一.传输层与传输层协议
1.传输层
传输层负责数据的端到端传输
端口号标识了一个主机上进行通信的不同的应用程序
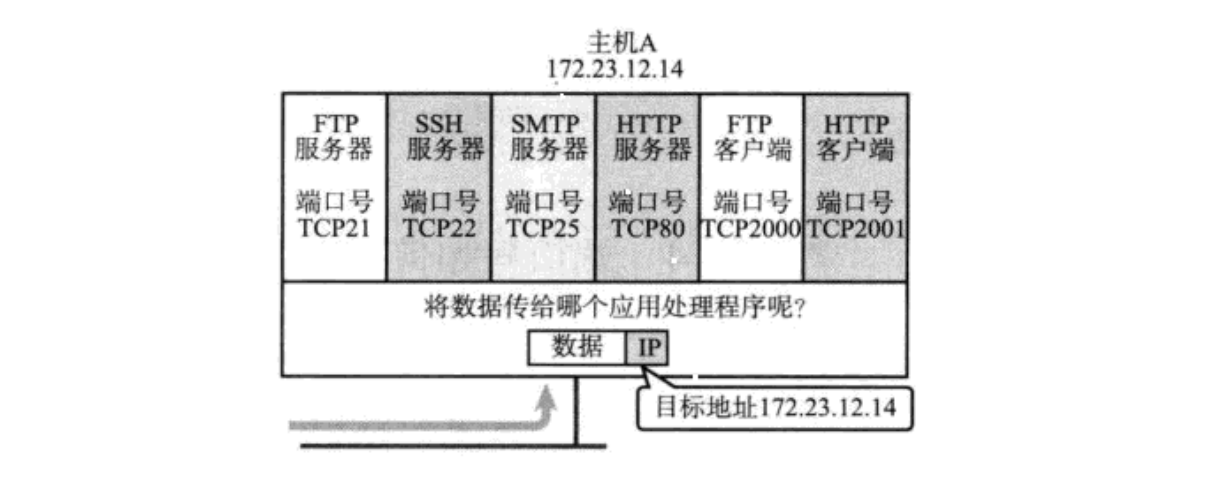
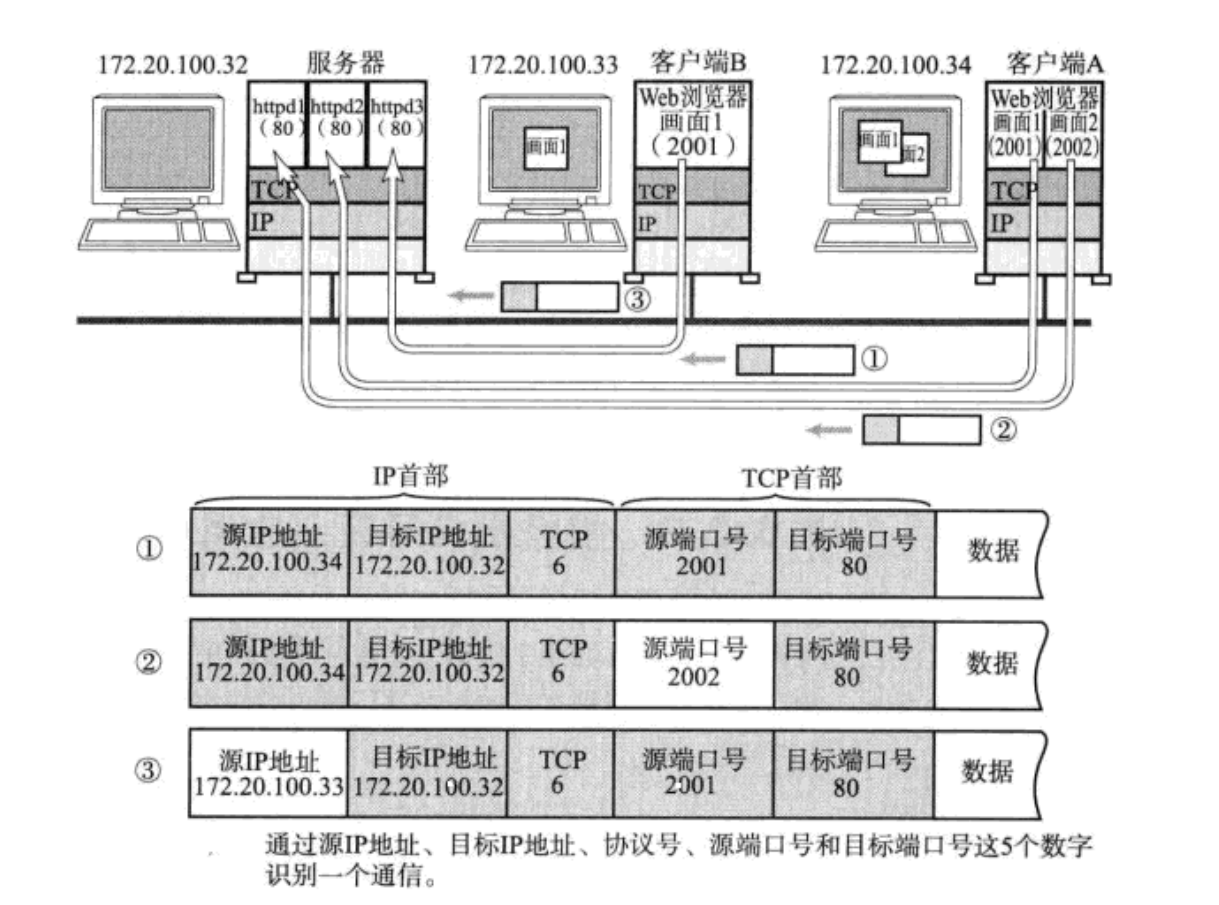
在TCP/IP协议中,用{源IP ,目的IP, 源端口号,目的端口号 ,协议}的五元组来标识一个通信(通信双方)
2.UDP协议
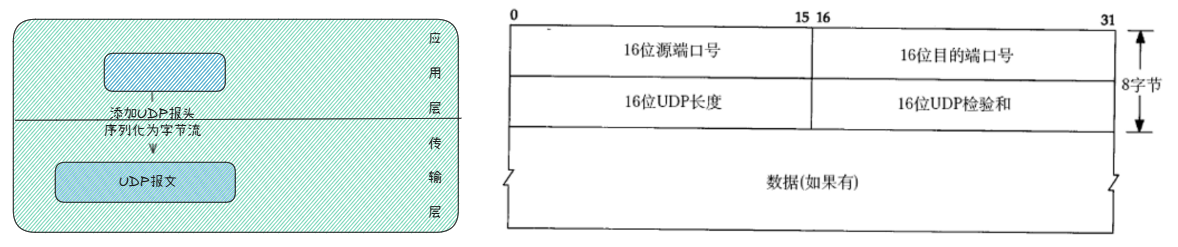
UDP报文的格式:
UDP报文,如何分离?如何分用?
UDP采用8字节定长报头,剩下的就是有效载荷。根据目的端口号,将UDP报文的有效载荷交给上层(应用层)。
问题:为什么端口号16位?因为内核协议是16位。
UDP凭什么叫用户数据报?因为它有16位UDP总长度,并且有八字节的定长报头,报文之间有边界,并且我们可以很容易解决粘包问题(应用层解决)。
UDP协议,本质也是 结构体!
cpp
struct udphdr {
__u16 source;
__u16 dest;
__u16 len;
__u16 check;
};那么UDP是否需要序列化和反序列化呢?在应用层可能有各种各样的语言进行编码,但是操作系统之间基本都是C语言编写,在操作系统内直接传输结构体对象。实际上这也是一种序列化。
应用层要求:高扩展高可用,允许一定程度的性能牺牲,但是操作系统底层一定是统一标准的。
UDP的特点:
UDP传输的过程类似于寄信,只需要对端的IP和端口号就直接进行传输,不需要建立连接;相应的TCP就类似于通电话,只有双方确认接通后才会对话。
同时UDP是不可靠的,没有确认和重传机制。面向数据报使得它不能灵活的控制读写数据的次数和数量。
面向数据报:
应⽤层交给UDP多⻓的报⽂, UDP原样发送, 既不会拆分, 也不会合并; ⽤UDP传输100个字节的数据:
• 如果发送端调⽤⼀次sendto, 发送100个字节, 那么接收端也必须调⽤对应的⼀次recvfrom, 接收100个字节; ⽽不能循环调⽤10次recvfrom, 每次接收10个字节;
UDP的缓冲区:UDP没有真正意义上的发送缓冲区。因为它往往通过send拷贝数据到缓冲区,就会立刻 进行发送,并起不到缓冲的作用,属于一种有但是不用的情况。
问题:发送失败,重发的数据来自哪?
将数据发送到网络中,在接收端确实收到 之前,缓冲区的数据是不会清空的。因为UDP不需要保证可靠性传输,所以它不需要发送缓冲区。
UDP使用的注意事项:
我们注意到, UDP协议⾸部中有⼀个16位的最⼤⻓度. 也就是说⼀个UDP能传输的数据最⼤⻓度是64K(包含UDP⾸部).
然⽽64K在当今的互联⽹环境下, 是⼀个⾮常⼩的数字.如果我们需要传输的数据超过64K, 就需要在应⽤层⼿动的分包, 多次发送, 并在接收端⼿动拼装;
基于UDP的应用层协议:
• NFS: ⽹络⽂件系统
• TFTP: 简单⽂件传输协议
• DHCP: 动态主机配置协议
• BOOTP: 启动协议(⽤于⽆盘设备启动)• DNS: 域名解析协议
3.理解报文
如果应用层正在进行报文的解析和处理,会影响操作系统从网络中读取报文吗?
在操作系统内部,一定可能同时存在大量的报文,甚至不同层次的报文。操作系统就必须管理这些报文,如何进行管理?
先描述,再组织。
struct sk_buff结构体就是用来统一描述报文的结构,类似于struct file的作用。
cpp
struct sk_buff {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
struct sock *sk;
struct skb_timeval tstamp;
struct net_device *dev;
struct net_device *input_dev;
union {
struct tcphdr *th;
struct udphdr *uh;
struct icmphdr *icmph;
struct igmphdr *igmph;
struct iphdr *ipiph;
struct ipv6hdr *ipv6h;
unsigned char *raw;
} h;
union {
struct iphdr *iph;
struct ipv6hdr *ipv6h;
struct arphdr *arph;
unsigned char *raw;
} nh;
union {
unsigned char *raw;
} mac;
struct dst_entry *dst;
struct sec_path *sp;
/*
* This is the control buffer. It is free to use for every
* layer. Please put your private variables there. If you
* want to keep them across layers you have to do a skb_clone()
* first. This is owned by whoever has the skb queued ATM.
*/
char cb[48];
unsigned int len,
data_len,
mac_len,
csum;
__u32 priority;
__u8 local_df:1,
cloned:1,
ip_summed:2,
nohdr:1,
nfctinfo:3;
__u8 pkt_type:3,
fclone:2,
ipvs_property:1;
__be16 protocol;
void (*destructor)(struct sk_buff *skb);
#ifdef CONFIG_NETFILTER
struct nf_conntrack *nfct;
#if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE)
struct sk_buff *nfct_reasm;
#endif
#ifdef CONFIG_BRIDGE_NETFILTER
struct nf_bridge_info *nf_bridge;
#endif
__u32 nfmark;
#endif /* CONFIG_NETFILTER */
#ifdef CONFIG_NET_SCHED
__u16 tc_index; /* traffic control index */
#ifdef CONFIG_NET_CLS_ACT
__u16 tc_verd; /* traffic control verdict */
#endif
#endif
#ifdef CONFIG_NET_DMA
dma_cookie_t dma_cookie;
#endif
#ifdef CONFIG_NETWORK_SECMARK
__u32 secmark;
#endif
/* These elements must be at the end, see alloc_skb() for details. */
unsigned int truesize;
atomic_t users;
unsigned char *head,
*data,
*tail,
*end;
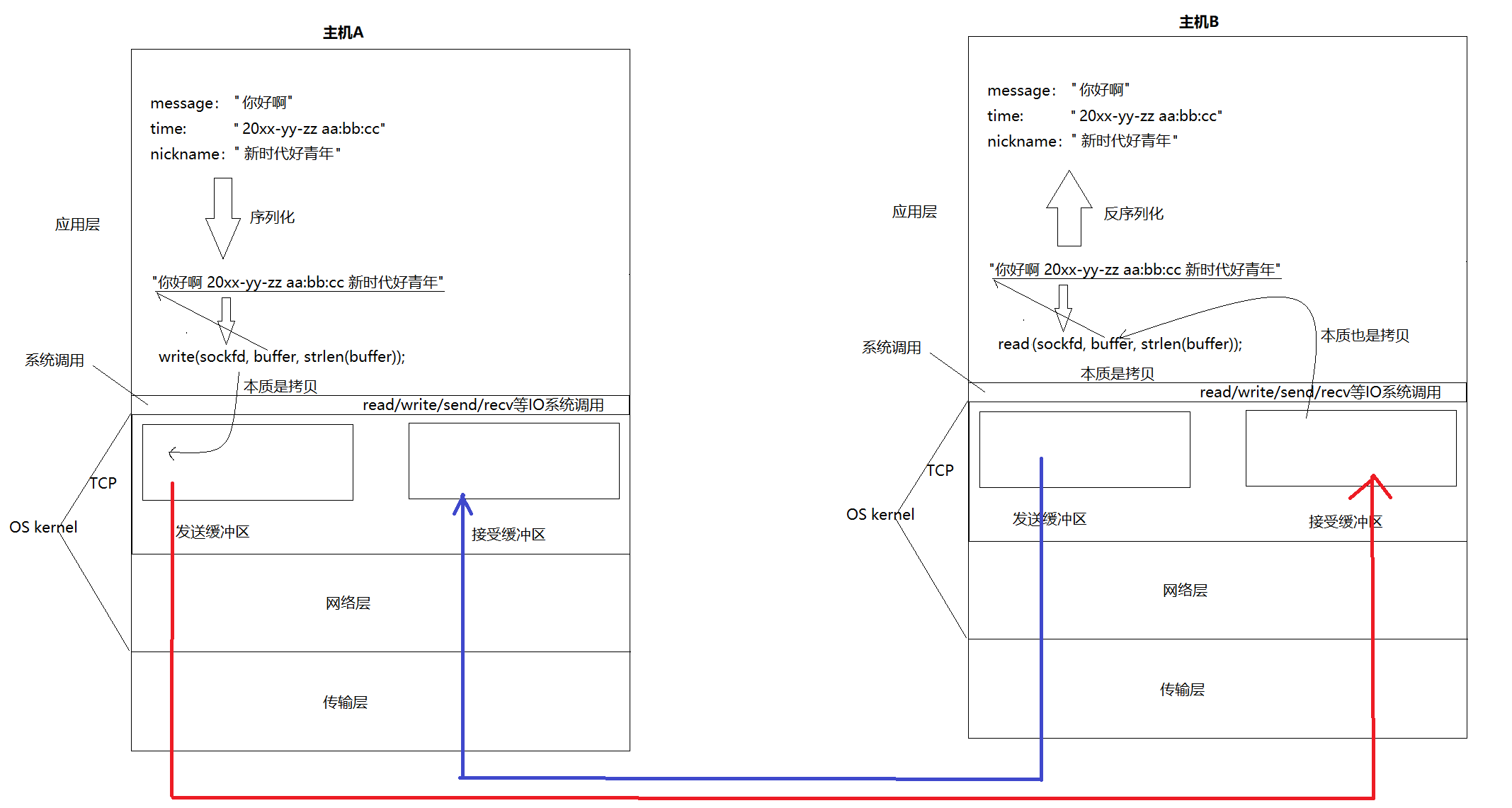
};那么,报文的报头和正文内容,如何组织的?
data指针代表一个报文的开始 ,tail代表报文的结束 ,而报文=报头+有效载荷。每经过一层网络协议栈,添加报头就是让data指针移动对应协议头大小的空间。所谓的封装和解包,本质就是在移动data指针在缓冲区中的位置。
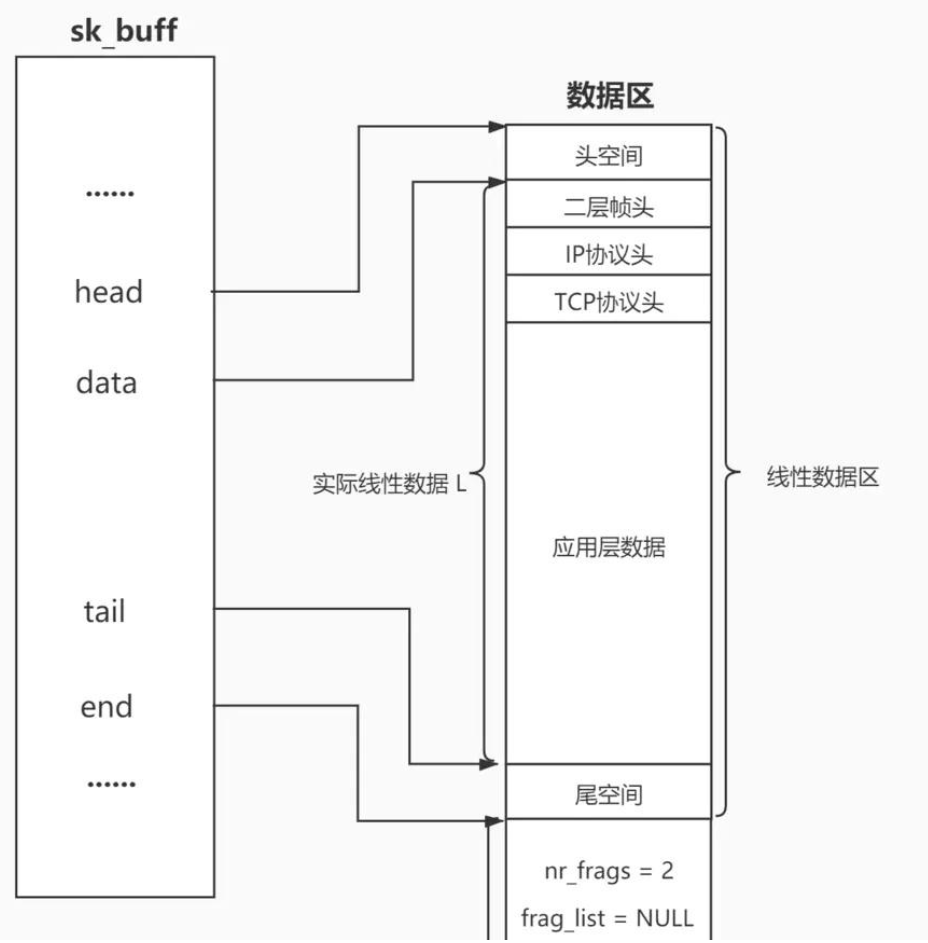
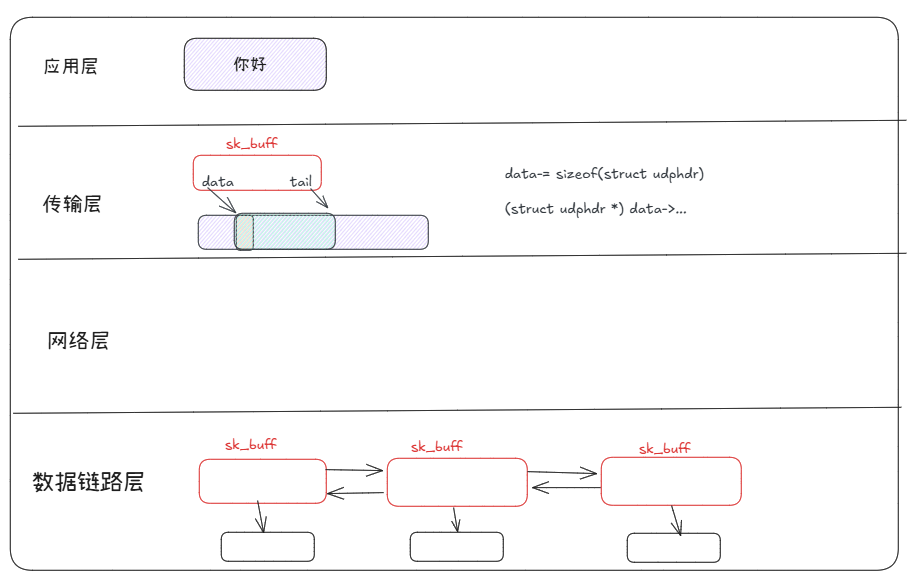
例如:从应用层发一条信息到传输层:也就是说,报文的传递本质上是skbuff在一层一层的流动。
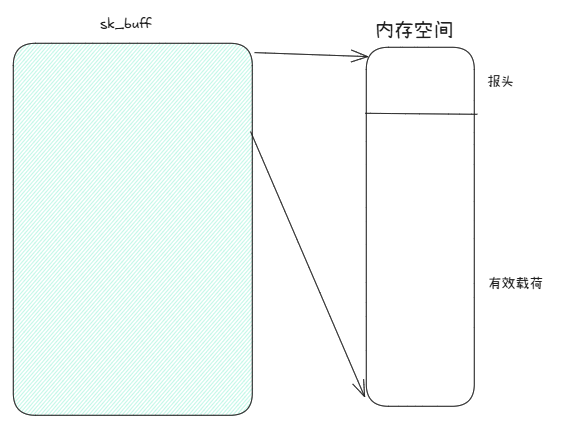
内核对于一个报文的组织 ,实际上是sk_buff+内存空间的内容!那么是如何关联到内存空间的?由sk_buff中的指针完成。
由此,就可以对操作系统每一层的报文通过某种数据结构进行管理了
4.TCP协议
TCP即传输控制协议。
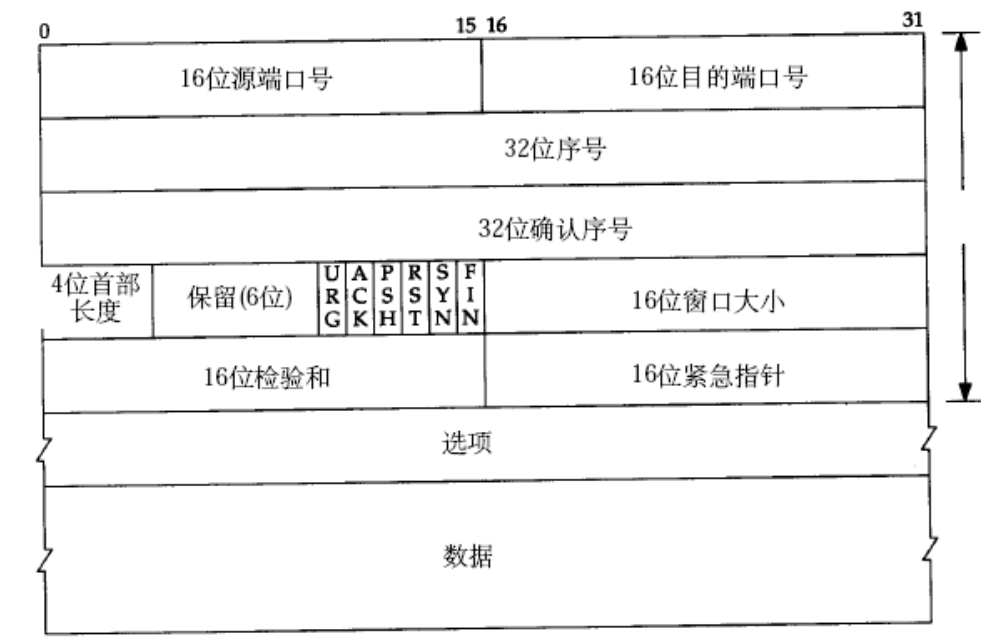
TCP报文:
1.报头字段与原理
报头和有效载荷的分离:报头的标准长度是20字节------也是定长!
如何交付?通过报头的源端口 和目的端口实现。
在20字节报头中,有一个4位首部长度 :指的是报头的长度,且包含选项的长度。但是四位,最多只能标识0-15,而我们的TCP报头最短也是20字节!这是为什么?所以这里的4位,单位长度为4字节!也就是说,实际上的范围是20-60字节!而不是0-15!这个标准由协议约定。同样地,我们不难算出最小值是5,在四位首部中,就应该写5-15。
那么报头和有效载荷如何分离?
先读20字节,然后读取4位首部长度,再乘4,减去二十,就得到了选项的长度,剩下的就是有效载荷。
问题:为什么再TCP中,没有包含整个报文大小,只有报头大小?
实际上,操作系统并不明确TCP报文的边界。对于TCP报文面向字节流,是没办法也不能设置报文大小的字段的。具体的数据部分究竟是否是一个完整报文,由上层读取报头进行分析。
在接收缓冲区中已经是被去掉报头的有效载荷了,数据和数据之间会粘包,但是数据不可能和其他报文的报头粘包。
2.TCP可靠性的本质
就比如:客户端说了消息1:你吃饭了吗?此时服务端收到了消息1,为了让客户端知道自己收到了消息1,所以回消息2:我吃了!客户端此时收到消息2,就确定了服务端一定收到了消息1.所以回消息3给服务端:好的!服务端收到消息3,确定客户端一定收到了消息2。
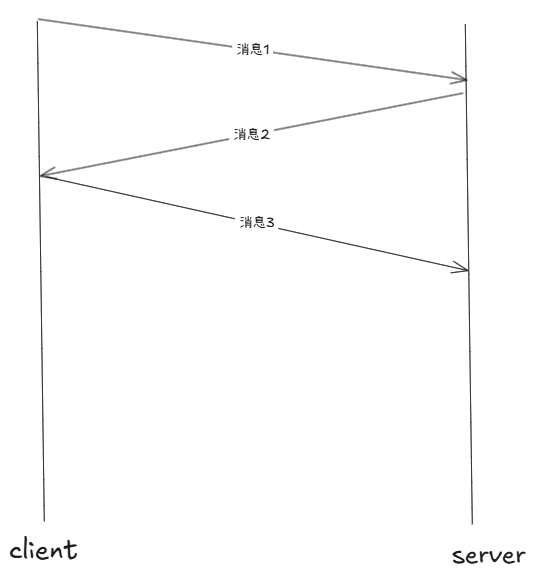
问题:为什么此时服务端不再回消息4,标识自己确实受到了消息3?这其实侧面反映出,世界上不存在绝对可靠 的协议。虽然消息3永远不会有回应,但是历史的所有消息能够百分百确定接收的。
也就是说:可靠性就是
1.具有应答,保证历史消息的可靠性
2.通信中,最新的报文永远没有应答,只有最新消息的可靠性无法保障。
如果要保证可靠性,TCP处于核心地位的就是确认应答机制!
3.TCP的一般通信过程
client给server发消息,server一定会给client发应答,而且是操作系统层面的自动完成的工作。这样就保证了从client到server发送消息的可靠性。如果,server也要给client发消息,client也需要做应答。但是,我们不对应答做应答。这一过程保证了server对client发送消息的可靠性。
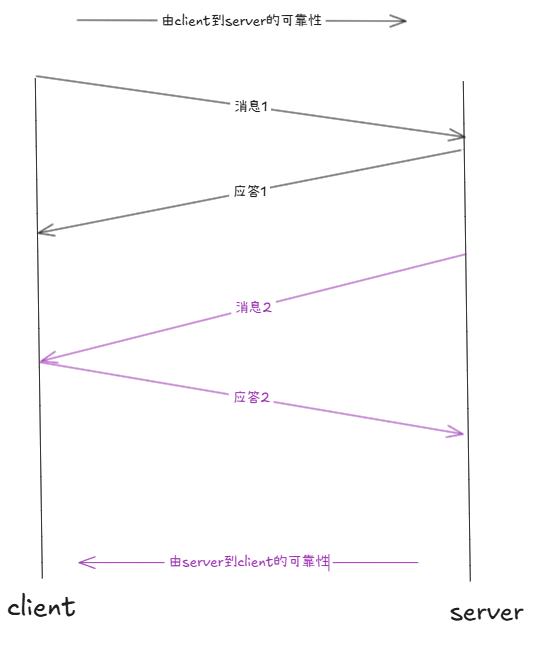
TCP在传递报文的时候,更通用的过程:以客户端向服务器发报文为例
实际上客户端可以一次发送多个消息,而服务器对每个消息做应答。
基于序号 的确认:32位序号,32位确认序号。这样我们就能区分哪些报文丢失,哪些报文正常发送。确认序号,往往是对应的序号+1。指定报文序号之前的所有信息,已经全部收到。这样的好处就是允许少量的应答报文丢失。
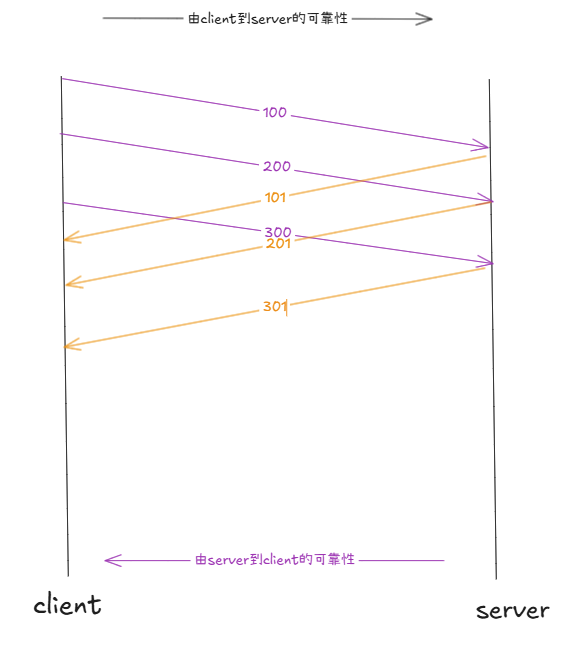
问题:发送时按照100,200,300,400发送,应答时一定会按顺序应答吗?
不一定,因为根据路由选择的问题等等。接收段的乱序问题,是一种不可靠的问题。而如今有了序号,可以根据序号进行排序,在一定程度上解决乱序问题。
我们发报文发的就是TCP报文,其中由对应的有32位序号;而应答一般不携带数据,只有报头。
问题:为什么在TCP报头中,设定了32位序号和确认序号?为什么要分开呢?
比如客户端给服务端发消息,而服务端应答时,实际上可以携带自己的数据。双方互发消息,真实的情况应该是下面的情况:应答和数据合并,效率更高。
问题:为什么TCP报头中既有32位序号,也有32位确认序号?这个工作不能只用一个来完成吗?
所谓的应答,只是一个报头;而数据就是有效载荷。如果捎带应答,代表着上一条消息服务端已收到,那么这里的两个序号,就是为了解决这种捎带问题 的场景。因为应答报文中:既有对上个报文的确认 ,同时还有自身报文的序号,两个序号就会被同时使用。
4.流量控制机制与滑动窗口
一台主机的接收数据能力,由接收缓冲区中的剩余大小决定。
现实的问题:如果发送端发送数据太快,客户端会怎样?因为接收缓冲区有限,所以这种情况会直接丢弃 。这样的处理方法原则上来说没问题,但不够合理。那么我们能不能,把接收和发送数据的这种能力,提前'预知'呢?
这就是报文的报头中16位窗口大小的作用。
如果客户端要给服务端发消息,就需要知道服务端接收缓冲区剩余空间的大小,反之亦然。要将数据据按量按需发送,必须知道对方的接收缓冲区中剩余空间的大小。窗口大小的数值,就代表着自己的接收缓冲区 剩余空间大小(要让对方知道自己的空间大小),而对方的大小通过应答报文得知。
注意:流量控制,是让发送数据变得合理,不是单纯的快慢问题。
5.报头中的标志位
可以看到,在我们的标准教材中有六个标志位。
实际上这些标志位,就是内核报头中的比特位:
cpp
unsigned int len,
data_len,
mac_len,
csum;
__u32 priority;
__u8 local_df:1,
cloned:1,
ip_summed:2,
nohdr:1,
nfctinfo:3;
__u8 pkt_type:3,
fclone:2,
ipvs_property:1;
__be16 protocol;问题:为什么要有标志位?
在申请建立TCP连接时,会发起申请连接的报文。这些报文不以传送数据为请求,而是请求连接。同样地,断开连接也是一样的------信息有类别之分。
接收方会根据不同类别的TCP报文,给予不同的处理并回应。而标志位就标识了TCP报文的类型。
从功能角度,每个标志位具体有什么作用?
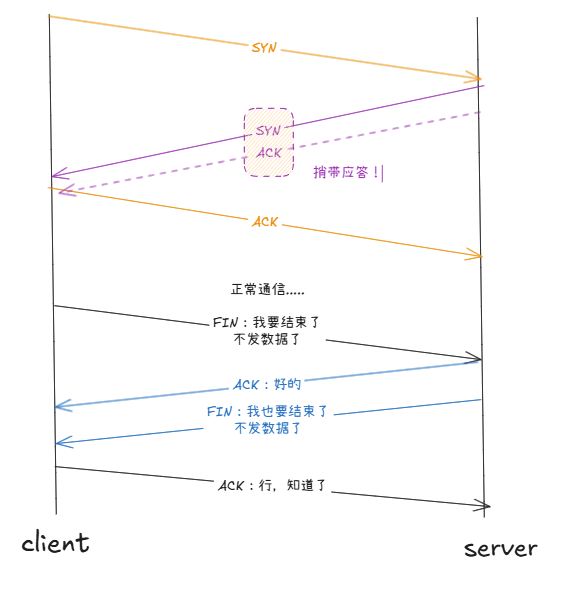
SYN:涉及到建立连接的三次握手。先来浅谈三次握手
客户端SYN:你要跟我建立链接吗?
服务端SYN+ACK:好的,什么时候开始?
服务端ACK:就现在。
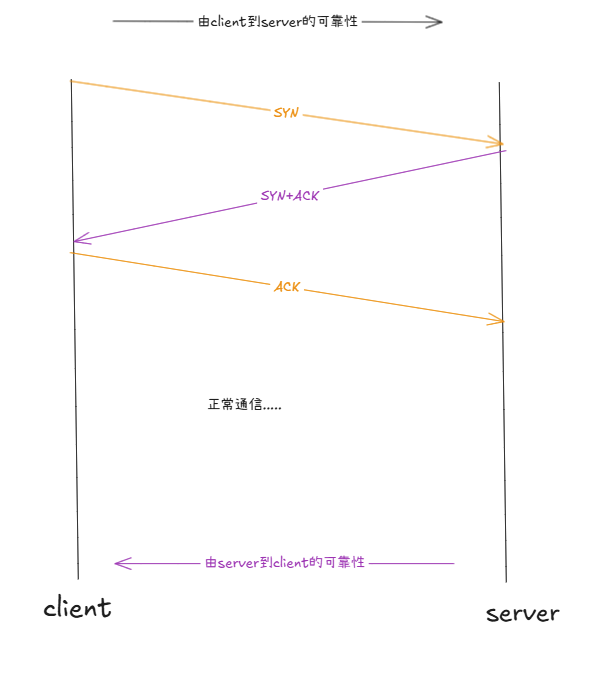
前两次握手,不能携带数据!只有TCP报头!
在握手阶段,就交换过双方的数据接受能力 了。在报头中,ACK表明报文是一个应答报文,并且ACK标志位几乎是被常设为1的。
断开连接:四次挥手。建立连接时往往需要一方主动 发起请求,而断开连接需要征求双方意见 。四次挥手的过程就是保证了:我们跟对方断开连接的请求被可靠收到。
我要跟你断开连接:FIN,收到:ACK。
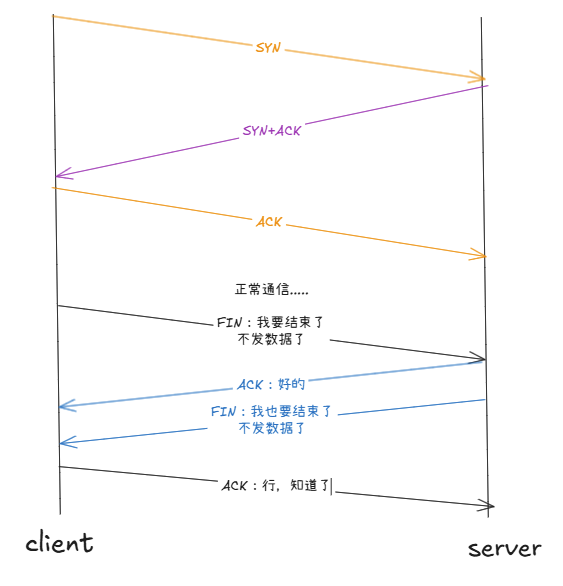
PSH:要求对端的接收缓冲区数据尽快交付上层,本端要继续发数据了。
问题:如果应用层没有读取的接口,PSH怎么工作?PSH只起到一个通知的作用,作为一个服务器没有读取数据的能力就是一种bug,与操作系统无关。
RST:对方要求重新建立连接,RST即复位报文段。因为建立连接不一定成功。
由于报文传输有时间差,尤其是对建立连接:会发生链接建立是否成功认知不一致的情况。当客户端发出ack时,客户端认为连接已经建立成功;而由于传输的时间差,服务端此时认为连接还未真正建立,但此时客户端就可能已经在发数据了!这样,服务端就会返回一个RST报文。
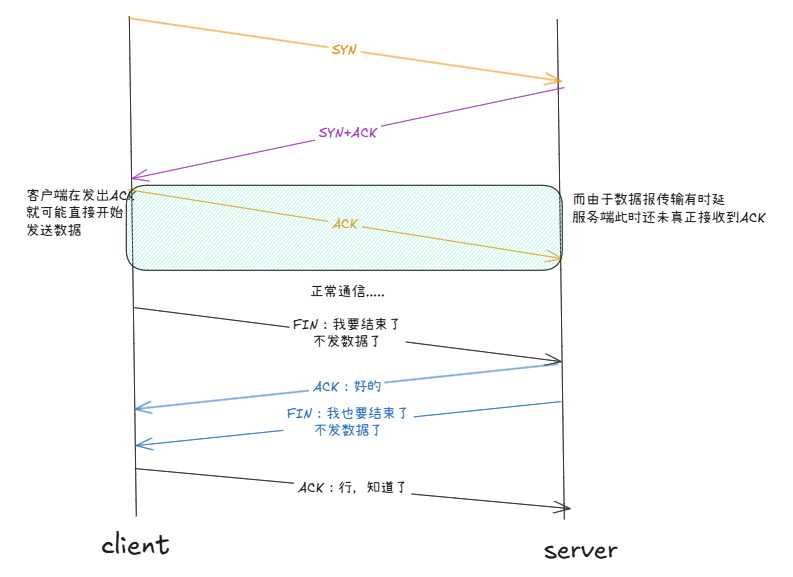
以上是一种较为极端的情况,这样的机制,也保证了连接出现任何问题,都可以进行重置。
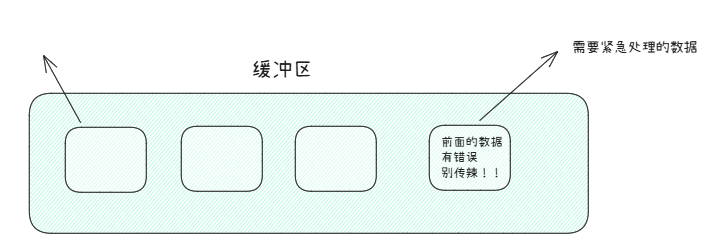
URG:若位0,代表16位紧急指针无效;若为1,则有效。在源码中,16位紧急指针表示urg_ptr。
TCP保证可靠性的序号,按需到达。对于接收缓冲区,我们把他看作字节流式的接收队列 。但是这样的结构也有问题,如果我们有数据想被优先处理的数据,却比较难办了。
那么,什么数据需要优先被处理?
比如说,传输数据时的"取消上传"报文。一般来说紧急数据并不属于常规的数据,我们也罢这种数据叫做带外数据。
16位紧急指针,标识当前报文的有效载荷中,特定偏移量处 有着紧急数据!因为它不能处于主流,因此只能占有一个字节 。这一个字节往往用来设置状态码 ,不同的数字标识不同的控制命令。
二.TCP相关机制
1.确认应答ACK机制
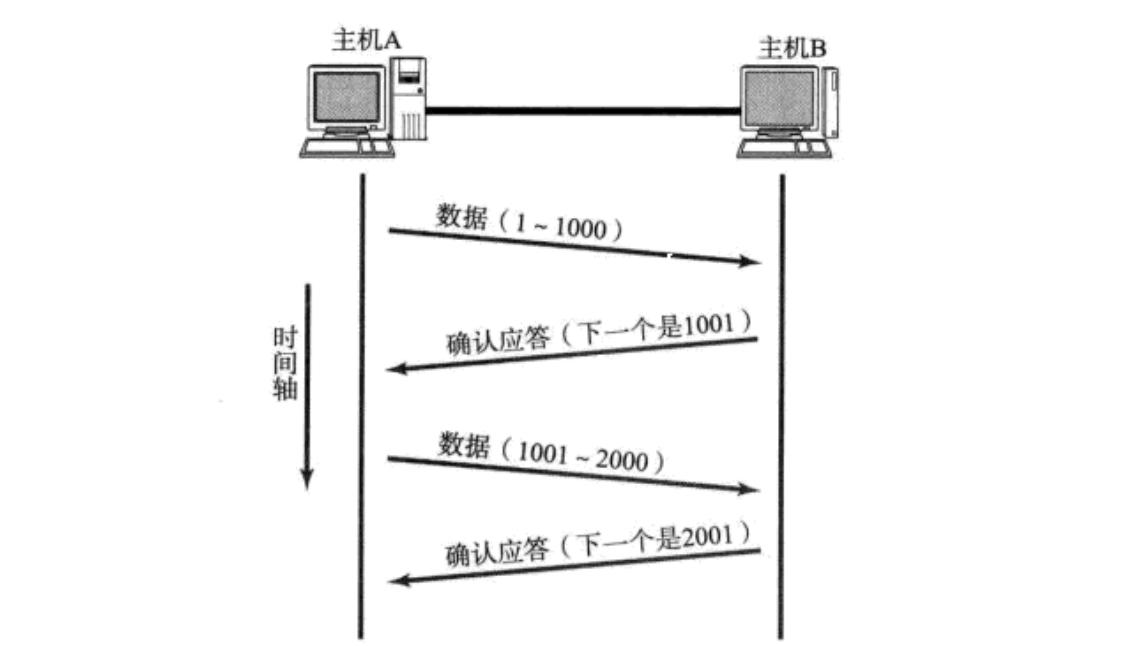
当发送应答报文时,就将ACK置为1.
一个重要的概念:什么叫做序号
我们可以把发送缓冲区,想象为一个char类型的数组。因此在缓冲区中,每一个字节都自带编号了。
2.超时重传机制
如何理解丢包,重新理解应答报文。
丢包的情况就两种:1.主机A给B发消息,发的消息丢了;2.主机B给A发送应答,应答丢了。
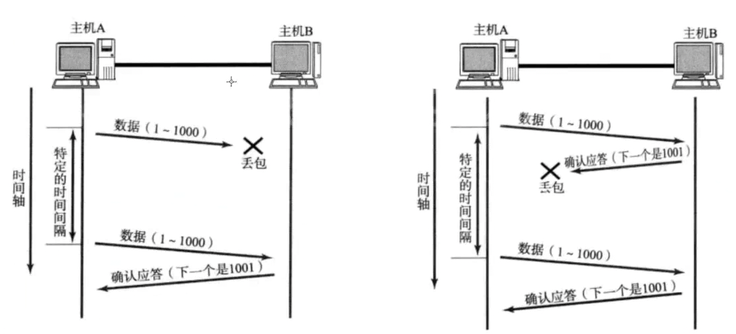
对于发送方,没有收到应答的ACK,意味着什么?是丢包吗?
只能意味着数据可能丢失,对方可能没收到------就比如第二种情况
收到应答,一定百分百收到消息了。
所以作为发送方,在当前情况下,实际上无法确认是数据丢还是应答丢(之后有解决办法)
于是客户端等待特定的时间间隔 ,如果在这个间隔内没收到应答,就判定报文丢失。------不一定是客观的报文丢失,也可能是应答丢失。这就是超时重传。
那么这个特定时间间隔,是多长?
这个时长应该是变化的------根据网络环境等因素。一般来说以500ms为基本单位(n*500ms)。
• 最理想的情况下, 找到⼀个最⼩的时间, 保证 "确认应答⼀定能在这个时间内返回".
• 但是这个时间的⻓短, 随着⽹络环境的不同, 是有差异的.
• 如果超时时间设的太⻓, 会影响整体的重传效率;
• 如果超时时间设的太短, 有可能会频繁发送重复的包;
TCP为了保证⽆论在任何环境下都能⽐较⾼性能的通信, 因此会动态计算这个最⼤超时时间.
• Linux中(BSD Unix和Windows也是如此), 超时以500ms为⼀个单位进⾏控制, 每次判定超时重发的超时时间都是500ms的整数倍.
• 如果重发⼀次之后, 仍然得不到应答, 等待 2*500ms 后再进⾏重传.
• 如果仍然得不到应答, 等待 4*500ms 进⾏重传. 依次类推, 以指数形式递增.• 累计到⼀定的重传次数, TCP认为⽹络或者对端主机出现异常, 强制关闭连接
收到重复报文怎么处理?序号来解决,直接丢弃重复报文。
序号作用:确认应答,按需到达,去重。
3.连接管理机制
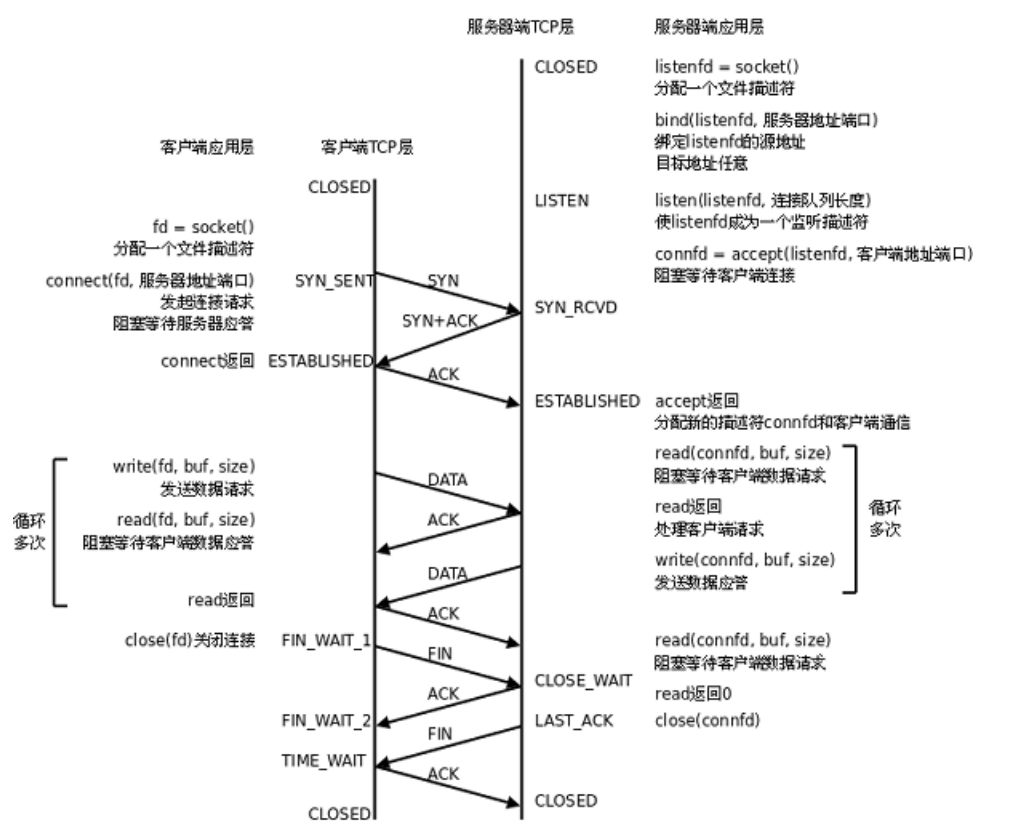
正常通信,都要通过三次握手建立连接。当要关闭连接时,就四次挥手断开连接。
实际上在进行握手和挥手,客户端和服务端的状态会改变。这个状态被描述为一个宏值。
服务器上一定会同时存在多个连接,它们的状态不同,这种连接也需要被管理。
建立连接需要成本------时间和空间
connect主动发起三次握手!这个过程由客户端的操作系统自动完成。
如果服务端不调用accept,能够正常发起三次握手建立连接吗?
accept不参与三次握手。整个过程由双方操作系统自动完成。
accept相当于将建立好的连接获取,并与它的返回值fd产生关联,便于使用。
问题:为什么要进行三次握手?
1.以最短的方式验证全双工。一次或者两次握手能验证吗?很显然不能。再多也没必要,因为三次已经足够了。
2.三次握手,本质上也是四次握手!只不过第二次做了捎带应答。包括挥手也是同样地道理.面对客户端的连接请求,服务器都要无脑接受。这样就以最小成本,验证了双方的通信意愿。