前面的文章已完成hadoop+Zookeeper配置,未完成的可参考前面文章。
|---------|--------------|-----------------------------|
| 节点 | Hbase角色 | 已部署角色(Hadoop/ZK) |
| master | HMaster | NameNode+DataNode+Zookeeper |
| slave01 | RegionServer | DataNode+Zookeeper |
| slave02 | RegionServer | SNN+DataNode+Zookeeper |
一、下载并解压文件
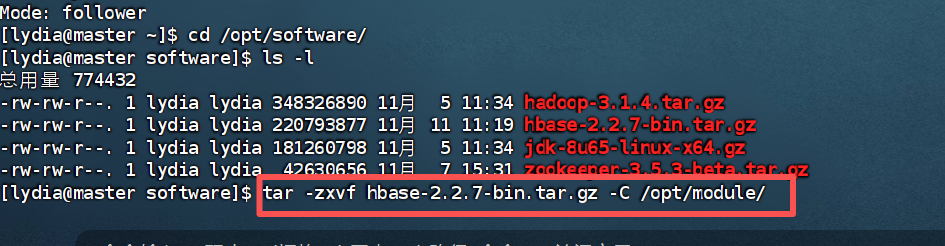
本次我们所需版本为hbase-2.2.7.下载上传到/opt/software。解压到/opt/module目录下。
二、环境变量配置
编辑/etc/profile.d/my_ens.sh文件插入

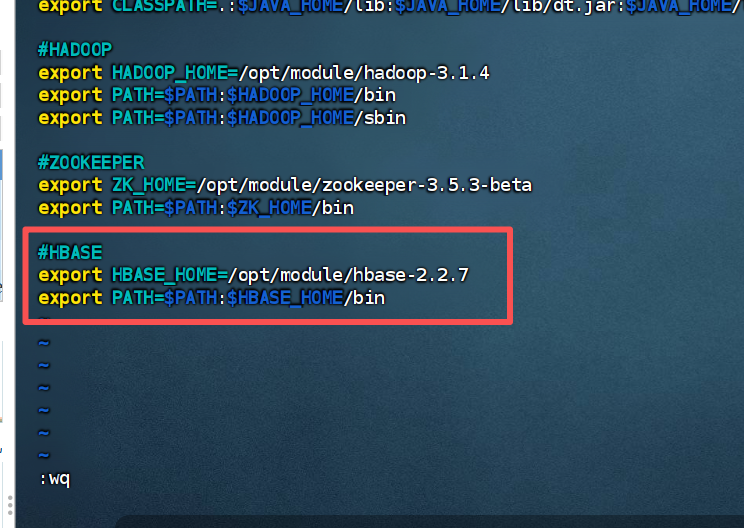
记得远程同步到其他节点。
三、核心配置文件修改
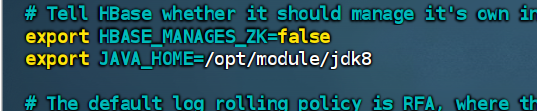
1.修改hbase-env.sh。导入安装的jdk,以及禁用内置zookeeper.
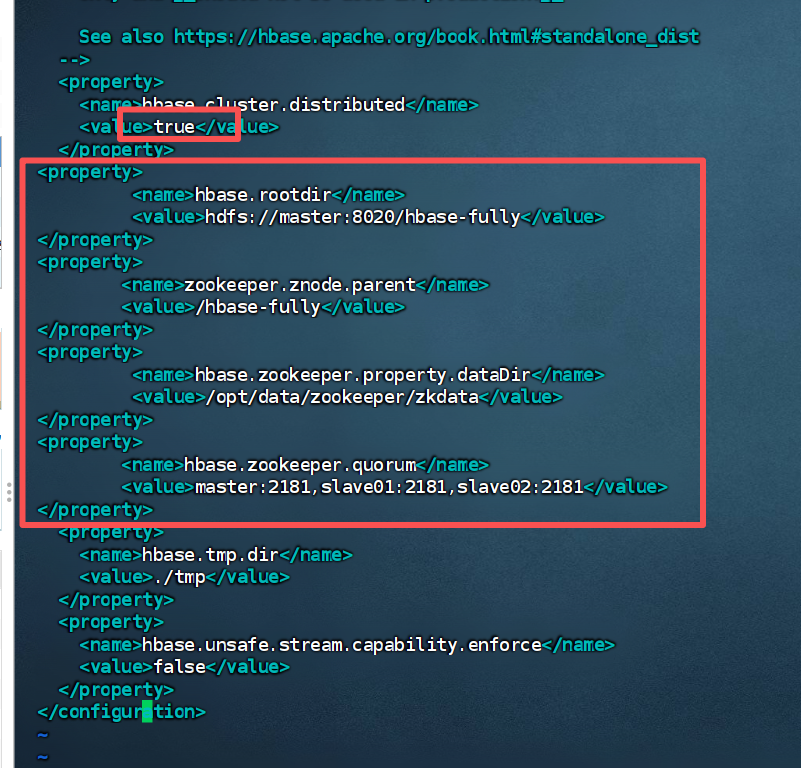
2.修改hbase-site.xml文件
 3.修改regionservers文件
3.修改regionservers文件

4.远程同步文件

四、启动集群
前提:启动Hadoop集群、Zookeeper.
在master节点启动集群:
 查看进程:
查看进程:
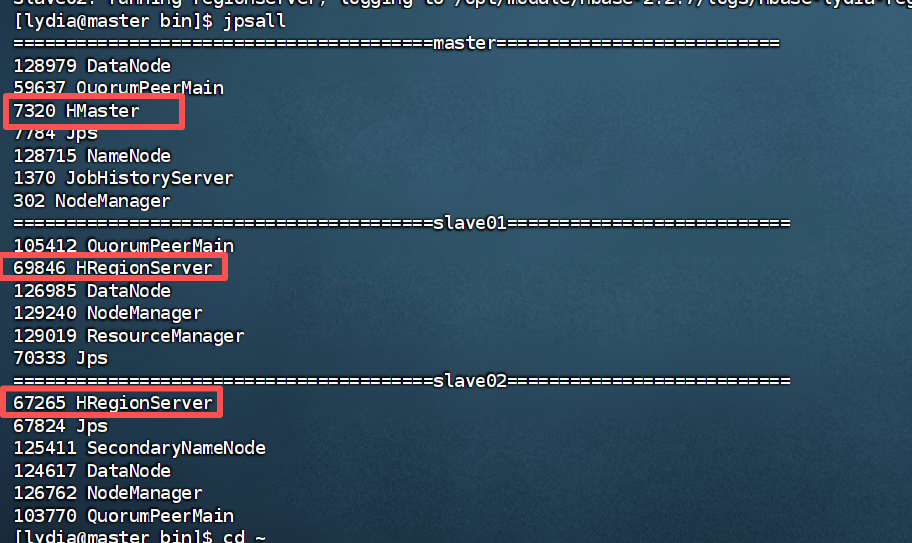
五、常见问题排查(快速避坑)
HMaster 启动后秒退:
检查 hbase-site.xml 中 hbase.rootdir 的 HDFS 路径是否正确(NameNode 主机名 / 端口是否通);
查看日志:/opt/module/hbase-2.2.7/logs/hbase-xxx-master-node1.log,重点看 ZK 连接失败(如 hbase.zookeeper.quorum 配置错误)。
RegionServer 启动失败:
检查所有节点的 HBase 配置文件一致(未分发配置会导致报错);
确认 ZK 集群正常(zkServer.sh status 查看所有节点角色,有 Leader/Follower)。
报 UnsupportedFileSystemException:
把 hbase.unsafe.stream.capability.enforce 设为 false,重启 HBase。
总结:
完全分布式核心是 "关联 Hadoop 存储 + 对接外部 ZK + 指定 RegionServer 节点",全程只需配置 3 个文件,依赖已部署的 Hadoop/ZK 时,无需额外复杂操作。启动后通过 Web 界面或 hbase shell 快速验证,遇到报错优先看日志和前置服务状态~