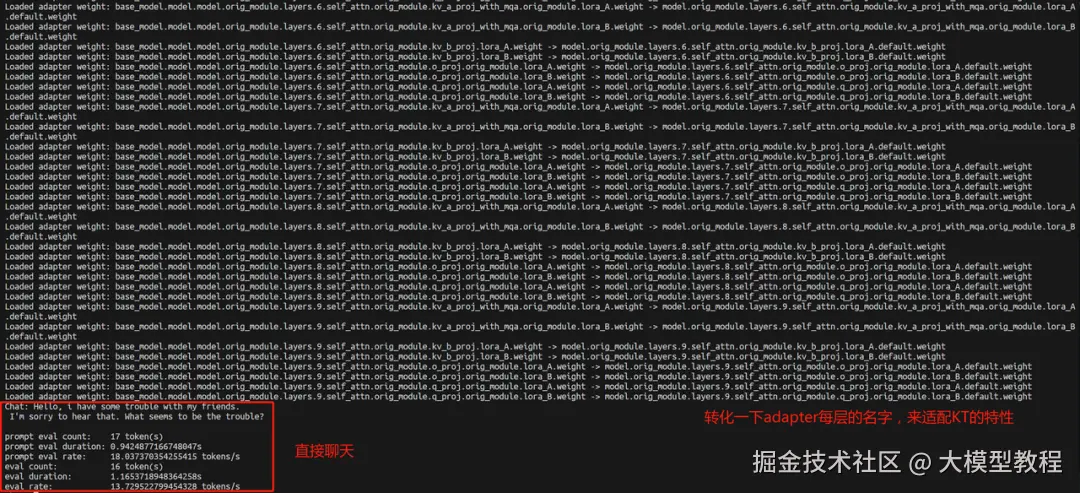
核心功能三:批量推理与指标评估(基础模型 + LoRA 适配器)
运行命令:
ini
API_PORT=8000 llamafactory-cli api examples/inference/deepseek3_lora_sft_kt.yaml调用经KTransformers微调的适配器来提供API;其他API的使用逻辑与原生LLaMA-Factory方式一致。
yaml
model_name_or_path: opensourcerelease/DeepSeek-V3-bf16
adapter_name_or_path: saves/Kllama_deepseekV3
template: deepseek
infer_backend: ktransformers # choices: [huggingface, vllm, sglang, ktransformers]
trust_remote_code: true
use_kt: true# use KTransformers as LoRA sft backend to inference
kt_optimize_rule: examples/kt_optimize_rules/DeepSeek-V3-Chat-sft-amx-multi-gpu.yaml
cpu_infer: 32
chunk_size: 819204 总结
KTransformers与LLaMA-Factory的这次联手,远不止是一次技术迭代,更是一次深刻的行业范式转移。这感觉就像,以前我们只能远远看着博物馆里的名画,后来终于能凑近看了,而现在,他们直接把画笔递到你手里,说:"来,照着你的想法改"。万亿模型,从此不再是巨头们的专属玩具,而是每个人手中的积木。接下来,就看我们怎么用它搭出下一个惊喜了。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。