一、特征归一化方法(Min-Max或StandardScaler) ⭐️
- 不同维度的数值范围相差太大,模型训练时:👇🏻
- 梯度会不稳定 🧵
- 某些特征被"超大值"主导 👁
- 最终收敛慢、效果差 💥
- 因此用
Min-Max或StandardScaler把值缩放到:👇🏻
0~1或均值 0、方差 1- 让模型"更容易学习"。
(一)、Min-Max 归一化(0-1 标准化)🍭

将特征缩放到 0~1 区间。
1、公式 📚
x′=x−xminxmax−xmin x' = \frac{x - x_{\min}}{x_{\max} - x_{\min}} x′=xmax−xminx−xmin
2、举例 🐰
python
from sklearn.preprocessing import MinMaxScaler # 从 sklearn 导入 Min-Max 归一化工具
import pandas as pd # 导入 pandas 库用于数据处理
# 创建示例数据,包含两列 A 和 B
df = pd.DataFrame({
"A": [10, 20, 30, 40], # A 列 4 个数值
"B": [100, 150, 200, 350] # B 列 4 个数值
})
# 初始化 Min-Max 缩放器,默认将数据缩放到 0~1 范围
scaler = MinMaxScaler()
# 使用缩放器对数据进行归一化(fit:计算 min/max,transform:执行映射)
scaled_data = scaler.fit_transform(df)
# 将结果转换回 DataFrame,并保留原来的列名
df_scaled = pd.DataFrame(scaled_data, columns=df.columns)
# 打印归一化后的 DataFrame
print(df_scaled)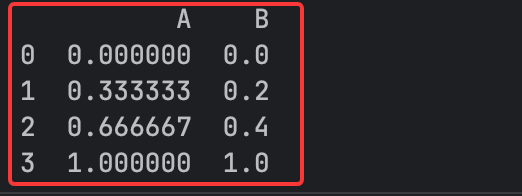
(二)、StandardScaler(Z-score 标准化)🍭

将数据变成 均值=0、标准差=1 的分布。
1、公式 📚
x′=x−μσ x' = \frac{x - \mu}{\sigma} x′=σx−μ
2、举例 🐰
python
from sklearn.preprocessing import StandardScaler # 从 sklearn 导入 Z-score 标准化工具
import pandas as pd # 导入 pandas 库,用于表格数据处理
# 创建一个示例 DataFrame,包含两列 A 和 B 的数值
df = pd.DataFrame({
"A": [10, 20, 30, 40], # A 列 4 个数值
"B": [100, 150, 200, 350] # B 列 4 个数值
})
# 初始化 StandardScaler(Z-score 标准化器)
# 该标准化方法会将数据转换为:
# 均值 μ = 0
# 标准差 σ = 1
scaler = StandardScaler()
# 使用标准化器对数据执行 Z-score 标准化
# fit:计算均值 μ 和标准差 σ
# transform:执行 (x - μ) / σ 转换
scaled_data = scaler.fit_transform(df)
# 将返回的 numpy 数组转换回 DataFrame,并保留列名
df_scaled = pd.DataFrame(scaled_data, columns=df.columns)
# 打印标准化后的结果
print(df_scaled)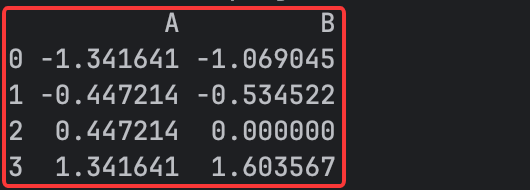
(三)、总结对比 🍭
| 方法 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|
| Min-Max | 数值范围固定在 0-1,直观 | 容易受极值影响 | 神经网络、深度学习 最常用 |
| StandardScaler | 不怕极值,稳定 | 没有固定范围 | 传统机器学习(SVM、KNN、线性模型) |
二、对 CSV 文件中的数据执行归一化 ⭐️
python
import pandas as pd # 导入 pandas,用于读取 CSV 和处理表格数据
from sklearn.preprocessing import MinMaxScaler, StandardScaler # 导入两种常用归一化方法(此处只用 MinMaxScaler)
# 读取当前目录下的 data.csv 文件,并加载为 DataFrame
df = pd.read_csv("data.csv")
# 指定需要进行归一化的列名
# 例如:age(年龄)、height(身高)、weight(体重)
# 这里的列名必须是 CSV 文件中真实存在的列
features = ["age", "height", "weight"] # features = list(df.columns) 表示df中的所有列名的列表(list 格式)
# 创建一个 Min-Max 归一化器,将数据缩放到 0~1 区间
scaler = MinMaxScaler()
# 对指定的特征列执行 Min-Max 归一化
# fit_transform:先计算每列的最小值与最大值(fit),再进行缩放(transform)
df[features] = scaler.fit_transform(df[features])
# 打印归一化后的前 5 行,确认结果
print(df.head())