前言
长久以来,我们只知道大型视觉语言模型(LVLM)会犯错,但始终缺乏一把"手术刀",无法剖析其视觉感知的根源性缺陷。我们只知其然,不知其所以然。我们希望当 AI 模型观察图像时,不再凭空想象,不再"指鹿为马"。
现在,这一瓶颈被打破了。bilibili 用户技术中心提出 VisionWeaver 及其核心诊断工具 VHBench-10 ,带来了创新性的视角。VisionWeaver 不再依赖单一编码器,而是开创性地提出"上下文感知路由网络",动态协同多个"视觉专家" 。而这一切得以实现的基础,正是其专门打造的诊断基准 VHBench-10------它让幻觉研究从 "识别现象"迈向了"诊断病因" 的新阶段。此工作已被 EMNLP 2025 Findings 录用。
相关链接
论文介绍
大型视觉语言模型(LVLM)的"幻觉"问题是阻碍其应用的核心障碍。以往的评测方法(如POPE)虽然有价值,但普遍停留在粗粒度层面,大多只关注"图片中是否存在某个物体"这类简单判断。这就像医生只知道病人发烧,却无法定位具体的病灶。这种"只知其然"的评测方式,无法揭示幻觉产生的根本原因,更无法为模型的改进提供针对性指导。
为了解决这一核心痛点,本研究首先提出了全新的诊断工具------VHBench-10基准。 它开创性地将幻觉问题溯源至检测、分割、定位、分类这四项基本视觉能力,并进一步细分为10个具体的子任务(如颜色、计数、文本识别等)。通过这个"精准CT扫描",我们首次能够系统性地诊断出不同视觉编码器各自的"能力盲区"。
基于这一深刻洞察,VisionWeaver架构应运而生。它不再是盲目地使用单一编码器,而是构建了一个动态专家协作系统,根据图像内容智能地调度最合适的视觉专家参与决策,从根源上抑制幻觉的产生。
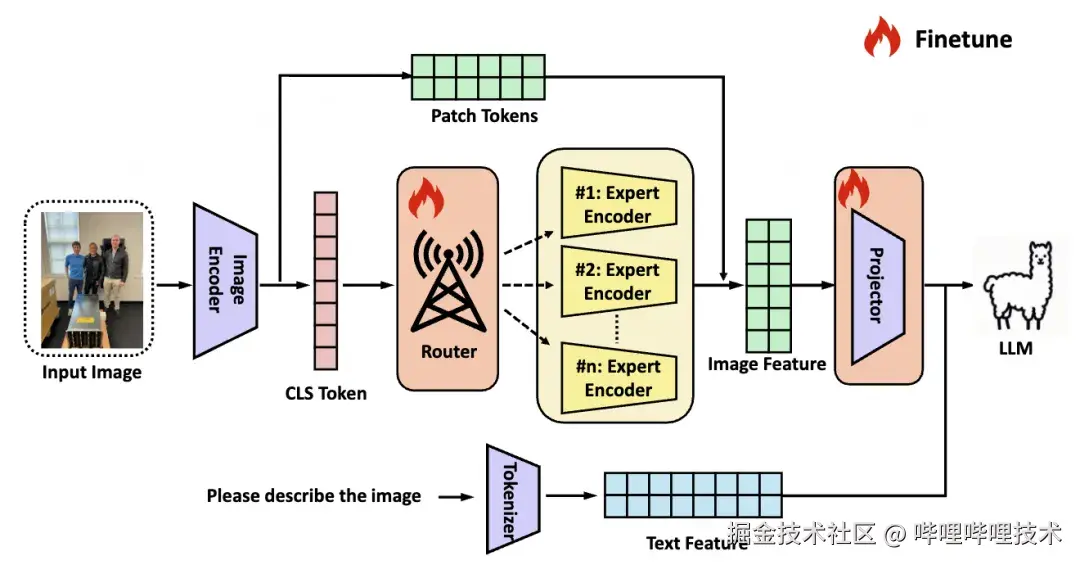
图1 VisionWeaver整体架构
我们的主要贡献点如下:
-
提出了VHBench-10------一个革命性的精细化诊断基准,推动幻觉研究从"识别现象"迈向"诊断病因"。 它首次将幻觉与底层视觉任务失败直接挂钩,为精确评估和定位LVLM的视觉能力短板提供了强有力的工具。
-
系统性地揭示了不同视觉编码器的幻觉倾向。 通过在VHBench-10上的全面评估,论文首次量化并证实了特定编码器在特定视觉任务上的优势与短板,为解决幻觉问题提供了明确的靶点。
-
提出了VisionWeaver------一个强大的LVLM新架构。 它引入上下文感知专家路由机制,能根据图像内容智能地聚合多个专家的视觉知识,效果远超简单的特征融合方法。
-
在多个权威基准上取得了SOTA性能。 大量实验表明,VisionWeaver不仅显著降低了幻觉率,还全面提升了模型的综合表现。
方法概述
VisionWeaver 的核心是解决单一视觉编码器能力有限且存在固有偏见的问题 。简单地将多个编码器的特征相加或拼接,实验证明效果并不理想 。为此,VisionWeaver 设计了一套智能、动态的专家协作流程,主要包含两大模块:
上下文感知路由 (Context-Aware Routing): 该机制旨在利用图像的全局语义特征来计算自适应的软路由权重,从而选择最合适的视觉专家 。具体而言,系统将基础 CLIP 编码器输出的CLS Token 特征作为路由模块的主要输入 。该 CLS Token 被证实能够有效捕获图像的关键全局视觉信息 。路由模块基于此特征生成一组路由信号,即针对每个下游专家编码器(如ConvNext, DINOv2, SAM, Vary等)的动态权重,以此决定不同专家在当前情境下的重要性得分 。
知识增强与特征融合 (Knowledge Enhancement and Fusion): 获得各专家的重要性权重后,系统对所有专家的输出特征进行加权融合(Weighted Fusion),生成一个聚合的专家表征 。为了在引入专家知识的同时不损失原始的细粒度视觉信息,该聚合表征将与基础 CLIP 编码器输出的 Patch Tokens 进行对齐 。实现方式上,通过一个残差式连接(residual-style connection),将聚合的专家特征与原始的 Patch Tokens 进行加法操作 。最终,这份增强后的视觉表征被传递至投影器(Projector),以映射到大型语言模型(LLM)的嵌入空间中,供后续的文本生成使用 。
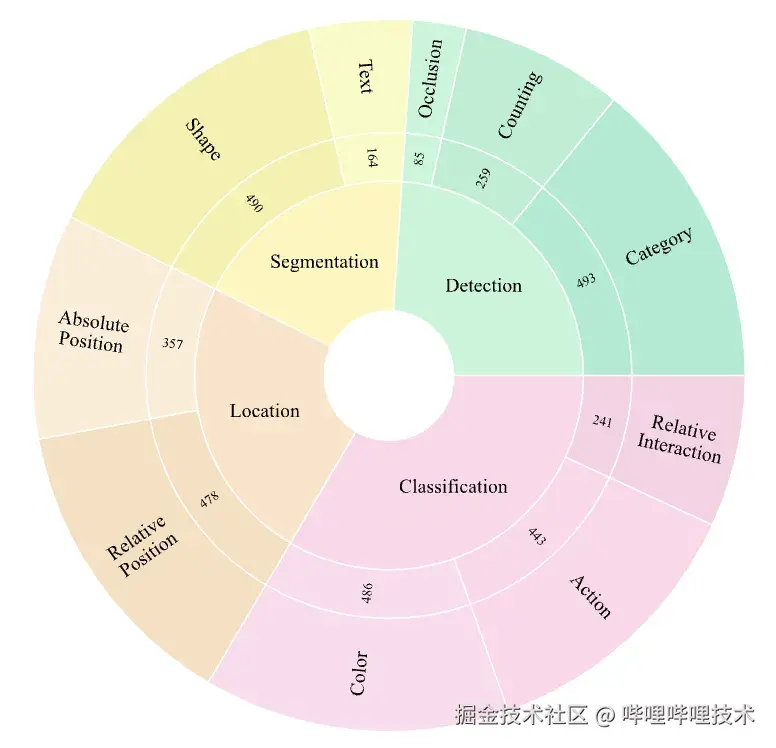
图2 VHBench-10将幻觉分为4大类10小类
关键特征
-
精细化幻觉诊断: 依托VHBench-10,从视觉任务根源诊断并解决幻觉问题。
-
上下文感知路由: 告别单一编码器,智能调度最适合当前任务的视觉专家。
-
多专家协同融合: 汇集不同编码器的独特优势,实现对图像的全方位、深层次理解。
-
卓越的幻觉抑制能力: 在多个基准上显著降低幻觉率,提升模型可靠性。
-
高效推理设计: 通过轻量级专家和KV缓存等机制,在不显著增加延迟的情况下提升性能。
实验
全新的精细化幻觉评估
VHBench-10基准的核心并非简单地判断对错,而是通过对10个细分视觉任务的评估,精准定位模型在感知能力上的具体短板。团队利用GPT-4为近万张图片生成了包含特定类型错误的描述(例如,颜色错误、数量错误等),与正确的描述形成对比,从而精确量化模型在各个维度上的幻觉倾向。
与已有方法的比较
在VHBench-10以及POPE、AutoHallusion等多个幻觉基准测试中,VisionWeaver的表现全面超越了使用单一编码器或简单多编码器融合的方法。如下图所示,无论是在物体存在性、颜色、形状还是文本识别等所有10个细分任务上,VisionWeaver的错误率均为最低,证明了其架构的普适性和有效性。
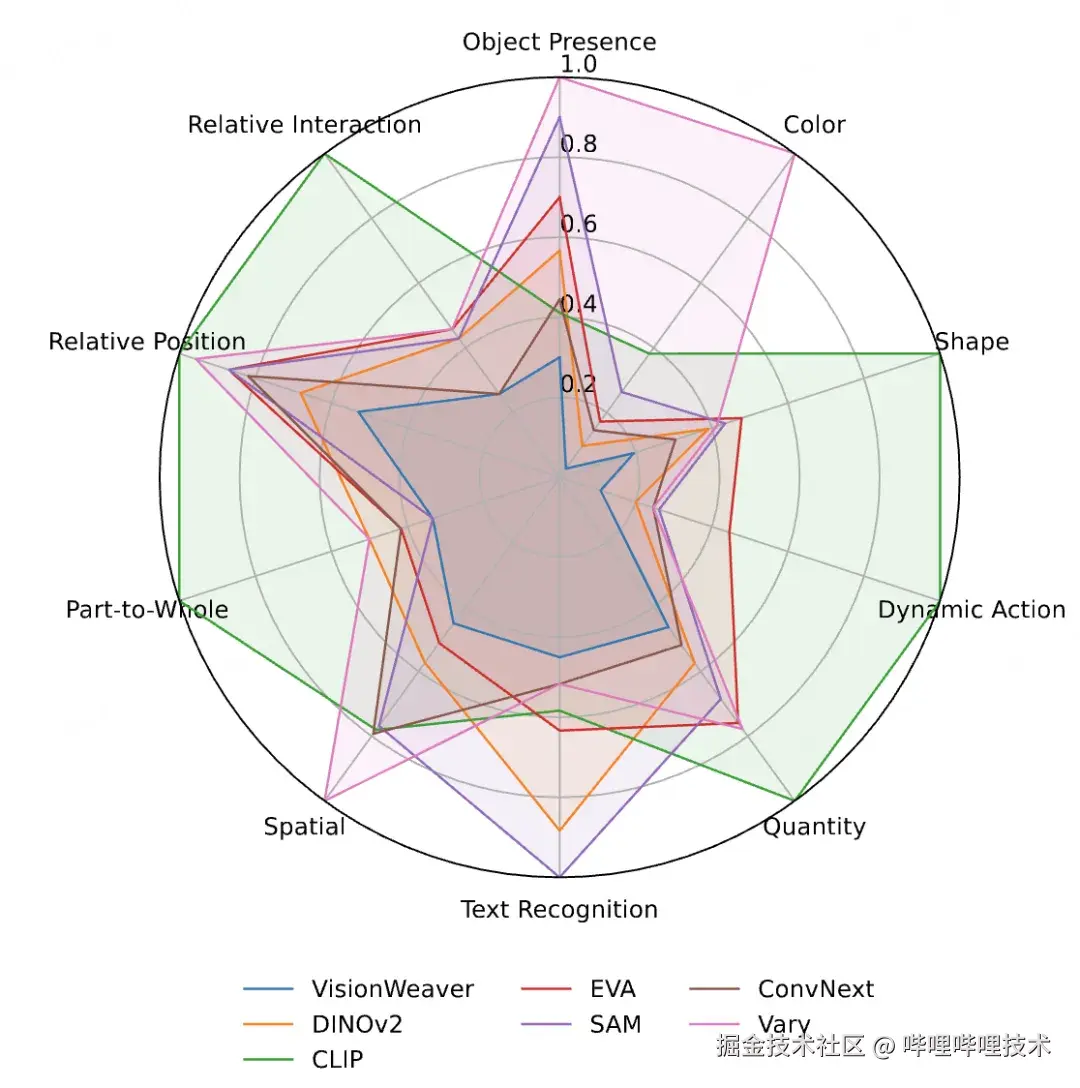
图3 VisionWeaver在10类细分幻觉任务上均取得最低错误率
总结
VisionWeaver及其核心评测工具VHBench-10,共同将幻觉研究的范式从模糊的现象描述,提升到了病因诊断层面。它不再满足于"知道模型错了",而是要探究"模型为什么会错"。通过VHBench-10提供的深刻洞察,VisionWeaver得以构建一个智能、动态的多专家协作系统,从视觉感知的根源上大幅缓解了幻觉问题。这一"诊断+治疗"的新范式,为构建更可靠、更精确的下一代多模态AI提供了坚实的基础和清晰的实现路径。
-End-
作者丨Jerry酱、Kiren_