
【C++】深入拆解二叉搜索树:从递归与非递归双视角,彻底掌握STL容器的基石
- 摘要
- 目录
-
- 一、概念
- [二、 性能分析](#二、 性能分析)
- 三、key结构非递归模拟实现
-
- [1. 二叉搜索树的插入](#1. 二叉搜索树的插入)
- [2. 二叉搜索树的查找](#2. 二叉搜索树的查找)
- [3. 二叉搜索树的删除](#3. 二叉搜索树的删除)
- [4. 二叉搜索树的中序遍历](#4. 二叉搜索树的中序遍历)
- 四、key结构递归的模拟实现
-
- [1. 递归与非递归二叉搜索树核心操作的对比](#1. 递归与非递归二叉搜索树核心操作的对比)
- [2. 递归插入](#2. 递归插入)
- [3. 递归查找](#3. 递归查找)
- [4. 递归删除](#4. 递归删除)
- 总结
摘要
二叉搜索树(BST)是一种重要的数据结构,它通过"左子树所有节点值小于根节点,右子树所有节点值大于根节点"的特性实现高效的元素组织。本文详细解析了BST的核心概念、性能特点,并分别通过非递归和递归两种方式完整实现了插入、查找、删除等关键操作,深入探讨了指针引用在递归实现中的巧妙应用,以及两种实现方式在时间复杂度、空间复杂度和适用场景上的差异。
目录
一、概念
二叉搜索树(Binary Search Tree)又称二叉排序树,它可以是一颗空树,也可以是一颗具有以下性质的二叉树
- 若它的左子树不为空,那么它左子树上所有节点上的值均小于根节点的值。
- 若它的右子树不为空,那么它右子树上所有节点上的值均大于根节点的值。
- 它的左右子树也分别为二叉搜索树
- ⼆叉搜索树中可以⽀持插⼊相等的值,也可以不⽀持插⼊相等的值,具体看使⽤场景定义,后续我们学习map/set/multimap/multiset系列容器底层就是⼆叉搜索树,其中map/set不⽀持插⼊相等值 ,multimap/multiset⽀持插⼊相等值。
如图所示:
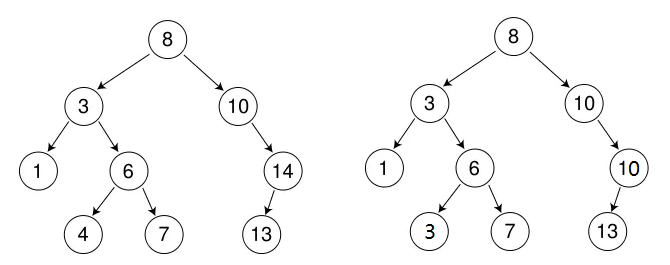
二、 性能分析
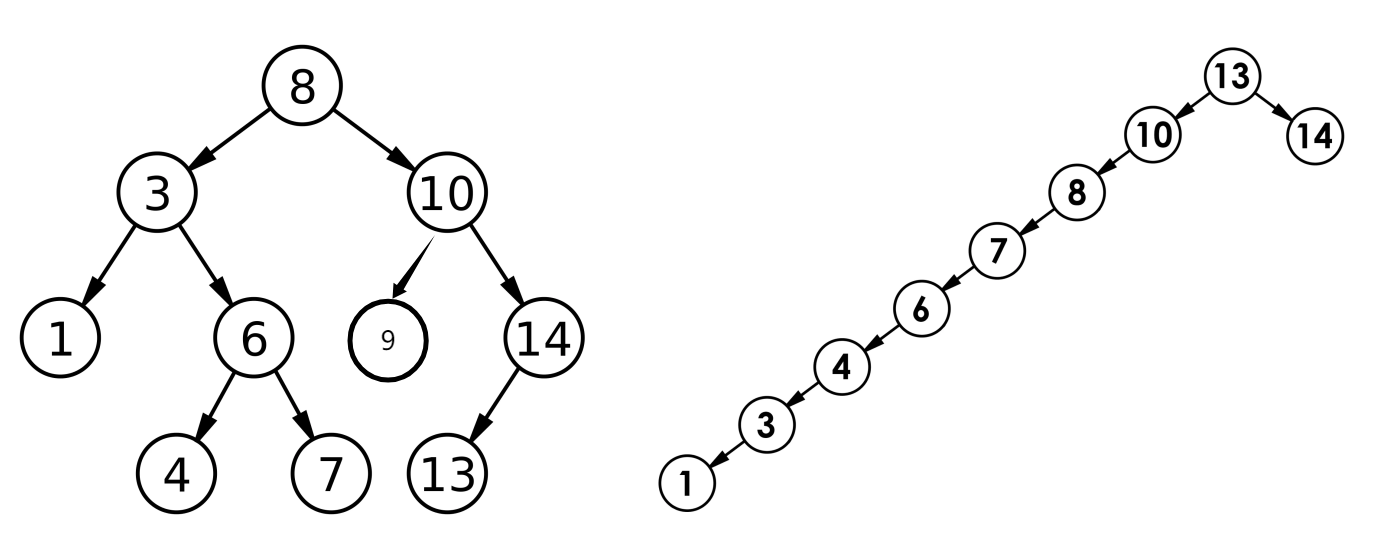
注意:左图为最好情况()完全二叉树,右图基本为最坏情况(单支二叉树)
其中AVL树和红黑树会在后续的文章中讲解。先了解一下就好。
| 对比维度 | 普通二叉搜索树 (BST) | AVL树(严格平衡) | 红黑树(近似平衡) |
|---|---|---|---|
| 核心定义 | 满足"左子树所有节点值 < 根节点值 < 右子树所有节点值"的二叉树,无平衡约束。 | 空树或左右子树高度差(平衡因子)的绝对值不超过1的二叉搜索树,是"严格平衡"的BST。 | 满足5条颜色规则(如根黑、叶黑、红父必黑等)的二叉搜索树,是"近似平衡"的BST。 |
| 平衡控制方式 | 无任何平衡机制,结构完全由插入顺序决定。 | 通过平衡因子(左高-右高) 监测平衡,失衡时执行四种旋转(LL、RR、LR、RL)调整。 | 通过节点颜色(红/黑) 和5条规则间接控制平衡,失衡时执行旋转+颜色翻转调整。 |
| 树高控制 | 高度不稳定:最优为完全二叉树(⌊log₂N⌋),最差退化为单支树(N)。 | 高度严格控制在O(log₂N),是所有BST中高度最矮的结构。 | 高度控制在2log₂(N+1) 以内,虽高于AVL树,但仍属于O(log₂N)级别。 |
| 时间复杂度 | - 查找/插入/删除:平均O(log₂N),最差O(N)(单支树时)。 | - 查找/插入/删除:均为O(log₂N)(平衡严格,无最差情况)。 | - 查找/插入/删除:均为O(log₂N)(平衡近似,无最差情况)。 |
| 调整成本 | 插入/删除无需调整结构,仅需找到位置后修改指针,成本极低。 | 插入/删除后可能触发多次旋转(最多2次),调整成本较高,但查找效率最优。 | 插入/删除后调整操作(旋转、变色)次数少(最多2次旋转),调整成本较低,更适合频繁修改。 |
| 适用场景 | 数据插入顺序接近有序时(如升序/降序插入)极易退化,仅适用于插入顺序随机、查询频率低的场景。 | 适用于查找操作远多于插入/删除的场景(如数据库索引),对查询效率要求极高。 | 适用于插入/删除操作频繁 的场景(如操作系统的进程调度、C++ std::map),追求综合性能均衡。 |
| 核心优势 | 实现简单,无额外平衡开销。 | 严格平衡,查找效率理论上最高。 | 平衡调整开销小,插入删除性能更优,实用性更强。 |
| 核心劣势 | 结构不稳定,最差性能等同于链表。 | 平衡调整频繁,插入删除性能开销大。 | 查找效率略低于AVL树,颜色规则和调整逻辑较复杂。 |
三、key结构非递归模拟实现
选择
struct定义节点结构体,是因节点需作为数据载体存储键值及左右子节点指针,且需被树类频繁访问,struct默认的public成员特性可简化操作;其构造函数采用const K& key的引用传参并结合const修饰,既能减少键值拷贝开销,又能避免数据被意外修改,同时通过初始化列表高效完成成员初始化。而用class定义二叉搜索树类,是因树类作为逻辑管理者,需封装根节点这一核心入口,class默认的private成员特性可隐藏根节点细节,仅通过公共接口对外提供安全操作,既符合封装原则,整体设计兼顾了访问效率、性能优化与数据安全性。
cpp
#include<iostream>
using namespace std;
namespace dh
{
//模板声明,K为节点中存储的键值类型
template<class K>
//定义节点结构体
struct BinarySearchTreeNode
{
//将这个节点结构体模板重命名(更简洁)
typedef BinarySearchTreeNode<K> BSTNode;
BSTNode* _left;//指向左子节点指针
BSTNode* _right;//指向右子节点指针
K _key;
// 构造函数:初始化节点,键值为传入的 key,左右子节点初始化为空
BinarySearchTreeNode(const K& key)
:_left(nullptr)
,_right(nullptr)
,_key(key)
{ }
};
//模板声明,与节点键值类型保持一致
template<class K>
//二叉搜索树类
class BinarySearchTree
{
public:
// 在树类内部定义节点别名(简化访问)
typedef BinarySearchTreeNode<K> BSTNode;
//构造函数:初始化树为空树
BinarySearchTree()
:_root(nullptr)
{ }
private:
//树的根节点(整个树的入口)
BSTNode* _root;
};
}1. 二叉搜索树的插入
插入规则:
二叉搜索树的插入需遵循 "左小右大、无重复键" 原则,首先判断树是否为空,若为空则直接创建新节点作为根节点;若不为空,则以根节点为起点,将插入节点的键值与当前节点键值比较:若小于当前节点键值,则前往其左子树继续比较;若大于当前节点键值,则前往其右子树继续比较;重复此过程,直到找到空节点位置,在此处创建新节点并链接到其父节点的对应指针上(左或右)。
注意:
- 二叉搜索树不允许重复键,若比较中发现键值相等,直接终止插入并返回失败;
- 遍历过程中需记录当前节点的父节点,以便在找到空位置后,将新节点正确链接到父节点的左或右指针上,确保树结构的完整性。
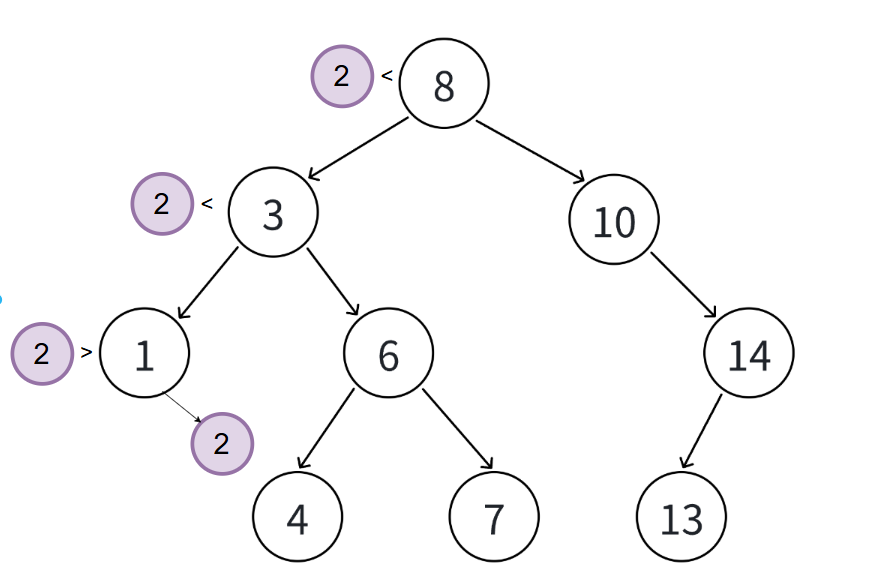
cpp
//判断树是否为空并执行相应操作
bool Insert(const K& key)
{
if (_root == nullptr) { _root = new BSTNode(key); }
else
{
BSTNode* parent = nullptr;//记录父节点
BSTNode* cur = _root;//从根节点开始比较遍历
while (cur != nullptr)
{
if (key > cur->_key)
{
parent = cur;//更新父节点
cur = cur->_right;
}
else if (key < cur->_key)
{
parent = cur;//更新父节点
cur = cur->_left;
}
else
{
return false;//如果插入键值相同返回错误
}
}
if (key > parent->_key) { parent->_right = new BSTNode(key); }
else { parent->_left = new BSTNode(key); }
}
return true;
}2. 二叉搜索树的查找
查找规则:
大于根" 的特性:先让 cur 指针指向根节点,若 cur 为空直接返回查找失败;非空则用目标 key 与 cur 的键值比较,key 相等则成功,key 更大就让 cur 指向右孩子,key 更小就指向左孩子,重复此比较和指针移动步骤,直到 cur 为空(失败)或找到相等值(成功),过程中需注意每次比较后必须更新 cur,且仅读取节点不修改树结构,时间复杂度为 O (h)(h 为树高,平衡树时接近 O (log n))。
cpp
//查找函数
bool Find(const K& key)
{
BSTNode* cur = _root;
while (cur != nullptr)
{
if (key > cur->_key) { cur = cur->_right; }
else if (key < cur->_key) { cur = cur->_left; }
else { return true; }
}
return false;
}3. 二叉搜索树的删除
删除规则:
- 删除无孩子节点(叶子节点):首先通过cur指针从根节点开始查找目标节点,同时用parent指针跟踪cur的父节点(每次cur移动时,parent同步更新为当前cur的位置)。当找到目标节点(cur的key与待删key相等)且其左右孩子均为空时,根据cur是parent的左孩子还是右孩子,将parent对应的左指针或右指针置空,随后释放cur节点的内存。这一步的核心是通过parent指针直接断开与目标节点的链接,因目标节点无孩子,无需额外处理子树衔接。
- 删除只有一个孩子的节点:同样先定位目标节点cur及父节点parent。若目标节点只有左孩子(右孩子为空),则根据cur是parent的左孩子还是右孩子,将parent的左指针或右指针直接指向cur的左孩子;若目标节点只有右孩子(左孩子为空),则让parent的对应指针指向cur的右孩子。完成指针重定向后,释放cur节点内存。此过程通过parent直接链接目标节点的唯一子树,确保树的连续性不被破坏。
- 删除有左右两个孩子的节点:先确定目标节点cur及父节点parent,由于直接删除会导致左右子树无法妥善衔接,需采用替代法:选择cur左子树中最右侧的节点(左子树最大值,记为subMax)或右子树中最左侧的节点(右子树最小值,记为subMin)作为替代节点(这两类节点最多只有一个孩子,便于后续删除)。将替代节点的key复制到cur中,再按照前两种情况删除替代节点------若替代节点是叶子,直接通过其parent断开链接;若有唯一孩子,则让其parent指向该孩子。最终释放替代节点内存,既删除了目标值,又维持了二叉搜索树"左小右大"的特性。
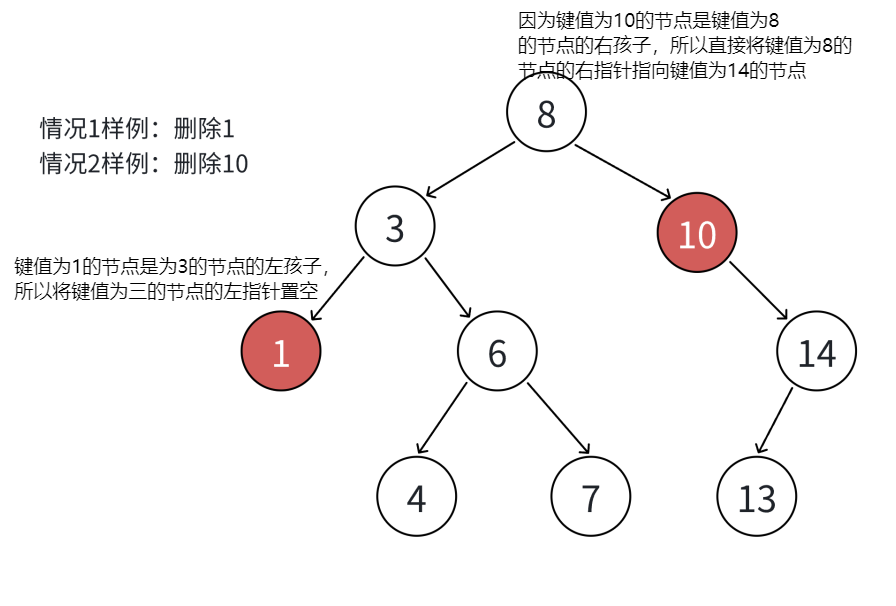
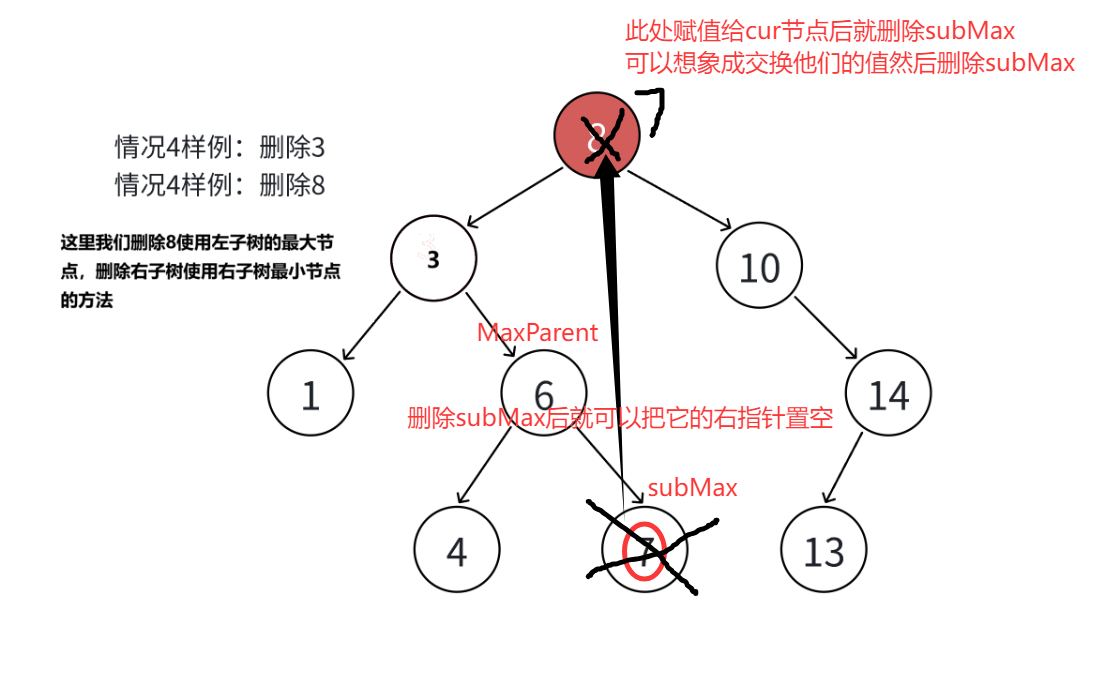
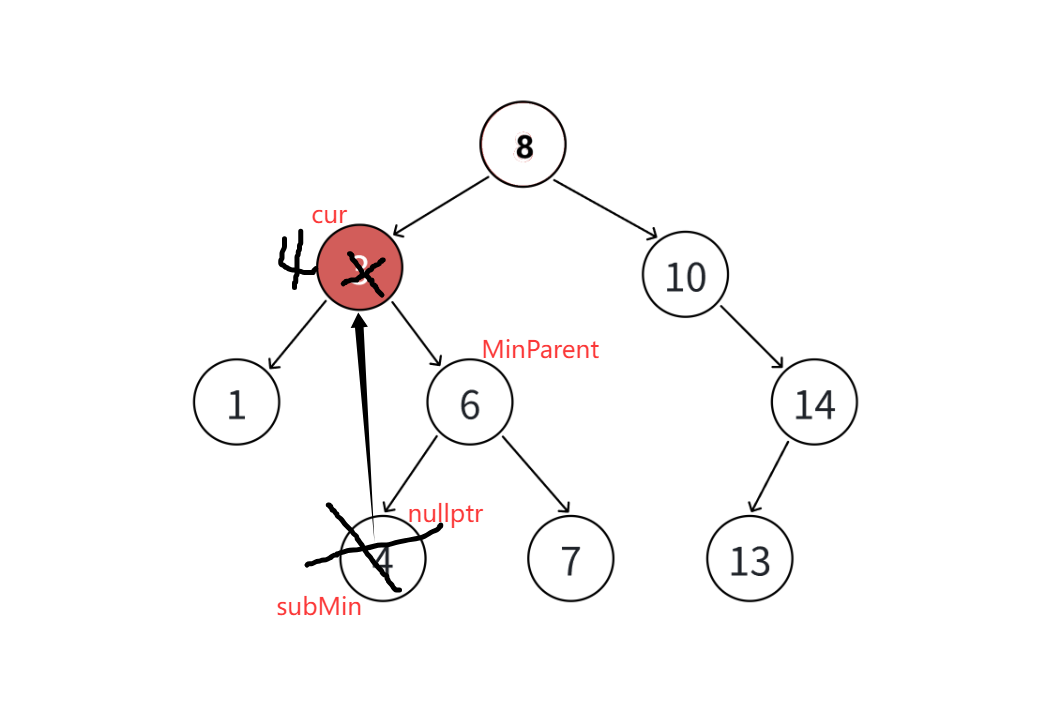
cpp
//二叉搜索树的删除
bool Erase(const K& key)
{
BSTNode* parent = nullptr;
BSTNode* cur = _root;
while (cur != nullptr)
{
if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else if (key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
//查找到需要删除的节点
else
{
//目标节点的右孩子为空
if (cur->_right == nullptr)
{
//目标节点的父节点为空,目标节点是根节点,删除后它的左孩子变成新的根
if (parent == nullptr) { _root = cur->_left; }
//目标节点不是根节点
else
{
//目标节点是父节点的右孩子
if (key > parent->_key) { parent->_right = cur->_left; }
//目标节点是父节点的左孩子
else { parent->_left = cur->_left; }
}
}
//目标节点的左孩子为空
else if (cur->_left == nullptr)
{
//cur是根节点
if (parent == nullptr) { _root = cur->_right; }
//cur不是根节点
else
{
//目标节点是父节点的右孩子
if (key > parent->_key) { parent->_right = cur->_right; }
//目标节点是父节点的左孩子
else { parent->_left = cur->_right; }
}
}
//左右子节点均存在(这里采用左子树最大节点替换法)
//这里的最大节点只有两种可能:
//没有节点 有一个左子节点 不可能有右子节点
else
{
BSTNode* SubMaxParent = cur;
BSTNode* SubMax = cur->_left;
//查找到左子树最大节点和它的父节点
while (SubMax->_right != nullptr)
{
SubMaxParent = SubMax;
SubMax = SubMax->_right;
}
//把SubMax赋值给目标节点(进行替换)
cur->_key = SubMax->_key;
//进行删除
//如果SubMaxParent是cur,说明submax是cur的直接左孩子
if (SubMaxParent == cur) { SubMaxParent->_left = SubMax->_left; }
//submax是submaxparent的右孩子
else { SubMaxParent->_right = SubMax->_left; }
//转移删除节点指针的目标
cur = SubMax;
}
delete cur;
return true;
}
}
return false;
}4. 二叉搜索树的中序遍历
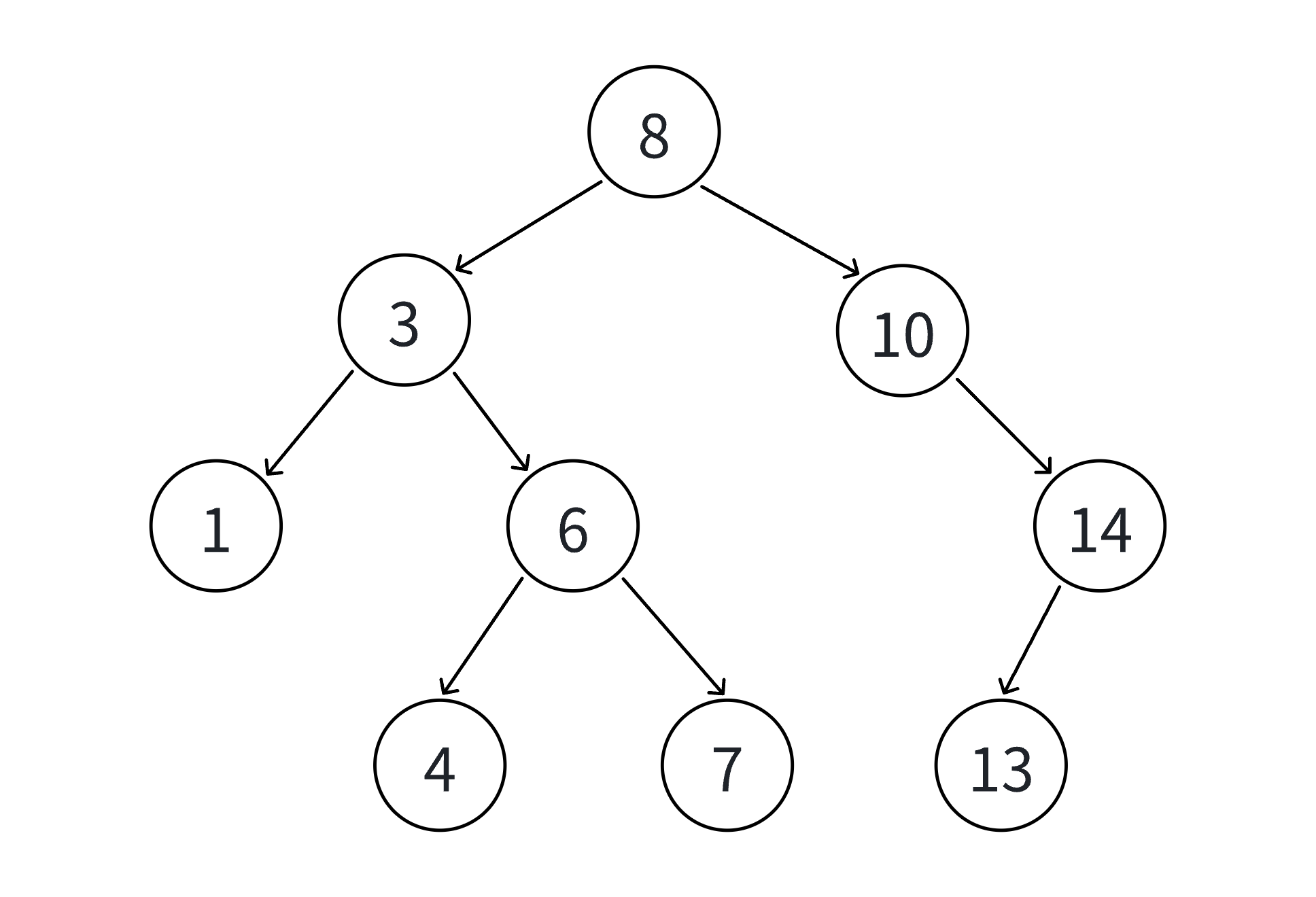
对这幅图中的二叉搜索树使用中序遍历进行遍历我们可以得到1、3、4、6、7、10、13、14我们发现刚好是一个有序的升序,所以二叉搜索树同时也可以称之为二叉排序树。
- 二叉搜索树中序递归遍历的核心矛盾是"类外无法访问私有根节点"与"递归需要节点指针参数",最优解是设计"公有接口+私有子遍历函数"的双层结构:公有函数作为类外调用入口,无需参数,仅负责判断根节点是否为空,非空则将私有根节点
_root传入私有子遍历函数,打通递归初始入口。- 私有子遍历函数的参数为节点指针
BSTNode*,专门承载递归过程中的当前节点,逻辑严格遵循中序规则:先判断传入节点是否为空(空则返回,终止递归),再调用自身传入当前节点的左指针(遍历左子树),接着访问打印当前节点值(处理根),最后调用自身传入当前节点的右指针(遍历右子树)。- 这种设计无需单独写函数暴露根节点(保证类的封装性),也满足递归对节点指针的控制需求,类外调用仅需一行代码(如
tree.InOrder()),既解决了访问权限问题,又让递归逻辑清晰分层,避免冗余且易用。
cpp
public:
// 1. 公有接口函数(类外调用入口)
void InOrder()
{
// 空树直接返回,调用私有子遍历函数并传入根节点
_InOrder(_root);
}
private:
//树的根节点(整个树的入口)
BSTNode* _root;
// 2. 私有子遍历函数(负责递归逻辑)
void _InOrder(BSTNode* cur)
{
// 递归终止:当前节点为空,无需遍历
if (cur == nullptr)
return;
// 中序遍历:左→根→右
_InOrder(cur->_left); // 先遍历左子树
cout << cur->_key << " "; // 访问当前节点(可替换为其他处理逻辑)
_InOrder(cur->_right); // 再遍历右子树
}四、key结构递归的模拟实现
1. 递归与非递归二叉搜索树核心操作的对比
- 在实现二叉搜索树的核心操作时,递归形式的插入、查找、删除函数需要通过控制节点来推进递归流程。这一过程与中序遍历类似,都需借助子函数实现,因此我们将这些子函数设为private 访问权限,避免用户直接调用;同时将对外提供服务的函数设为public 访问权限,作为用户可调用的接口。
- 为了统一管理递归与非递归两种实现,我们将它们置于同一个命名空间下。为清晰区分二者,所有递归函数的名称后会统一添加 "R" 作为标识,例如非递归插入函数名为 Insert,对应的递归版本则命名为 InsertR。
- 递归实现的优势在于无需额外寻找父节点,逻辑更简洁,代码编写难度较低。但它也存在明显局限:当树的深度过大、递归调用次数过多时,会增加栈溢出的风险,这是在选择实现方式时需要重点权衡的问题。
| 对比维度 | 递归实现(带R标识) | 非递归实现 |
|---|---|---|
| 实现逻辑 | 依赖函数递归调用推进,通过子节点自然传递状态 | 借助循环和指针手动控制遍历路径,需显式记录节点 |
| 父节点处理 | 无需单独记录父节点,递归参数直接传递当前节点 | 需额外维护指针跟踪父节点,用于修改链接关系 |
| 代码复杂度 | 逻辑简洁,代码量少,可读性高 | 需处理循环边界和指针跳转,代码稍繁琐 |
| 性能与风险 | 递归调用压栈可能导致栈溢出(深度过大时) | 无栈溢出风险,内存占用更稳定 |
| 访问权限设计 | 递归子函数设为private,对外暴露public接口函数 | 直接通过public接口函数实现,无需私有子函数 |
| 适用场景 | 树深度较小时,追求代码简洁性 | 树深度较大或对稳定性要求高的场景 |
2. 递归插入
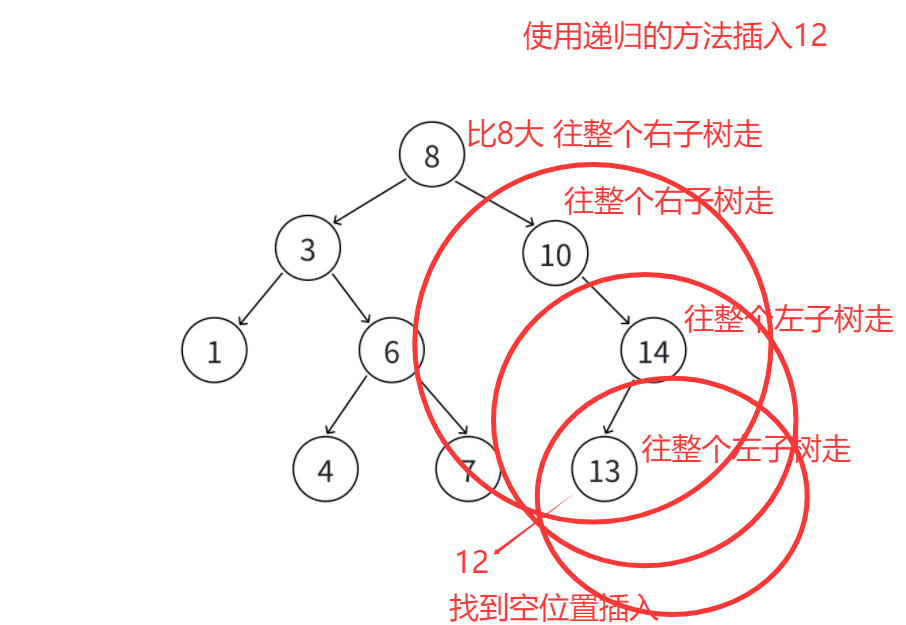
- 递归插入本质上只处理一种核心场景:找到二叉搜索树中"应该插入新节点的空位置"。无论是根节点为空(直接插入根节点),还是非空树中寻找插入点,最终都会落到"对空指针进行赋值"这一步------因为递归会一层层深入,直到找到符合条件的空节点位置。
- 这里的关键是指针引用的用法:当递归传入左/右子树指针时(比如
_InsertR(root->_right, key)),下一层栈帧中的root引用的正是当前节点的右指针。这种设计让新节点的创建(new Node(key))可以直接通过引用赋值给父节点的左/右指针,天然建立了链接关系,完全无需像非递归实现那样额外记录父节点。- 为什么非递归不能这么做?因为C++的引用一旦初始化就无法改变指向。非递归需要循环遍历寻找插入点,过程中需要不断切换指向不同节点的指针,而引用的"不可变指向"特性与此冲突。但递归场景中,每层栈帧的引用都是独立初始化的(分别指向层引用父节点的左指针,下一层可能引用另一个节点的右指针),互不影响,因此可以安全使用。
- 最后,递归过程中需通过
return将子函数的结果逐层传递:遇到相同key时返回false(插入失败),成功创建节点时返回true,最终将结果反馈给外层的InsertR接口。
cpp
public:
// 递归插入接口:对外提供的插入入口
bool InsertR(const K& key)
{
return _InsertR(_root, key); // 调用私有递归子函数
}
private:
// 递归插入子函数:实际执行插入逻辑(私有,仅内部调用)
// 参数 root:当前节点的指针引用,用于直接修改父节点的左/右孩子
bool _Insert(BSTNode*& root, const K& key)
{
if (root == nullptr) // 找到插入位置(空节点)
{
root = new BSTNode(key); // 创建新节点并通过引用绑定到父节点
return true;
}
// 根据key大小递归查找插入位置
if (key > root->_key)
return _Insert(root->_right, key); // 插入右子树
else if (key < root->_key)
return _Insert(root->_left, key); // 插入左子树
else
return false; // key已存在,插入失败
}3. 递归查找
cpp
//递归查找
public:
// 递归查找接口:对外提供的查找入口
bool FindR(const K& key)
{
return _FindR(_root, key); // 调用私有递归子函数
}
private:
// 递归查找子函数:实际执行查找逻辑(私有,仅内部调用)
// 参数 root:当前节点的const指针引用(避免修改节点,提高安全性)
bool _FindR(const BSTNode*& root, const K& key)
{
if (root == nullptr) // 递归终止条件:节点为空,未找到key
return false;
// 根据BST特性递归查找
if (key > root->_key)
return _FindR(root->_right, key); // 去右子树查找
else if (key < root->_key)
return _FindR(root->_left, key); // 去左子树查找
else
return true; // 找到匹配key
}注意:此处子函数可以使用节点指针引用作为参数,因为不需要要父亲节点(不需要查找或者删除节点)
4. 递归删除
- 二叉搜索树递归删除的核心巧妙之处,在于用指针引用(
BSTNode*& root)替代了非递归中手动追踪父节点的操作。当调用递归子函数时,参数root会天然绑定父节点的左指针或右指针------比如查找右子树时,root实际引用的是上层节点的_right指针,这就意味着找到目标节点后,无需额外记录父节点,直接通过root就能修改父节点与目标节点的链接关系,从根源上简化了逻辑。- 递归删除的流程可以分为三大场景,和非递归逻辑一致但实现更简洁。第一种场景是目标节点右子树为空,此时先用
delNode暂存目标节点(避免后续修改root后丢失地址),再通过root = root->_left让左子树直接"上位",最后释放delNode即可;第二种场景是目标节点左子树为空,操作和第一种类似,只需将root指向root->_right,让右子树接替目标节点的位置,释放delNode后完成删除。- 最关键的是第三种场景:目标节点左右子树都不为空。 为了维持二叉搜索树的性质,需要先找到目标节点左子树的最大节点(即左子树最右侧的节点,记为
subMAX),把subMAX的_key覆盖到目标节点的_key上------这一步相当于完成了"值替换",将删除两个子节点的复杂场景,转化为删除左子树中maxNode的简单场景。由于subMAX是左子树的最大节点,它的右子树必然为空(最多只有左子树),此时不能直接删除subMAX(它只是局部变量,修改不会影响树的链接),也不能从整棵树根节点开始查找删除,而要从当前目标节点的左子树根节点(root->_left)开始递归,传入subMAX的_key作为查找条件,这样就能精准定位并删除subMAX,最终把复杂删除转化为只有一个或零个子节点的简单删除。- 整个过程中,递归的优势被体现得淋漓尽致:无需像非递归那样用
parent指针手动记录父节点,每一层栈帧的指针引用都会自动"记住"当前节点在父节点中的位置(左或右),既减少了代码冗余,也避免了手动维护父节点时容易出现的逻辑错误。
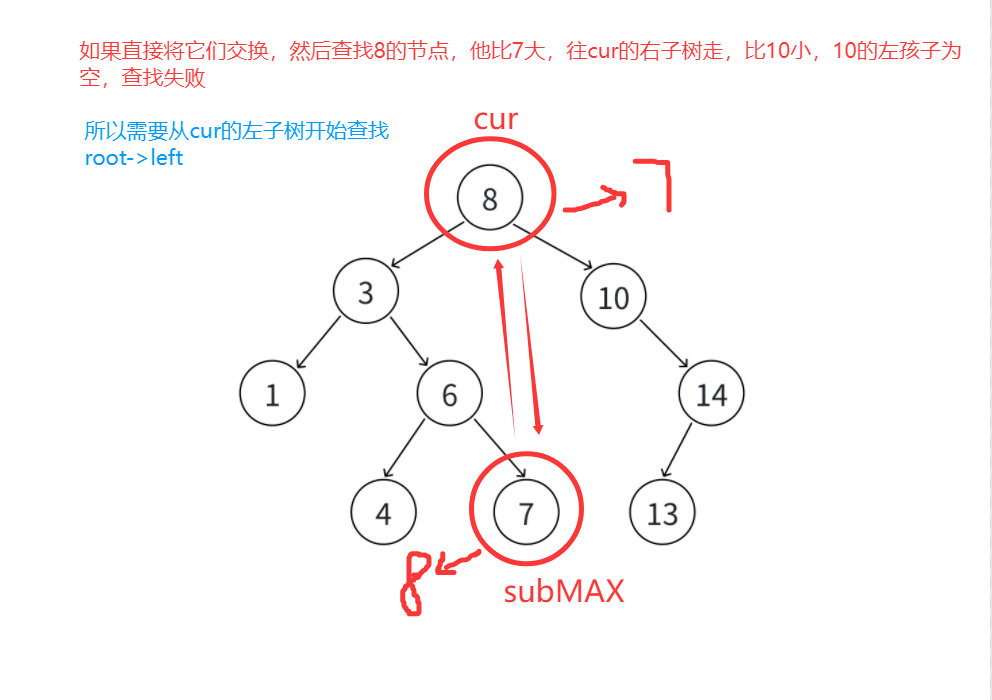
cpp
public:
//递归删除
bool EraseR(const K& key)
{
return _EraseR(_root, key);
}
private:
//递归删除节点子函数
bool _EraseR( BSTNode*& root, const K& key)
{
if (root == nullptr) { return false; }
if (key > root->_key) { return _EraseR(root->_right, key); }
else if (key < root->_key) { return _EraseR(root->_left, key); }
//查找到开始进行删除
else
{
//先储存根节点的值,避免修改root丢失地址
BSTNode* delNode = root;
//有一方为空子树的场景
if (root->_right == nullptr)
{
root = root->_left;
delete delNode;
return true;
}
else if (root->_left == nullptr)
{
root = root->_right;
delete delNode;
return true;
}
//左右都有子树的情景
else
{
BSTNode* subMAX = root->_left;
while (subMAX->_right)
{
subMAX = subMAX->_right;
}
root->_key = subMAX->_key;
return _EraseR(root->_left, subMAX->_key);
}
}
}总结
二叉搜索树作为基础而重要的数据结构,其价值在于通过简单的"左小右大"规则实现了元素的快速查找、插入和删除。非递归实现虽然代码稍显繁琐但性能稳定,适合处理深度较大的树;递归实现逻辑简洁但存在栈溢出风险,适用于树深度较小的场景。两种实现各有优劣,实际应用中应根据具体需求选择。理解BST的运作原理对于后续学习更复杂的平衡树结构(如AVL树、红黑树)具有重要意义,是数据结构学习道路上不可或缺的关键一环。
✨ 坚持用 清晰易懂的图解 + 代码语言, 让每个知识点都 简单直观 !
🚀 个人主页 :不呆头 · CSDN
🌱 代码仓库 :不呆头 · Gitee
📌 专栏系列 :
💬 座右铭 : "不患无位,患所以立。"
