【Python爬虫基础-3】数据解析
1、XPath解析数据
- XPath
- 全称:XML Path Language是一种小型的查询语言
- 是一门在XML文档中查找信息的语言
- XPath的优点
- 可在XML中查找信息
- 支持HTML的查找
- 可通过元素和属性进行导航
- XPath需要依赖lxml库,安装xml命令
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
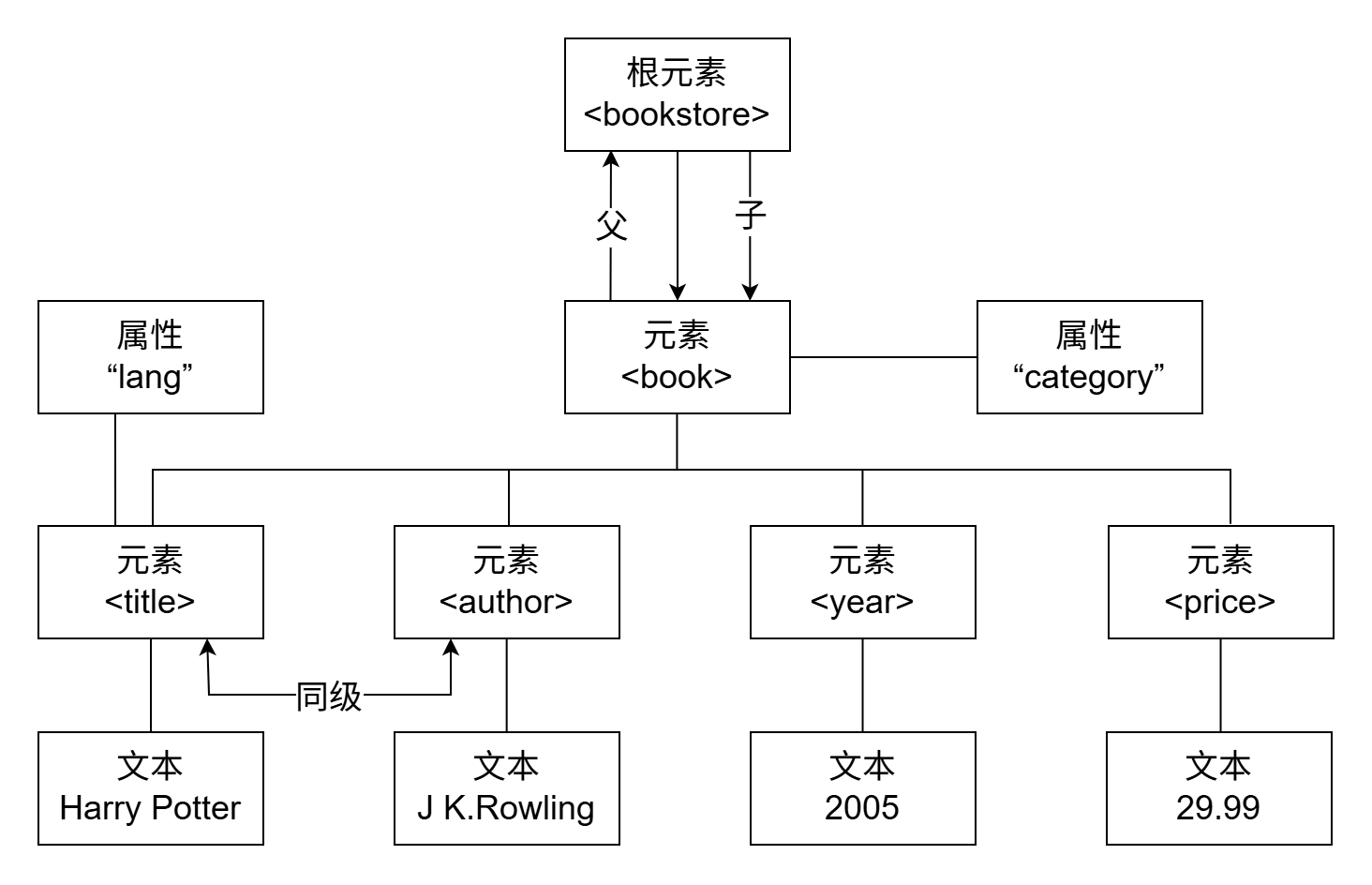
XML的树形结构
html
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J K.Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>XML树形结构图解:
使用XPath选取节点
| 序号 | 表达式 | 描述 |
|---|---|---|
| 1 | nodename | 选取此节点的所有子节点 |
| 2 | / | 从根节点选择 |
| 3 | // | 从匹配选择的当前节点选择文档中的节点,而不考虑他们的位置 |
| 4 | . | 选取当前节点 |
| 5 | .. | 选取当前节点的父节点 |
| 6 | /text() | 获取当前路径下的文本内容 |
| 7 | /@xxx | 提取当前路径下标签的属性值 |
| 8 | |可选符 | 可选若干个路径//pl//div,在当前路径下选取所有符合条件的p标签和div标签 |
XPath选取节点
| 序号 | 表达式 | 描述 |
|---|---|---|
| 1 | xpath('/body/div1') | 选取body下的第一个div节点 |
| 2 | xpath('/body/divlast()') | 选取body下最后一个div节点 |
| 3 | xpath('/body/divlast()-1') | 选取body下倒数第二个div节点 |
| 4 | xpath('/body/divposition()\< 3') | 选取body下前两个div节点 |
| 5 | xpath('/body/div@class') | 选取body下带有class属性的div节点 |
| 6 | xpath('/body/div@class='main'') | 选取body下class属性为main的div节点 |
| 7 | xpath('/body/divprice\>35.00') | 选取body下price的div节点 |
示例代码:
python
import requests
from lxml import etree
url='https://www.qidian.com/rank/yuepiao'
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0'
}
#发送请求
resp=requests.get(url,headers)
e=etree.HTML(resp.text) #类型转换 <class 'lxml.etree._Element'>
names=e.xpath('//div[@class="book-mid-info"]/h4/a/text()')
authors=e.xpath('//p[@class="author"]/a[1]/text()')
#print(names)
#print(authors)
#将names与authors打包
for name,author in zip(names,authors):
print(name,":",author)2、BeautifulSoup解析数据
- BeautifulSoup
- 是一个可以从HTML或XML文件中提取数据的python库。其功能简单而强大、容错能力高、文档相对完善,清晰易懂
- 非Python标准模块,需要安装才能使用
- 在线安装方式:
pip install bs4 -i https://pypi.tuna.tsinghua.edu.cn/simple - 测试方式:
import bs4 - 解析器
- BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果不安装第三方解析器,则Python会使用默认解析器。
| 序号 | 解析器 | 使用方法 | 优点 | 缺点 |
|---|---|---|---|---|
| 1 | 标准库 | BeautifulSoup(html,'html.parser') | 内置标准库,速度适中,文档容错能力强 | Python3.2版本前的文档容错能力差 |
| 2 | lxml HTML | BeautifulSoup(html,'lxml') | 速度快,文档容错能力强 | 安装C语言库 |
| 3 | lxml XML | BeautifulSoup(html,'lxml') | 速度快,唯一支持XML | 安装C语言库 |
| 4 | html5lib | BeautifulSoup(html,'html5lib') | 容错能力强,可生成HTML5 | 运行慢,扩展差 |
示例代码:
python
from bs4 import BeautifulSoup
html='''
<html>
<head>
<title>马士兵教育</title>
</head>
<body>
<h1 class="info bg" float="left">欢迎大家来到马士兵教育</h1>
<a href="http://www.mashibing.com">马士兵教育</a>
<h2><!--注释的内容--></h2>
</body>
</html>
'''
#bs = BeautifulSoup(html,'html.parser') #自带的解析器
bs = BeautifulSoup(html,'lxml')
print(bs.title) #获取标签
print(bs.h1.attrs) #获取h1标签的所有属性
#获取单个属性
print(bs.h1.get('class'))
print(bs.h1['class'])
print(bs.a['href'])
#获取文本内容
print(bs.title.text)
print(bs.title.string)
#获取内容
print(bs.h2.string) #获取到h2标签中的注释的文本内容
print(bs.h2.text) #因为h2标签中没有文本内容BeautifulSoup提取数据的常用方法
| 返回值类型 | 方法 | 功能 | 语法 | 举例 |
|---|---|---|---|---|
| Tag | find() | 提取满足要求的首个数据 | bs.find(标签,属性) | bs.find('div',class_='books') |
| Tag | find_all() | 提取满足要求的所有数据 | bs.find_all(标签,属性) | bs.find_all('div',class_='books') |
示例代码:
python
from bs4 import BeautifulSoup
html='''
<title>马士兵教育</title>
<div class="info" float="left">欢迎来到马士兵教育</div>
<div class="info" float="right" id="gb">
<span>好好学习,天天向上</span>
<a href="http://www.mashibing.com">官网</a>
</div>
'''
bs=BeautifulSoup(html,'lxml')
print(bs.title,type(bs.title))
print(bs.find('div',class_='info'),type(bs.find('div',class_='info'))) #获取第一个满足条件的标签
print('---------------------')
print(bs.find_all('div',class_='info')) #得到的是一个标签的列表
for item in bs.find_all('div',class_='info'):
print(item,type(item))
print('---------------------')
print(bs.find_all('div',attrs={'float':'right'}))
print('===============CSS选择器====================')
print(bs.select("#gb"))
print('-------------------------------------------')
print(bs.select(".info"))
print('-------------------------------------------')
print(bs.select("div>span"))
print('-------------------------------------------')CSS选择器
| 功能 | 举例 |
|---|---|
| 通过ID查找 | bs.select('#abc') |
| 通过class查找 | bs.select('.abc') |
| 通过属性查找 | bs.select(a'class="abc"') |
Tag对象
| 功能 | 举例 |
|---|---|
| 获取标签 | bs.title |
| 获取所有属性 | bs.title.attrs |
| 获取单个属性的值 | bs.div.get('class') bs.div.class bs.a'href' |
案例:爬取淘宝网首页的内容
python
import requests
from bs4 import BeautifulSoup
url = 'https://www.taobao.com/'
header = {'user-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0'}
#构建请求对象
resp = requests.get(url,header)
#print(resp.text)
bs=BeautifulSoup(resp.text,'lxml')
a_list=bs.find_all('a')
print(len(a_list))
for a in a_list:
url=a.get('href')
print(url)
if url==None:
continue3、正则表达式
- 是一个特殊的字符序列,它能帮助用户便捷地检查一个字符串是否与某种模式匹配。
- Python的正则模块是re,是Python的内置模块,不需要安装,导入即可
正则语法:
| 序号 | 元字符 | 说明 |
|---|---|---|
| 1 | . | 匹配任意字符 |
| 2 | ^ | 匹配字符串的开头 |
| 3 | $ | 匹配字符的末尾 |
| 4 | * | 匹配前一个元字符0到多次 |
| 5 | + | 匹配前一个元字符1到多次 |
| 6 | ? | 匹配前一个元字符0到1次 |
| 7 | {m} | 匹配前一个字符m次 |
| 8 | {m,n} | 匹配前一个字符m到n次 |
| 9 | {m,n}? | 匹配前一个字符m到n次,并且取尽可能少的情况 |
| 10 | \\ | 对特殊字符进行转义 |
| 11 | \[\] | 一个字符的集合,可以匹配其中任意一个字符 |
| 12 | | | 逻辑表达式"或",比如a |
| 13 | (...) | 被括起来的表达式作为一个元组。findall()在有组的情况下只显示组的内容 |
特殊序列:
| 序号 | 元字符 | 说明 |
|---|---|---|
| 1 | \A | 只在字符串开头进行匹配 |
| 2 | \b | 匹配位于开头或者结尾的空字符串 |
| 3 | \B | 匹配不位于开头或者结尾的空字符串 |
| 4 | \d | 匹配任意十进制数,相当于0-9 |
| 5 | \D | 匹配任意非数字字符,相当于\^0-9 |
| 6 | \s | 匹配任意空白字符,相当于\\t\\n\\r\\f\\v |
| 7 | \S | 匹配任意空白字符,相当于\^\\t\\n\\r\\f\\v |
| 8 | \w | 匹配任意数字、字母、下划线,相当于a-z A-Z 0-9 |
| 9 | \W | 匹配任意非数字、字母、下划线,相当于\^a-z A-Z 0-9 |
正则处理函数:
| 序号 | 正则处理函数 | 说明 |
|---|---|---|
| 1 | re.match(pattern,string,flags=0) | 尝试从字符串的开始位置匹配一个模式,如果匹配成功,就返回一个匹配成功的对象,否则返回None |
| 2 | re.search(pattern,strinig,flags=0) | 扫描整个字符串并返回第一个成功匹配的对象,如果匹配失败,就返回None |
| 3 | re.findall(pattern,strinig,flags=0) | 获取字符串所有匹配的字符串,并以列表的形式返回 |
| 4 | re.sub(pattern,repl,string,count=0,flags=0) | 用于替换字符串中的匹配项,如果没有匹配的项,则返回没有匹配的字符串 |
| 5 | re.compile(pattern,flag) | 用于编译正则表达式,生成一个正则表达式(Pattern)对象,供match()和search()使用 |
正则表达式使用示例代码:
python
import re
from tokenize import group
s='I study Python3.8 every day'
print('-------match方法,从起始位置开始匹配---------')
print(re.match('I',s).group())
print(re.match('\w',s).group()) #\w匹配字母数字下划线
print(re.match('.',s).group()) # . 匹配任意字符
print('-------search方法,从任意位置开始匹配,匹配第一个---------')
print(re.search('study',s).group())
print(re.search('s\w',s).group())
print('-------findall方法,从任意位置开始匹配,匹配多个---------')
print(re.findall('y',s)) #结果为列表
print(re.findall('Python',s))
print(re.findall('P\w+.\d',s))
print(re.findall('P.+\d',s))
print('-------sub方法,替换功能---------')
print(re.sub('study','like',s))
print(re.sub('s\w+','like',s))4、pyquery解析数据
-
pyquery
- pyquery库是jQuery的Python实现,能够jQuery的语法来操作解析 HTML文档,易用性和解析速度都很好
- 前提条件:对CSS选择器与jQuery有所了解
- 非Python标准模块,需要安装
- 安装方式:
pip3 install pyquery -i https://mirrors.aliyun.com/pypi/simple/ - 测试方式:
import pyquery
- 安装方式:
-
pyquery的初始化方式
字符串方式:
python
from pyquery import PyQuery as pq
html='''
<html>
<head>
<title>PyQuery</title>
</head>
<body>
<h1>PyQuery</h1>
</body>
</html>
'''
doc=pq(html) #创建PyQuery的对象,实际上就是在进行一个类型转换,将str类型转换成PyQuery类型
print(doc)
print(type(doc))
print(type(html))
print(doc('title'))url方式:
python
from pyquery import PyQuery as pq, PyQuery
doc=PyQuery(url='http://www.baidu.com',encoding='utf-8')
print(doc('title'))文件
python
from pyquery import PyQuery as pq, PyQuery
doc=PyQuery(filename='XML文件.html')
print(doc)
print(doc('price'))- pyquery的使用
| 序号 | 提取数据 | 举例 |
|---|---|---|
| 1 | 获取当前节点 | doc('#main') |
| 2 | 获取子节点 | doc('#main').children() |
| 3 | 获取父节点 | doc('#main').parent() |
| 4 | 获取兄弟节点 | doc('#main').siblings()方法 |
| 5 | 获取属性 | doc('#main').attr('href') |
| 6 | 获取内容 | doc('#main').heml() doc('#main').text() |
示例代码:
python
from pyquery import PyQuery
html='''
<html>
<head>
<title>PyQuery</title>
</head>
<body>
<div id="main">
<a href="http://www.mashibing.com">马士兵教育</a>
<h1>欢迎来到</h1>
</div>
<h2>Python学习</h2>
</body>
</html>
'''
doc=PyQuery(html)
#获取节点
print(doc("#main"))
#获取父节点,子节点,兄弟节点
print('----------父节点--------------')
print(doc("#main").parent())
print('----------子节点--------------')
print(doc("#main").children())
print('----------兄弟节点--------------')
print(doc("#main").siblings())
print('----------获取属性--------------')
print(doc('a').attr('href'))
print('----------获取标签内容--------------')
print(doc('#main').html())
print(doc('#main').text())示例代码:
python
#爬取起点小说网
import requests
from pyquery import PyQuery
url='https://www.qidian.com/rank/yuepiao'
headers={'user-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0'}
resp=requests.get(url,headers=headers)
#初始化PyQuery对象
doc=PyQuery(resp.text) #使用字符串初始化方式初始化PyQuery对象
#a_tag=doc('h4 a')
names=[a.text for a in doc('h4 a')] #列表生成式
authors=doc('p.author a')
author_lst=[]
for index in range(len(authors)):
if index%2==0:
author_lst.append(authors[index].text)
for mane,authors in zip(names,author_lst):
print(name,':',author)