键值缓存是生产环境中低级逻辑模型(LLM)高效推理的关键技术之一。键值缓存是实现高效计算的LLM推理的重要组成部分。本文将从概念和代码两个层面解释其工作原理,并提供一个从零开始编写的、易于理解的实现示例。
概述
简而言之,KV缓存存储中间的键值对(K)和值对(V)计算结果,以便在推理过程中(训练之后)重复使用,从而显著提高文本生成速度。KV缓存的缺点是会增加代码的复杂性,提高内存需求(这也是我最初没有将其纳入本书的主要原因),并且不能在训练过程中使用。然而,在生产环境中使用LLM时,推理速度的提升通常足以弥补代码复杂性和内存方面的不足。
什么是KV缓存?
假设 LLM 正在生成一些文本。具体来说,假设 LLM 收到以下提示:"时间"。您可能已经知道,LLM 一次生成一个单词(或标记),以下两个文本生成步骤可能如下图所示:

该图展示了 LLM 如何逐个生成文本标记。从提示"Time"开始,模型生成下一个标记"flies"。下一步,对完整的序列"Time flies"进行重新处理,生成标记"fast"。
请注意,生成的 LLM 文本输出中存在一些冗余,如下图所示:

该图突出显示了 LLM 在每个生成步骤中都必须重新处理的重复上下文("Time flies")。由于 LLM 不缓存中间键值状态,因此每次生成新标记(例如,"fast")时,它都会重新编码整个序列。
在实现大型语言模型(LLM)文本生成功能时,我们通常只使用每个步骤中最后生成的词元。然而,上面的可视化图突显了概念层面上的主要效率低下问题之一。如果我们放大观察注意力机制本身,这种效率低下(或冗余)会更加清晰。
下图展示了LLM核心注意力机制计算的一个片段。图中,输入词元("时间"和"苍蝇")被编码为三维向量(实际上,这些向量要大得多,但这样难以在一张小图中完整显示)。矩阵W是注意力机制的权重矩阵,负责将这些输入转换为键向量、值向量和查询向量。
下图显示了底层注意力分数计算过程的一部分,其中键向量和值向量已突出显示:
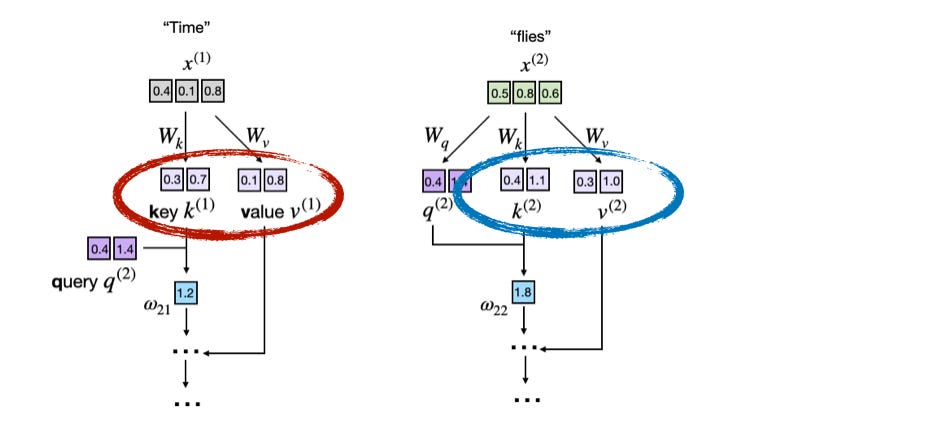
该图展示了LLM如何在注意力计算过程中从词嵌入中导出键向量(k)和值向量(v)。每个输入词元(例如,"时间"和"苍蝇")都使用学习到的矩阵进行投影W_k,W_v从而获得其对应的键向量和值向量。
如前所述,LLM 一次生成一个单词(或标记)。假设 LLM 生成了单词"fast",那么下一轮的提示就变成了"Time flies fast"。如下图所示:

此图展示了 LLM 在每个生成步骤中如何重新计算先前出现的词元("Time"和"flies")的键值向量。在生成第三个词元("fast")时,模型会再次重新计算相同的键值向量k(1)/v(1),k(2)/v(2)而不是重用它们。这种重复计算凸显了在自回归解码过程中不使用键值缓存的低效性。
通过比较前两幅图,我们可以看到前两个标记的键和值向量完全相同,在每一轮生成下一个标记文本时重新计算它们会造成浪费。
KV 缓存的思想是实现一种缓存机制,存储先前生成的键值向量以供重用,这有助于我们避免不必要的重复计算。
LLM如何生成文本(有无键值缓存)
在上一节回顾了基本概念之后,在查看具体代码实现之前,让我们更详细地了解一下。假设我们有一个没有键值缓存的文本生成过程,用于生成"时光飞逝"这句话,我们可以这样理解:
![]()
注意其中的冗余:标记"Time"和"flies"在每个新的生成步骤中都会重新计算。KV缓存通过存储和重用先前计算的键值向量来解决这种效率低下的问题:
-
首先,该模型计算并缓存输入标记的键值向量。
-
对于生成的每个新标记,该模型仅计算该特定标记的键向量和值向量。
-
从缓存中检索先前计算过的向量,以避免冗余计算。
下表总结了计算和缓存步骤及状态:

这样做的好处是,`key`"Time"计算一次,重复使用两次;`value`"flies"计算一次,重复使用一次。(为了简单起见,这里只举一个简短的文本示例,但应该很容易理解,文本越长,重复使用已计算的键值对的次数就越多,从而提高了生成速度。)
下图并排展示了有 KV 缓存和没有 KV 缓存的生成步骤 3。

比较使用和不使用键值缓存的文本生成过程。在上图(不使用缓存)中,每个词元步骤都会重新计算键值向量,导致冗余操作。在下图(使用缓存)中,从键值缓存中检索先前计算过的键值,避免重复计算,从而加快生成速度。
因此,如果我们想在代码中实现键值缓存,只需像往常一样计算键和值,然后将它们存储起来,以便在下一轮中检索即可。下一节将通过一个具体的代码示例来说明这一点。
从零开始实现键值缓存
实现 KV 缓存的方法有很多,其主要思想是,我们只计算每个生成步骤中新生成的标记的键和值张量。
我选择了一种更注重代码可读性的简洁方法。我觉得最简单的办法就是直接滚动浏览代码变更,看看它是如何实现的。
我在 GitHub 上分享了两个文件,它们是独立的 Python 脚本,分别从头开始实现了带 KV 缓存和不带 KV 缓存的 LLM:
-
gpt_ch04.py:这段独立代码取自我的*《从零开始构建大型语言模型》*一书的第3章和第4章,用于实现大型语言模型并运行简单的文本生成函数。
-
gpt_with_kv_cache.py:与上述相同,但进行了必要的更改以实现 KV 缓存。
要查看与 KV 缓存相关的代码修改,您可以:
a. 打开gpt_with_kv_cache.py文件,查找# NEW标记新更改的部分:

b. 使用你选择的文件差异比较工具查看这两个代码文件,比较它们的更改:

此外,为了总结实现细节,以下小节中有一个简短的概述。
1. 注册缓存缓冲区
在构造函数内部MultiHeadAttention,我们添加了两个非持久缓冲区,cache_k它们cache_v将保存跨步骤连接的键和值:
`self.register_buffer("cache_k", None, persistent=False)
self.register_buffer("cache_v", None, persistent=False)`2. 带旗 向前传球 use_cache
接下来,我们扩展forward该类的方法MultiHeadAttention,使其接受一个use_cache参数:
`def forward(self, x, use_cache=False):
b, num_tokens, d_in = x.shape
keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)
values_new = self.W_value(x)
queries = self.W_query(x)
#...
if use_cache:
if self.cache_k is None:
self.cache_k, self.cache_v = keys_new, values_new
else:
self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)
self.cache_v = torch.cat([self.cache_v, values_new], dim=1)
keys, values = self.cache_k, self.cache_v
else:
keys, values = keys_new, values_new`这里对键和值的存储和检索实现了 KV 缓存的核心思想。
存储
具体来说,在通过 if 初始化缓存之后,我们分别通过和self.cache_k is None: ...将新生成的键和值添加到缓存中。self.cache_k = torch.cat(...)``self.cache_v = torch.cat(...)
检索
然后,keys, values = self.cache_k, self.cache_v从缓存中检索存储的值和键。
以上就是键值缓存的核心存储和检索机制。接下来的第3节和第4节将介绍一些次要的实现细节。
3. 清除缓存
生成文本时,我们必须记住在两次独立的文本生成调用之间重置键缓冲区和值缓冲区。否则,新提示的查询将使用前一个序列遗留的过期键,导致模型依赖无关上下文并产生不连贯的输出。为了防止这种情况,我们reset_kv_cache在类中添加了一个方法MultiHeadAttention,以便在后续的文本生成调用之间使用:
`def reset_cache(self):
self.cache_k, self.cache_v = None, None`4.在完整模型中 传播 use_cache
类更改MultiHeadAttention完成后,我们现在GPTModel对类进行修改。首先,我们为教师添加标记索引的位置跟踪:
`self.current_pos = 0`这是一个简单的计数器,用于记住模型在增量生成会话期间已经缓存了多少个令牌。
然后,我们将单行代码块调用替换为显式循环,遍历use_cache每个转换器代码块:
`def forward(self, in_idx, use_cache=False):
# ...
if use_cache:
pos_ids = torch.arange(
self.current_pos, self.current_pos + seq_len,
device=in_idx.device, dtype=torch.long
)
self.current_pos += seq_len
else:
pos_ids = torch.arange(
0, seq_len, device=in_idx.device, dtype=torch.long
)
pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)
x = tok_embeds + pos_embeds
# ...
for blk in self.trf_blocks:
x = blk(x, use_cache=use_cache)`如果我们进行上述设置use_cache=True,就会从某个点开始self.current_pos计数seq_len。然后,递增计数器,以便下一次解码调用从上次中断的地方继续。
之所以要进行self.current_pos跟踪,是因为新的查询必须紧跟在已存储的键值对之后。如果不使用计数器,每个新步骤都会从位置 0 重新开始,因此模型会将新标记视为与之前的标记重叠。(或者,我们也可以通过其他方式进行跟踪offset = block.att.cache_k.shape[1]。)
上述更改还需要对TransformerBlock类进行一些小的修改,使其能够接受该use_cache参数:
`def forward(self, x, use_cache=False):
# ...
self.att(x, use_cache=use_cache)`最后,为了方便起见,我们添加了一个模型级重置,以便GPTModel一次性清除所有块缓存:
`def reset_kv_cache(self):
for blk in self.trf_blocks:
blk.att.reset_cache()
self.current_pos = 0`5. 在生成过程中使用缓存
GPTModel对、TransformerBlock和进行更改后MultiHeadAttention,最后,以下是我们在简单的文本生成函数中使用 KV 缓存的方法:
`def generate_text_simple_cached(
model, idx, max_new_tokens, use_cache=True
):
model.eval()
ctx_len = model.pos_emb.num_embeddings # max sup. len., e.g. 1024
if use_cache:
# Init cache with full prompt
model.reset_kv_cache()
with torch.no_grad():
logits = model(idx[:, -ctx_len:], use_cache=True)
for _ in range(max_new_tokens):
# a) pick the token with the highest log-probability
next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)
# b) append it to the running sequence
idx = torch.cat([idx, next_idx], dim=1)
# c) feed model only the new token
with torch.no_grad():
logits = model(next_idx, use_cache=True)
else:
for _ in range(max_new_tokens):
with torch.no_grad():
logits = model(idx[:, -ctx_len:], use_cache=False)
next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)
idx = torch.cat([idx, next_idx], dim=1)
return idx`请注意,我们仅通过 c) 中的新 token 将模型传递给它logits = model(next_idx, use_cache=True)。由于没有缓存,我们将整个输入传递给模型logits = model(idx[:, -ctx_len:], use_cache=False),因为它没有存储的键和值可以重用。
简单的性能比较
在概念层面了解了键值缓存之后,关键问题是它在实际应用中,尤其是在一个小例子中,性能究竟如何。为了测试其实现,我们可以将前面提到的两个代码文件作为 Python 脚本运行,这将运行一个包含 124M 参数的小型 LLM 来生成 200 个新 token(初始提示为 4 个 token 的"Hello, I am"):
`pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/requirements.txt
python gpt_ch04.py
python gpt_with_kv_cache.py`在配备 M4 芯片(CPU)的 Mac Mini 上,结果如下:

因此,正如我们所见,即使使用一个参数量仅为 1.24 亿的小型模型和一个长度仅为 200 个标记的短序列,我们也能获得约 5 倍的加速。(请注意,此实现针对代码可读性进行了优化,而非针对 CUDA 或 MPS 运行时速度进行了优化,后者需要预先分配张量,而不是重新加载并连接它们。)
**注意:**该模型在这两种情况下都会生成"乱码",即看起来像这样的文本:
输出文本:你好,我是 Featureiman Byeswickattribute argument logger Normandy Compton analogous bore ITVEGIN ministriesysics Kle functional recountrictionchangingVirgin embarrassedgl ...
这是因为我们还没有训练模型。下一章会训练模型,你可以使用训练好的模型的键值缓存(但是,键值缓存仅用于推理阶段)来生成连贯的文本。这里我们使用未经训练的模型是为了简化代码。
更重要的是,两种实现gpt_ch04.py方式gpt_with_kv_cache.py生成的文本完全相同。这说明键值缓存的实现是正确的------索引错误很容易导致结果不一致。
KV缓存的优点和缺点
随着序列长度的增加,KV缓存的优点和缺点在以下几个方面变得更加明显:
-
【优点】计算效率提升:如果没有缓存,步骤 t 的注意力机制必须将新查询与之前的t 个键进行比较,因此累积工作量呈二次方增长,即 O(n²)。使用缓存后,每个键和值只需计算一次即可重复使用,从而将每步的总复杂度降低到线性,即 O(n)。
-
【缺点】内存使用量线性增长:每个新标记都会添加到键值缓存中。对于长序列和大型 LLM,累积的键值缓存会不断增大,这可能会消耗大量甚至超出其容量限制的(GPU)内存。作为一种变通方法,我们可以截断键值缓存,但这会增加复杂性(不过,在部署 LLM 时,这样做可能非常值得)。
优化 KV 缓存实现
虽然我上面对 KV 缓存的概念性实现有助于提高清晰度,并且主要面向代码可读性和教育目的,但在实际场景中部署它(尤其是在模型更大、序列长度更长的情况下)需要更仔细的优化。
扩展缓存时常见的陷阱
-
内存碎片化和重复分配 :
torch.cat如前所述,通过连续连接张量会导致频繁的内存分配和重新分配,从而造成性能瓶颈。 -
内存使用量的线性增长:如果没有适当的处理,KV 缓存大小对于非常长的序列将变得不切实际。
技巧 1:预先分配内存
与其重复连接张量,我们可以根据预期的最大序列长度预先分配一个足够大的张量。这可以确保内存使用的一致性并减少开销。伪代码如下所示:
`# Example pre-allocation for keys and values
max_seq_len = 1024 # maximum expected sequence length
cache_k = torch.zeros(
(batch_size, num_heads, max_seq_len, head_dim), device=device
)
cache_v = torch.zeros(
(batch_size, num_heads, max_seq_len, head_dim), device=device
)`在推理过程中,我们可以直接将数据写入这些预先分配的张量的切片中。
技巧 2:通过滑动窗口截断缓存
为了避免耗尽GPU内存,我们可以采用动态截断的滑动窗口方法。通过滑动窗口,我们只window_size在缓存中保留最后的几个标记:
`# Sliding window cache implementation
window_size = 512
cache_k = cache_k[:, :, -window_size:, :]
cache_v = cache_v[:, :, -window_size:, :]`实践中的优化
您可以在gpt_with_kv_cache_optimized.py文件中找到这些优化。
在配备 M4 芯片(CPU)的 Mac Mini 上,生成 200 个标记,窗口大小等于 LLM 的上下文长度(以保证结果相同,从而进行公平比较),以下代码运行时间比较如下:

遗憾的是,由于 CUDA 设备是小型设备,速度优势在 CUDA 设备上消失了,设备传输和通信超过了 KV 缓存对这种小型设备的好处。
结论
虽然缓存会引入额外的复杂性和内存方面的考虑,但效率的显著提升通常会超过这些权衡取舍,尤其是在生产环境中。
请记住,虽然我在这里优先考虑的是代码的清晰度和可读性而非效率,但关键在于,实际应用中往往需要周全的优化,例如预先分配内存或应用滑动窗口缓存来有效管理内存增长。从这个意义上讲,我希望这篇文章对大家有所帮助。
欢迎尝试这些技巧,祝您编程愉快!
奖励:Qwen3 和 Llama 3 中的 KV 缓存
在为我从零开始实现的 Qwen3 (0.6 B) 和 Llama 3 (1 B) 添加 KV 缓存后,我进行了额外的实验,比较了启用和禁用 KV 缓存的模型运行时间。需要注意的是,我选择了上文提到的 torch.cat 方法,而不是像*"优化 KV 缓存实现"*部分所述那样预先分配 KV 缓存张量。由于 Llama 3 和 Qwen3 支持的上下文大小非常大(分别为 131k 和 41k 个 token),预先分配的张量会消耗约 8 GB 的额外内存,这相当昂贵。
此外,由于我采用了更节省内存的torch.cat方式来动态创建张量,我将 KV 缓存移到了模型之外,以便编译模型,torch.compile从而提高计算效率。
代码可以在这里找到:
演出内容如下所示。


正如我们所见,在 CPU 上,KV 缓存带来的加速效果最为显著。编译还能进一步提升性能。然而,在 GPU 上,常规编译模型即可实现最佳性能,这可能是因为我们没有在 GPU 上预先分配张量,而且模型相对较小。