在当今多模态大模型(VLMs)飞速发展的时代,一个令人尴尬的问题依然存在:为什么这些能看懂图像、生成描述的模型,却难以精确地定位图像中的物体?
答案在于一个根本性矛盾:让一个为语言生成而设计的模型,去输出精确的浮点数坐标,就像让一位诗人去做微积分------虽然都是处理"符号",但思维方式截然不同。
坐标生成的困境
现有的多模态大模型在生成边界框时面临两大挑战:
- 格式敏感性: 一个坐标值的轻微偏差就可能导致整个检测框无效
- 多实例处理困难: 长序列的坐标生成容易超出模型的注意力范围
结果就是,即使在COCO这样的标准检测数据集上,顶尖的开源VLM模型召回率也不到40%,远低于专用检测器50-60%的水平。
VLM-FO1的突破
浙江大学与Om AI Research团队提出的VLM-FO1框架带来了全新的思路:与其让大模型艰难地生成坐标,不如让它直接理解区域内容。

核心创新
- 即插即用的模块化设计
VLM-FO1不需要重新训练整个大模型,而是作为一个增强模块接入现有的预训练VLM。这意味着开发者可以快速为已有模型赋予检测能力,而不用担心破坏其原有的语言理解能力。
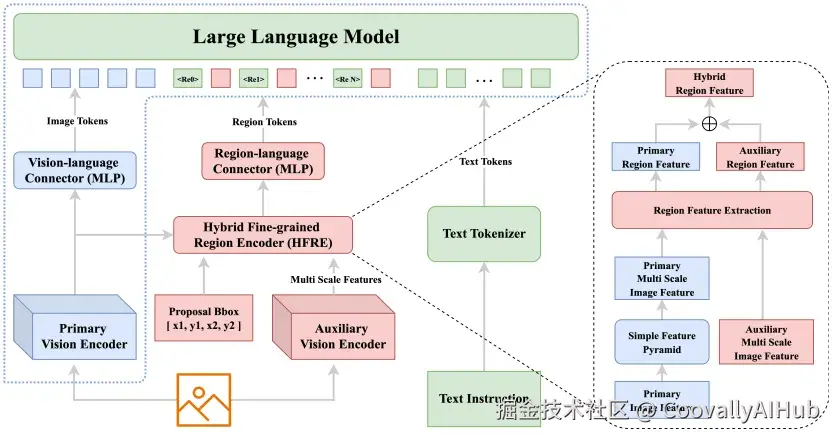
- 双视觉编码器架构
团队设计了混合细粒度区域编码器(HFRE),包含两个并行的视觉编码器:
主编码器:沿用原VLM的视觉编码器,提供丰富的语义信息
辅助编码器:采用高分辨率处理的DaViT模型,捕捉细节特征
两者特征融合后,形成了既懂"是什么"又知"在哪里"的区域表示。
- 两阶段训练策略
阶段一:只训练新添加的模块,学习将区域特征映射到语言空间
阶段二:开放更多参数进行指令微调,全面提升感知能力
性能表现:小模型的大能量
在多项基准测试中,VLM-FO1展现出了令人印象深刻的性能:
- 目标定位能力显著提升

在COCO目标检测任务上,仅3B参数的VLM-FO1达到了44.4 mAP,比同类VLM方法提升超过20个点,甚至超越了部分专用检测器。
特别是在包含困难负样本的OVDEval数据集上,VLM-FO1的43.7 mAP显著高于Grounding DINO等专业模型,证明其能有效利用大模型的世界知识进行推理。
- 区域理解全面领先
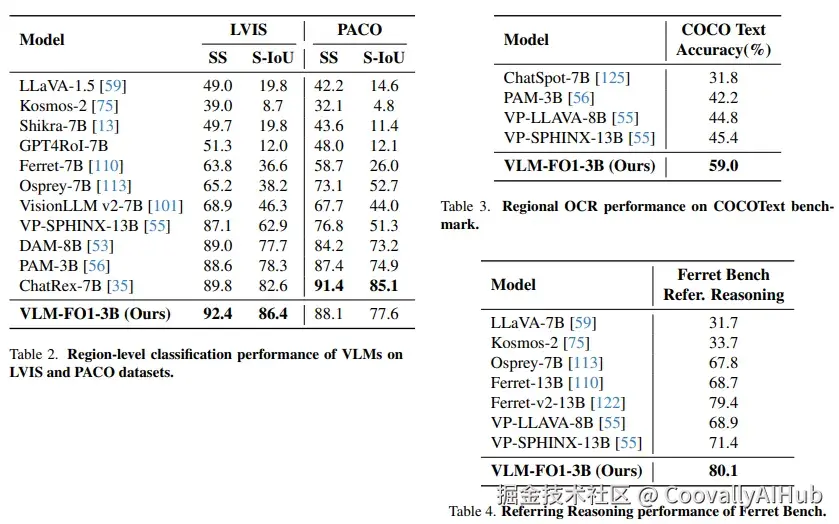
区域分类:在LVIS数据集上达到92.4% 的语义相似度
区域OCR:在COCO文本上以59.0% 的准确率大幅领先
指代表达理解:在Ferret Bench上以80.1分刷新纪录
- 复杂推理表现出色
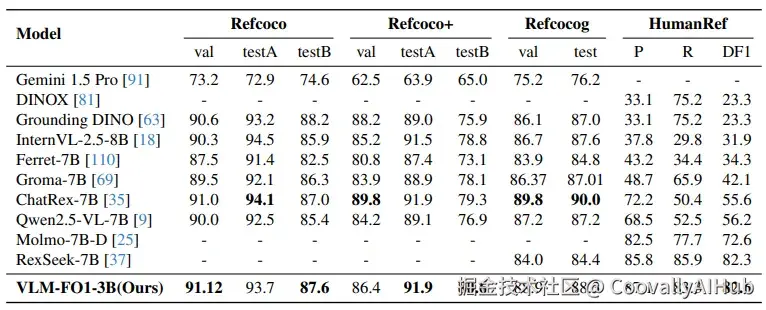
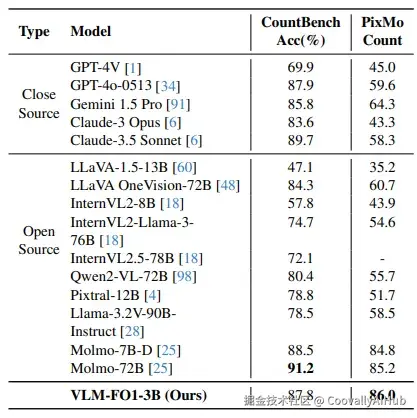
在需要结合语言理解和视觉定位的指代表达理解任务中,VLM-FO1在多个数据集上保持领先。在对象计数任务中,其"先检测再计数"的策略在PixMo-Count上达到86.0% 的准确率,超越了众多参数量大得多的模型。
- 不影响原有能力:真正的"增强"而非"替换"

最令人惊喜的是,VLM-FO1在增强细粒度感知的同时,完全保留了基础模型的通用视觉理解能力。在OpenCompass综合评测中,VLM-FO1-3B与原始Qwen2.5-VL-3B的表现基本持平,证明其没有出现灾难性遗忘。
实际应用展示
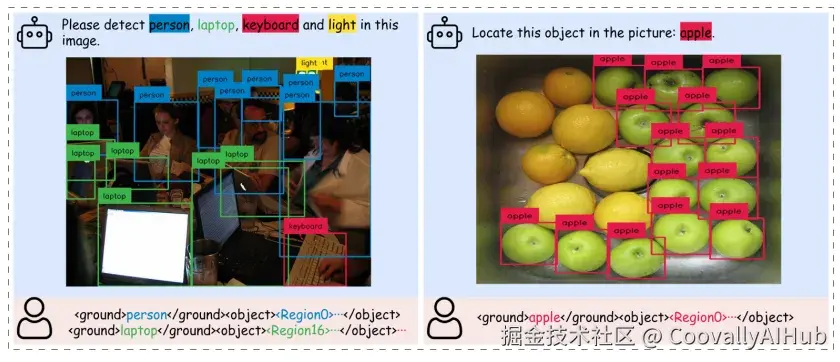
论文中展示了丰富的可视化结果,包括:
- 目标检测: 准确框出人物、笔记本电脑等物体
- 指代表达理解: 根据语言描述定位特定对象
- 对象计数: 复杂场景下的数量统计
- 区域描述: 针对特定区域生成详细描述
- 视觉推理: 结合逻辑推理的区域分析




特别是在复杂推理任务中,模型能够展示出清晰的思维链条,如通过排除法找到"没有打领带的人",逐步推理定位"盛放黑色甜甜圈的盘子"。
技术启示
VLM-FO1的成功为多模态大模型的发展提供了重要启示:
- 扬长避短
不强求大模型完成所有任务,而是将其核心的语言理解和推理能力与专门的视觉处理模块相结合。
- 模块化设计
通过即插即用的方式增强模型能力,避免每次升级都要推倒重来。
- 训练策略创新
分阶段、有针对性的训练策略能够在引入新能力的同时保护已有知识。
结语
VLM-FO1架起了一座桥梁,连接了大模型的高层推理能力与细粒度视觉感知需求。这种"理解内容而非生成坐标"的范式转变,不仅解决了当前VLM在定位任务上的瓶颈,更为构建真正理解视觉世界的多模态模型指明了方向。
随着这种技术的成熟,我们离能够真正"看懂"图像、在像素世界中自由"对话"的AI助手又近了一步。