上一篇拆解了Redis单线程高并发的底层逻辑------靠I/O多路复用和高效优化实现10万+QPS。但生产环境中,"快"只是基础,"数据不丢、不出错"才是底线。面试官常追问:"Redis宕机后数据会丢吗?"、"如何保证命令执行的原子性?"、"Redis事务和MySQL事务有什么区别?"
本文将聚焦Redis数据安全的3大核心机制:原子性、持久化(RDB+AOF)、事务,从底层原理、实战配置、面试坑点三个维度彻底讲透,帮你轻松应对中大厂面试。
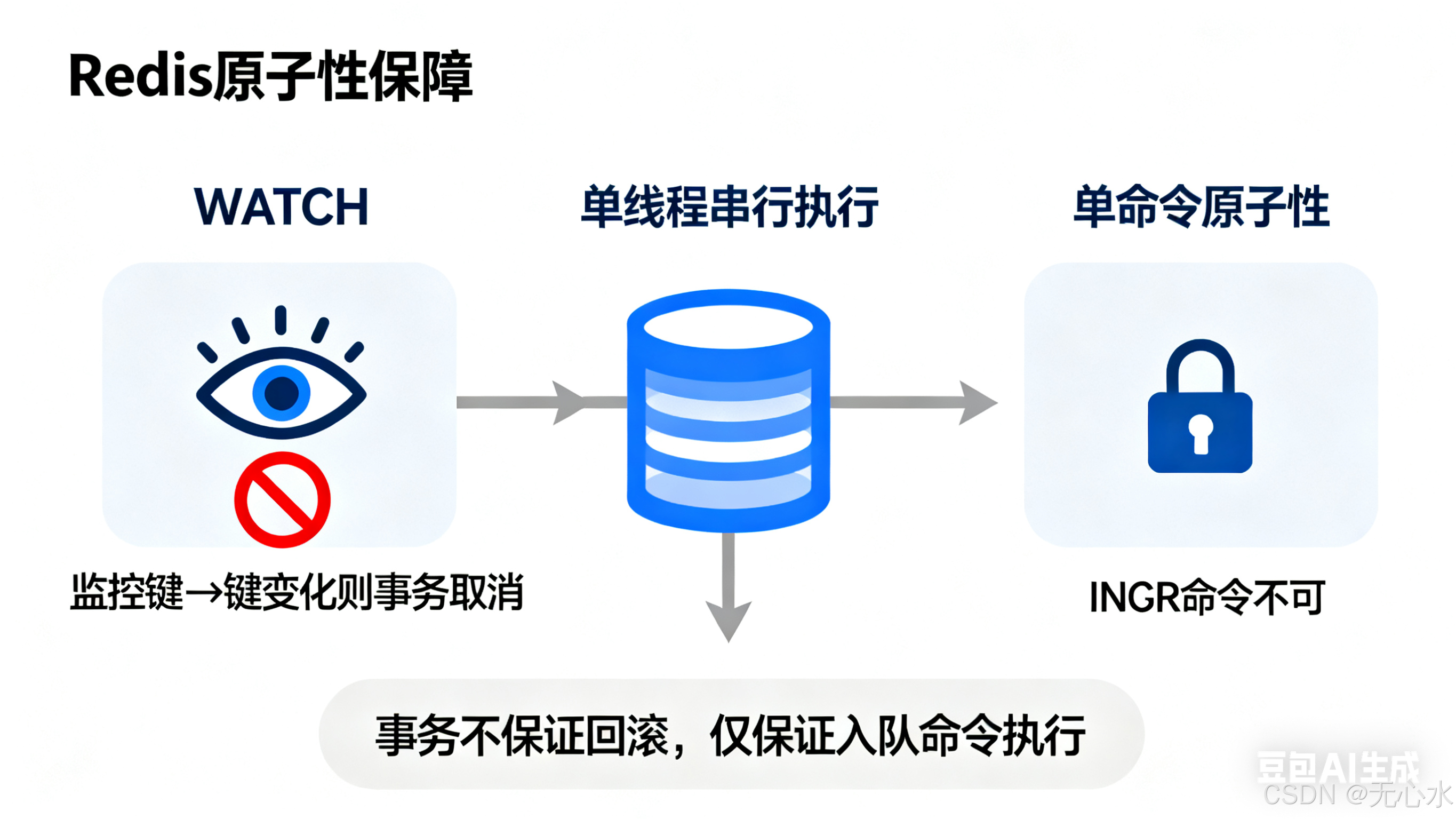
一、核心结论(面试必背)
Redis的数据安全靠"三层防护"层层递进,缺一不可:
- 原子性:单线程串行执行,保证单个命令"不可分割";
- 持久化:RDB(快照)+AOF(日志),将内存数据落地磁盘,宕机可恢复;
- 事务:批量命令打包执行,保证顺序性不被其他命令打断(非严格ACID事务)。
三者的关系:原子性是"内存中数据一致性"的基础,持久化是"宕机不丢数据"的保障,事务是"批量操作顺序性"的补充。
二、第一层防护:原子性------单线程的"天然优势"
原子性是Redis数据安全的核心前提,也是面试高频基础题。很多人误以为"Redis所有操作都是原子的",这其实是误区,需要精准区分。
1. 什么是Redis的原子性?
定义:单个Redis命令的执行过程(读→计算→写)不会被任何其他命令打断 ,要么完全执行,要么完全不执行。
示例:执行INCR count(count初始值100),流程是"读取100→加1→写回101",中间不会插入其他客户端的命令,最终结果一定是101,不会出现"100→101"过程中被其他INCR插入导致结果为101(而非102)的情况。
2. 为什么单线程能保证原子性?
Redis的核心命令执行流程是"单线程串行处理":
- 所有客户端发送的命令会被放入FIFO命令队列;
- 主线程从队列中逐个取出命令执行,执行完一个再取下一个;
- 不存在"多线程并行执行命令"的情况,自然不会有"命令打断"或"数据竞争"。
对比多线程:若两个线程同时执行INCR count,可能出现"线程A读100→线程B读100→A写101→B写101"的情况,最终结果少加1------单线程完全规避了这种问题。
3. 面试误区:"复合操作"不具备原子性
单个命令是原子的,但多个命令的组合(复合操作)不具备原子性 。
示例(非原子操作):
bash
# 步骤1:读取count值(假设为100)
GET count
# 步骤2:业务逻辑计算(count+1=101)
# 步骤3:写回新值
SET count 101问题:步骤1和步骤3之间,可能有其他客户端执行INCR count,导致最终结果错误(比如变成102而非101)。
4. 复合操作的原子性解决方案(实战必备)
面试常问"如何保证Redis复合操作的原子性",核心有2种方案:
- 方案1:Redis事务(
MULTI/EXEC):将复合操作打包成事务,顺序执行不被打断(下文详细拆解); - 方案2:Lua脚本:Redis会将整个Lua脚本当作"单个命令"执行,天然原子性(推荐,性能更优)。
Lua脚本示例(实现"先查后改"的原子操作):
lua
-- 脚本功能:只有当count < 100时,才执行INCR
local current = redis.call('GET', 'count')
if current and tonumber(current) < 100 then
return redis.call('INCR', 'count')
else
return 0 -- 不满足条件,返回0
end执行命令:
bash
redis-cli eval "local current = redis.call('GET', 'count') if current and tonumber(current) < 100 then return redis.call('INCR', 'count') else return 0 end" 0三、第二层防护:持久化机制------宕机不丢数据的"核心保障"
单线程保证了内存中数据的一致性,但服务器断电、崩溃时,内存数据会全部丢失。Redis的持久化机制就是"将内存数据写入磁盘",分为RDB和AOF两种方案,生产环境通常混合使用。
1. RDB(快照持久化):给数据"拍张照"
RDB是Redis默认的持久化方案,核心是"定期将内存中所有数据生成二进制快照,写入dump.rdb文件"。
(1)底层原理与触发方式
- 原理 :通过
fork()系统调用创建子进程,子进程负责生成快照,主线程继续处理客户端请求------基于"写时复制(COW)"机制,子进程读取内存数据时,主线程修改数据会复制一份副本,不影响快照完整性。 - 触发方式 :
-
自动触发:在
redis.conf中配置触发条件(如"3600秒内有1次写操作"):confsave 3600 1 # 1小时内1次写操作触发 save 300 10 # 5分钟内10次写操作触发 save 60 10000 # 1分钟内1万次写操作触发 -
手动触发:执行
BGSAVE(异步,不阻塞主线程)或SAVE(同步,阻塞主线程,不推荐)。
-
(2)优缺点与适用场景
| 优点 | 缺点 | 适用场景 |
|---|---|---|
| 文件体积小(二进制压缩) | 可能丢失最后一次快照后的新数据 | 追求性能、可接受少量数据丢失的场景 |
| 恢复速度快(直接加载内存) | 快照生成时,fork子进程会占用额外内存 | 数据备份、主从复制的全量同步 |
(3)面试坑点:BGSAVE会阻塞主线程吗?
不会。BGSAVE通过fork子进程生成快照,主线程仅在fork瞬间阻塞(微秒级),后续不影响命令执行;而SAVE会让主线程全程阻塞,直到快照生成完成(秒级/分钟级),生产环境严禁使用。
2. AOF(追加文件持久化):给数据"写日记"
AOF是"日志型"持久化方案,核心是"将所有写命令(SET/DEL/HSET等)按顺序追加到appendonly.aof文件",宕机后通过"重新执行日志中的命令"恢复数据。
(1)核心配置与刷盘策略(面试必问)
AOF的关键是"刷盘策略"------控制命令写入磁盘的时机,平衡数据安全性和性能:
conf
appendonly yes # 开启AOF(默认关闭)
appendfsync everysec # 刷盘策略(推荐)刷盘策略对比:
| 策略 | 实现逻辑 | 数据安全性 | 性能影响 |
|---|---|---|---|
always |
每写一条命令就刷盘 | 最高(不丢数据) | 最低(频繁磁盘I/O) |
everysec |
每秒刷盘一次 | 较高(最多丢1秒数据) | 均衡(推荐生产环境使用) |
no |
由操作系统决定刷盘时机(通常30秒) | 最低(可能丢大量数据) | 最高(减少磁盘I/O) |
(2)AOF重写:解决文件过大问题
AOF文件会随着命令增多越来越大(比如多次INCR count会记录多条命令),导致恢复速度变慢。Redis通过"重写"机制优化:
- 原理 :遍历内存中的当前数据,生成"一条命令对应一个数据状态"的精简日志(如
INCR count 10替代10条INCR count),替换原有冗余日志。 - 触发方式 :
-
自动触发:
redis.conf配置(如"AOF文件比上次重写后增大100%,且文件大小超过64MB"):confauto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb -
手动触发:执行
BGREWRITEAOF(异步,不阻塞主线程)。
-
(3)优缺点与适用场景
| 优点 | 缺点 | 适用场景 |
|---|---|---|
| 数据安全性高(最多丢1秒) | 文件体积大(文本命令) | 追求数据安全、不接受大量丢失的场景 |
| 日志可手动修改(恢复灵活) | 恢复速度慢(需重新执行命令) | 核心业务数据、金融类场景 |
3. 混合持久化(Redis 4.0+):RDB+AOF的结合体
混合持久化是Redis 4.0引入的优化方案,解决了"RDB丢数据多"和"AOF恢复慢"的问题:
- 原理:AOF文件中包含"RDB快照(前半部分)+ 增量命令日志(后半部分)";
- 配置 :
aof-use-rdb-preamble yes(默认开启); - 恢复流程:先加载RDB快照(快速恢复大部分数据),再执行增量AOF命令(恢复快照后的新数据);
- 优势:兼顾RDB的"恢复快"和AOF的"数据安全",是生产环境的最优选择。
4. 生产环境持久化配置示例
conf
# 开启混合持久化
appendonly yes
appendfsync everysec
aof-use-rdb-preamble yes
# RDB配置(作为备份和主从同步)
save 3600 1
save 300 10
save 60 10000
# AOF重写配置
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb四、第三层防护:事务机制------批量命令的"顺序执行保障"
Redis事务的核心是"将多个命令打包,一次性顺序执行,中间不插入其他客户端的命令"------但它不是严格意义上的ACID事务,这是面试的核心考点。
1. 事务的基本流程(3步走)
bash
# 1. 标记事务开始
MULTI
# 2. 命令入队(不执行)
HGET user:1 balance
HSET user:1 balance 90
# 3. 批量执行所有入队命令
EXEC- 执行
MULTI后,后续命令会被放入"事务队列",返回QUEUED; - 执行
EXEC后,队列中的命令会按顺序执行,返回每个命令的结果。
2. 核心特性(与MySQL事务的区别,面试必问)
Redis事务与MySQL事务的核心差异在于"不支持回滚"和"弱隔离性":
| 事务特性 | Redis事务 | MySQL事务(InnoDB) |
|---|---|---|
| 原子性 | 顺序执行,语法错则全不执行,执行错则继续 | 要么全执行,要么全回滚(支持ROLLBACK) |
| 一致性 | 单线程环境下保证一致性 | 支持ACID一致性 |
| 隔离性 | 串行执行,天然隔离(无并发冲突) | 支持4种隔离级别(默认RR) |
| 持久性 | 依赖持久化机制(RDB/AOF) | 依赖事务日志(redo/undo log) |
3. 关键坑点:Redis事务不支持回滚
- 若事务队列中存在"语法错误"(如
HSET少传参数),EXEC会拒绝执行所有命令; - 若事务队列中存在"执行时错误"(如对字符串执行
LPUSH),错误命令会失败,其他命令仍会继续执行,不会回滚。
示例(执行时错误):
bash
MULTI
SET key1 "hello"
LPUSH key1 123 # 对字符串执行列表命令,执行时错误
SET key2 "world"
EXEC结果:key1仍为hello,key2被设置为world------错误命令不影响其他命令执行。
4. 事务的适用场景
Redis事务适合"需要批量执行命令,且无需回滚"的场景,比如:
- 秒杀库存扣减(先查库存→再扣减→再记录日志);
- 批量更新用户信息(同时修改多个字段)。
若需要"严格原子性+回滚",建议用Lua脚本或分布式事务框架(如Seata)。
五、辅助保障:避免数据"异常"的细节设计
除了三大核心机制,Redis还有两个细节设计,保证数据长期稳定:
1. 过期键删除策略(避免内存泄漏)
Redis的过期键删除采用"惰性删除+定期删除"的组合策略,避免单线程阻塞:
- 惰性删除:访问键时才检查是否过期,过期则删除(不浪费CPU资源);
- 定期删除:每隔100ms,单线程花几毫秒扫描部分过期键并删除(避免过期键长期占用内存)。
2. 哈希表渐进式rehash(避免扩容阻塞)
哈希表扩容时,若一次性迁移所有数据,会阻塞单线程。Redis采用"渐进式rehash":
- 分多次迁移数据(每次处理几个键);
- 迁移期间,新旧哈希表同时存在,查询时先查新表再查旧表;
- 不影响命令执行,避免单线程阻塞。
六、面试高频题&标准答案
-
问:如何保证Redis数据不丢失?
答:开启"混合持久化(RDB+AOF)",AOF刷盘策略设为
everysec(最多丢1秒数据),RDB定期生成快照作为备份,同时部署主从复制(从库备份)。 -
问:RDB和AOF的区别是什么?生产环境选哪种?
答:RDB优点是文件小、恢复快,缺点是丢数据多;AOF优点是数据安全,缺点是文件大、恢复慢。生产环境选"混合持久化",兼顾两者优势。
-
问:Redis事务为什么不支持回滚?
答:Redis设计者认为,执行时错误多是"编程错误"(如用错命令),应在开发阶段解决;支持回滚会增加代码复杂度和性能损耗,不符合Redis"高效"的设计理念。
-
问:AOF文件损坏了怎么办?
答:用Redis自带的
redis-check-aof工具修复:redis-check-aof --fix appendonly.aof,修复后重启Redis加载文件。 -
问:Lua脚本为什么能保证原子性?
答:Redis会将整个Lua脚本当作"单个命令"执行,放入命令队列中,串行执行且不被其他命令打断,天然具备原子性。
七、总结与下一篇预告
Redis的数据安全机制围绕"单线程模型"展开:
- 原子性靠"单线程串行"实现,是基础;
- 持久化靠"RDB+AOF+混合持久化"落地,是核心;
- 事务靠"命令入队+批量执行"补充,解决批量操作顺序性问题。
理解这些机制,就能应对"数据安全"相关的所有面试题。
下一篇将聚焦Redis实战场景------缓存穿透、缓存击穿、缓存雪崩的解决方案(含代码实现),以及分布式锁的落地细节,都是中大厂面试的"实战加分项",敬请关注。
如果觉得本文有用,欢迎收藏+转发,后续会持续更新Redis面试核心系列,帮你系统攻克Redis考点~