大家好,这里是架构资源栈!
大家总说模型会 过拟合数据 ,但很少有人注意到:Prompt 也会过拟合模型。
很多开发者遇到过这种情况:新模型明明更强,但接入后效果不升反降,甚至用户还嫌弃。比如当 Cursor 第一次接入 GPT-5 时,网上一度骂声一片,直到官方和 OpenAI 一起做了 Prompt 调优,体验才逐渐反转。
 结论很简单: 👉 模型升级时,不重写 Prompt = 用老钥匙开新锁,必然卡壳。
结论很简单: 👉 模型升级时,不重写 Prompt = 用老钥匙开新锁,必然卡壳。
下面从三个角度聊聊,为什么 Prompt 不能一招鲜吃遍天。
1. Prompt 格式差异
不同模型对输入格式的"偏好"差异巨大。
- OpenAI 系列 :从早期到现在,几乎一直偏爱 Markdown,官方教程和系统提示大多都是这种格式。
- Anthropic Claude 系列 :则更适配 XML。Claude 3.5 的系统提示直接就是 XML,因为它在训练中接触了大量 XML 数据,自然更懂这一套。
案例: 同样一段 XML 格式 Prompt,Claude 表现出色,而 GPT-4 可能就完全不行。
所以换模型时,如果你还抱着老 Prompt 不放,就像让一个没学过 LaTeX 的人硬读公式,效果可想而知。
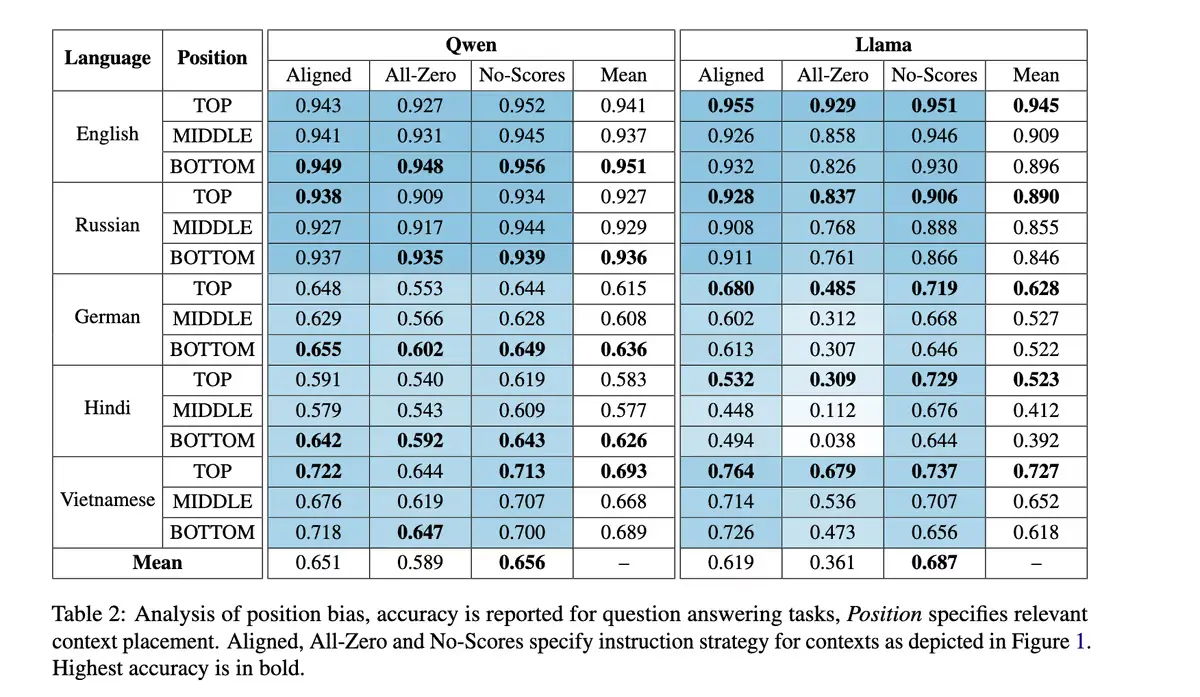
2. 位置偏差(Position Bias)
模型并不会平均对待 Prompt 的每个位置。
- 有的模型更看重开头;
- 有的模型则对结尾权重更高;
- 甚至同一个模型,在不同语言、不同上下文下,偏好还会变化。
一篇 2025 年的跨语言研究表明:
- Qwen 系列 → 更在意最后的内容;
- Llama 系列 → 更看重开头。
这意味着:在 RAG 场景下,你放在 Prompt 开头还是结尾的示例,直接决定了模型能不能答好问题。
3. 模型固有偏差(Model Biases)
除了格式和位置,不同模型本身也有"性格差异"。
- 显性偏差:比如部分中文大模型会主动规避敏感话题。
- 隐性偏差:有的模型默认话多啰嗦,有的则简洁直接;有的喜欢生成额外字段,有的更保守。
问题是,大多数人写 Prompt 时都在 跟模型的偏差作对。 比如反复加"Be concise",但如果新模型本身已经足够简洁,这些约束就成了赘余,反而影响效果。
3a. 学会顺势而为
与其强行矫正,不如利用模型的默认倾向。 如果模型总会加几个 JSON 字段,与其拼命阻止,不如考虑接受并调整下游逻辑,结果可能更稳定。
关键结论
- 模型不是"即插即用"的,Prompt 过拟合是常态;
- 每换一个模型,都要 重写 / 调优 Prompt;
- 甚至在同一模型的升级版本之间,Prompt 也可能需要微调;
- 最佳实践:写完就 eval,和模型"磨合",顺着它的天性去设计。
换句话说: 👉 Prompt 就是"模型的 API",新版本上线,API 可能改了,你不更新调用方式,必然踩坑。
给公众号读者的实操建议
如果你在做 LLM 应用,可以尝试以下三步:
- 对比 Prompt 格式:在新模型上分别用 Markdown 和 XML 测试同一任务,看看差异;
- 测试位置敏感性:调换上下文示例的顺序,观察输出变化;
- 监控默认风格:比如字数长短、是否爱加说明、输出结构是否稳定,决定要不要顺势而为。
这样,你就能快速判断 是否需要重写 Prompt,而不是把问题归咎于"新模型不行"。
喜欢就奖励一个"👍"和"在看"呗~
