背景
嘿,兄弟!你是不是也感觉 AI 越来越香,但 Token 账单也越来越"烫"? 💸
GPT-4o、Kimi 这些模型的上下文窗口动不动就几十万、上百万 Token,我们恨不得把整个项目都扔进去。但冷静下来看看账单... ... 哇哦
LLM 的 Token 每一分都是真金白银啊!
当大家都在想办法优化模型、优化算法时,有没有想过,我们每天都在用的 JSON,可能就是那个"背刺"我们 Token 费用的"内鬼"?
JSON 虽好,但它实在是... ... 太!啰!嗦!了!
"内鬼"现形:JSON 到底有多浪费
在 LLM 的世界里,Token 就是钱。表达同样的信息,谁用的 Token 少,谁就是赢家。
不信?我们直接上例子,用事实说话。
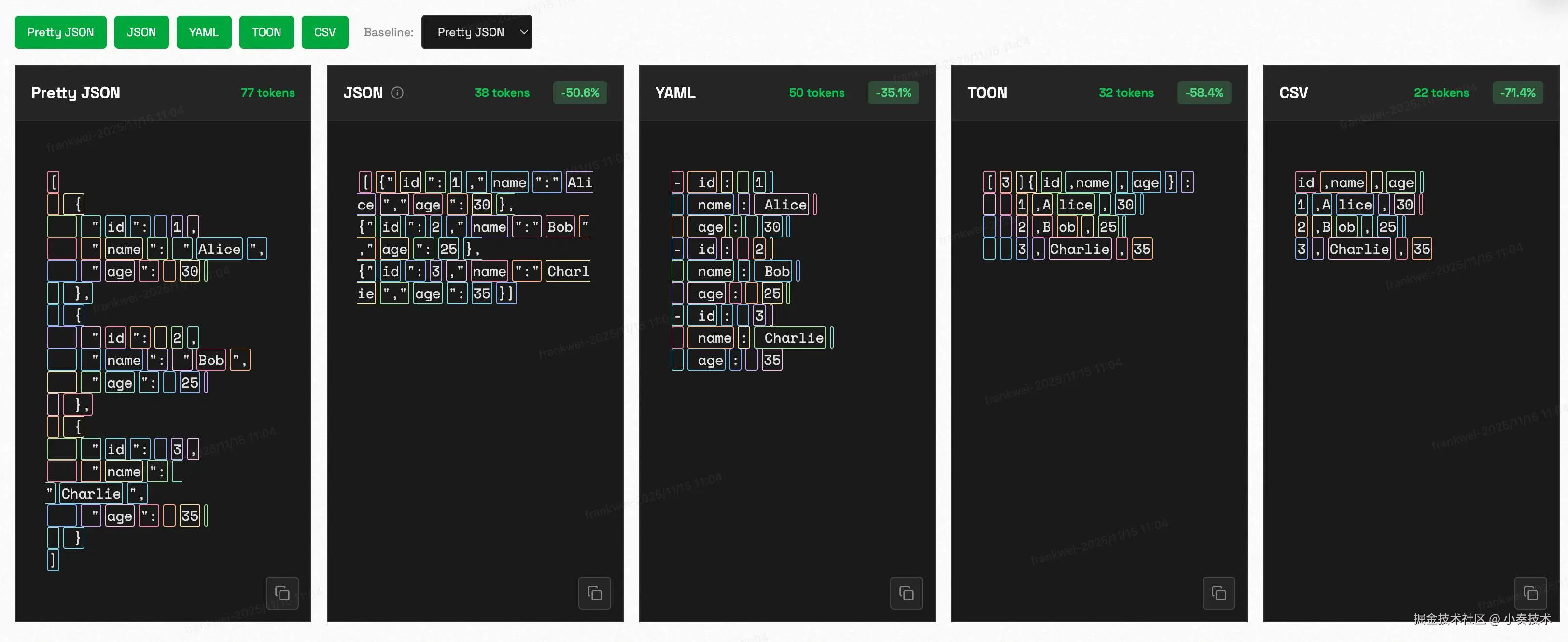
假设我们有这样一个简单的用户列表:
1. 冗长的"老大哥":JSON
标准的 JSON 格式,充满了大括号、双引号和逗号,简直是 Token 杀手。
json
[
{
"id": 1,
"name": "Alice",
"age": 30
},
{
"id": 2,
"name": "Bob",
"age": 25
},
{
"id": 3,
"name": "Charlie",
"age": 35
}
](数数看,光是 name 这个词就重复了 3 遍!)
2. "小清新"但还不够:YAML
YAML 确实清爽了不少,用缩进代替了括号,也去掉了双引号。
yaml
- id: 1
name: Alice
age: 30
- id: 2
name: Bob
age: 25
- id: 3
name: Charlie
age: 35嗯,进步了,但不多。id, name, age 这些键名还是在无情地重复。
3. "抠门"的王者:TOON 登场!
TOON (Token-Oriented Object Notation)闪亮登场,它用了一种近乎"变态"的方式来压缩信息:
TOON
[3]{id,name,age}:
1,Alice,30
2,Bob,25
3,Charlie,35看明白了吗?3 表示有3个对象,{id,name,age} 只定义了一次"表头",后面的数据就像 CSV 一样紧凑排列。
没有对比就没有伤害! 同样的数据,TOON 的 Token 占用量简直是"骨折价"!
啥是 TOON?为 LLM 而生的"省钱利器"
TOON(面向 Token 的对象表示法)就是这么一个专为 LLM 提示词而生的、紧凑且人类可读的数据格式。
它能表示和 JSON 一模一样的对象、数组和数据类型,但它的语法就是为了最小化 Token 使用而设计的。
你可以把它理解为 YAML 的嵌套结构 + CSV 的表格布局 = TOON
TOON 最擅长处理的场景,就是我们最常见的**"结构一致的对象数组"**。在实现 CSV 般紧凑的同时,它又提供了清晰的结构信息({key1, key2}:),帮助 LLM 更可靠地解析和验证数据。
注意: TOON 并非银弹。如果你的数据是深度嵌套或结构极其不统一的,那 JSON 可能还是老老实实的选择。但在"对象数组"这个 LLM 最常见的场景下,TOON 简直无敌。
数据为证:TOON 到底有多能打?
光说不练假把式。Chase Adams 大佬做了一组非常直观的基准测试,对比了 JSON、YAML、TOON 和 CSV 的 Token 效率。
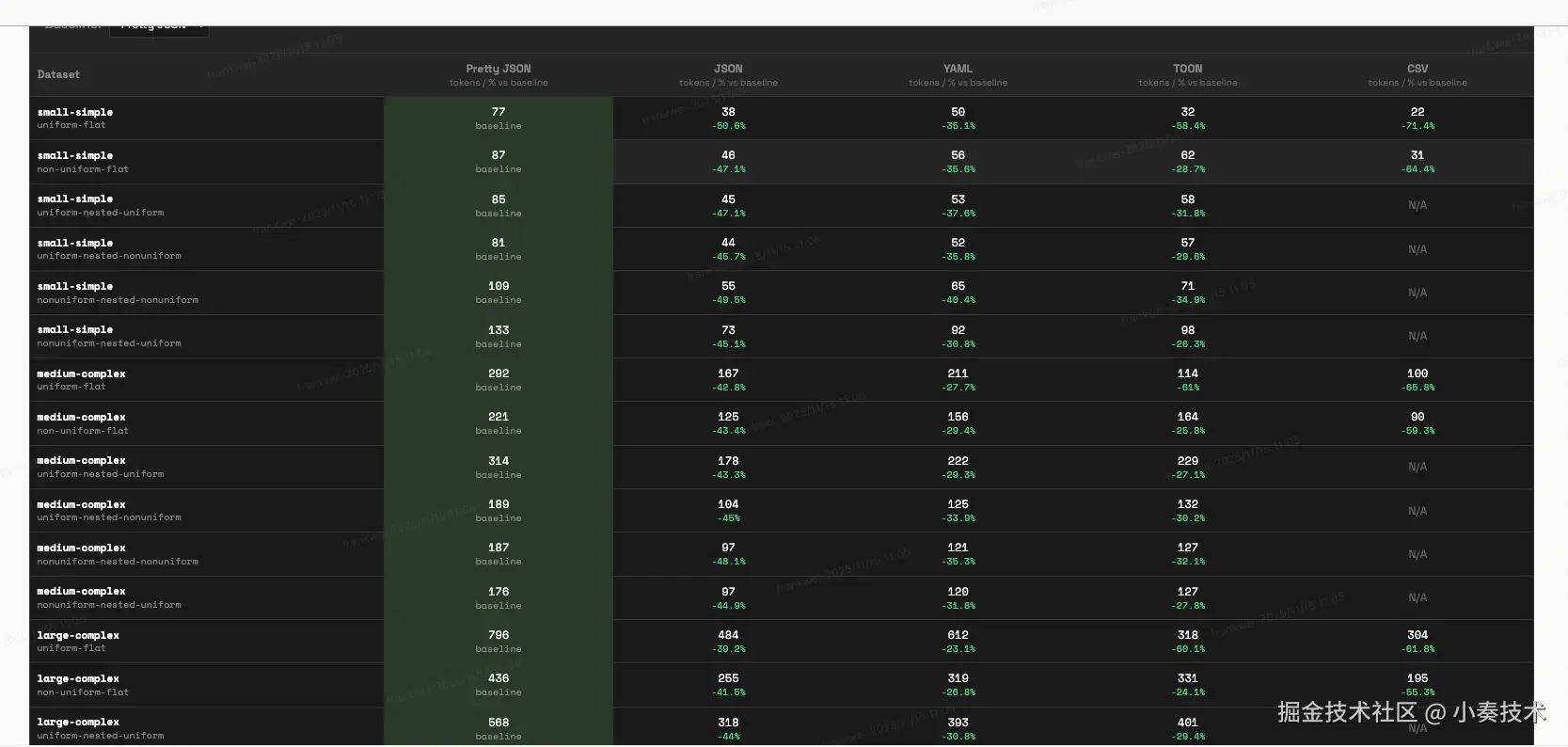
结论一目了然:
CSV 是 Token 效率的"天花板",但它无法表示嵌套结构,而且没有元数据,LLM 很容易"读歪"。
TOON 稳坐第二把交椅,效率直逼 CSV,但它保留了完整的结构信息。
JSON 和 YAML... ... 两位老大哥,在 Token 效率上被 TOON 吊打。
如何在 LLM 中"无痛"用上 TOON?
你可能会想:"哇,这么牛?那我岂不是要重构整个系统?"
完全不用
官方推荐的架构是这样的:
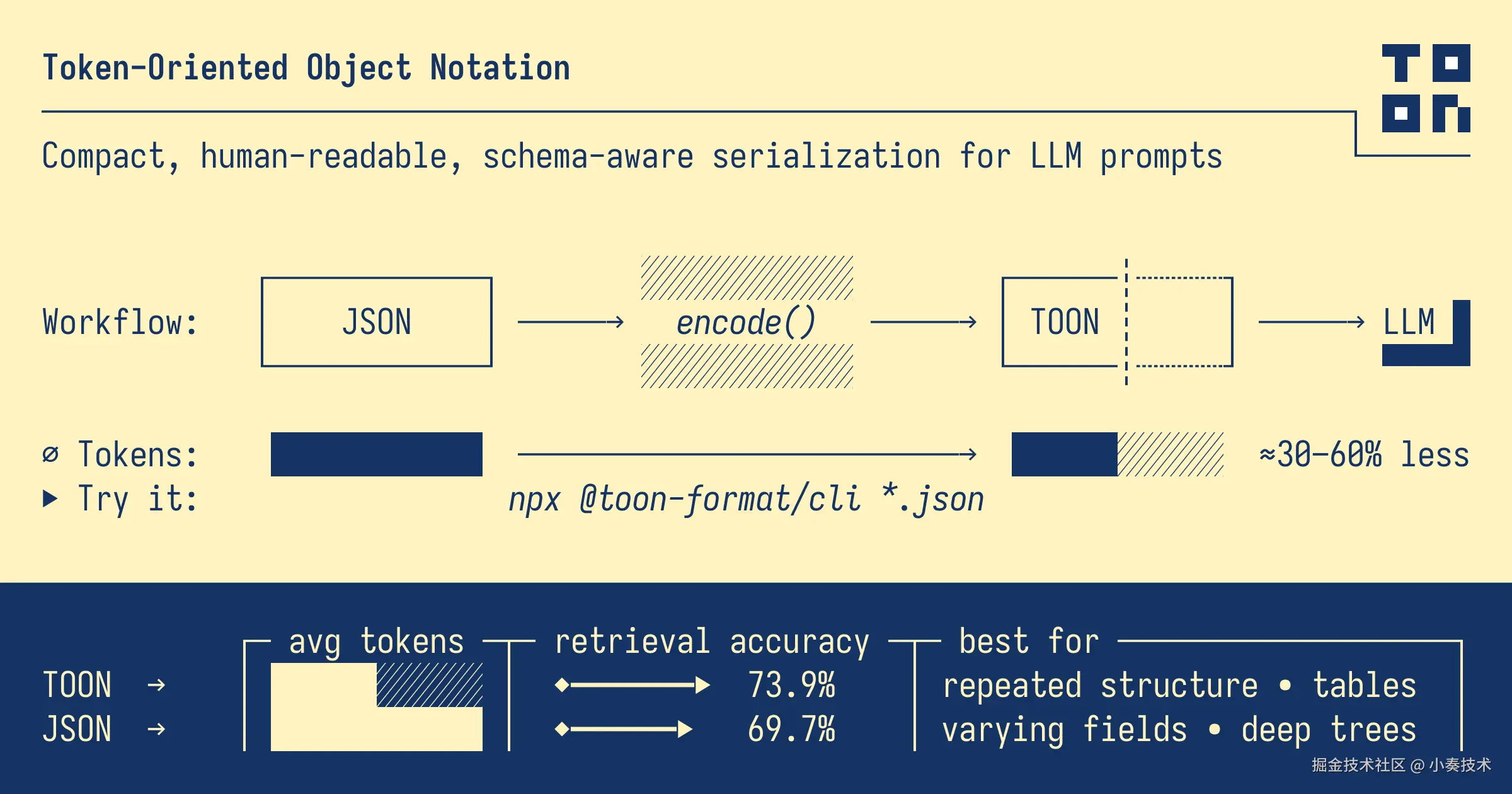
看懂了吗?TOON 只是一个**"转换层"**。
你的系统内部,该用 JSON 还是用 JSON,啥也不用改。
在调用 LLM 之前,你只需加一个编码步骤,把 JSON 编码(Encode) 成 TOON 格式再发送。
LLM 返回 TOON 格式的数据后,你再解码(Decode) 成 JSON 给系统用。
你就把它当成一个"中间件",在和 LLM 交互的"最后一公里"上帮你省钱
别再浪费 Token 了!
在 LLM 时代,Token 效率就是核心竞争力。
JSON 是一个伟大的格式,但在 LLM 交互这个新场景下,它显得既臃肿又昂贵。
TOON 提供了一个完美的替代方案:它在保留 JSON 完整表达能力的同时,实现了接近 CSV 的 Token 效率。
如果你还在为高昂的 LLM Token 费用而头疼,如果你还在忍受 JSON 带来的冗余,那么,是时候给你的系统"升个舱"了