本文档详细描述了我们如何通过流式处理(Streaming)来优化大语言模型(LLM)的响应,以提升用户体验。我们将通过代码实现和性能对比,来展示流式处理的优势。
实际效果
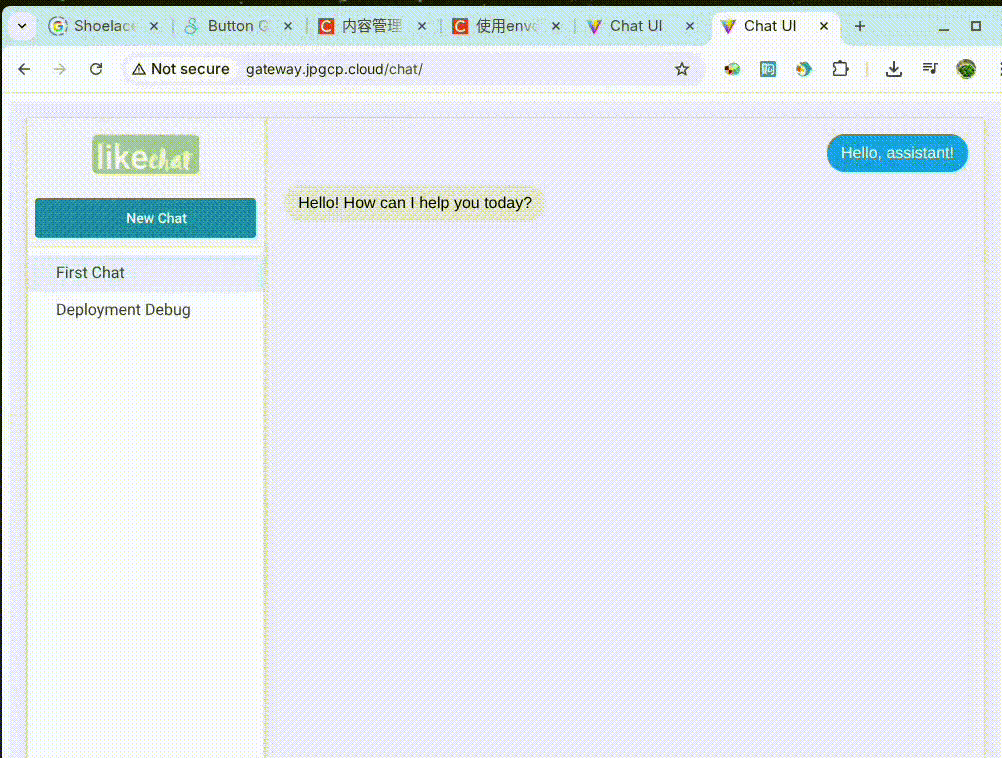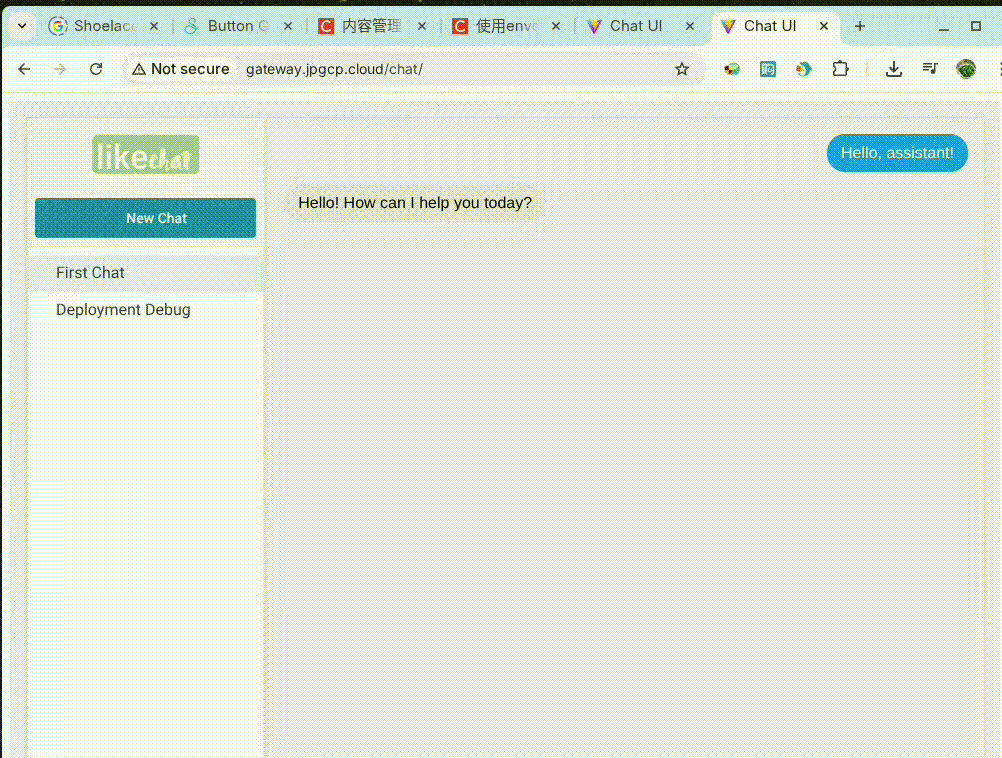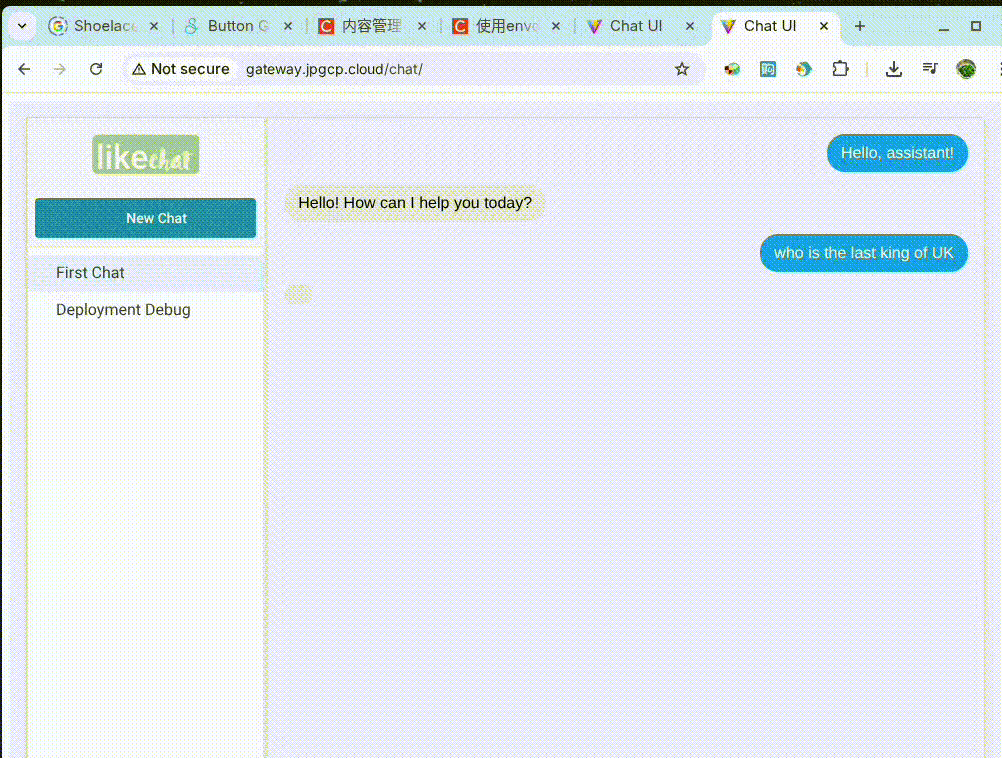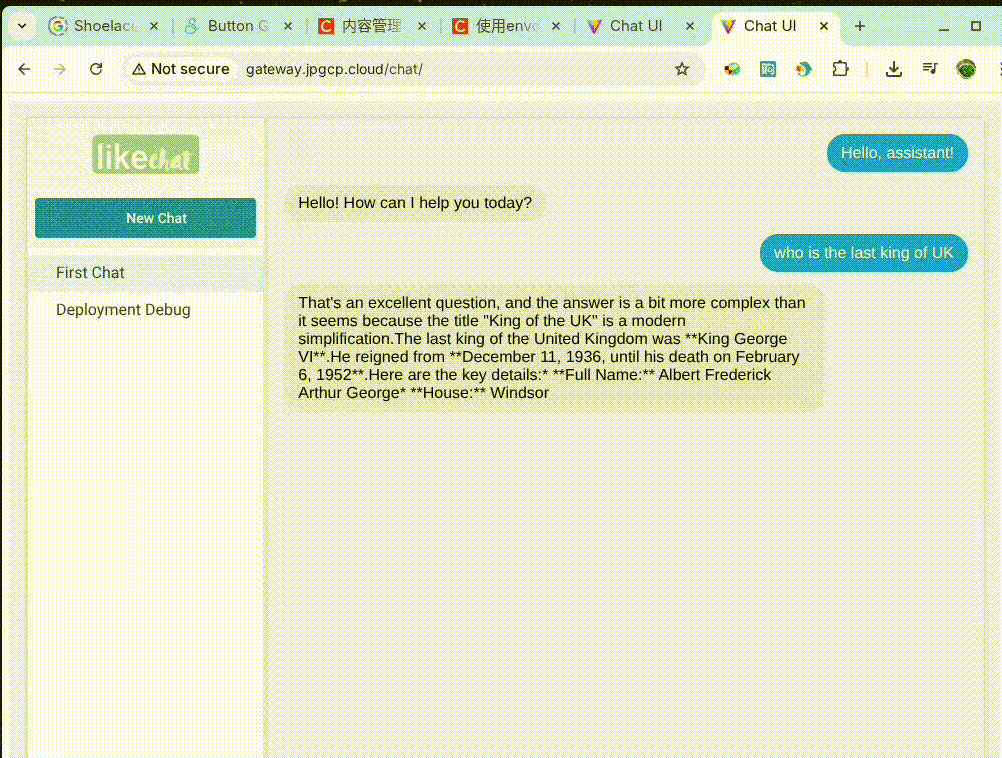
先
-
问题背景
在传统的请求-响应模式中,客户端向服务器发送一个请求,然后必须等待服务器完全处理完该请求并生成完整的响应后,才能接收到数据。对于 LLM 应用来说,这意味着用户在输入问题后,需要等待模型生成完整的答案(可能需要几十秒),这期间界面没有任何反馈,用户体验较差。
-
解决方案:流式处理
为了解决这个问题,我们采用了流式处理技术。其核心思想是,服务器不再一次性地返回完整的响应,而是将响应分割成多个小的数据块(chunks),并逐个地、实时地发送给客户端。
在我们的实现中,我们使用了 FastAPI 的 StreamingResponse,它允许我们创建一个异步生成器,该生成器可以持续地 yield 数据块,直到响应完全结束。
2.1. 后端实现
我们的后端实现主要涉及以下几个部分:
deepseek_chat_model.py: 负责初始化 ChatDeepSeek 模型。
llm_service.py: 封装了与 LLM 模型的交互。
chat_router.py: 定义了 FastAPI 路由和流式生成器。
2.1.1. src/llm/deepseek_chat_model.py
这个文件负责从配置文件中读取 API 密钥和基础 URL,并初始化 ChatDeepSeek 模型。
python
from langchain_deepseek import ChatDeepSeek
from src.configs.config import yaml_configs
def get_deepseek_llm():
"""
Initializes and returns a ChatDeepSeek instance.
"""
api_key = yaml_configs["deepseek"]["api-key"]
base_url = yaml_configs["deepseek"]["base-url"]
llm = ChatDeepSeek(
model="deepseek-chat",
temperature=0.2,
max_tokens=None,
api_key=api_key,
base_url=base_url,
)
return llm
```
2.1.2. src/services/llm_service.py
这个服务类封装了与 LLM 模型的交互,提供了 ainvoke(非流式)和 astream(流式)两种方法。
```python
from langchain_core.language_models import BaseChatModel
from loguru import logger
class LLMService:
def __init__(self, llm: BaseChatModel):
logger.info("Initializing LLMService...")
self.llm = llm
logger.info("LLMService initialized.")
async def ainvoke(self, prompt: str):
logger.info(f"LLMService ainvoking with prompt: {prompt}")
response = await self.llm.ainvoke(prompt)
logger.info("LLMService ainvocation complete.")
return response
def astream(self, prompt: str):
"""Streams the response from the LLM."""
logger.info(f"LLMService astreaming with prompt: {prompt}")
return self.llm.astream(prompt)2.1.3. src/routers/chat_router.py
这是我们的 FastAPI 路由,它定义了 /api/v1/chat 这个端点。它使用 Depends 来注入 LLMService,并通过一个异步生成器 stream_generator 来调用 LLMService 的 astream 方法,然后将返回的数据块逐个地 yield 给客户端。
python
from fastapi import APIRouter, Depends
from starlette.responses import StreamingResponse
from src.llm.deepseek_chat_model import get_deepseek_llm
from src.services.llm_service import LLMService
# ...
def get_llm_service():
"""Dependency to get a singleton instance of LLMService."""
try:
deepseek_model = get_deepseek_llm()
return LLMService(llm=deepseek_model)
except Exception as e:
logger.error(f"Failed to initialize LLM service for dependency: {e}")
return None
# ...
async def stream_generator(prompt: str, llm_service: LLMService):
"""Async generator that yields response chunks from the LLM stream."""
# ...
try:
# Call the astream method on the service
llm_stream = llm_service.astream(prompt)
# Iterate over the stream and yield each chunk to the client
async for chunk in llm_stream:
if hasattr(chunk, 'content') and chunk.content:
yield f"data: {chunk.content}\n\n"
# ...
@router.post("/chat")
async def chat(request: ChatRequest, llm_service: LLMService = Depends(get_llm_service)):
# ...
return StreamingResponse(stream_wrapper(), media_type="text/event-stream")2.2. yield 的作用:流式处理的核心
在我们的实现中,yield 关键字是实现流式处理的核心。它在两个关键位置发挥作用:
在 stream_generator 中:
python
yield f"data: {chunk.content}\n\n"在 StreamingResponse 中: FastAPI 在内部处理 stream_wrapper 生成器时,也是通过 yield 来逐块发送数据。
专业解释
当一个函数包含 yield 关键字时,它就不再是一个普通的函数,而是一个生成器(Generator)。
yield 在 stream_generator 中:
当我们调用 stream_generator 时,它不会立即执行函数体,而是返回一个生成器对象。
async for chunk in llm_stream: 循环每次从 LLM 模型获取一个数据块(chunk)。
python
yield f"data: {chunk.content}\n\n" 这行代码的作用是:暂停函数的执行,并将 f"data: {chunk.content}\n\n" 这个值作为当前迭代的结果发送出去。
当外部代码(在这里是 stream_wrapper)请求下一个值时,stream_generator 会从上次暂停的地方恢复执行,直到遇到下一个 yield 或函数结束。
StreamingResponse 如何使用 yield:
FastAPI 的 StreamingResponse 接收一个生成器(在我们的例子中是 stream_wrapper)。
它在内部迭代这个生成器。每当 stream_generator yield 一个数据块时,StreamingResponse 就会立即将这个数据块通过 HTTP 连接发送给客户端,而不会等待整个响应生成完毕。
这个过程会一直持续,直到生成器执行完毕,此时 StreamingResponse 会关闭 HTTP 连接。
这个机制实现了服务器和客户端之间的持续通信通道,数据可以源源不断地从服务器流向客户端。
通俗解释
我们可以把这个过程比作看一场正在直播的足球比赛。
非流式处理(传统方式):
这就像是等待比赛结束后,一次性地观看完整的比赛录像。你必须等到终场哨声吹响,电视台把90分钟的比赛全部录制打包好,然后才能开始观看。在等待的90分钟里,你什么也看不到,只能干等。
流式处理(我们的实现):
这就像是直接观看电视直播。
yield 在 stream_generator 中:可以看作是解说员。他不会等到比赛结束才说话,而是每当有精彩瞬间(比如进球、犯规、换人),他就会立即 yield 一句解说词(一个数据块)。
StreamingResponse:可以看作是电视台。它不会把所有解说词都攒起来,而是一旦收到解说员 yield 的一句话,就立刻通过电视信号(HTTP 连接)把它广播给千家万户(客户端)。
你(客户端):坐在电视机前,几乎是实时地听到解说员的每一句话,看到球场上的每一个动作。虽然整场比赛(完整的 LLM 响应)还没结束,但你已经可以持续地获取信息,体验非常好。
通过这种方式,yield 就像一个聪明的"暂停-继续"按钮,它让服务器能够"边说边送",而不是"说完再说",从而实现了流畅的流式体验。
2.3. 前端实现
在前端,我们可以使用 fetch API 或 EventSource API 来接收服务器发送的流式数据。每当接收到一个新的数据块时,我们就可以立即将其追加到界面上,从而实现打字机一样的效果。
- 性能对比:流式 vs. 非流式
为了量化流式处理的优势,我们编写了一个 pytest 测试用例,分别测试了 invoke(非流式)和 stream(流式)两种模式下的响应时间。
test/services/test_deepseek_chat_model.py:
python
def test_deepseek_chat_model_invoke():
# ...
start_time = time.time()
result = model.invoke(prompt)
end_time = time.time()
response_time = end_time - start_time
logger.info(f"Invoke mode - Total response time: {response_time:.4f} seconds")
# ...
def test_deepseek_chat_model_stream():
# ...
start_time = time.time()
stream = model.stream(prompt)
# ...
for chunk in stream:
if not first_chunk_received:
time_to_first_chunk = time.time() - start_time
logger.info(f"Stream mode - Time to first chunk: {time_to_first_chunk:.4f} seconds")
first_chunk_received = True
# ...
total_stream_time = time.time() - start_time
logger.info(f"Stream mode - Total response time: {total_stream_time:.4f} seconds")
# ...3.1. 测试结果
我们的测试结果非常清晰地展示了流式处理的优势:
非流式(Invoke)模式:
总响应时间:7.31 秒
流式(Stream)模式:
首个数据块响应时间:1.03 秒
总响应时间:30.93 秒
3.2. 结果分析
从测试结果中我们可以看到:
用户感知延迟:在流式模式下,用户在 1.03 秒 内就看到了第一个数据块,这给了用户一个"系统正在工作"的即时反馈。而在非流式模式下,用户需要等待 7.31 秒 才能看到任何内容。
总响应时间:流式处理的总时间(30.93 秒)比非流式处理(7.31 秒)要长。这是因为流式处理需要逐块地生成和传输数据,而 invoke 模式则是一次性地在服务器端生成所有内容。
- 结论
尽管流式处理的总时间更长,但它通过显著降低首次响应时间,极大地提升了用户体验。对于任何需要与 LLM 进行交互的应用来说,流式处理都是一个必不可少的优化手段。