1、安装jdk、scala(提前安装准备)
[root@keep-hadoop ~]# java -version
java version "1.8.0_172"
Java(TM) SE Runtime Environment (build 1.8.0_172-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.172-b11, mixed mode)
[root@keep-hadoop ~]# scala -version
Scala code runner version 2.11.8 -- Copyright 2002-2016, LAMP/EPFL2、下载安装包
https://downloads.apache.org/spark/
3、解压安装包到指定目录
[root@keep-hadoop hadoop]# tar -zxvf spark-1.6.3-bin-hadoop2.6.tgz -C /usr/local/src/4、配置环境变量
[root@keep-hadoop ~]# vim /etc/profile
export SPARK_HOME=/usr/local/src/spark-2.0.2-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
[root@keep-hadoop ~]# source /etc/profile5、修改Spark配置文件
[root@keep-hadoop conf]# cp spark-env.sh.template spark-env.sh
[root@keep-hadoop conf]# vim spark-env.sh
export SCALA_HOME=/usr/local/src/scala-2.11.8
export JAVA_HOME=/usr/local/src/jdk1.8.0_144
export HADOOP_HOME=/usr/local/src/hadoop-2.6.1
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_IP=master
export SPARK_LOCAL_DIRS=/usr/local/src/spark-2.0.2-bin-hadoop2.6
export SPARK_DRIVER_MEMORY=1G6、启动集群
[root@keep-hadoop sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/src/spark-2.0.2-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.master.Master-1-keep-hadoop.out
localhost: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/src/spark-2.0.2-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-keep-hadoop.out
[root@keep-hadoop sbin]# jps
17763 SecondaryNameNode
18102 NodeManager
17496 NameNode
17608 DataNode
31337 Master
17978 ResourceManager
31436 Worker
31628 Jps7、验证
# 本地模式
spark_path:
[root@keep-hadoop spark-2.0.2-bin-hadoop2.6]# bin/run-example SparkPi 10 --master local[2]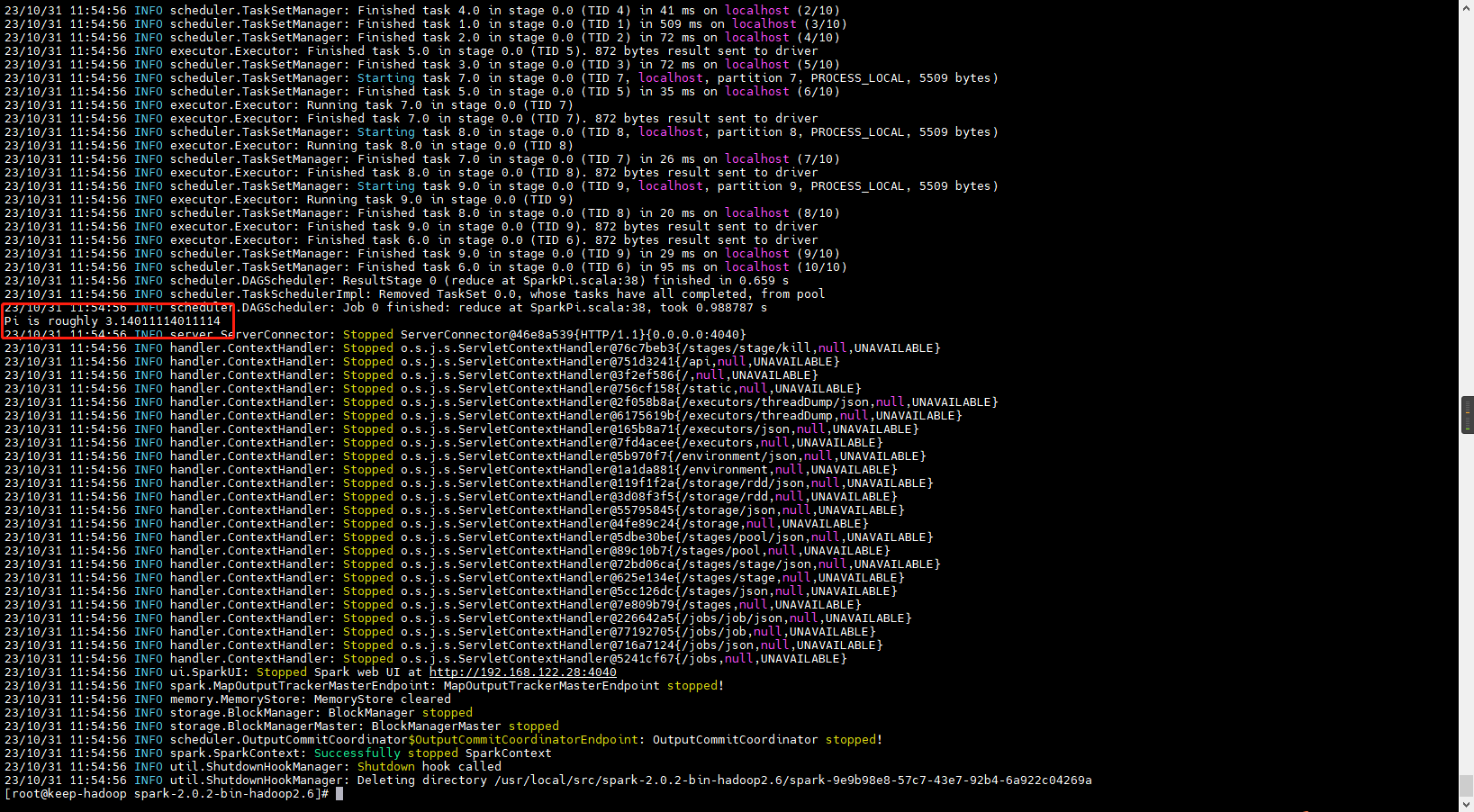
# 集群Standalone
spark_2.x:
[root@keep-hadoop spark-2.0.2-bin-hadoop2.6]# bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://192.168.122.28:7077 examples/jars/spark-examples_2.11-2.0.2.jar 10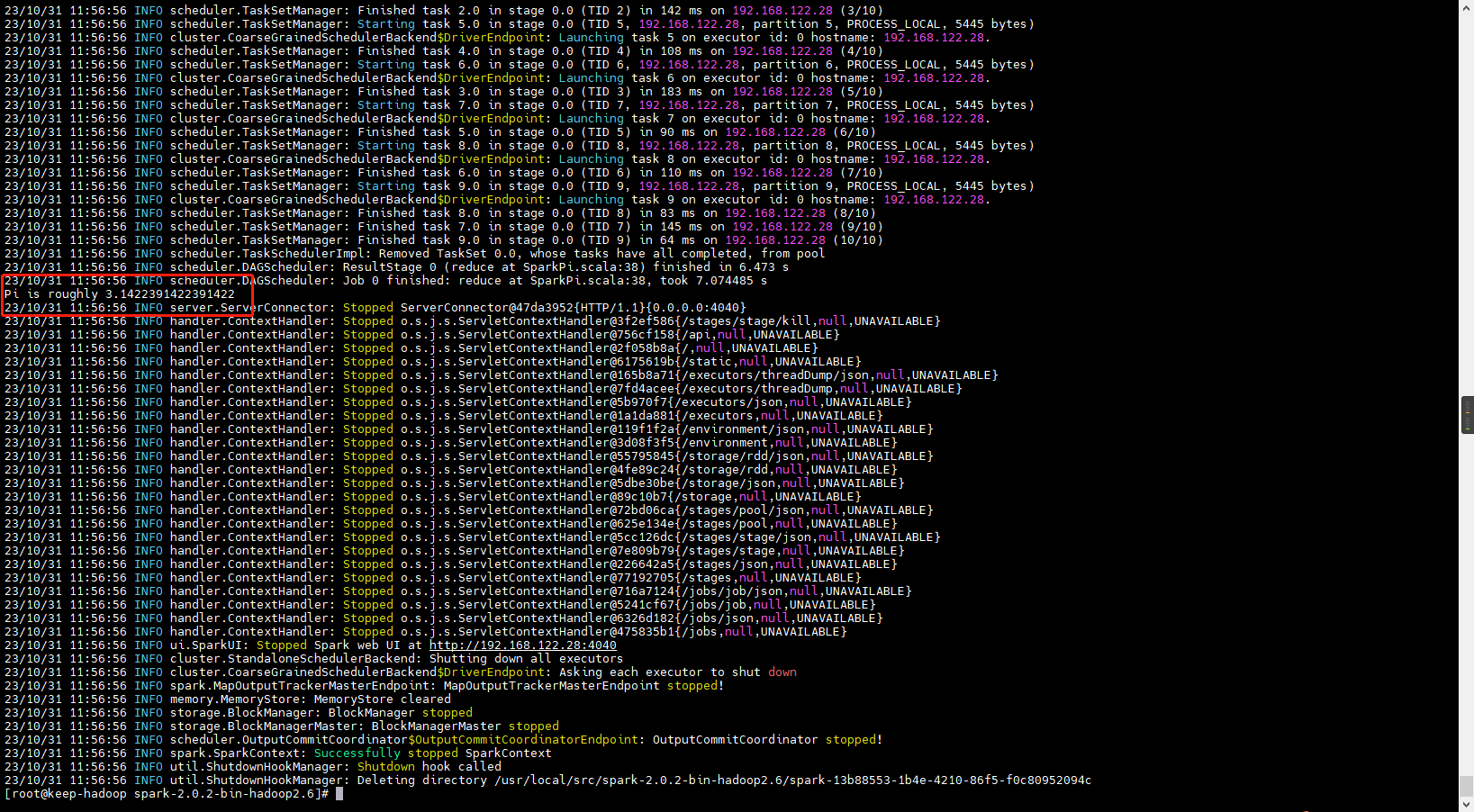
# 集群spark on Yarn
spark_2.x:
[root@keep-hadoop spark-2.0.2-bin-hadoop2.6]# bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster examples/jars/spark-examples_2.11-2.0.2.jar 10
8、网页监控面板
http://192.168.122.28:8080