前言
本文为我最近一段时间以来对pytorch一些底层原理的使用和认识,着重在**"这技术怎样提高我们的训练效率"**,有以下几个方向
- 超参数调优
- .cuda传递数据
- 混合精度计算
本文目标是针对和我一样刚入门的读者,方便比较快的上手,然后我后续也会慢慢深入理解
超参数调优
有几个参数是我们需要注意的,
DataLoader方面:
- batch_size,这里我们需要针对我们GPU的显存进行调整,对于我们拷贝的不同项目,我们尤其要注意这里的大小,调整它来适应我们自己的硬件环境
意义就是,batch_size越大,则我们迭代的次数越少,越快执行完,但是可能导致GPU显存溢出
比如我个人的电脑是:rtx4060,具体显存如下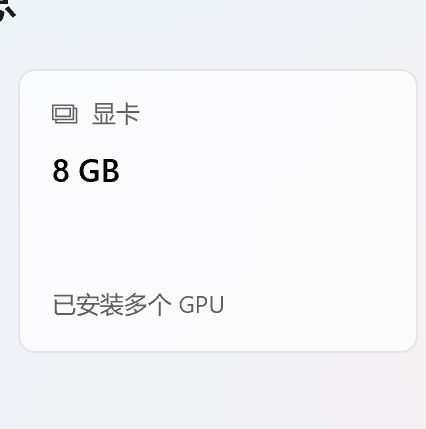
然后我拷贝了一个github项目,发现它超参数的设定是这样:
XML
crop:
type: center
size: [224, 224] # crop image with HxW size
batch_size: 4
n_sup: 183
noise_std: 0.1
workers: 16
mean: [123.675, 116.28, 103.53]
std: [58.395, 57.12, 57.375]
ignore_label: 255那我根据我个人显存的大小,我就要对其batch_size进行调整,否则会OOM错误(显存溢出)
- num_worker:这参数重点是针对CPU的,参考这一篇博文
Pytorch dataloader中的num_workers (选择最合适的num_workers值)_dataloader的numworkers-CSDN博客
总结一下,num_worker是任务运行中,专门创建用来加载数据的子进程数目,将原来一个进程做的任务专门分出加载数据这一个任务,交给一个新的进程做,有点类似内外存交换中的DMA操作,这里主进程类似DMA中的CPU,子进程类似DMA中的DMA控制器。
按照上一篇博文,我在个人电脑运行博文中提到的脚本,可以看出
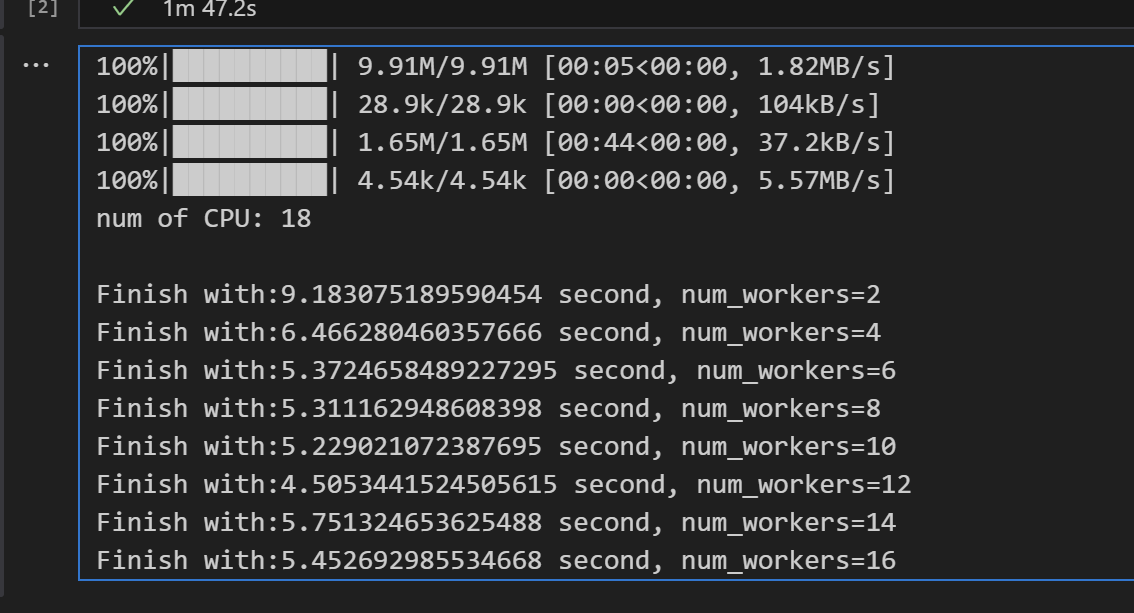
我个人num_workers的极限是16
- ping_memory,参考这篇博文
Pytorch DataLoader pin_memory 理解 - 知乎
总结一下,ping_memory是将内存中的一部分页面专门用来和GPU进行交换数据,因此设置为True可以显著增加速度
cuda传递数据
使用方法:
python
.to(device)参考下面几篇博文
PyTorch 中的数据与模型迁移:理解 .to(device) 的使用 - Jeremy Feng's Blog
pytorch:to()、device()、cuda()将Tensor或模型移动到指定的设备上_to(device)-CSDN博客
然后从AI问答中,还得到了一些关键信息
- CPU→GPU/GPU→CPU 的拷贝是同步操作(会阻塞主线程),且涉及 PCIe 总线传输,耗时比设备内计算高一个数量级;
- 优化建议:批量迁移数据(而非单样本)、尽量减少跨设备拷贝(如训练时全程在 GPU,仅推理结果拷贝回 CPU)。
但是,转移到目标设备,仅仅只是最基础的操作,远远达不到我们充分发挥GPU性能的要求,但这也算最基本的,因此我们也必须了解
混合精度
参考下面博文
我的总结是:python数据类型有fp16,fp32,int8,int16,我们可以知道,对于浮点数和整型的数据,CPU的计算难度不可同日而语,浮点数计算过程往往比整型耗时更多,而浮点数精度越高,往往耗时更多
而混合精度,就是在pytorch计算时选择性的使用高精度的浮点数,这样减少计算量
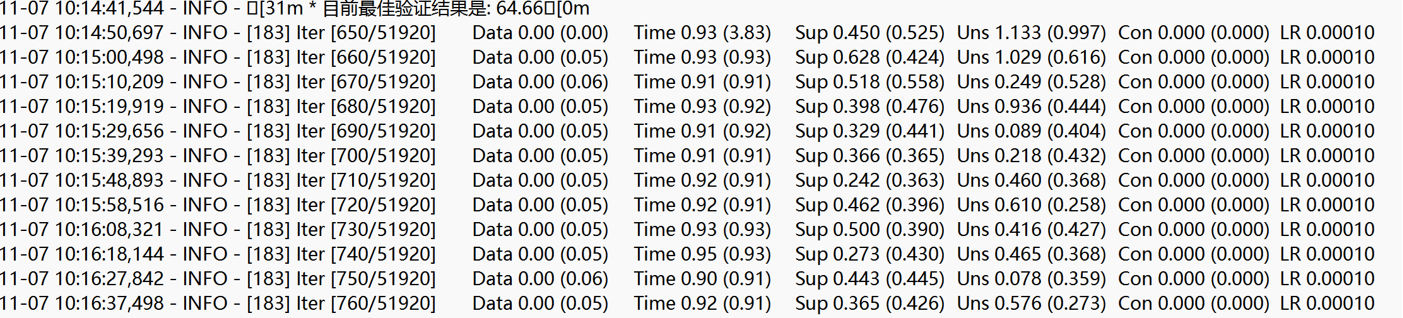
下面是我使用混合精度前的一个批次计算耗时:
使用混合精度后的计算耗时
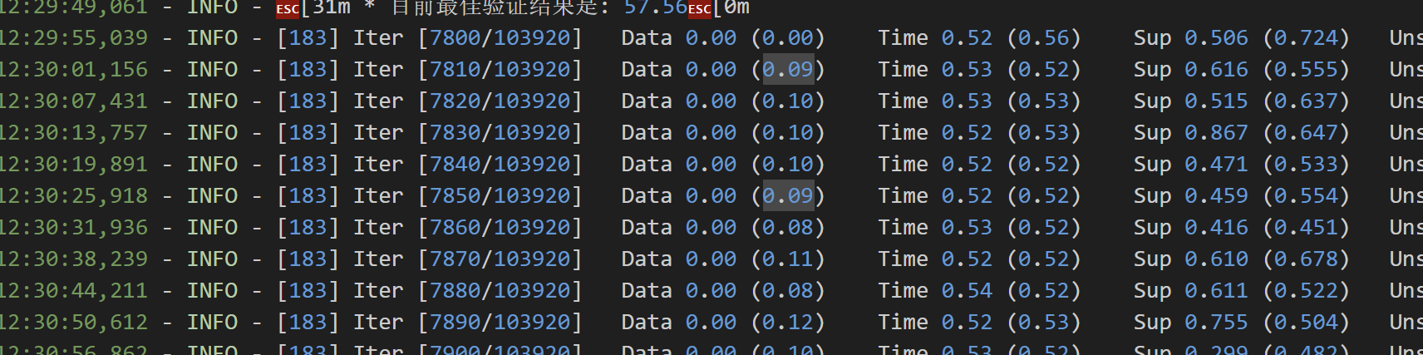
可以看出,提升是非常大的,但是有个不足,因为不同的任务对数据精度要求不一样,因此如果低精度可能会影响我们部分任务的预测结果!!但混合精度带来的提升是很明显的