在 Python 数据处理场景中,将列表(List)数据导出为 Excel 文件是高频需求(如数据报表、批量数据导出等)。相比于传统的openpyxl、xlwt等库,Free Spire.XLS for Python 是一款免费的 Excel 处理库,无需依赖 Microsoft Excel,支持完整的 Excel 文件创建、编辑和格式设置,尤其适合新手快速实现列表到 Excel 的转换。
本文将从环境准备、基础示例到进阶优化演示如何用 Free Spire.XLS for Python 实现列表转 Excel,覆盖以下核心场景:
- 基础实战:导出一维列表到 Excel(单列)
- 进阶实战:导出二维列表到 Excel(带表头)
- 实战拓展:导出字典列表到 Excel(贴合业务场景)
1. 安装免费库
Free Spire.XLS for Python 支持 Python 3.6 及以上版本,通过 pip即可安装:
bash
pip install Spire.XLS.Free2. 基础实战:导出一维列表到 Excel(单列)
实现思路
- 创建空白工作簿,获取默认工作表;
- 遍历一维列表,将每个元素写入 Excel 的指定列(如A列);
- 保存 Excel 文件并释放资源。
Python 代码
python
from spire.xls import *
from spire.xls.common import *
# 定义要转换的一维列表
one_dimensional_list = ["Python", "Java", "C++", "JavaScript", "Go"]
# 1. 创建工作簿对象
workbook = Workbook()
# 2. 获取第一个工作表(默认创建)
worksheet = workbook.Worksheets[0]
# 3. 设置工作表名称
worksheet.Name = "编程语言列表"
# 4. 遍历列表,写入Excel(从第1行第1列开始)
for index, value in enumerate(one_dimensional_list):
# 行号从1开始
row = index + 1
# 写入A列(第1列)
worksheet.Range[row, 1].Text = value
# 5. 保存Excel文件(支持.xlsx/.xls/.xlsm等格式)
output_path = "一维列表转Excel.xlsx"
workbook.SaveToFile(output_path, FileFormat.Version2016)
# 6. 释放资源(重要,避免内存泄漏)
workbook.Dispose()
print(f"一维列表已成功导出到:{output_path}")代码解析
Workbook():创建 Excel 工作簿对象,相当于新建一个 Excel 文件;Worksheets[0]:获取工作簿中第一个工作表(索引从0开始);Range[row, col]:定位 Excel 单元格,行/列号均从1开始;Text:设置单元格的文本内容;SaveToFile():保存文件,第二个参数指定Excel版本;Dispose():释放工作簿资源,避免占用内存。
效果图:
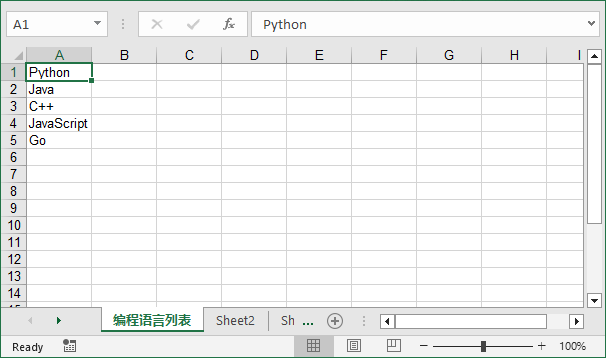
3. 进阶实战:导出二维列表到 Excel(带表头)
实现思路
- 定义二维列表(包含表头和数据);
- 先写入表头行,再遍历数据行逐行写入;
- 可选:设置表头样式(加粗、居中)提升可读性。
完整代码
python
from spire.xls import *
from spire.xls.common import *
# 定义二维列表(表头+数据)
two_dimensional_list = [
["姓名", "年龄", "城市", "职业"], # 表头
["张三", 28, "北京", "工程师"],
["李四", 32, "上海", "产品经理"],
["王五", 25, "广州", "设计师"],
["赵六", 30, "深圳", "开发工程师"]
]
# 1. 创建工作簿
workbook = Workbook()
worksheet = workbook.Worksheets[0]
worksheet.Name = "人员信息表"
# 2. 遍历二维列表,逐行写入Excel
for row_index, row_data in enumerate(two_dimensional_list):
# Excel行号从1开始
current_row = row_index + 1
for col_index, cell_value in enumerate(row_data):
# Excel列号从1开始
current_col = col_index + 1
# 写入单元格内容
worksheet.Range[current_row, current_col].Text = str(cell_value)
# 3. 优化表头样式(加粗、居中)
if current_row == 1:
worksheet.Range[current_row, current_col].Style.Font.IsBold = True
worksheet.Range[current_row, current_col].Style.HorizontalAlignment = HorizontalAlignType.Center
# 4. 自动调整列宽(适配内容长度)
worksheet.AllocatedRange.AutoFitColumns()
# 5. 保存文件
output_path = "二维列表转Excel.xlsx"
workbook.SaveToFile(output_path, FileFormat.Version2016)
workbook.Dispose()
print(f"二维列表已成功导出到:{output_path}")代码解析
- 二维列表遍历:外层循环控制行,内层循环控制列,实现"逐行逐列"写入;
- 表头样式优化:通过
IsBold = True设置加粗,HorizontalAlignType.Center设置水平居中; AllocatedRange.AutoFitColumns():自动调整列宽,避免内容被截断;- 数据类型转换:
str(cell_value)确保数字、字符串等类型统一写入,避免类型报错。
效果图:
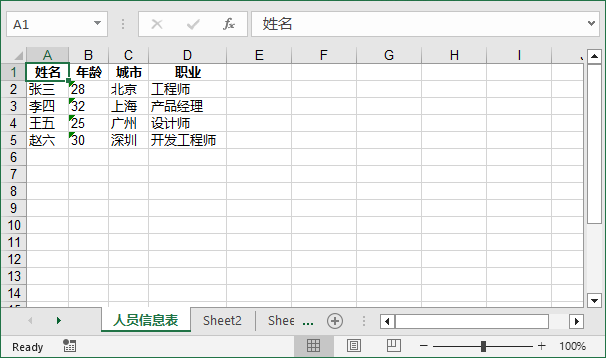
4. 实战拓展:导出字典列表到 Excel(贴合业务场景)
字典列表是 Python 业务开发中最常用的数据格式(如从数据库/接口获取的结构化数据),每个字典代表一行数据,字典的键 对应Excel表头,值对应单元格数据。以下是完整实现方案。
实现思路
- 定义字典列表(每个字典的键为字段名,值为字段值);
- 提取字典的键作为 Excel 表头(需确保字典键一致,或兼容键缺失场景);
- 先写入表头行并设置样式,再遍历字典列表,按表头顺序提取值写入单元格;
- 自动调整列宽,提升 Excel 可读性。
完整代码
python
from spire.xls import *
from spire.xls.common import *
# 定义字典列表(模拟业务场景:从接口/数据库获取的用户数据)
dict_list = [
{"用户ID": 1001, "姓名": "张三", "年龄": 28, "城市": "北京", "注册时间": "2024-01-15"},
{"用户ID": 1002, "姓名": "李四", "年龄": 32, "城市": "上海", "注册时间": "2024-02-20"},
{"用户ID": 1003, "姓名": "王五", "年龄": 25, "城市": "广州", "注册时间": "2024-03-10"},
{"用户ID": 1004, "姓名": "赵六", "年龄": 30, "城市": "深圳", "注册时间": "2024-04-05"}
]
# 1. 创建工作簿和工作表
workbook = Workbook()
worksheet = workbook.Worksheets[0]
worksheet.Name = "用户信息表(字典列表)"
# 2. 提取表头(字典的键)
if not dict_list:
print("字典列表为空,无需导出!")
workbook.Dispose()
exit()
# 以第一个字典的键作为表头(确保所有字典键一致,或参考下方注意事项处理)
headers = list(dict_list[0].keys())
# 3. 写入表头行并设置样式
for col_index, header in enumerate(headers):
current_col = col_index + 1
# 写入表头文本
worksheet.Range[1, current_col].Text = header
# 4. 遍历字典列表,写入数据行
for row_idx, data_dict in enumerate(dict_list):
current_row = row_idx + 2 # 表头占第1行,数据从第2行开始
for col_idx, header in enumerate(headers):
current_col = col_idx + 1
# 提取字典值(用get方法兼容键缺失场景,避免KeyError)
cell_value = data_dict.get(header, "")
# 写入单元格(统一转字符串,避免类型报错)
worksheet.Range[current_row, current_col].Text = str(cell_value)
# 5. 自动调整列宽(适配内容长度)
worksheet.AllocatedRange.AutoFitColumns()
# 6. 保存Excel文件
output_path = "字典列表转Excel.xlsx"
workbook.SaveToFile(output_path, FileFormat.Version2016)
# 7. 释放资源
workbook.Dispose()
print(f"字典列表已成功导出到:{output_path}")代码解析
- 表头提取 :
list(dict_list[0].keys())从第一个字典中提取所有键作为 Excel 表头,是业务场景中最常用的方式; - 兼容键缺失 :
data_dict.get(header, "")替代直接取值data_dict[header],若某个字典缺失指定键,会填充空字符串,避免KeyError报错; - 行号计算 :数据行从第2行开始(
current_row = row_idx + 2),因为第1行已写入表头;
效果图:
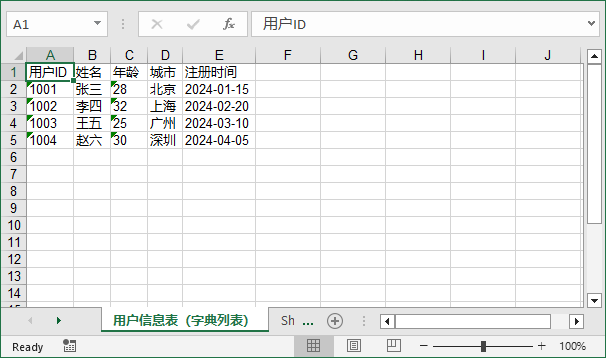
5. 常见问题与注意事项
- 免费版限制:Free Spire.XLS for Python 在读写 .xls 格式的 Excel 文档时,有每个文档 5 个工作表,每个工作表 200 行的限制。读写 .xlsx 格式的 Excel 文档时没有任何限制;
- 中文乱码问题:若导出的Excel出现中文乱码,需确保代码文件编码为 UTF-8,且写入时直接使用字符串(无需额外转码);
- 资源释放 :务必调用
Dispose()释放工作簿资源,否则可能导致文件被占用(无法删除/修改); - 文件格式 :
FileFormat.Version2016对应.xlsx格式,FileFormat.Excel97to2003对应.xls格式(兼容旧版Excel); - 字典列表兼容 :若字典键不一致,优先提取所有唯一键作为表头,并用
get方法取值避免报错。
python
# 提取所有唯一键作为表头
all_headers = set()
for d in dict_list:
all_headers.update(d.keys())
headers = sorted(list(all_headers)) # 排序保证表头顺序固定通过本文的示例,你可以快速实现从简单的一维列表到贴合业务场景的字典列表导出,满足日常数据报表、批量导出等场景需求。如果需要更复杂的 Excel 操作(如合并单元格、设置单元格颜色、插入公式等),可参考官方示例文档进一步拓展。