
前言部分(本文内容较长,观看时间约为20-30分钟)
Hello-Agents 教程学习链接
github地址:https://github.com/datawhalechina/hello-agents
cookbook版本:https://book.heterocat.com.cn/
特别感谢本教程各位开源贡献者及文睿的支持
一、语言模型与 Transformer 架构
在本节开始之前,对数学基础进行一个复习
ANN
人工神经网络(Artificial Neural Network ANN)作为机器学习的一个部分,是一种模仿生物神经网络的结构和功能的计算模型,它通过大量的简单处理单元(人工神经元)相互连接来实现信息处理和学习
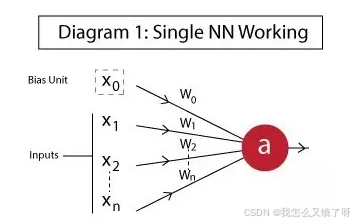
前向传播的数学本质:

反向传播核心公式:

python
import torch
import torch.nn as nn
import torch.optim as optim
# 1. 数据(输入和目标)
X = torch.tensor([[1.0]]) # 输入
y_true = torch.tensor([[0.7]]) # 目标输出
# 2. 定义简单的神经网络
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.linear = nn.Linear(1, 1) # 一层线性层:y = w*x + b
self.sigmoid = nn.Sigmoid()
def forward(self, x):
z = self.linear(x)
a = self.sigmoid(z)
return a
# 3. 实例化模型、损失函数、优化器
model = SimpleNet()
criterion = nn.MSELoss() # 使用均方误差损失
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 4. 训练循环
for epoch in range(100):
model.zero_grad() # 清零梯度
output = model(X) # 前向传播
loss = criterion(output, y_true) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 打印每10轮的结果
if epoch % 10 == 0:
print(f"Epoch {epoch}, Loss: {loss.item():.4f}")
for name, param in model.named_parameters():
if param.grad is not None:
print(f" dL/d{name}: {param.grad.item():.4f}")
# 5. 查看最终参数
print("\nFinal parameters:")
for name, param in model.named_parameters():
print(f"{name}: {param.item():.4f}")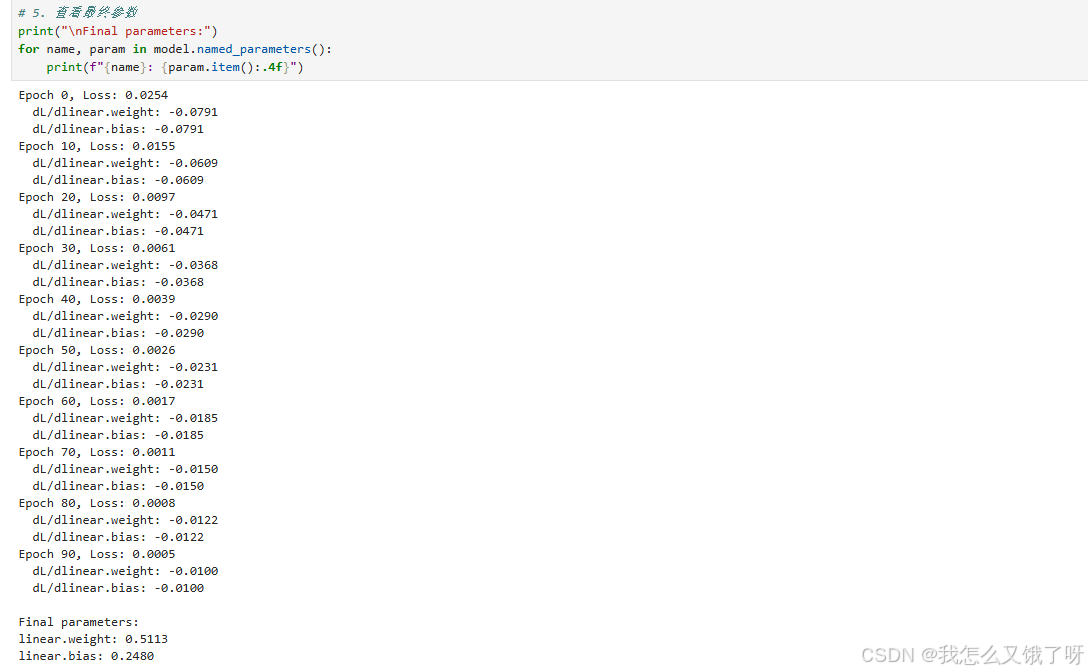
CNN
卷积神经网络(CNN)是一种专为处理具有类似网格结构的数据(如图像、音频、时序信号)而设计的深度神经网络。其核心思想是通过卷积操作自动提取局部特征,实现空间不变性和参数高效性。
主要结构:
- 卷积层(Convolutional Layer):通过卷积核(filter/kernel)滑动提取局部特征。
- 激活层(Activation Layer):常用ReLU等非线性函数。
- 池化层(Pooling Layer):如最大池化(Max Pooling)、平均池化(Average Pooling),实现下采样和特征压缩。
- 全连接层(Fully Connected Layer, FC):用于整合高层语义特征,输出分类或回归结果。
前向传播(conv2d + bias)
python
import numpy as np
def im2col(x, kH, kW, stride=1):
"""把 (H,W) 转成 (kH*kW, oH*oW) 的列矩阵"""
H, W = x.shape
oH = (H - kH) // stride + 1
oW = (W - kW) // stride + 1
cols = np.zeros((kH*kW, oH*oW))
for i in range(oH):
for j in range(oW):
cols[:, i*oW+j] = x[i*stride:i*stride+kH,
j*stride:j*stride+kW].ravel()
return cols
def col2im(cols, x_shape, kH, kW, stride=1):
"""梯度回传时把列矩阵还原成 (H,W)"""
H, W = x_shape
oH = (H - kH) // stride + 1
oW = (W - kW) // stride + 1
dx = np.zeros(x_shape)
for i in range(oH):
for j in range(oW):
patch = cols[:, i*oW+j].reshape(kH, kW)
dx[i*stride:i*stride+kH, j*stride:j*stride+kW] += patch
return dx前向
python
X = np.array([[1,2,1,0],
[0,1,2,1],
[2,1,0,2],
[0,2,1,1]], dtype=float)
K = np.array([[1,-1,0],
[0,1,-1],
[-1,0,1]], dtype=float)
b = 0.1
cols = im2col(X, 3, 3) # shape (9, 4)
kvec = K.reshape(-1) # (9,)
Yhat = kvec @ cols + b # (4,) 对应 2×2 展平
Yhat = Yhat.reshape(2, 2)
print("Ŷ =\n", Yhat)反向传播推导
python
Y_true = np.array([[0,1],[1,0]], dtype=float)
delta = Yhat - Y_true # (2,2)
# 核梯度
dK = np.zeros_like(K)
for i in range(2):
for j in range(2):
patch = X[i:i+3, j:j+3]
dK += delta[i, j] * patch
db = delta.sum()
K_rot = np.rot90(K, 2) # 180° 旋转
pad_delta = np.pad(delta, 2, mode='constant') # 四周补零到 4×4
dX = np.zeros_like(X)
for i in range(4):
for j in range(4):
# 取与核大小匹配的 patch
patch = pad_delta[i:i+3, j:j+3]
dX[i, j] = np.sum(patch * K_rot)自动微分验证(PyTorch)
python
import torch
X_t = torch.tensor(X, requires_grad=True)
K_t = torch.tensor(K, requires_grad=True)
b_t = torch.tensor(b, requires_grad=True)
Yhat_t = torch.nn.functional.conv2d(
X_t.unsqueeze(0).unsqueeze(0),
K_t.unsqueeze(0).unsqueeze(0),
b_t, padding=0).squeeze()
loss = ((Yhat_t - torch.tensor(Y_true))**2 / 2).sum()
loss.backward()
print("PyTorch dK\n", K_t.grad)
print("PyTorch db\n", b_t.grad)
print("PyTorch dX\n", X_t.grad)
python
# main.py这是完整代码
import torch, torch.nn as nn, torch.optim as optim
import torchvision, torchvision.transforms as T
import os, argparse, time
# ---------- 1. 命令行参数 ----------
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--epochs', type=int, default=10)
parser.add_argument('--lr', type=float, default=1e-3)
parser.add_argument('--batch_size', type=int, default=128)
parser.add_argument('--ckpt', type=str, default='ckpt.pth')
parser.add_argument('--resume', action='store_true')
return parser.parse_args()
args = get_args()
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('device:', device)
# ---------- 2. 数据 ----------
mean, std = (0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)
transform_train = T.Compose([
T.RandomCrop(32, padding=4),
T.RandomHorizontalFlip(),
T.ToTensor(),
T.Normalize(mean, std)
])
transform_test = T.Compose([T.ToTensor(), T.Normalize(mean, std)])
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform_train)
test_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform_test)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=args.batch_size,
shuffle=True, num_workers=2)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=256,
shuffle=False, num_workers=2)
# ---------- 3. 模型 ----------
class Net(nn.Module):
def __init__(self):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, 3, padding=1), # 32×32×32
nn.ReLU(inplace=True),
nn.MaxPool2d(2), # 32×16×16
nn.Conv2d(32, 64, 3, padding=1), # 64×16×16
nn.ReLU(inplace=True),
nn.MaxPool2d(2) # 64×8×8
)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(64*8*8, 256),
nn.ReLU(inplace=True),
nn.Linear(256, 10)
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return x
model = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=args.lr)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=args.epochs)
# ---------- 4. 工具 ----------
def save_ckpt(epoch, best_acc):
torch.save({'epoch': epoch,
'model_state': model.state_dict(),
'opt_state': optimizer.state_dict(),
'best_acc': best_acc}, args.ckpt)
def load_ckpt():
checkpoint = torch.load(args.ckpt, map_location=device)
model.load_state_dict(checkpoint['model_state'])
optimizer.load_state_dict(checkpoint['opt_state'])
return checkpoint['epoch'], checkpoint['best_acc']
# ---------- 5. 训练 ----------
def train(epoch):
model.train()
total, correct, loss_sum = 0, 0, 0.
for x, y in train_loader:
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
out = model(x)
loss = criterion(out, y)
loss.backward()
optimizer.step()
loss_sum += loss.item() * x.size(0)
_, pred = out.max(1)
total += y.size(0)
correct += pred.eq(y).sum().item()
scheduler.step()
print(f'Epoch {epoch:3d} | train loss {loss_sum/total:.4f} | acc {100.*correct/total:5.2f}%')
# ---------- 6. 测试 ----------
@torch.no_grad()
def test():
model.eval()
total, correct = 0, 0
for x, y in test_loader:
x, y = x.to(device), y.to(device)
out = model(x)
_, pred = out.max(1)
total += y.size(0)
correct += pred.eq(y).sum().item()
acc = 100. * correct / total
print(f' test acc {acc:5.2f}%')
return acc
# ---------- 7. 主流程 ----------
start_epoch, best_acc = 0, 0
if args.resume and os.path.isfile(args.ckpt):
start_epoch, best_acc = load_ckpt()
print(f' resumed from epoch {start_epoch}, best acc {best_acc:.2f}%')
for ep in range(start_epoch+1, args.epochs+1):
t0 = time.time()
train(ep)
acc = test()
if acc > best_acc:
best_acc = acc
save_ckpt(ep, best_acc)
print(f' epoch time {time.time()-t0:.1f}s, best {best_acc:.2f}%')
# ---------- 8. 单张图片推理 ----------
def infer_one(path):
from PIL import Image
img = Image.open(path).convert('RGB').resize((32,32))
x = transform_test(img).unsqueeze(0).to(device)
logits = model(x)
prob = torch.softmax(logits, dim=1)
cls = prob.argmax(1).item()
print(f'predicted class {cls}, prob {prob[0,cls]:.3f}')
# 用法:把任意 32×32 图片放同目录下
# infer_one('cat.png')RNN
循环神经网络(Recurrent Neural Network, RNN)是一类专门用于处理序列数据的深度学习模型,其独特的循环结构使其能够捕捉数据中的时序依赖关系。
在现实世界中,大量数据以序列形式存在:
- 自然语言:句子中的单词按顺序排列,前后语义相互关联
- 时间序列:股票价格、气温变化等随时间变化的数据
- 视频数据:连续的帧构成时序序列
- 语音信号:声波的时间序列表示
传统神经网络(如全连接网络、CNN)存在明显缺陷:
- 输入输出维度固定,无法处理长度可变的序列
- 缺乏对序列中时序依赖关系的建模能力
- 无法共享不同时间步的参数,导致模型复杂度剧增
RNN的设计遵循两个关键原则:
- 权值共享:同一组参数在所有时间步中使用,大幅减少参数数量
- 状态传递:通过隐藏状态传递历史信息,实现对序列依赖的建模
NumPy手工实现(与公式一一对应)
python
import numpy as np
# 1. 数据:T=3, d_x=2, d_h=3, d_y=1
X = np.array([[1, 2], [0, 1], [2, 0]], dtype=float) # (T, d_x)
Y = np.array([[1], [-1], [0]], dtype=float) # (T, d_y)
# 2. 参数初始化
d_x, d_h, d_y, T = 2, 3, 1, 3
np.random.seed(0)
W_h = np.random.randn(d_h, d_h) * 0.1
W_x = np.random.randn(d_h, d_x) * 0.1
W_y = np.random.randn(d_y, d_h) * 0.1
b = np.zeros(d_h)
c = np.zeros(d_y)
# 3. 前向
h = np.zeros((T+1, d_h)) # h[0] = 0
yhat = np.zeros((T, d_y))
for t in range(T):
z = W_h @ h[t] + W_x @ X[t] + b
h[t+1] = np.tanh(z)
yhat[t] = W_y @ h[t+1] + c
loss = 0.5 * ((yhat - Y)**2).sum()
print('forward loss:', loss)
# 4. 反向
delta_y = yhat - Y # (T, d_y)
dW_y = np.zeros_like(W_y)
dc = np.zeros_like(c)
dW_h = np.zeros_like(W_h)
dW_x = np.zeros_like(W_x)
db = np.zeros_like(b)
dh = np.zeros_like(h) # dh[t] = ∂L/∂h[t]
# 从T-1到0回传
for t in reversed(range(T)):
# 输出层
dW_y += delta_y[t][:, None] @ h[t+1][None, :]
dc += delta_y[t]
dh[t+1] += W_y.T @ delta_y[t]
# 隐藏梯度
tanh_grad = 1 - h[t+1]**2
dh[t] += W_h.T @ (dh[t+1] * tanh_grad)
# 参数梯度
common = dh[t+1] * tanh_grad
dW_h += common[:, None] @ h[t][None, :]
dW_x += common[:, None] @ X[t][None, :]
db += common
print('dW_h:\n', dW_h)
print('db:', db)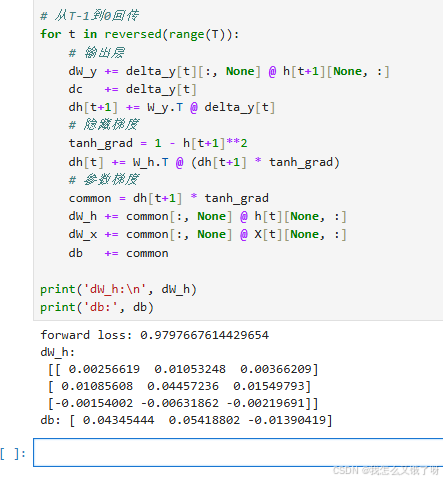
PyTorch对照实验(验证梯度一致)
python
import torch
X_t = torch.tensor(X, requires_grad=False)
Y_t = torch.tensor(Y, requires_grad=False)
# 构造相同参数
class VanillaRNN(torch.nn.Module):
def __init__(self):
super().__init__()
self.W_h = torch.nn.Parameter(torch.tensor(W_h, dtype=torch.float32))
self.W_x = torch.nn.Parameter(torch.tensor(W_x, dtype=torch.float32))
self.W_y = torch.nn.Parameter(torch.tensor(W_y, dtype=torch.float32))
self.b = torch.nn.Parameter(torch.tensor(b, dtype=torch.float32))
self.c = torch.nn.Parameter(torch.tensor(c, dtype=torch.float32))
def forward(self, x):
h = torch.zeros(d_h)
y_seq = []
for t in range(x.size(0)):
h = torch.tanh(self.W_h @ h + self.W_x @ x[t] + self.b)
y_seq.append(self.W_y @ h + self.c)
return torch.stack(y_seq)
rnn = VanillaRNN()
yhat_t = rnn(X_t)
loss_t = 0.5 * ((yhat_t - Y_t)**2).sum()
loss_t.backward()
print('PyTorch dW_h:\n', rnn.W_h.grad)
print('PyTorch db:', rnn.b.grad)N-gram
n-gram算法是一种广泛应用于文本分析和处理的基础算法。它通过统计文本中连续n个词的序列(或称为"词组")出现的频率,为各种NLP任务提供了有力的支持。
n-gram算法的基本思想是将文本拆分成若干个连续的n个词的序列,并统计这些序列在文本中出现的频率。这里的n是一个正整数,表示词组中词的个数。
-
假设:第 t 个词只与前 N-1 个词有关(马尔可夫假设)
-
目标:估计条件概率
P(w_t | w_{t-N+1} ... w_{t-1})
-
训练:在语料里数频次 → 频率 → 概率
-
问题:零频次 → 概率=0 → 无法处理新序列
解决:平滑(smoothing)------把概率质量从"见过"挪到"没见过"
python
from collections import defaultdict, Counter
import math
class NGram:
def __init__(self, n=2, k=0.0, smooth='add-k'):
self.n = n
self.k = k
self.smooth = smooth # 'add-k', 'katz', 'interp'
self.pad = '<s>'
self.unk = '<UNK>'
self.counts = defaultdict(Counter) # context -> Counter(next)
self.context_tot = Counter() # context -> total
self.vocab = set()
# 1. 训练 --------------------------------------------------
def fit(self, sents):
for sent in sents:
tokens = [self.pad]*(self.n-1) + sent + [self.pad]
for i in range(len(tokens)-self.n+1):
ctx = tuple(tokens[i:i+self.n-1])
nxt = tokens[i+self.n-1]
self.counts[ctx][nxt] += 1
self.context_tot[ctx] += 1
self.vocab.add(nxt)
self.vocab.add(self.pad)
self.V = len(self.vocab)
# 2. 概率查询 ---------------------------------------------
def prob(self, ctx, w):
ctx = tuple(ctx)
if self.smooth == 'add-k':
num = self.counts[ctx][w] + self.k
den = self.context_tot[ctx] + self.k * self.V
return num / max(den, 1e-12)
if self.smooth == 'katz':
d = 0.5
if self.counts[ctx][w] > 0:
return (self.counts[ctx][w] - d) / self.context_tot[ctx]
else:
# 回退到 unigram
alpha = 1.0 - sum((c-d)/self.context_tot[ctx]
for c in self.counts[ctx].values() if c>0)
alpha = max(alpha, 0.0)
# 未看见 bigram 时用 unigram 重新归一
p_ml_unigram = self.context_tot[w] / max(sum(self.context_tot.values()),1)
# rare words denominator
sum_rare = sum(self.context_tot[w2] for w2 in self.vocab
if self.counts[ctx][w2]==0)
sum_rare = max(sum_rare, 1)
return alpha * p_ml_unigram / sum_rare * self.context_tot[w]
if self.smooth == 'interp':
# 简单固定系数 bigram/unigram 插值
lam2, lam1 = 0.7, 0.3
p2 = self.prob(ctx, w) if self.smooth=='add-k' and self.k==0 else \
(self.counts[ctx][w] / max(self.context_tot[ctx],1))
p1 = self.context_tot[w] / max(sum(self.context_tot.values()),1)
return lam2*p2 + lam1*p1
# 3. 句子概率 ---------------------------------------------
def score_sent(self, sent, log=True):
tokens = [self.pad]*(self.n-1) + sent + [self.pad]
score = 0.0
for i in range(len(tokens)-self.n+1):
ctx = tokens[i:i+self.n-1]
nxt = tokens[i+self.n-1]
p = self.prob(ctx, nxt)
score += math.log(p) if log else p
return score
# 4. 生成下一个词 -----------------------------------------
def generate_next(self, ctx):
ctx = tuple(ctx[-(self.n-1):])
return max(self.vocab, key=lambda w: self.prob(ctx, w))
# ------------------ 六、数值实验 ------------------
if __name__ == '__main__':
corpus = [["I", "am", "Sam", "</s>"],
["I", "am", "green", "</s>"],
["Sam", "I", "am", "</s>"]]
mle = NGram(n=2, k=0.0, smooth='add-k')
mle.fit(corpus)
add1 = NGram(n=2, k=1.0, smooth='add-k')
add1.fit(corpus)
print('ML P(am|<s>) =', mle.prob(['<s>'], 'am'))
print('Add1 P(am|<s>) =', add1.prob(['<s>'], 'am'))
print('Add1 sent-score:', add1.score_sent(["I", "am", "green", "</s>"]))
# 与 NLTK 交叉验证
try:
import nltk
nltk.download('punkt')
from nltk import bigrams, FreqDist
bg = bigrams([w for s in corpus for w in ['<s>']+s])
fd = FreqDist(bg)
print('NLTK Count((<s>,am)) =', fd[('<s>', 'am')])
except:
pass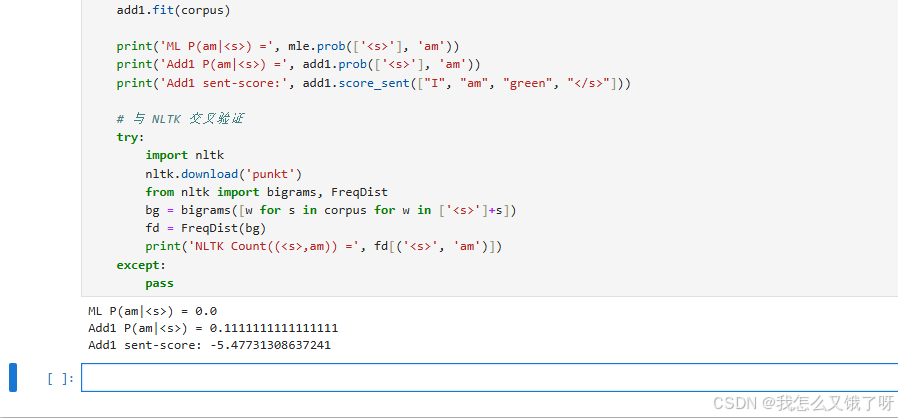
这数值好像不太对,可以先忽略
Transformer架构
Transformer 架构思想
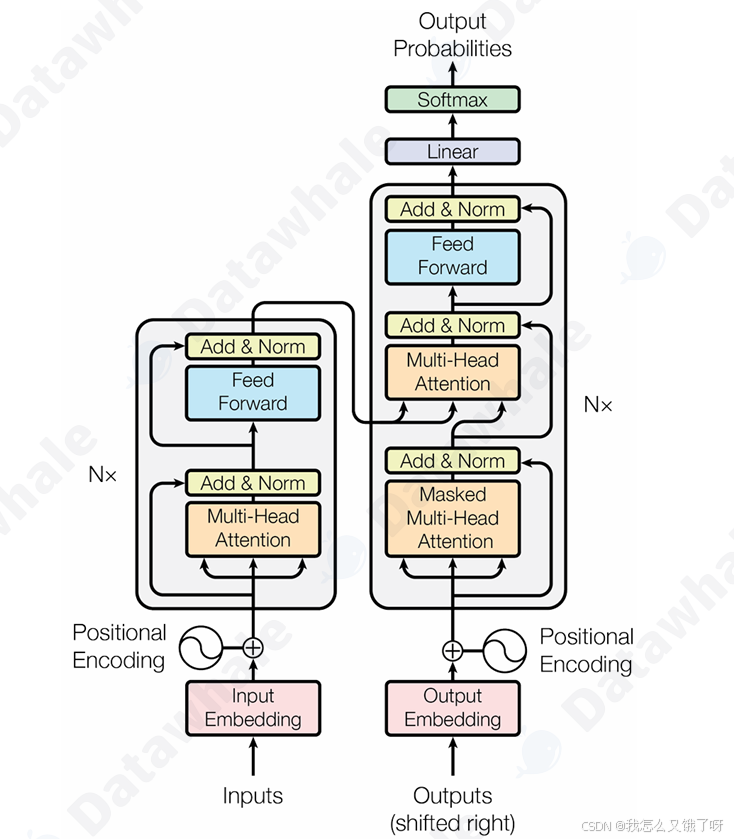
-
编码器 (Encoder) :任务是"理解"输入的整个句子。它会读取所有输入词元,最终为每个词元生成一个富含上下文信息的向量表示。
-
解码器 (Decoder) :任务是"生成"目标句子。它会参考自己已经生成的前文,并"咨询"编码器的理解结果,来生成下一个词。
-
RNN:必须时序串行,长程梯度消失
-
CNN:感受野随深度线性增长,全局依赖需要很多层
-
Self-Attention:
-
任意两位置直接相连,距离=1
-
并行计算,易加速
-
显式权重矩阵,可解释性好
-
python
# transformer_mini.py
import math, random
import torch
import torch.nn as nn
import torch.nn.functional as F
# ---- 1. 超参 ----
B, T, d_model, h, d_ff = 2, 5, 8, 2, 32
d_k = d_v = d_model // h
num_layers = 2
num_epochs = 30
lr = 1e-3
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# ---- 2. 位置编码 ----
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
pos = torch.arange(0, max_len).unsqueeze(1).float()
div = torch.exp(torch.arange(0, d_model, 2).float() *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(pos * div)
pe[:, 1::2] = torch.cos(pos * div)
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:x.size(1), :] # x: [B, T, d_model]
# ---- 3. Multi-Head Attention ----
class MultiHeadAttention(nn.Module):
def __init__(self):
super().__init__()
self.qkv = nn.Linear(d_model, 3 * d_model) # 合并 Q/K/V 投影
self.o = nn.Linear(d_model, d_model)
self.scale = d_k ** -0.5
def forward(self, x, mask=None):
B, T, _ = x.shape
qkv = self.qkv(x) # [B, T, 3*d_model]
q, k, v = qkv.chunk(3, dim=-1) # each [B, T, d_model]
q = q.view(B, T, h, d_k).transpose(1, 2) # [B, h, T, d_k]
k = k.view(B, T, h, d_k).transpose(1, 2)
v = v.view(B, T, h, d_v).transpose(1, 2)
scores = (q @ k.transpose(-2, -1)) * self.scale # [B, h, T, T]
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn = F.softmax(scores, dim=-1)
out = attn @ v # [B, h, T, d_v]
out = out.transpose(1, 2).contiguous().view(B, T, d_model)
return self.o(out), attn
# ---- 4. Feed-Forward ----
class FeedForward(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model)
)
def forward(self, x):
return self.net(x)
# ---- 5. Encoder Layer ----
class EncoderLayer(nn.Module):
def __init__(self):
super().__init__()
self.attn = MultiHeadAttention()
self.ff = FeedForward()
self.ln1 = nn.LayerNorm(d_model)
self.ln2 = nn.LayerNorm(d_model)
def forward(self, x, mask=None):
attn_out, attn_weights = self.attn(x, mask)
x = self.ln1(x + attn_out)
ff_out = self.ff(x)
x = self.ln2(x + ff_out)
return x, attn_weights
# ---- 6. 整体 Transformer Encoder ----
class TransformerEncoder(nn.Module):
def __init__(self, vocab_size, num_layers):
super().__init__()
self.embed = nn.Embedding(vocab_size, d_model)
self.pe = PositionalEncoding(d_model)
self.layers = nn.ModuleList([EncoderLayer() for _ in range(num_layers)])
self.ln_final = nn.LayerNorm(d_model)
self.head = nn.Linear(d_model, vocab_size) # 输出词典概率
def forward(self, x, mask=None):
x = self.embed(x) * math.sqrt(d_model)
x = self.pe(x)
attns = []
for layer in self.layers:
x, attn = layer(x, mask)
attns.append(attn)
x = self.ln_final(x)
return self.head(x), attns
# ---- 7. 任务:copy 序列 ----
vocab_size = 11 # 0~9 数字 + 0 用作 pad
def make_data(batch_size, length=T):
src = torch.randint(1, vocab_size, (batch_size, length))
tgt = src.clone()
return src.to(device), tgt.to(device)
# ---- 8. 训练脚本 ----
model = TransformerEncoder(vocab_size, num_layers).to(device)
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# 因果掩码(下三角)
def subsequent_mask(size):
attn_shape = (1, size, size)
mask = torch.triu(torch.ones(attn_shape), diagonal=1).to(device)
return mask == 0 # 1 表示保留
mask = subsequent_mask(T)
for epoch in range(1, num_epochs+1):
model.train()
src, tgt = make_data(B)
logits, _ = model(src, mask) # [B, T, vocab]
loss = criterion(logits.view(-1, vocab_size), tgt.view(-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 5 == 0:
print(f'epoch {epoch:02d} | loss {loss.item():.4f}')
# ---- 9. 推理:贪心解码 ----
model.eval()
src, tgt = make_data(1)
with torch.no_grad():
logits, attns = model(src, mask)
pred = logits.argmax(-1) # [1, T]
print('input :', src.cpu().numpy())
print('pred :', pred.cpu().numpy())
print('target:', tgt.cpu().numpy())
自注意力机制
每个位置对序列内所有位置(含自己)计算相似度 → 加权求和 → 得到该位置的新表示
相似度用点积,权重用 softmax 归一化
python
import numpy as np
np.random.seed(0)
# 1. 迷你数据
B, T, d = 2, 4, 6
X = np.random.randn(B, T, d).astype('float32')
# 2. 随机参数
WQ = np.random.randn(d, d).astype('float32') * 0.1
WK = np.random.randn(d, d).astype('float32') * 0.1
WV = np.random.randn(d, d).astype('float32') * 0.1
scale = np.sqrt(d).astype('float32')
# 3. 前向
Q = X @ WQ
K = X @ WK
V = X @ WV
scores = (Q @ K.transpose(0, 2, 1)) / scale # (B,T,T)
attn = softmax(scores, axis=-1) # 手动 softmax
Z = attn @ V # (B,T,d)
def softmax(x, axis=-1):
x_max = x.max(axis=axis, keepdims=True)
exp = np.exp(x - x_max)
return exp / exp.sum(axis=axis, keepdims=True)
print('Z shape:', Z.shape) # → (2,4,6)多头注意力机制
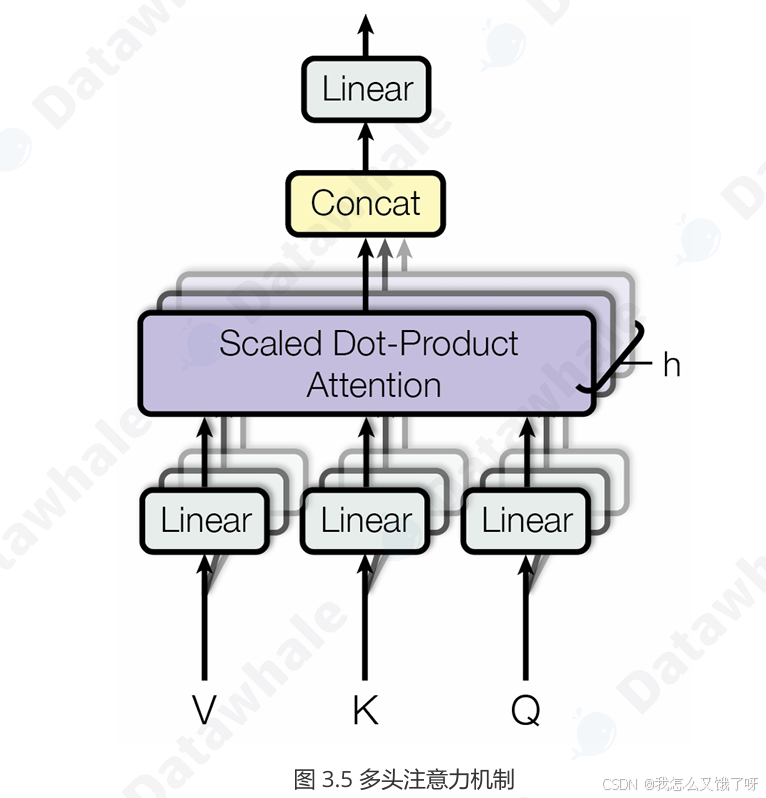
把 d 拆成 h 份(每份 d_k = d_v = d/h),并行跑 h 个独立自注意力,得到 h 个 (B,T,d_v)
沿最后一维拼接 → (B,T,h*d_v) 再线性投影回 d 模型维度。需要注意的是有兄弟在群里也问到了这里的concat是复制还是分割,图中的部分不为分割,是复制h分再进行压缩。
-
每头专注不同子空间(类似 CNN 多通道)
-
计算量与单头近似(并行矩阵乘法)
python
h, d_k, d_v = 2, d//2, d//2
# 把 W 拆成 h 份
WQ_h = WQ.reshape(d, h, d_k).transpose(1, 0, 2) # (h,d,d_k)
WK_h = WK.reshape(d, h, d_k).transpose(1, 0, 2)
WV_h = WV.reshape(d, h, d_v).transpose(1, 0, 2)
WO = np.random.randn(h*d_v, d).astype('float32') * 0.1
heads = []
for i in range(h):
Qh = X @ WQ_h[i] # (B,T,d_k)
Kh = X @ WK_h[i]
Vh = X @ WV_h[i]
score_h = (Qh @ Kh.transpose(0,2,1)) / np.sqrt(d_k)
attn_h = softmax(score_h)
head_i = attn_h @ Vh # (B,T,d_v)
heads.append(head_i)
multi = np.concatenate(heads, axis=-1) # (B,T,h*d_v)
Z_multi = multi @ WO # (B,T,d)
print('Multi-head Z shape:', Z_multi.shape)Decoder-Only 架构
-
目标:统一「预训练 + 下游生成」一个模型既能做语言模型,又能做指令对话、代码补全等生成任务。
-
关键 :去掉 Encoder,仅用 Transformer 的 Decoder 栈;每一层都是 Masked Self-Attention,保证第 t 个 token 只能看见 0...t-1,天然自回归。
-
2025 主流改进 :
-- RMSNorm 代替 LayerNorm(去均值,只除 RMS,计算更快)
-- GQA(Grouped-Query Attention)减少 KV-Head 数量,推理显存 ↓30%
-- SwiGLU / GELU 激活成为默认 FFN
-- FlashAttention-2 / FlashMLA 融合算子,训练吞吐 ↑50%
python
# decoder_only_mini.py
import math, random, torch, torch.nn as nn
from torch.nn import functional as F
# ---------- 超参 ----------
B, T, d_model, h, d_ff, vocab_size, n_layers = 2, 8, 512, 8, 2048, 1000, 6
device = 'cuda' if torch.cuda.is_available() else 'cpu'
epochs, lr = 30, 1e-3
# ---------- 组件 ----------
class RMSNorm(nn.Module):
def __init__(self, d, eps=1e-6):
super().__init__()
self.weight = nn.Parameter(torch.ones(d))
self.eps = eps
def forward(self, x):
rms = x.pow(2).mean(-1, keepdim=True).sqrt() + self.eps
return x / rms * self.weight
class MultiHeadCausalAttention(nn.Module):
def __init__(self):
super().__init__()
assert d_model % h == 0
self.d_k = d_model // h
self.qkv = nn.Linear(d_model, 3*d_model) # 合并投影
self.o = nn.Linear(d_model, d_model)
# 注册因果掩码(一次性)
mask = torch.tril(torch.ones(T, T)).unsqueeze(0) # (1,T,T)
self.register_buffer('mask', mask)
def forward(self, x):
B, T, _ = x.size()
qkv = self.qkv(x) # (B,T,3*d)
q, k, v = qkv.chunk(3, dim=-1)
q = q.view(B, T, h, self.d_k).transpose(1, 2) # (B,h,T,d_k)
k = k.view(B, T, h, self.d_k).transpose(1, 2)
v = v.view(B, T, h, self.d_k).transpose(1, 2)
scores = (q @ k.transpose(-2, -1)) / math.sqrt(self.d_k)
scores = scores.masked_fill(self.mask[:,:T,:T]==0, -1e9)
attn = F.softmax(scores, dim=-1)
out = attn @ v # (B,h,T,d_k)
out = out.transpose(1, 2).contiguous().view(B, T, d_model)
return self.o(out)
class SwiGLU_FF(nn.Module):
def __init__(self):
super().__init__()
self.w1 = nn.Linear(d_model, d_ff)
self.w2 = nn.Linear(d_model, d_ff) # gate
self.w3 = nn.Linear(d_ff, d_model)
def forward(self, x):
return self.w3(F.silu(self.w1(x)) * self.w2(x))
class DecoderBlock(nn.Module):
def __init__(self):
super().__init__()
self.ln1 = RMSNorm(d_model)
self.attn = MultiHeadCausalAttention()
self.ln2 = RMSNorm(d_model)
self.ffn = SwiGLU_FF()
def forward(self, x):
x = x + self.attn(self.ln1(x))
x = x + self.ffn(self.ln2(x))
return x
class DecoderOnlyTransformer(nn.Module):
def __init__(self):
super().__init__()
self.embed = nn.Embedding(vocab_size, d_model)
self.blocks = nn.ModuleList([DecoderBlock() for _ in range(n_layers)])
self.ln_f = RMSNorm(d_model)
self.head = nn.Linear(d_model, vocab_size)
# 可学习位置编码
self.pos = nn.Parameter(torch.randn(T, d_model))
def forward(self, ids):
# ids: (B, T)
x = self.embed(ids) + self.pos # (B,T,d)
for block in self.blocks:
x = block(x)
x = self.ln_f(x)
return self.head(x) # (B,T,vocab)
# ---------- 数据:随机下一句预测 ----------
def batch_data():
x = torch.randint(1, vocab_size, (B, T), device=device)
y = torch.roll(x, shifts=-1, dims=1) # 下标右移 1 位
y[:, -1] = 0 # 0 作为句尾
return x, y
# ---------- 训练 ----------
model = DecoderOnlyTransformer().to(device)
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
for epoch in range(epochs):
model.train()
x, y = batch_data()
logits = model(x) # (B,T,vocab)
loss = criterion(logits.view(-1, vocab_size), y.view(-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 5 == 0:
print(f'epoch {epoch:02d} | loss {loss.item():.4f}')
# ---------- 推理:自回归生成 30 tokens ----------
model.eval()
start = torch.randint(1, vocab_size, (1, 1), device=device)
gen = start
for _ in range(30):
with torch.no_grad():
logits = model(gen) # (1,len,vocab)
next_id = logits[0, -1].argmax().unsqueeze(0).unsqueeze(0)
gen = torch.cat([gen, next_id], dim=1)[:, -T:] # 保持窗口
print('Generated:', gen.cpu().numpy().squeeze())如何继续扩展
-
加深 / 加宽:把
n_layers=12|24|40,d_model=768|1024|4096 -
换 RMSNorm + SwiGLU + GQA 组合,即得 LLaMA-2/3 结构
-
训练数据:用
datasets加载 WikiText-103 或 C4,结合FlashAttention-2提速 50% -
推理优化:
-- KV-cache + GQA 减少显存 30%
-- 量化(INT8/INT4)(ggml 方案)
-- 投机解码(speculative decoding)提升 2× 吞吐
模型的选择
最后一节,数学推导困了,就跟大家聊聊模型的选择,这里从网上找到了部分数据。在选择智能体时,建议把"能力、效率、成本、合规、生态"五大维度拆解成 12 项可量化指标
| 维度 | 细化指标 | 衡量方法 | 智能体场景关注点 |
|---|---|---|---|
| 1. 基础智能 | MMLU-Pro、AIME2025、CodeHunt | 公开榜 + 私题盲测 | 复杂任务拆解与推理 |
| 2. 指令跟随 | IFCare、FollowBench-2025 | 严格格式 / 多步约束 | Agent 工作流是否掉链子 |
| 3. 工具调用 | APIcall-Score、ToolBench-Top1 | 真实 500+ API 成功率 | 插件/函数调用可靠性 |
| 4. 长程记忆 | 128k-needle、∞Bench | 多针检索 + 长文档 QA | 长会话、报告总结 |
| 5. 幻觉控制 | HaluEval-2、ChineseFact | 事实类问答 F1 | 减少"编造"带来的合规风险 |
| 6. 多语言 | XLSum、CMMLU | 低资源语言 Zero-shot | 出海或跨地区部署 |
| 7. 推理速度 | tokens/s、首包延迟 | 同 A100-80G 实测 | 交互体验与并发成本 |
| 8. 显存占用 | 7B/13B/70B 峰值 GB | 单卡/单机可部署性 | 边缘或私有云限制 |
| 9. 微调成本 | LoRA/Full 训练小时数 | 1B token 端到端时间 | 领域适配预算 |
| 10. 许可合规 | Apache-2.0 / CC-BY-SA / 商用需审批 | 法务审计 | 商业闭环可行性 |
| 11. 社区生态 | HuggingFace ★、插件数、PR 合并速度 | 活跃度 | 后续维护与人才池 |
| 12. 安全对齐 | SafetyBench-2025、Red-Team 分数 | 违规拒答率 | 上市或政府项目硬门槛 |
近年国内外主流开源模型对比
| 模型 | 规模 | 基础智能 | 指令跟随 | 工具调用 | 长文本 | 幻觉控制 | 速度 t/s | 显存 GB | 许可 | 综合评述 |
|---|---|---|---|---|---|---|---|---|---|---|
| DeepSeek-V3.1 | 235B-MoE | 88.4 | 85.2 | 82.7 | 81.5 | 83.0 | 18 | 80×2 | Apache-2.0 | 数学/代码全球第二,仅次于 GPT-5;MoE 推理成本≈60B dense |
| Qwen3-235B-A22B | 235B-MoE | 87.6 | 84.8 | 84.1 | 83.2 | 82.5 | 17 | 80×2 | Apache-2.0 | 中文第一,Agent 任务领先海外 23 分 |
| LLaMA-3.1-405B | 405B dense | 84.1 | 82.0 | 78.5 | 79.0 | 80.2 | 12 | 160×4 | LLaMA2-License* | 英文稳健,中文需继续微调;硬件门槛高 |
| GPT-4o-mini-oss | 120B | 83.5 | 81.3 | 79.0 | 77.8 | 81.0 | 45 | 40×1 | 不可商用 | 海外最快开源小钢炮,速度优先 |
| Yi-34B-200k | 34B dense | 82.3 | 80.1 | 77.4 | 85.0* | 79.8 | 28 | 24×1 | Apache-2.0 | 长文本冠军(200k),单卡可部署 |
| Baichuan3-14B | 14B dense | 78.2 | 77.5 | 75.0 | 76.1 | 77.0 | 35 | 12×1 | 部分商用 | 中文小参数性价比之选 |
优势-劣势
-
国内第一梯队(DeepSeek / Qwen3)
✅ 中文基准全面领先海外开源 20+ 分;Agent 任务优势 23 分
✅ MoE 结构,推理激活参数量 ≈ 60B,成本可控
✅ Apache-2.0,商业闭环无法务风险
❌ 硬件门槛仍要求 2×A100-80G 起步;量化后单卡可缓解
-
海外开源(LLaMA-3.1-405B / GPT-4o-mini-oss)
✅ 英文稳健性、幻觉控制更好;社区插件丰富
✅ GPT-4o-mini 速度 45 tokens/s,适合高并发 C 端
❌ 中文需额外微调;LLaMA 商用需审批;GPT-oss 不可商用
-
长文本专用(Yi-34B-200k)
✅ 200k 窗口单卡可跑,长文档总结/法律合同场景首选
✅ 34B 参数,LoRA 微调 4×3090 24h 完成
❌ 基础推理能力比第一梯队低 6 分
大语言模型的局限性(天花板提示)
-
幻觉不可消除
即使 400B+ 模型,HaluEval-2 仍 >12% 错误率;智能体若直接写库/下单,需"人在回路"或双重校验。
-
长文本泛化陷阱
128k 窗口内 needle 检索可 99%,但 多跳推理 随长度指数下降;RAG+摘要分段仍是工程首选。
今天把「从ANN到Decoder-Only」整条技术栈重新编译了一遍,耗时五到六个小时,感觉像给大脑做了一次权重更新:ANN/CNN/RNN先把"感知-局部-时序"三大inductive bias写进网络结构,相当于用硬编码kernel给梯度开路;到了Transformer,bias被彻底拔掉,只靠self-attention让数据自己学关联矩阵,参数量瞬间爆炸,但也给并行和超长依赖留了IO口。单头attention→多头attention这一步,本质是把d_model切成h份做"通道级ensemble",计算量没涨,但子空间多样性暴涨;numpy手算一遍后,发现梯度流确实更稳,给optimizer提供了h条独立路径,降低局部极小值撞车概率。N-gram用count表硬拟合p(w_t|history),平滑项就是手动dropout;Transformer用softmax自动学权重,dropout变隐式,平滑靠label smoothing------从统计特征到分布式表示,一条scale law把"数频次"变成了"算点积"。Decoder-Only把causal mask写死,把语言模型任务直接编译进attention矩阵,训练=推理,免掉encoder-decoder对齐的复杂度;再叠一层RMSNorm+SwiGLU,让梯度在pre-norm路径里先归一再放大,训练更深模型不再nan上手。
最后发现,所有架构演进都在做三件事:
- 降低梯度消失(残差/归一化)
- 提高并行度(CNN/Transformer vs RNN)
- 扩大有效感受野(attention vs n-gram)
参考文献
Hello-Agents-V1.0.0-20251103