目录
[数据挖掘与 OLTP/OLAP/DSS/数据仓库的关系](#数据挖掘与 OLTP/OLAP/DSS/数据仓库的关系)
特异型(异常)知识挖掘(Outlier/Exception)
[事务数据库中的挖掘(Transactional DB)](#事务数据库中的挖掘(Transactional DB))
[关系型数据库中的挖掘(Relational DB)](#关系型数据库中的挖掘(Relational DB))
[数据仓库中的挖掘(Data Warehouse)](#数据仓库中的挖掘(Data Warehouse))
[Web 数据源中的挖掘(Web Mining)](#Web 数据源中的挖掘(Web Mining))
[数据挖掘与 CRM(客户关系管理)](#数据挖掘与 CRM(客户关系管理))
什么是数据挖掘
定义
数据挖掘(Data Mining)是综合数据库技术、人工智能、机器学习、统计学、知识工程、信息检索、高性能计算与数据可视化等多学科方法,对大规模数据进行自动化/半自动化的模式发现、趋势挖掘与预测,以获得具有可解释性且可复用的知识,支撑分析与决策。
更宽的术语是KDD(Knowledge Discovery in Databases, 数据库中的知识发现),它是一个过程:
(1) 数据选择
(2) 数据清洗/预处理
(3) 数据集成/变换(含特征构造、降维)
(4) 数据挖掘(核心算法阶段:分类、聚类、关联、回归、序列/时序、异常检测等)
(5) 模式评估与表达(可视化、解释、部署)
层级关系
数据→信息→知识:查询/报表主要把数据转为信息;挖掘/KDD进一步把信息概括为知识(一般化、可验证、可迁移的模式/规律),面向更高层的理解与决策。
现实中常出现 Data Rich, Information Poor(富数据、贫信息/知识),即数据库里堆满数据,但人只能得到零散、局部且被动的信息;KDD正是为系统性、主动性地把数据资产转成知识资本。
数据挖掘技术的产生与发展
商业需求与应用牵引
数据库系统与应用环境的演化
20世纪60---70年代:从文件处理系统向数据库系统转变;
70---80年代:层次/网状/关系三种主要模型研究与应用推进;
80年代中后期:关系数据库成熟并主导;对象-关系/面向对象数据库、并行/分布式数据库、主动数据库(Active DB)、知识库/信息库等相继提出;
90年代:业务上联机事务处理(OLTP)为核心的应用普及,但面向分析/预测的高层应用不足;随之出现数据仓库(DW)、联机分析处理(OLAP)与决策支持(DSS),但仍难满足从"信息"走向"知识"的深层诉求。
结论:企业/政府/行业的规模化信息化与竞争加剧,把从历史数据中提炼可执行洞见的能力推到战略高度,直接催生了数据挖掘。
数据形态与规模的变化
数据量级持续跃升;类型从结构化扩展到半结构化/非结构化(文本、图像、音视频、日志、Web、传感器、多媒体等);来源从单机/部门扩展到多源异构、跨组织、跨网络;存取从离线转向近实时/实时。
痛点:传统手工分析 + 经验判断已难支撑规模、速度与复杂度;统计报表只能回答已知问题,难以发现未知模式。
技术背景驱动
信息技术底座: 数据库/数据仓库/Internet 技术成熟;并行与分布式架构、高性能计算、存储与网络的指数级进步(摩尔定律带来的CPU、存储、I/O成本下降与能力提升)
**方法论底座:**统计学(推断、建模、假设检验、概率图)、人工智能/机器学习(监督/无监督/半监督/强化、规则学习、树/概率/核/集成/深度模型等)与知识工程(表示、推理、解释)成果从理论走向工程化。
**经验型智能的瓶颈:**专家系统暴露"知识获取难、可扩展性差、维护成本高、领域迁移困难"的局限;社会数据与业务复杂性迫使我们从"手工规则"转向"从数据自动学习"。
互联网与社会网络: 用户规模爆炸与在线行为数据的全面数字化,形成了天然样本库,倒逼挖掘技术向大规模、在线化、个性化演进。
大数据时代对数据挖掘的新增需求
大数据概念的演进与阶段
1. 概念萌芽期(2000年之前至早期): 学术界少量论文与产业苗头(以Google等为代表),强调"大数据将成为关键生产要素"。
2. 广泛讨论/探索期(2001---2010): 论文与报道激增,产业普及,数据规模与应用场景快速扩展,Web与联网数据成为核心来源之一。
3. 深化与落地期(2011年至今): 咨询与厂商报告将大数据系统化(如IDC 4V、IBM"真伪性Veracity"、Gartner"价值实现需有可处理模式"等),学术论文指数式增长,应用渗透政产学研。
典型定义与"4V"
IDC(行业共识): Volume(规模)、Velocity(速度)、Variety(多样)、Value(价值)四个维度(IBM额外强调Veracity(真伪/可信))
Gartner: 只有当处理模式能将潜在价值转化为可感知/可运营的收益,大数据才成立。
学术补充: 维克托•迈尔-舍恩伯格等提出不再以抽样到推断为唯一途径,而是面向全量/弱约束数据的直接计算与管理,凸显处理范式迁移。
围绕4V的技术挑战与挖掘应对
(1)Volume 超大规模
挑战:单机内存/磁盘/带宽受限,多遍扫描代价高。
应对:
分布式存储与计算(Hadoop/Spark、MPP、并行数据库)
算法并行化(MapReduce风格、参数/数据并行、模型并行)
近似计算/抽样/草图结构/压缩(Reservoir、Count-Min等)
离线批处理 + 线上增量/在线学习的分层计算
(2)Velocity 高速度/实时性
挑战:数据以流(Data Stream)方式到达,到达快、变化快、分布漂移,难以多遍读取。
应对:
流式挖掘范式:一次扫描/有限存储/增量更新
滑动窗口/时间衰减/采样
概念漂移检测与自适应模型
CEP(复杂事件处理)与近实时特征/在线预测
(3)Variety 多源异构/多模态
挑战:结构化(表)、半结构化(XML/JSON/日志)、非结构化(文本、图像、语音、视频)并存;跨域、跨平台、跨组织数据需要对齐与融合。
应对:
表示学习与特征工程(词向量/图表示/视觉深度特征等)
信息抽取与模式对齐(实体消歧、对齐、Schema映射、知识图谱)
领域化挖掘分支:Web挖掘(内容/结构/链接/访问日志)、社交网络挖掘、多媒体挖掘。
多模态融合(文本+图像+语音+传感)与因果/时空网络
(4)Value 价值密度低但潜在价值高
挑战:海量数据"噪多信少",有用模式稀疏;仅做存储与可视化难以"变现"。
应对:
从指标到洞见:关注可解释、可行动的模型与业务闭环(发现→决策→反馈→再学习)
任务导向:风险控制、精准营销、用户画像、推荐、运维与异常检测、供应链优化、公共治理等
真伪性(Veracity)控制:数据质量、偏差与公平性、鲁棒与不确定性评估
数据流挖掘的要点
数据到达方式:连续、快速、只读一次可行,难以全量落库后多轮计算。
算法范式:单遍扫描、增量式、受限内存、任何时刻可给出当前模型/统计。
工程管道:采集→缓冲/队列→在线特征→模型更新→告警/决策;支持突发流量、漂移、窗口策略。
与传统离线挖掘对比:传统依赖多次完整扫描+静态样本,流式要求到达即处理+持续演化
数据挖掘与 OLTP/OLAP/DSS/数据仓库的关系
OLTP:面向事务的细粒度操作(增删改查),强调并发与一致性。
数据仓库(DW):集成面向主题的历史数据,支撑分析;ETL把源系统数据清洗/集成到仓库。
OLAP/DSS:多维汇总与交互分析/决策支持,回答"已知问题"。
数据挖掘:在此之上,自动发现未知模式并进行预测与推断,是更高层次的分析与知识服务。
ETL 的英文全称是 Extract, Transform, Load,中文译为数据抽取、转换、加载。
Extract(抽取):从多个数据源(如数据库、文件、API 等)提取原始数据。
Transform(转换):对抽取的原始数据进行清洗、整合、标准化等处理,使其符合目标系统要求。
Load(加载):将处理后的干净数据加载到数据仓库(DW)等目标存储中。
OLTP 是数据的生产者。数据仓库是数据的整理者和存储中心。
OLAP 是数据的使用者和提问者。
数据挖掘是数据的探索者和预言家。
典型任务与方法
监督学习:分类(SVM、树/集成、神经网络)、回归(线性/非线性/树、神经网络)
无监督学习:聚类(k-means/层次/谱/密度)、关联规则(Apriori/FP-Growth)、主题模型。
半监督/主动/迁移/联邦/图学习:应对标注稀缺、跨域、隐私与分布式场景。
时序/序列/图挖掘:序列模式、异常检测、因果与事件链、社交/知识图谱。
文本/Web/日志/多媒体:内容/结构/链接/访问混合建模,多模态融合与推荐检索
可视化与可解释性:规则/重要性/反事实、交互式可视分析。
有答案的练习(监督学习),比如教机器区分猫狗图片(分类),或者预测房价走势(回归)。常用方法如同画分界线的SVM、像专家团队的决策树、以及模拟人脑的神经网络。
自己找规律(无监督学习),比如把客户自动分组(聚类),或者发现"买尿布常买啤酒"的购物规律(关联规则)
现实世界中数据往往不完美,于是发展出一些更聪明的方法:
当缺少标注时,用半监督/主动学习(少量标签+智能提问)
需要复用经验时,用迁移学习(举一反三)
保护隐私时用联邦学习(数据不动模型动)
对于特殊类型数据,工厂也有专门车间:
分析时间序列(如股价预测)
挖掘关系网络(如社交圈分析)
无论是处理文本、网页还是音视频,工厂都能通过多模态融合技术,实现更精准的推荐和搜索。
最重要的是,这个工厂不仅给出结果,还通过可视化分析和规则解释,让人能看懂推理过程,比如告诉你"申请被拒是因为收入不足",甚至模拟"如果收入增加2万就能通过"的反事实场景,让AI的决策变得透明可信。
数据挖掘研究的发展趋势
1. 总体态势
多学科汇聚: 历经十数年发展,数据挖掘吸收数据库、AI/ML、统计学、信息检索、可视化与高性能计算等成果,形成带有自身范式与方法论的交叉研究分支。
阶段性特征: 与其他新技术类似,经历概念提出 → 接受扩散 → 广泛研究与探索 → 渐进应用与大规模应用。当前多数学者认为研究仍处于广泛研究与探索阶段:
一方面,概念已被广泛接受,理论上涌现出大量挑战性与前瞻性问题;
另一方面,产业化与大面积应用仍需更深入的研究积累与工程实践。
2. 学术与产业拉动
学界与业界对数据挖掘的兴趣持续增长,研究力量来自高校、研究机构、政府项目与企业。学术界偏基础理论与通用方法,企业/政府偏落地问题与数据资源结合。
自20世纪80年代末概念提出后,挖掘的经济价值逐步显现,并被咨询/厂商推动形成市场。2007年Gartner把数据挖掘和机器学习列入未来3--5年影响产业的关键技术之一;同时它也进入十大战略技术名单,说明其在体系结构/数据库/分析等底层领域的战略地位。
3. 技术鸿沟与应用形态
目前很多系统仍处在跨越鸿沟之前:
多为通用辅助开发工具,需要专家和数据科学团队配合;
横向方案(Horizontal Solution)多,纵向方案(Vertical Solution)不足,即通用平台较多,行业场景化方案缺口仍大。
产业成功更可能源于将挖掘理念与特定领域知识与业务逻辑结合,形成面向问题的端到端纵向解决方案。
4. 面向应用的六类关键开放问题
业务价值落地: 不止于发现模式,更要无缝嵌入业务流程,提供可解释、可验证、可执行的洞察(如直接生成风控规则或推荐策略)
数据源适配: 算法必须能灵活、高效地处理各种类型的数据源(从传统数据库到NoSQL、JSON、日志文件等),克服接口和模型的差异。
数据规模与质量: 在动辄海量、充满噪声、不完整的数据中,必须进行有选择、有针对性的预处理,而不是蛮力规整所有数据。
人机协同交互: 系统需要模块化、可交互,支持人在循环中进行采样、试探、评估和可视化,实现"边挖边看"的协同分析。
专用工具语言: 需要超越SQL的、更高级的抽象语言和可视化工具,来简化和描述整个数据挖掘任务管道,并直观呈现结果与偏差。
**专属理论发展:**需建立数据挖掘自身的理论基础,以专门解决其独特问题。
数据挖掘概念
从商业角度看数据挖掘技术
定义(商业视角): 一种面向商业信息处理的新技术,通过对历史与现网数据的观察→统计→分析→综合→推理,自动发现关联、模式与趋势,把数据转化为可解释且可执行的知识,以支持运营/管理/营销/风控/预测等高层活动。
定位: 数据挖掘是企业信息化的"知识层",位于DW/OLAP之上,聚焦未知的规律与将来态的预测/决策。
**效果:**帮助企业从海量、复杂、异构数据中提取可落地的洞见,形成可操作规则/模型,服务策略优化与流程改进。
数据挖掘的技术含义与KDD
**KDD(Knowledge Discovery in Databases):**数据库中的知识发现过程。1990年代形成国际会议KDD并扩展出DMKD等专刊,成为国际研究热点。
三种常见关系视角:
KDD看成挖掘的一个特例(早期观点): 把从各类数据库/仓库/Web/文本等中抽取知识的过程统称数据挖掘,强调源数据形式的多样性。
数据挖掘是KDD过程中的一步(主流工程观点): KDD=选择、清洗、集成、变换、挖掘、评估、表示的端到端流水线;挖掘是其中算法核心步骤。
**KDD与Data Mining含义相同(宽泛用法):**二者常被混用,实际语境依赖场景。
数据挖掘研究的理论基础(七类代表框架)
1. 模式发现:
核心思想: 让机器自动学习
(以机器学习为核心,从数据中自动找出各类知识结构。)
2. 规则发现:
核心思想: 万法归宗,皆是规则
(将所有挖掘问题统一为寻找"如果...那么..."的规则,并用一套标准指标来衡量。)
3. 概率与统计:
核心思想: 用概率说话,量化不确定性。
(为发现的结果提供置信度和可解释性,处理噪声和随机性。)
4. 微观经济学:
核心思想: 挖掘也要算经济账。
(将模式视为商品,衡量其价值(效用)和成本,追求性价比最高的发现。)
5. 最小描述长度:
核心思想: 最好的模型是最简洁的模型。
(一个模式如果能极大地压缩数据长度,它就是好模式。)
6. 归纳数据库:
核心思想: 把"知识"当"数据"一样管理。
(在数据库中直接存储和查询挖掘出的模式和规则,形成发现与管理的闭环。)
7. 可视化数据挖掘:
核心思想: 让人脑参与循环。
(通过可视化将挖掘过程变得直观,利用人类的视觉和直觉进行探索和交互。)
数据挖掘技术的分类问题
从四个角度来给数据挖掘:
A. 按"挖掘任务/要得到什么"来分
概念/特征的总结:把零散数据概括成规律或特征
关联规则:找"同时出现/有依赖"的关系(超市"啤酒-尿布"就是典型)
序列/时序模式:按时间先后出现的规律(用户行为路径、购买序列)
相似模式:相像的内容归到一起(文本相似、图片相似)
混沌/噪声中的规律、依赖关系/概率模型、异常/稀有事件(欺诈、故障早期征兆)等
B. 按"数据放在哪里/什么类型数据"来分
关系型数据库、面向对象数据库、空间数据库(地理位置)、
时态/时序数据库、文本数据库、多媒体数据库、异质/跨源数据、
过程/流式数据、Web数据......
核心意思:数据长什么样,决定你要换什么"刀法"。
C. 按"用什么方法/理论工具"来分
机器学习(监督/无监督/半监督/强化)
统计学方法(回归、检验、概率模型)
聚类分析(k-means、层次、密度等)
神经网络/深度学习
遗传/进化算法
数据库方法(靠SQL/索引/内置算子来做)
近似与不确定性推理、粗糙集/模糊集、集合/代数方法、集成方法(Bagging/Boosting)
D. 按"能发现的知识类型"来分
概念/定义型知识(某类东西的共性定义)
偏好/差异型知识(A和B有什么不同)
关联/依赖型知识(一起出现/相互影响)
预测/分类型知识(给出标签或数值预测)
异常/罕见知识(少见但重要的异常点/异常序列/异常关联)
这些角度互补:先看"要什么(任务)",再看"数据啥样(对象)",再定"怎么做(方法)",最后产出"知识类型"
常用的知识表示模式与方法
挖掘不仅要"挖",还要怎么表示让人看懂、能用(挖什么+怎么表达)
广义知识挖掘(总结概况)
目标:把细碎数据"拉远看",得到更宏观、更可视化的知识(报表/图表背后的概念化总结)
① 概念描述(Concept Description)
做什么:给某类对象做特征总结(Characterization)和区别点(Discrimination)
常用法:
概念归纳/多层次汇总(像把明细按维度汇总上卷:部门→公司→城市→国家)
多维统计/OLAP(均值、最大、占比、趋势图等),把结果以表/柱状/饼图等呈现。
注意:样本要够、类别边界要清、层级要合理(所谓概念层次/层级)
② 多层次概念描述(Concept Hierarchy)
为什么:很多属性天然分层(如地点:区→市→省→国家;年龄段;收入段)
四种建层方式:
模式层次(Schema层次,数据库自带层级)
取值分组层次(把连续值按段分箱,如0--1000、1000--2000...)
操作导出层次(按业务规则组合成更抽象概念)
基于规则的层次(写规则把低层映到高层)
用处:支持上钻/下钻的多层汇总,成为概览/仪表盘/报表的知识基础。
关联知识挖掘(Association)
定义:找项与项之间的"同时发生/依赖"关系(如{牛奶, 面包}→{黄油})。
为什么有用:能指导搭售/陈列、交叉营销、捆绑定价等。
经典指标:
最小支持度(Support):一起出现的频率要不低于阈值
最小置信度(Confidence):推出关系的可靠度要不低于阈值
代表算法:Apriori / FP-Growth
代表算法:Apriori
核心思想:"步步为营"。像筛沙子一样,一层层地筛。
第一步:先找出所有 "单人气王"(支持度高的单个商品),比如"牛奶"、"面包"、"尿布"。
第二步:只用这些"单人气王"来组合,找出所有 "双人组合"(如{牛奶,面包}、{牛奶,尿布}),再筛出其中支持度高的。
第三步:再用这些"双人组合"去生成 "三人组合",继续筛...
为什么这样? 因为一个组合如果本身不火,那它再加上别的商品也不可能火。这大大减少了计算量。
代表算法:FP-Growth
核心思想:"建一棵情报树"。它更聪明,先把所有小票信息压缩成一棵特殊的"树形结构",然后直接从这棵树里快速"采摘"出所有的频繁组合。
特点:通常比 Apriori 更快,尤其适合大数据量。
类知识挖掘(Classification)
定义:把样本分到已知的类别(有标签的监督学习)
基本流程:划训练/测试 → 选特征 → 训练模型 → 评估(准确率、召回、AUC等)
常见方法:
决策树(ID3/C4.5/CART...):可解释、训练快;对噪声和连续变量要注意剪枝/离散化
贝叶斯分类(朴素/网络):假设独立性,速度快、可解释;相关性强时会打折扣
神经网络:表达力强、能拟合复杂模式;训练慢、可解释性弱(早期BP,如今可理解为深度学习的前身)
遗传/进化算法:搜索最优规则或特征组合,适合复杂空间的优化
基于实例/相似度:kNN、Case-Based;简单好用,但特征尺度/距离要处理好
其他:粗糙集/模糊集(处理不确定/模糊边界)、回归(连续值预测)、规则学习/集成方法等
小对比:分类是"有标签老师";聚类是"无老师自己分组"
分类就是你利用一批已经知道答案的数据(训练集),去训练一个模型(分拣员),让它学会一套判断标准,从而能够自动地对新的、未知的数据进行预测和归类。
聚类知识挖掘(Clustering)
定义:把对象按相似性自动分成若干群;无监督学习。
用途:客户分群、商品分群、图像分组、异常点初筛等。
主要技术家族:
基于划分:k-means、PAM、CLARA、EM(高维/大样本常用,需选k)
基于层次:凝聚/分裂两派(CF-Tree/BIRCH、Chameleon等),能形成树状层级
基于密度:DBSCAN/DENCLUE/OPTICS,能发现任意形状簇,并能识别噪声/离群点
基于网络/图:把数据放到网格/图结构里再聚(如STING、WaveCluster、CLIQUE)
基于模型:用统计模型刻画每个簇(如高斯混合),通过优化得到最佳划分
提示:聚类结果依赖距离/相似度定义与参数;不同任务往往需要结合业务特征来解释。
聚类就是一场探索性的发现之旅,它帮你从无标签的数据中,找到内在的自然分组,为更深度的分析和决策提供起点。
预测型知识挖掘(Prediction)
定义:利用历史 + 当前数据,预测未来数值或趋势。
典型方向:
趋势/回归:移动平均、指数平滑、线性回归等
周期/季节:频谱/小波/周期开窗分析
序列模式/频繁序列:如FreeSpan等找"事件序列规律"
神经网络/机器学习:当关系非线性、特征多时效果更好
场景:销售/流量预测、库存/能耗预测、健康/故障预警等。
预测型知识挖掘,就是基于已经发生的"过去"和正在发生的"现在",运用各种分析工具,像一位经验丰富的航海家一样,尽可能地"看见"未来,从而帮助我们提前决策、规避风险、抓住机会。
特异型(异常)知识挖掘(Outlier/Exception)
目标:从海量数据里找稀少但重要的异样点/异样模式(可能是欺诈、入侵、设备故障、罕见病症等)
常见类型:
孤立点:个别点偏离整体(基于距离/密度/统计检验)
异常序列:一段行为序列不符合常规(异常轨迹、异常Log序列)
异常关联/规则:违反常见关联的"反常组合"
要点:异常通常很少、代价高,评估要结合业务后果与告警可解释性。
分类 vs 聚类:有老师(有标签)vs 没老师(无标签)
关联 vs 序列:同时出现的关系 vs 按时间先后的关系
预测 vs 描述:预测"将来会怎样" vs 概括"现在/过去是什么样"
异常:少见但重要,重在发现和解释
概念层次:支持"上钻/下钻"的多层汇总,是仪表盘/报表后面的知识骨架。
不同数据存储形式下的挖掘
事务数据库中的挖掘(Transactional DB)
场景:超市小票、购物车、点击会话,每条记录是一桩"交易/事务",包含一组项。
代表任务:关联规则/频繁项集(Market Basket Analysis)
例:{牛奶, 面包} => {黄油},用支持度/置信度衡量"常见度/可靠度"。
为什么重要:算法成熟(Apriori/FP-Growth),能直接落地到定价、陈列、推荐、补货等。
事务数据库挖掘,就是把你手上的每一份"小票"或"记录"都变成情报,通过"支持度"和"置信度"这两个筛子,从海量数据中筛出那些最常出现、最可靠的"黄金搭档",然后把它们变成真金白银的商业决策。
关系型数据库中的挖掘(Relational DB)
关系库有多表/主外键,能描述对象之间的关系,适合做更"结构化"的知识。
四个典型问题:
多维知识:单维"谁买了何物"不够,要加地域/时间/客户分层等多维汇总(可借OLAP的维度层级)多表/多关系挖掘:不仅在一张表里挖,还要跨主外键做联合分析(多关系挖掘、关系模式挖掘)多层级挖掘:地点=区→市→省→国;产品=SKU→品类→部门,支持上钻/下钻的层次模式。
规则评价:同一条强规则在现实可能互相替代/竞争(买A减少买B),要考虑约束、利益、代价等更贴近业务的评估。
关系型数据库挖掘,就是让你利用数据库中已经存在的各种"关系"和"结构",进行一场更深入、更立体、也更贴合商业现实的分析。
它不再是孤立地看一次购买行为,而是把 "谁、在何时、何地、买了什么、他是什么人" 所有这些信息串联起来,让你做出不仅精准、而且明智的决策。
数据仓库中的挖掘(Data Warehouse)
定位:面向主题、支持历史汇总与多维分析的存储。天然适合高层洞察与趋势预测。
方法:在立方体(Cube)上作切片/旋转,再叠加挖掘算法(OLAM:联机分析挖掘)。
价值:把"OLAP的快汇总"+"挖掘的找规律"合在一起,既快又有结论。
数据仓库中的挖掘,就是将"OLAP的宏观、快速洞察能力"与"数据挖掘的微观、深度规律发现能力"完美结合。
在关系---对象模型演进下的新型数据库
对象-关系/可扩类型:支持复杂对象、用户自定义类型/方法;可直接在库里存时间、空间、图像等富数据。
研究点:如何把这些复杂字段的比较/相似度/索引/抽象层级,和挖掘算法自然对接。
这种新型数据库就像给了我们一个能存储任何复杂事物的"万能工坊",但随之而来的挑战是,我们必须为这个工坊里的每一种新工具(复杂数据类型)都配备一套新的 "使用说明书"(比较、索引、分层方法),并教会传统的挖掘算法如何按照这些新说明书来工作。
面向应用的新型"数据源"里的挖掘
空间/工程/日志/多媒体/时态序列等已经很常见。
典型需求:
时空:在时间+地理上找轨迹、热点与相关性;
工程/日志:长期监控,做健康度评估、异常预警;
多媒体:从内容特征中抽取可用标签与相似度,服务检索/推荐。
难点:数据大+结构复杂+半结构化,要有专用特征/索引/相似度与可扩模型。
面向这些新型数据源的挖掘,就像是从传统的"矿业"升级为现代的"尖端科研"。它要求我们针对每一种特定的数据环境(空间、媒体、日志等),打造一套专用的"科研仪器"(特征、索引、算法和模型),才能从这些更复杂、更海量的数据中,提取出前所未有的宝贵洞察。
Web 数据源中的挖掘(Web Mining)
数据特点:来源分散、格式多(结构化/半结构化/非结构化),变化快。
三大流派:
Web 结构挖掘:分析超链接结构(PageRank/HITS思想),找权威页/枢纽页、社区、主题图谱Web 使用挖掘:挖日志(URL、IP、时间等),做画像、导航优化、性能监测、异常检测
Web 内容挖掘:对文本/多媒体做主题、情感、摘要、实体抽取等(Text Mining/信息抽取)
关键难点:
异构数据源(不同站点风格各异)
半结构化(HTML/XML)
动态变化(页面/兴趣频繁更新)
粗糙集方法及其在挖掘中的应用
粗糙集理论的核心思想
想象一下,我们有一些信息不完整或模糊的对象。粗糙集提供了一种方法来描述这些"模糊"的集合。
它的核心工具是上近似和下近似:
下近似: 可以100%确定属于这个模糊集合的所有对象。这是该集合的核心部分。
上近似: 可能属于这个模糊集合的所有对象。这是该集合的边界部分,包含了所有不确定的对象。
通过这两个概念,一个模糊的集合就被一个清晰的"下近似"和一个更大的"上近似"框定起来了。
重要基本概念
1. 信息系统: 这就是我们的数据表。比如文中的汽车数据库表。
U: 所有行(对象)的集合,比如10辆汽车。
A: 所有列(属性)的集合,比如Power, Turbo, Weight。
V: 每个属性可能的取值,比如Power可以是HIGH, MEDIUM, LOW。
f: 信息函数,就是表格里每个单元格的值。比如f(1, Power) = HIGH。
2. 条件属性与决策属性:
条件属性 (C): 相当于我们分析问题的"原因"或"输入"。例子中是 {Power, Turbo}。
决策属性 (D): 相当于我们想预测的"结果"或"输出"。例子中是 {Weight}。
3. 等价类: 把所有在某些属性上取值完全相同的对象归为一组,这个组就是一个等价类。这就像我们按照某些特征给人分组一样。
基于条件属性的等价类 (E): 按(Power, Turbo)分组,得到了 E1, E2, E3, E4 四个组。
基于决策属性的等价类 (Y): 按Weight分组,得到了 Y1, Y2, Y3 三个组。
**4. 约简:**寻找最小的属性组合,使得它划分出的等价类和原来所有属性划分出的效果一样。目的是为了简化规则,去掉冗余信息。
如何从粗糙集中生成规则
规则的形式是:如果 条件,那么 决策。
规则是通过比较条件等价类 (E) 和决策等价类 (Y) 的关系得出的。
规则的可信度 (cf) 如何计算?
可信度 (cf) = |E ∩ Y| / |E|
(即:在条件组E中,有多少个对象也属于决策组Y)
例子中的规则推导:
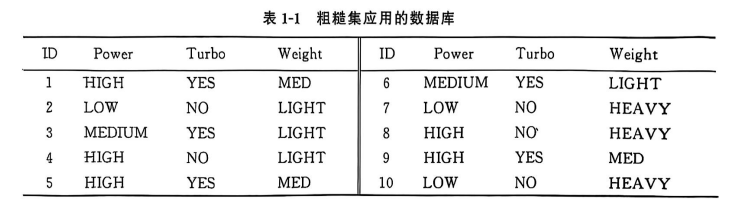
规则 r11:
条件 (E1): Power = HIGH 且 Turbo = YES -> 包含对象 {1, 5, 9}
决策 (Y1): Weight = MED -> 包含对象 {1, 5, 9}
分析: E1 中的所有对象 {1,5,9} 都在 Y1 中。所以这是一个确定性规则(可信度=1.0)
规则: Power = HIGH ∧ Turbo = YES → Weight = MED (cf = 3/3 = 1.0)
规则 r22:
条件 (E2): Power = LOW 且 Turbo = NO -> 包含对象 {2, 7, 10}
决策 (Y2): Weight = HEAVY -> 包含对象 {7, 8, 10}
分析: E2 中的对象 {2,7,10},只有 {7,10} 在 Y2 中。对象2不在。所以这是一个不确定规则(可信度<1.0)
规则: Power = LOW ∧ Turbo = NO → Weight = HEAVY (cf = 2/3 ≈ 0.67)
规则 r23:
条件 (E2): Power = LOW 且 Turbo = NO -> 包含对象 {2, 7, 10}
决策 (Y3): Weight = LIGHT -> 包含对象 {2, 3, 4, 6}
分析: E2 中的对象 {2,7,10},只有 {2} 在 Y3 中。
规则: Power = LOW ∧ Turbo = NO → Weight = LIGHT (cf = 1/3 ≈ 0.33)
规则 r43:
条件 (E4): Power = HIGH 且 Turbo = NO -> 包含对象 {4, 8}
决策 (Y3): Weight = LIGHT -> 包含对象 {2, 3, 4, 6}
分析: E4 中的对象 {4,8},只有 {4} 在 Y3 中。
规则: Power = HIGH ∧ Turbo = NO → Weight = LIGHT (cf = 1/2 = 0.5)
数据挖掘的应用分析
是什么
把已有的业务/科研数据,按一定目标,用统计与算法提炼"可用的信息和规律",反过来指导业务决策或科学发现。
能做什么(常见场景)
商业:客户分群、精准营销、交叉销售/推荐、用户流失预警、信用评分、反欺诈、运营提效。
科研:生物信息(基因、蛋白)、天文、图像/文本挖掘等。
社会治理/安全:舆情分析、入侵检测、异常行为识别、风险预警等。
价值
降成本(自动化分析)、增收入(找机会)、控风险(提前预警)、提效率(让决策更快)
数据挖掘与 CRM(客户关系管理)
CRM 是什么
围绕客户"获客---留存---价值提升"的一套理念与系统。
在 CRM 里挖什么(典型子任务)
客户分群/分类:把客户按特征分成可运营的群体。
客户画像/特征分析:提炼"某类客户长什么样,喜欢什么"。
流失分析:找出"可能流失的人"和"流失原因"。
信用/评分:评估还款或欺诈风险。
交叉/关联销售:哪些商品/服务经常一起被买。
活动效果评估:活动带来的净增转化。
怎么落地(数据与流程)
数据来源=交易、浏览/点击、客服工单、渠道触达、问卷等 → 清洗与特征工程 → 训练模型(分类/回归/序列/规则/推荐)→ 联线部署与A/B→ 看指标(AUC、F1、Lift、留存率、ARPU 等)→ 持续迭代。
常用方法
分群:K-means、层次聚类。
评分/流失:逻辑回归、GBDT、XGBoost、时间序列。
关联:Apriori、FP-Growth。
推荐:协同过滤、序列推荐。
注意点
合规(隐私、同意、最小化收集)、可解释(为什么这么判)、实时性(触达窗口)、冷启动与漂移。
数据挖掘与社会网络
社会网络是什么
把人或实体看作"点",关系看作"边"的网络;研究其结构与传播规律。经典概念:
结构洞(连接不同群体的"桥"位点能带来资源优势)
小世界(路径很短)
无标度/幂律(少数节点连接很多)
能做什么
社区发现(谁和谁是一圈)
影响力/传播(找关键节点、算传播范围)
链接预测(未来可能产生关系的点对)
内容/谣言传播分析、舆情监测
推荐与反垃圾/反刷(利用关系特征)
常用方法
图算法:Louvain/Label Propagation、PageRank/HITS、最短路、随机游走。
学习范式:图嵌入(Node2Vec)、图神经网络(GCN/GAT)、时序图模型。
数据与挑战
数据异构(文本/图像/日志)、半结构化(XML/JSON/HTML)、动态变化快、跨站整合难、隐私合规。