文章目录
- [一、R-HORIZON 核心亮点](#一、R-HORIZON 核心亮点)
- 二、研究背景
-
- [2.1 测试时扩展的兴起与局限](#2.1 测试时扩展的兴起与局限)
- [2.2 当前训练与评估范式的关键局限](#2.2 当前训练与评估范式的关键局限)
- [2.3 关注的核心问题](#2.3 关注的核心问题)
- [三、R-HORIZON 方法论](#三、R-HORIZON 方法论)
-
- [3.1 R-HORIZON 数据集构建](#3.1 R-HORIZON 数据集构建)
-
- [3.1.1 数学任务](#3.1.1 数学任务)
- [3.1.2 代码任务](#3.1.2 代码任务)
- [3.1.3 智能体任务](#3.1.3 智能体任务)
- [3.2 R-HORIZON 基准测试](#3.2 R-HORIZON 基准测试)
- [3.3 基于 R-HORIZON 的强化学习](#3.3 基于 R-HORIZON 的强化学习)
- 四、实验与剖析
-
- [4.1 当前 LRM 在长周期推理场景中的表现评估](#4.1 当前 LRM 在长周期推理场景中的表现评估)
-
- [4.1.1 评估实验设置](#4.1.1 评估实验设置)
- [4.1.2 评估发现](#4.1.2 评估发现)
- [4.2 R-HORIZON 强化学习训练](#4.2 R-HORIZON 强化学习训练)
-
- [4.2.1 训练设置](#4.2.1 训练设置)
- [4.2.2 训练发现](#4.2.2 训练发现)
- [4.3 深度分析](#4.3 深度分析)
-
- [4.3.1 评估结果分析](#4.3.1 评估结果分析)
- [4.3.2 R-HORIZON 强化学习带来的改善](#4.3.2 R-HORIZON 强化学习带来的改善)
- 五、小结
原文链接:《R-Horizon: How Far Can Your Large Reasoning Model Really Go in Breadth and Depth?》
原文摘要 :近期,推理模型中的测试时扩展(test-time scaling)趋势(例如 OpenAI 的 o1 模型和 DeepSeek-R1)通过长链式思维(Chain-of-Thought, CoT)取得了显著进展。然而,现有的基准测试主要关注即时、单步任务,未能充分评估模型在复杂、长周期场景中的理解与应对能力 。为了解决大型推理模型(Large Reasoning Models, LRMs)在这一评估上的不足,我们提出了 R-HORIZON,一种通过查询组合激发 LRMs 长周期推理行为的方法 。基于 R-HORIZON,我们构建了一个长周期推理基准,包含复杂的多步推理任务,这些任务中的问题相互依赖,跨越较长的推理周期。通过对 LRMs 在 R-HORIZON 基准上的全面评估,我们发现即使是最先进的 LRMs 也出现了显著的性能下降。我们的分析表明,LRMs 的有效推理长度有限,并且在多个问题之间合理分配"思考预算"方面存在困难。针对这些局限性,我们利用 R-HORIZON 构建长周期推理数据,用于强化学习与验证奖励(RLVR)训练。与使用单周期数据训练相比,基于 R-HORIZON 的 RLVR 不仅显著提升了多周期推理任务的表现,还在标准推理任务上提高了准确率(在 AIME2024 上提升 7.5 分)。这些结果使 R-HORIZON 成为一种可扩展、可控且低成本的范式,用于增强和评估 LRMs 的长周期推理能力。
一、R-HORIZON 核心亮点
R-HORIZON 通过构建多步依赖的推理任务 ,首次系统揭示了当前推理模型在长周期推理 中的能力边界与失效原因,并提供了可扩展的训练与评估新范式。
- Query Composition 方法:创新性提出多Query嵌套方法,通过将上一个问题的答案与下一个问题中的关键信息建立关联,从而实现将独立任务转化为复杂多步推理场景;
- 全面评测基准:涵盖数学、代码生成、Agent 应用等 6 大数据集;
- 评测结果发现:观察到现有的推理模型在单程任务上表现突出,但在相同数据集构造的长程推理场景下效果显著下降,揭示 LRMs 的有效推理长度瓶颈、局部化反思机制、思考预算分配失衡等关键问题;
- 长程推理RLVR范式:基于 R-HORIZON 改进了RLVR的训练范式,在长程任务提升 +17.4 分的同时,单任务性能也提升 +7.5 分(AIME2024)。模型展现出更高效的思考路径规划能力,在长链推理中能更合理地分配"思考预算",显著改善反思与规划能力。
二、研究背景
2.1 测试时扩展的兴起与局限
- 测试时扩展(test-time scaling) 成为提升推理模型性能的新范式,代表模型如 OpenAI o1、DeepSeek-R1。模型通过生成更长的思维链(CoT)在数学、代码、智能体任务中取得显著性能提升。
- 然而,后续多项研究表明模型存在最优推理长度(Effective Reasoning Length),一旦 CoT 超过该长度,性能反而下降,并伴随"过度思考"现象,造成计算浪费。
2.2 当前训练与评估范式的关键局限
- 评估数据集仅关注孤立、单步推理任务 ,无法评估模型在多步、长周期、问题间依赖的复杂推理场景中的表现。
- 传统的强化学习方法通常也仅关注单个孤立问题,导致模型在训练过程中无法发展出应对多问题序列的长周期推理能力。
- 现实任务往往需要跨多个问题、长时间跨度的推理与规划,当前范式无法胜任。
2.3 关注的核心问题
在广度与深度两个维度上,大型推理模型(LRMs)究竟能走多远?
三、R-HORIZON 方法论
3.1 R-HORIZON 数据集构建
3.1.1 数学任务

采用顺序组合 方式,构建具有显式依赖关系的多步数学问题。构建流程分为两个阶段:
-
种子问题筛选(Seed Problem Filtering)
给定初始数据集 D = { ( q i , a i ) } i = 1 N \mathcal{D} = \{(q_i, a_i)\}{i=1}^N D={(qi,ai)}i=1N,应用以下筛选条件获得种子集合 D seed \mathcal{D}{\text{seed}} Dseed,其中 I ( ⋅ ) I(\cdot) I(⋅) 表示从输入文本中提取所有整数:
D seed = { ( q , a ) ∈ D ∣ ∣ I ( q ) ∣ > 0 ∧ a ∈ Z } \mathcal{D}_{\text{seed}} = \{(q, a) \in \mathcal{D} \mid |I(q)| > 0 \land a \in \mathbb{Z}\} Dseed={(q,a)∈D∣∣I(q)∣>0∧a∈Z}对于每个 ( q , a ) ∈ D seed (q, a) \in \mathcal{D}_{\text{seed}} (q,a)∈Dseed,进一步识别关键变量,其中 M ( q , m ) = 1 M(q, m) = 1 M(q,m)=1 表示若从问题中移除该整数,问题将变得不可解:
K ( q ) = { m ∈ I ( q ) ∣ M ( q , m ) = 1 } K(q) = \{m \in I(q) \mid M(q, m) = 1\} K(q)={m∈I(q)∣M(q,m)=1} -
扩展问题组合(Expanded Problem Composition)
基于种子问题及其关键变量构建依赖链 。确保每个新问题 q i + 1 ′ q_{i+1}' qi+1′ 包含一个占位变量 v i + 1 v_{i+1} vi+1,其值必须通过前一个问题的答案 a i a_i ai 计算得出:
v i + 1 = f i ( a i ) v_{i+1} = f_i(a_i) vi+1=fi(ai)即:将前一个问题的答案嵌入到后一个问题的条件中,从而建立问题间顺序依赖关系,模型必须按顺序正确解决所有问题才能得到最终答案。
3.1.2 代码任务
利用现有数据集中的数据作为组合的种子问题,采用直接组合的串联格式 ,不添加问题间的显式依赖关系。(因为代码任务需通过沙箱执行获取答案,难以构建问题与答案间的直接依赖)
3.1.3 智能体任务
基于 WebShaper 提供的结构化数据,将问题分解为"目标"(目标变量)和"变量"(中间变量)。每个问题均遵循以下处理流程:
- 筛选原始WebShaper数据集以获取不同复杂度的问题。
- 通过浏览工具访问每个问题关联的URL,并将浏览结果存储以供后续处理。
- 运用Claude-Sonnet-4模型从网页中提取每个变量V的值。
- 将原始问题与变量V组合成有向无环图(DAG)。经拓扑排序后,通过剪枝操作衍生出子问题与种子问题。
3.2 R-HORIZON 基准测试
评估指标:
- All-or-Nothing 准确率(Acc):
Acc ( Q ) = { 1 , 所有子问题答案正确 0 , else \text{Acc}(\mathcal{Q}) = \begin{cases} 1, & \text{所有子问题答案正确} \\ 0, & \text{else} \end{cases} Acc(Q)={1,0,所有子问题答案正确else
- 理论准确率(Acc_expected) :
Acc expected ( Q ) = ∏ i = 1 n p i \text{Acc}{\text{expected}}(\mathcal{Q}) = \prod{i=1}^n p_i Accexpected(Q)=i=1∏npi
其中 p i p_i pi 为单问题的通过率。
3.3 基于 R-HORIZON 的强化学习
- 使用 GRPO 算法进行 RLVR 训练
GRPO算法原理参见我的另一篇博客(深度解析 GRPO:从原理到实践的全攻略),这里不再赘述
- 奖励设计:
| 奖励类型 | 定义 | 说明 |
|---|---|---|
| R_last | 仅当最后一个问题答案正确时奖励为1 | 只关注最终结果 |
| R_all | 所有子问题答案均正确时奖励为1 | 强调中间过程正确性 |
四、实验与剖析
4.1 当前 LRM 在长周期推理场景中的表现评估
4.1.1 评估实验设置
- 数据集:基于 R-HORIZON 构建了三类组合任务。
| 任务类型 | 原始数据集 | 组合方式 | 组合数量 n n n |
|---|---|---|---|
| 数学 | MATH500 | 顺序组合 | {1, 2, 4, 8, 16} |
| 数学 | AIME24 / AIME25 | 顺序组合 | {1, 2, 3, 4, 5} |
| 代码 | LiveCodeBench (v5) | 直接组合 | {1, 2, 3, 4, 5} |
| 智能体 | WebShaper | 多轮工具调用 | {1, 2, 3, 4, 5} |
-
模型:25 个主流 LRM。
- DeepSeek-R1 系列(1.5B ~ 70B)
- Qwen3 系列(8B ~ 235B)
- Nemotron、Skywork-OR1、OpenThinker3、Polaris 等
-
所有模型生成长度上限设为 64k tokens,避免截断。
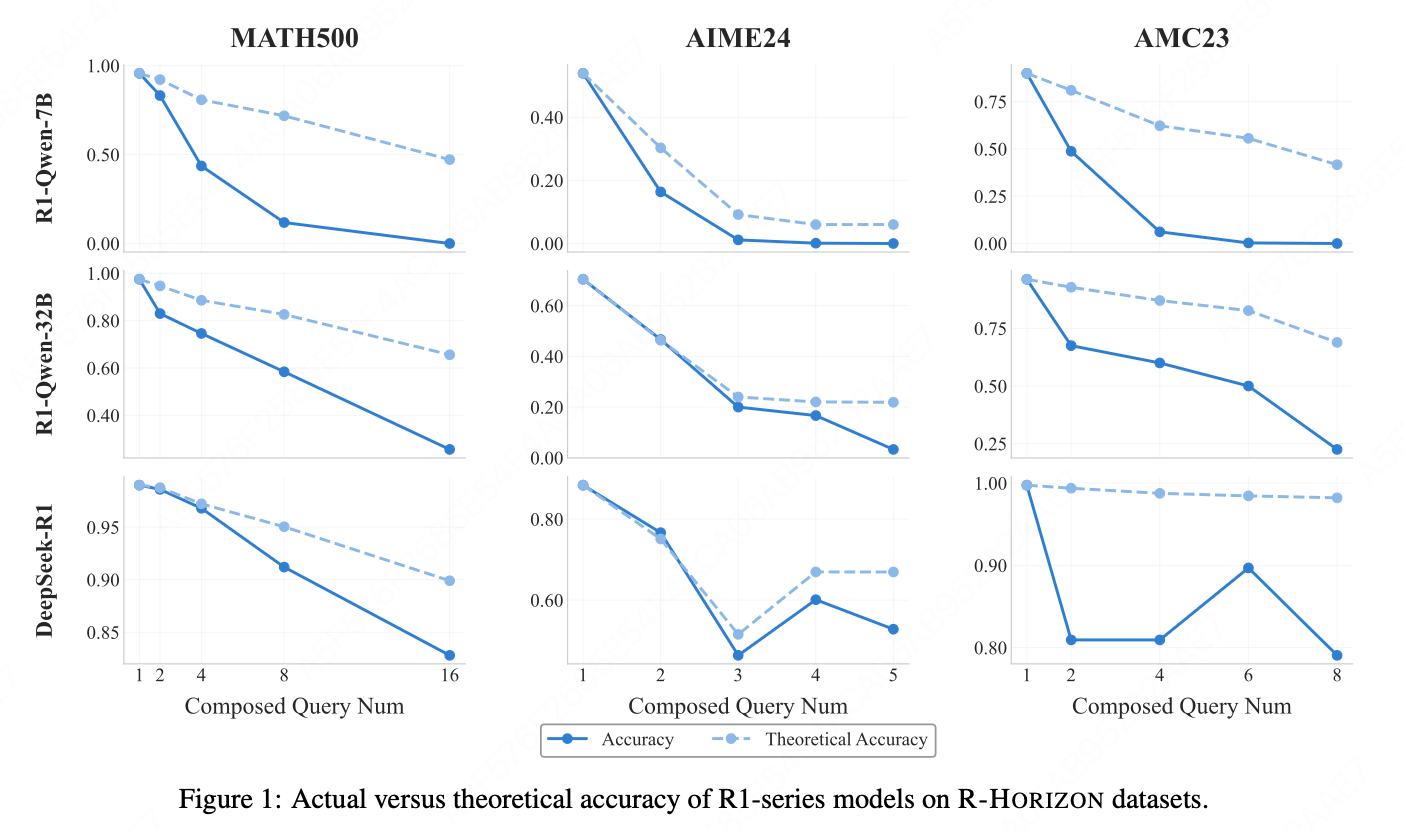
4.1.2 评估发现
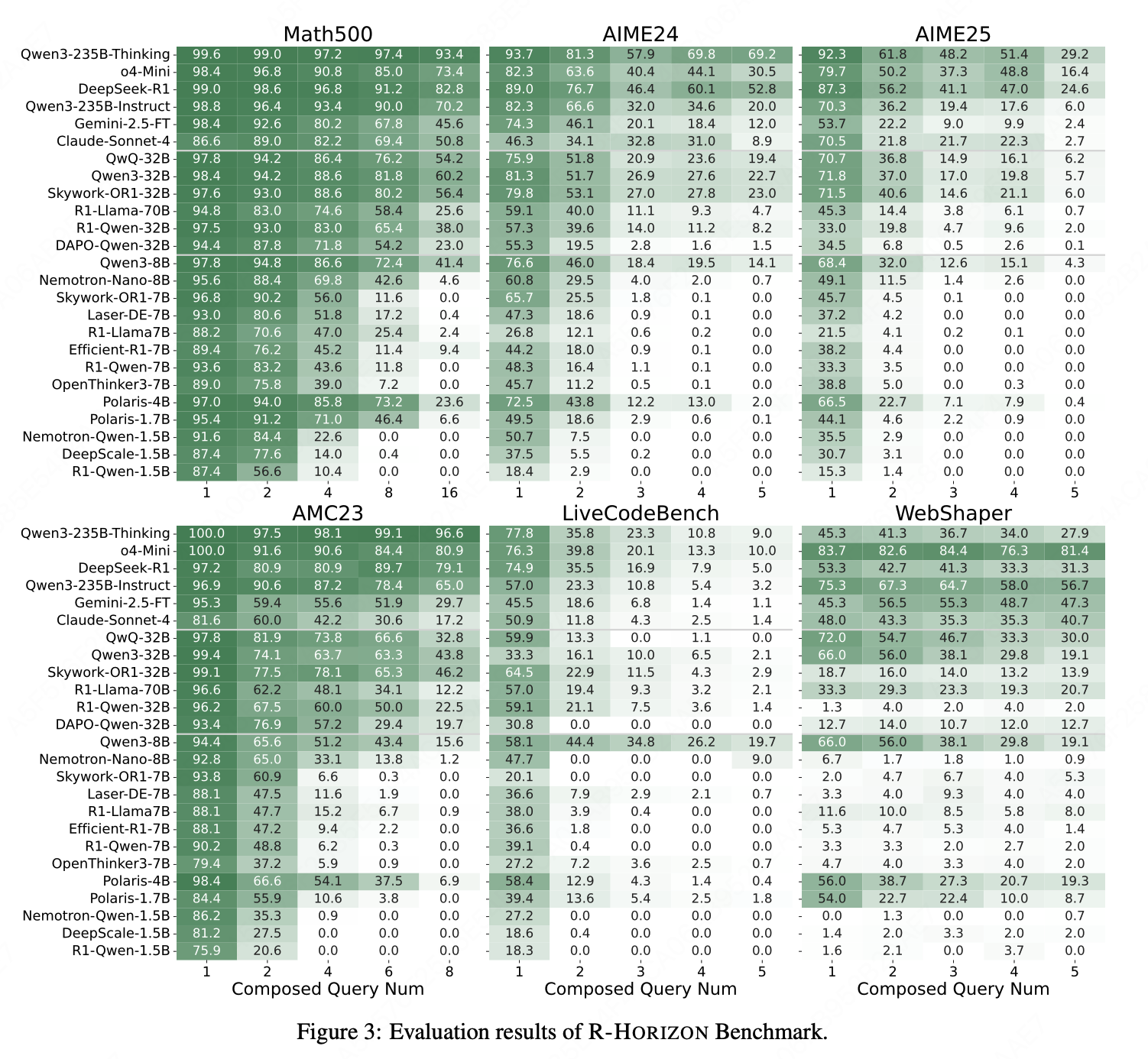
趋势1:推理步数增加 → 性能普遍下降
- 所有模型在组合问题上的准确率随 n n n 增加而显著下降,即使是最强模型(如 DeepSeek-R1、Qwen3-235B-Thinking、o4-mini)也不例外;
- 小模型下降更剧烈:R1-Qwen-7B 在 MATH500 上从 93.6%(n=1)降至 0%(n=16)。
趋势2:任务越难 → 下降越陡
- AIME25(更难)比 AIME24(较易)下降更快;
- 代码任务下降幅度高于数学任务;
- 智能体任务中,许多模型丧失工具调用能力,表现极差。
4.2 R-HORIZON 强化学习训练
4.2.1 训练设置
- 基础模型:R1-Qwen-7B
- 训练数据:从 Skywork-OR1-RL 数据中筛选,构建数据池,控制预期通过率>0.25
- 奖励函数:使用 R_last(仅奖励最终答案)
- 最大响应长度:40k tokens
4.2.2 训练发现
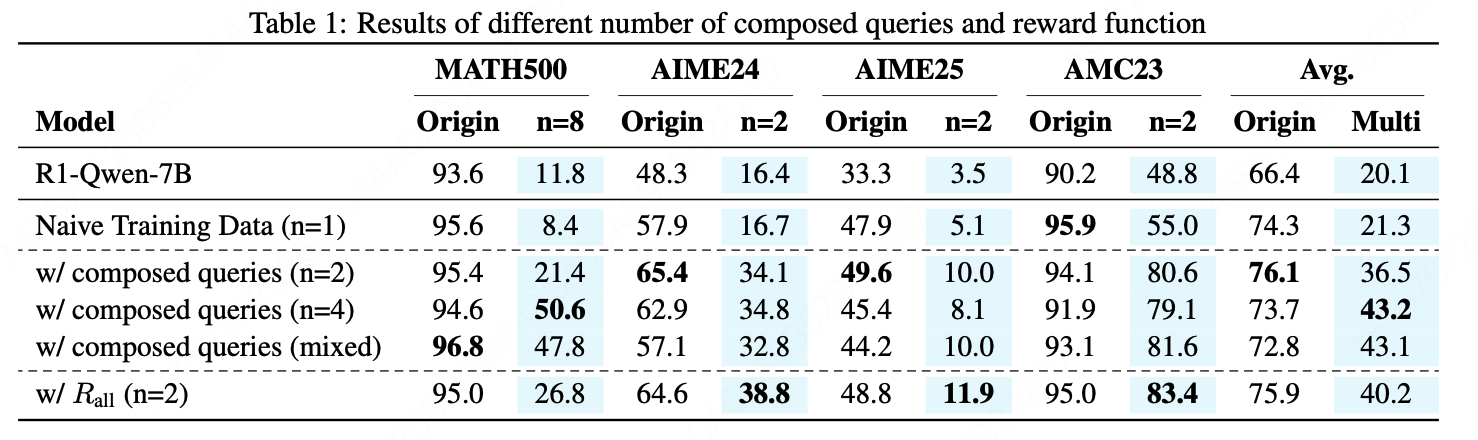
- 使用 R_all 奖励函数(要求全部正确)在 n=2 时效果优于 R_last;
- 使用组合数据训练的模型在组合问题上表现更强,原始单步问题上也有正向迁移。
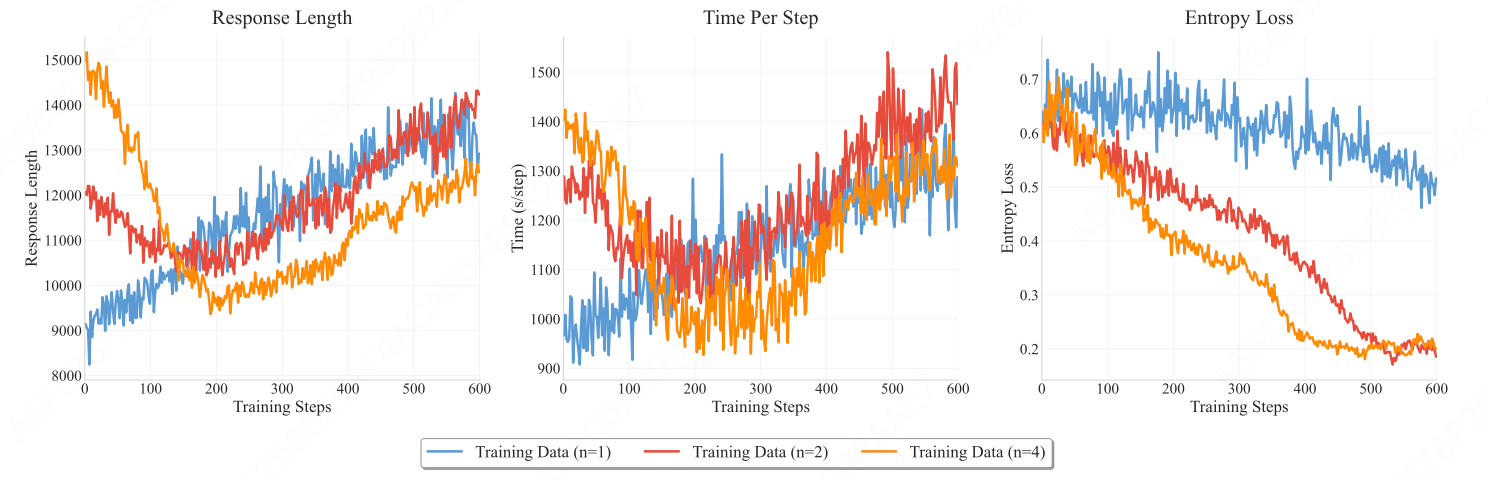
- 使用组合数据训练的模型响应长度在训练初期先下降后上升,最终达到与原始数据训练模型相当的水平,且每步训练时间相似。表明模型解决每个问题所需的token更少,证明组合数据训练能促进高效推理。
- 组合数据训练模型的熵损失下降速度快于原始数据训练模型,可能限制模型进行有效探索的能力。
4.3 深度分析
4.3.1 评估结果分析
1. 错误类型与失效模式
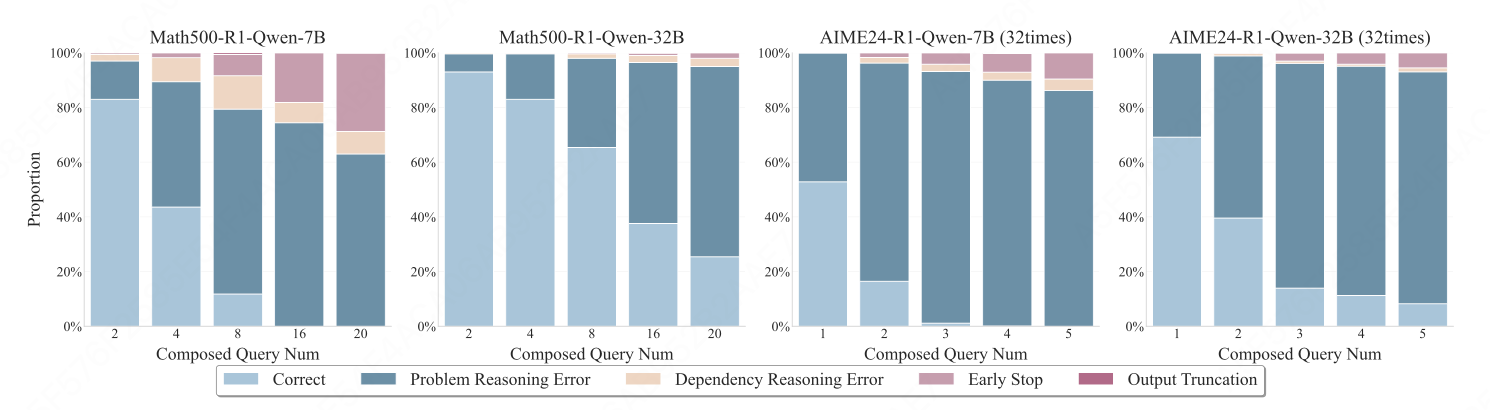
- 问题推理错误随步数激增。
- 依赖推理错误虽总量小,但随链长稳步上升。
- 提前终止现象:模型只回答前半部分题目,导致 All-or-Nothing 指标直接归零。
2. 有效推理长度边界
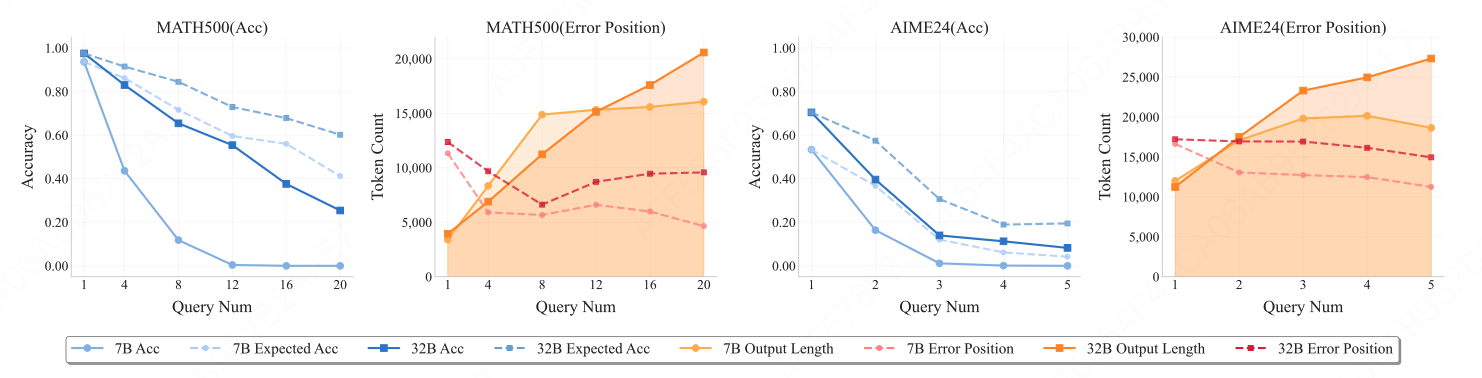
- 实际准确率与理论准确率差距随步数拉大,出现明显"长度惩罚"。
- 错误位置先下降后稳定,每类模型存在固定推理边界 :
- 7B模型 ≈ 4--6k tokens
- 32B模型 ≈ 8--10k tokens
3. 反思频率
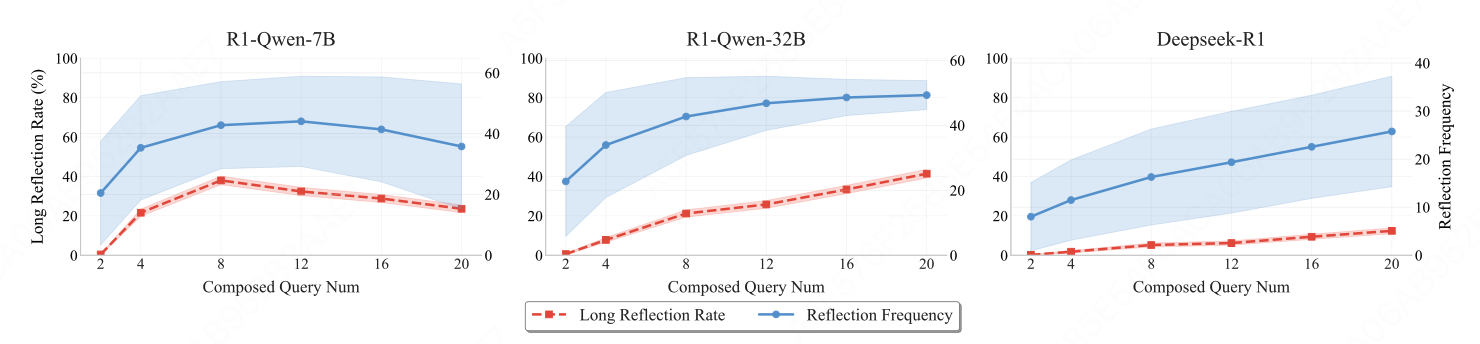
- 虽随题目增多而上升,但超过一半的问题仍无任何"长范围反思",模型的反思高度局部化,倾向于"看一步算一步"。
4. Token预算分配
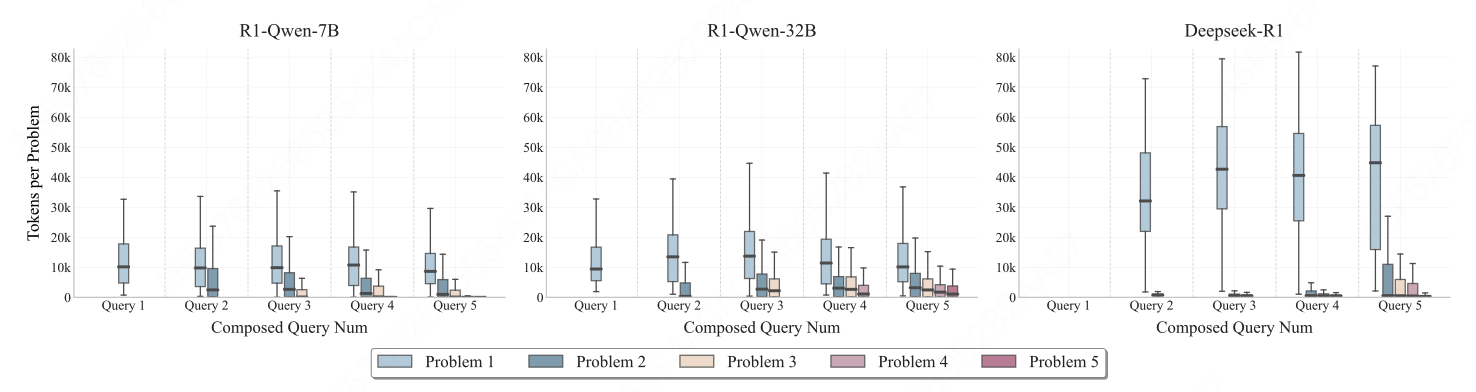
- 高度前倾,前序题目消耗过多,后续题目"粮尽弹绝",表明主流 LRM 尚未具备根据推理难度动态分配思考预算的能力。
4.3.2 R-HORIZON 强化学习带来的改善
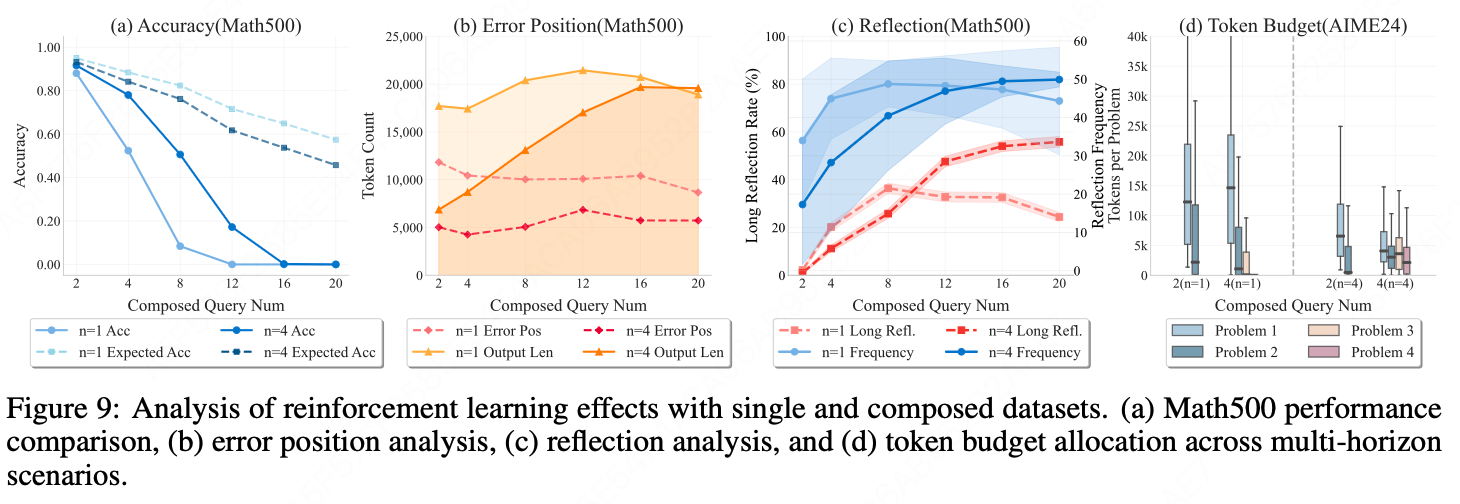
- 准确率提升与迁移效应:组合数据训练显著提升了模型在组合任务和原始单步任务的表现,并且可以泛化到更长的推理链。
- 缓解"过度思考"现象:同任务输出长度显著缩短,token利用率提高。
- 预算与反思 :
- 长范围反思频率显著增加,且增长斜率更合理;
- 题目间token分布趋于均衡,早期"堆砌"现象减弱。
五、小结
本文提出了 R-HORIZON,这是一种通过查询组合来激发大型推理模型(LRM)长周期推理能力的新颖且高效的方法。通过将简单问题组合成具有顺序依赖关系的多步任务,R-HORIZON 构建了兼具评估与训练功能的多步推理数据集:一方面用于评估 LRM 的长周期推理能力,另一方面用于在训练阶段增强其复杂推理表现,为未来复杂推理数据合成以及具备强长周期推理能力的模型开发奠定了基础。