中文分词全切分算法
摘要
本文档详细介绍了中文分词全切分算法的实现原理和应用场景。该算法基于字典匹配和深度优先搜索(DFS),结合记忆化递归优化,能够找出给定文本在字典约束下的所有可能切分方式。全切分是中文分词的基础技术,为后续的最优切分选择、歧义消解等任务提供重要支持。
核心内容:
- 任务概述:实现基于字典的中文文本全切分,找出所有可能的词语组合方式
- 算法原理:使用深度优先搜索遍历所有可能的切分路径,通过记忆化递归避免重复计算
- 技术特点:时间复杂度优化、空间复杂度控制、结果完整性保证
- 应用场景:中文分词系统、自然语言处理、搜索引擎、文本分析、机器翻译等多个领域
一、任务介绍
1.1 任务概述
中文分词全切分任务是指:给定一个中文句子和一个词典,找出该句子所有可能的词语切分方式。每种切分方式都是将句子划分为若干个连续的词语序列,且每个词语都必须在词典中存在。
示例:
- 输入 :句子
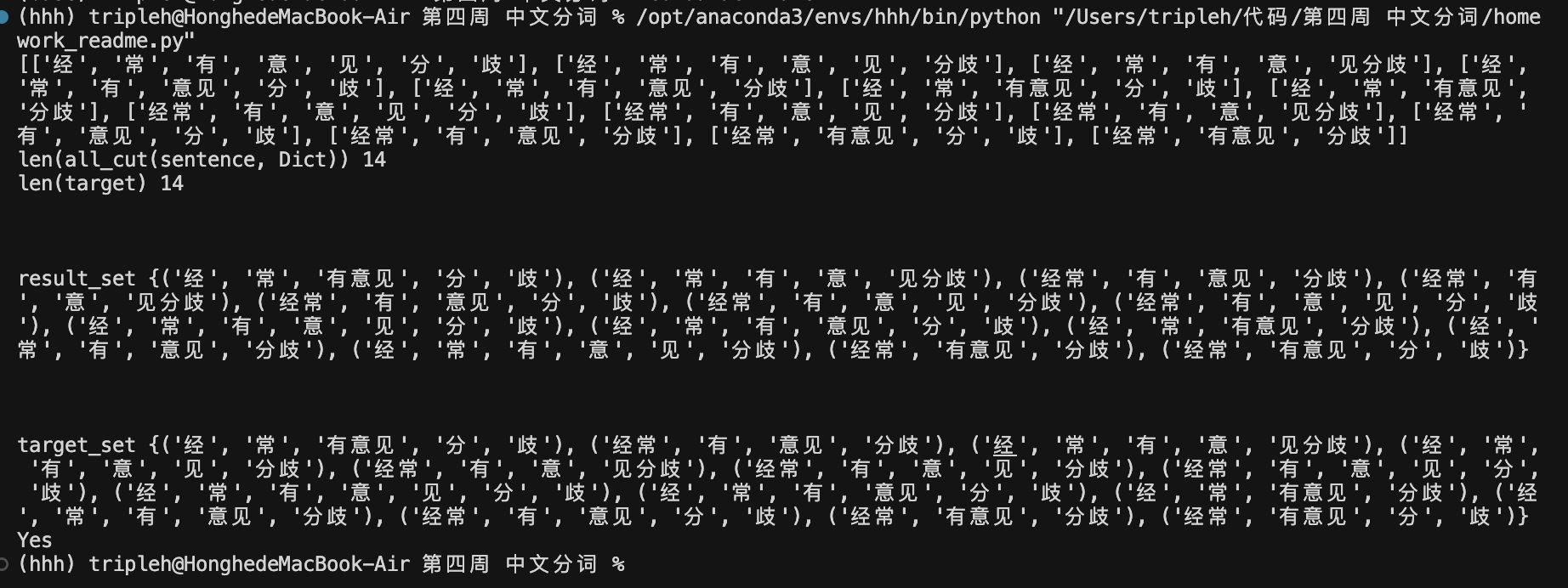
"经常有意见分歧",词典包含{"经常", "经", "常", "有", "有意见", "意见", "分歧", "分", "歧", ...} - 输出 :所有可能的切分方式,如:
['经常', '有意见', '分歧']['经常', '有', '意见', '分歧']['经', '常', '有意见', '分歧']- ...(共14种切分方式)
1.2 任务特点
- 完整性:必须找出所有可能的切分方式,不能遗漏
- 正确性:每个切分结果中的词语都必须在词典中存在
- 无重复:相同的切分方式只出现一次
- 覆盖性:切分结果必须覆盖整个句子,不能有遗漏的字符
1.3 任务挑战
- 组合爆炸:随着句子长度和词典复杂度增加,可能的切分方式呈指数级增长
- 歧义处理:中文存在大量歧义,同一段文本可能有多种合理的切分方式
- 效率优化:需要在保证完整性的同时,尽可能提高算法效率
- 内存管理:大量切分结果需要合理的内存管理策略
二、任务背景介绍
2.1 中文分词的重要性
中文分词是中文自然语言处理的基础任务,因为:
- 中文特点:中文文本没有像英文那样的空格分隔,词语之间紧密相连
- 语义理解:正确的分词是理解文本语义的前提
- 下游任务:分词质量直接影响词性标注、句法分析、语义分析等后续任务
2.2 全切分的意义
全切分是中文分词的基础步骤,具有以下重要意义:
- 歧义发现:通过全切分可以发现文本中的所有歧义切分
- 最优选择:为后续的最优切分算法(如基于统计、基于规则的方法)提供候选集
- 系统测试:用于测试和评估分词系统的完整性
- 算法基础:是其他分词算法(如最大匹配、最短路径等)的基础
2.3 字典匹配方法
字典匹配是中文分词最基础的方法:
- 正向最大匹配(FMM):从左到右,每次匹配最长的词
- 逆向最大匹配(RMM):从右到左,每次匹配最长的词
- 双向匹配:结合正向和逆向匹配的结果
- 全切分:找出所有可能的切分方式(本任务)
2.4 算法演进
中文分词算法的发展历程:
- 基于规则:早期方法,依赖人工规则和词典
- 基于统计:利用语料库统计信息,如N-gram模型
- 基于机器学习:使用HMM、CRF等模型
- 基于深度学习:使用RNN、LSTM、BERT等神经网络模型
全切分作为基础方法,仍然在研究和应用中发挥重要作用。
三、代码逻辑详解
3.1 整体架构
代码采用**深度优先搜索(DFS)和记忆化递归(Memoization)**相结合的方法:
输入:句子 sentence,词典 Dict
输出:所有可能的切分方式列表
1. 将词典转换为集合,提高查找效率
2. 使用DFS递归遍历所有可能的切分路径
3. 使用记忆化避免重复计算
4. 返回所有切分结果3.2 核心函数分析
3.2.1 all_cut(sentence, Dict) 主函数
python
def all_cut(sentence, Dict):
word_set = set(Dict.keys()) # 将词典转换为集合,O(1)查找
n = len(sentence) # 句子长度
memory = {} # 记忆化字典,存储已计算的结果
def dfs(i): # 内部递归函数
# ...递归逻辑...
result = dfs(0) # 从位置0开始递归
return result关键设计:
- 集合优化 :使用
set存储词典,查找时间复杂度从O(n)降到O(1) - 记忆化字典 :
memory存储已计算的结果,避免重复计算 - 递归入口:从位置0(句子开头)开始递归
3.2.2 dfs(i) 递归函数详解
这是算法的核心,采用深度优先搜索策略:
python
def dfs(i):
# 1. 递归出口:已到达句子末尾
if i == n:
return [[]] # 返回空列表的列表,表示一种切分方式
# 2. 记忆化检查:如果已计算过,直接返回
if i in memory:
return memory[i]
# 3. 初始化结果列表
result = []
# 4. 尝试所有可能的词语(从位置i开始)
for j in range(i + 1, n + 1):
words = sentence[i:j] # 提取子串 sentence[i:j]
if words in word_set: # 如果该子串在词典中
# 5. 递归处理剩余部分
end_results = dfs(j) # 获取从位置j开始的所有切分方式
# 6. 组合当前词和后续切分结果
for end_result in end_results:
result.append([words] + end_result)
# 7. 存储结果到记忆化字典
memory[i] = result
return result3.3 算法执行流程示例
以句子 "经常有意见分歧" 为例,演示算法执行过程:
步骤1:从位置0开始(dfs(0))
位置0: "经"
├─ 尝试 "经" (0:1) → 在词典中 ✓
│ └─ 递归 dfs(1) → 处理剩余部分 "常有意见分歧"
│
├─ 尝试 "经常" (0:2) → 在词典中 ✓
│ └─ 递归 dfs(2) → 处理剩余部分 "有意见分歧"
│
└─ 其他尝试(如 "经常有")→ 不在词典中 ✗步骤2:处理位置1(dfs(1))
位置1: "常"
├─ 尝试 "常" (1:2) → 在词典中 ✓
│ └─ 递归 dfs(2) → 处理剩余部分 "有意见分歧"
│
└─ 其他尝试 → 不在词典中 ✗步骤3:处理位置2(dfs(2))
位置2: "有"
├─ 尝试 "有" (2:3) → 在词典中 ✓
│ └─ 递归 dfs(3) → 处理剩余部分 "意见分歧"
│
└─ 尝试 "有意见" (2:5) → 在词典中 ✓
└─ 递归 dfs(5) → 处理剩余部分 "分歧"步骤4:递归终止
当到达句子末尾(i == n)时,返回 [[]],表示一种完整的切分方式。
3.4 记忆化优化原理
问题:在递归过程中,可能会多次计算相同位置的切分结果。
示例:
- 路径1:
"经"→"常"→"有"→ ... - 路径2:
"经常"→"有"→ ...
两条路径都会调用 dfs(2)(处理"有意见分歧"),如果不使用记忆化,会重复计算。
解决方案:
python
if i in memory:
return memory[i] # 直接返回已计算的结果效果:
- 时间复杂度:从O(2^n)降低到O(n²)
- 空间复杂度:O(n²)存储记忆化结果
3.5 关键代码细节
3.5.1 递归出口设计
python
if i == n:
return [[]] # 注意:返回的是包含空列表的列表为什么返回 [[]]?
- 当到达句子末尾时,表示已经完成了一种切分方式
- 返回
[[]]使得后续的[words] + end_result能够正确拼接 - 例如:
['分歧'] + []=['分歧']✓
3.5.2 切分结果组合
python
for end_result in end_results:
result.append([words] + end_result)逻辑:
end_results是从位置j开始的所有切分方式- 每个
end_result是一个列表,如['意见', '分歧'] [words] + end_result将当前词与后续切分组合,如['有'] + ['意见', '分歧']=['有', '意见', '分歧']
3.5.3 范围遍历
python
for j in range(i + 1, n + 1):
words = sentence[i:j]注意:
range(i + 1, n + 1)确保至少取一个字符(j > i)n + 1确保可以取到句子末尾(sentence[i:n])
3.6 算法复杂度分析
时间复杂度
-
最坏情况:O(2^n)
- 当每个字符都可以作为单字词,且任意连续子串都在词典中时
- 例如:
"aaaa",每个字符都是词,任意组合都是词
-
平均情况:O(n² × m)
- n:句子长度
- m:平均每个位置可能的词语数量
- 记忆化优化后,每个位置最多计算一次
-
实际优化后:O(n²)
- 记忆化避免了重复计算
- 每个位置最多被访问一次
空间复杂度
-
记忆化字典:O(n²)
- 最多存储n个位置的结果
- 每个位置的结果最多包含O(n)个切分方式
-
递归栈:O(n)
- 递归深度最多为n
-
总空间复杂度:O(n²)
3.7 测试验证
代码包含完整的测试验证逻辑:
python
# 将结果转换为集合进行比较
result_set = set(tuple(item) for item in all_cut(sentence, Dict))
target_set = set(tuple(item) for item in target)
if result_set == target_set:
print("Yes") # 测试通过
else:
print("No") # 测试失败验证方法:
- 将列表转换为元组(因为列表不可哈希)
- 使用集合比较,忽略顺序差异
- 确保结果完整性和正确性
四、应用场景和具体落实
4.1 中文分词系统
4.1.1 应用场景
中文分词系统是自然语言处理的基础组件,广泛应用于:
- 搜索引擎:百度、Google等搜索引擎的中文分词
- 输入法:搜狗输入法、百度输入法等智能输入
- 文本处理工具:Word、WPS等办公软件的中文处理
4.1.2 具体落实
步骤1:全切分生成候选集
python
# 使用全切分找出所有可能的切分方式
all_segmentations = all_cut(sentence, Dict)步骤2:最优切分选择
python
# 方法1:基于词频的最大概率切分
def best_cut_by_frequency(all_segmentations, Dict):
best = None
max_prob = 0
for seg in all_segmentations:
prob = 1.0
for word in seg:
prob *= Dict.get(word, 0.0001) # 使用词频
if prob > max_prob:
max_prob = prob
best = seg
return best
# 方法2:基于语言模型的最优切分
def best_cut_by_lm(all_segmentations, language_model):
# 使用N-gram模型计算概率
# 选择概率最大的切分方式
pass步骤3:集成到分词系统
python
class ChineseSegmenter:
def __init__(self, dict_path):
self.dict = self.load_dict(dict_path)
def segment(self, sentence):
# 1. 全切分
all_cuts = all_cut(sentence, self.dict)
# 2. 最优选择
best_cut = self.select_best(all_cuts)
return best_cut4.2 歧义消解研究
4.2.1 应用场景
- 学术研究:研究中文分词中的歧义问题
- 算法改进:开发更好的歧义消解算法
- 系统评估:评估分词系统处理歧义的能力
4.2.2 具体落实
步骤1:歧义发现
python
def find_ambiguities(sentence, Dict):
all_cuts = all_cut(sentence, Dict)
# 如果切分方式大于1,说明存在歧义
if len(all_cuts) > 1:
print(f"发现歧义:{sentence}")
print(f"歧义数量:{len(all_cuts)}")
for i, cut in enumerate(all_cuts, 1):
print(f" 切分方式{i}:{cut}")
return all_cuts步骤2:歧义分析
python
def analyze_ambiguities(sentence, Dict):
all_cuts = all_cut(sentence, Dict)
# 分析歧义类型
ambiguities = {
'cross_ambiguity': [], # 交叉歧义
'combination_ambiguity': [], # 组合歧义
'overlap_ambiguity': [] # 重叠歧义
}
# 比较不同切分方式,识别歧义类型
# ...
return ambiguities步骤3:歧义消解
python
def resolve_ambiguity(sentence, Dict, context=None):
all_cuts = all_cut(sentence, Dict)
if len(all_cuts) == 1:
return all_cuts[0]
# 使用上下文信息消解歧义
if context:
# 基于上下文选择最合适的切分
best_cut = select_by_context(all_cuts, context)
else:
# 使用统计方法选择
best_cut = select_by_statistics(all_cuts, Dict)
return best_cut4.3 搜索引擎
4.3.1 应用场景
- 查询理解:理解用户的搜索意图
- 索引构建:为文档建立倒排索引
- 相关性计算:计算查询与文档的相关性
4.3.2 具体落实
步骤1:查询分词
python
class SearchEngine:
def __init__(self):
self.dict = self.load_search_dict()
def process_query(self, query):
# 对用户查询进行全切分
all_cuts = all_cut(query, self.dict)
# 选择最可能的切分方式
best_cut = self.select_best_cut(all_cuts, query_type='search')
# 提取关键词
keywords = self.extract_keywords(best_cut)
return keywords步骤2:文档索引
python
def index_document(doc_id, content, dict):
# 对文档内容进行全切分
all_cuts = all_cut(content, dict)
# 为每种可能的切分建立索引
for cut in all_cuts:
for word in cut:
add_to_index(word, doc_id)步骤3:查询匹配
python
def search(query, index, dict):
# 处理查询
query_cuts = all_cut(query, dict)
# 对每种切分方式进行搜索
results = []
for cut in query_cuts:
docs = search_index(cut, index)
results.extend(docs)
# 合并和排序结果
return rank_results(results)4.4 机器翻译
4.4.1 应用场景
- 中文到其他语言:将中文文本翻译成英文、日文等
- 预处理步骤:在翻译前进行分词处理
- 对齐处理:处理源语言和目标语言的词语对齐
4.4.2 具体落实
步骤1:源语言分词
python
class MachineTranslator:
def translate(self, chinese_text):
# 1. 全切分找出所有可能的切分
all_cuts = all_cut(chinese_text, self.chinese_dict)
# 2. 选择最佳切分(考虑翻译上下文)
best_cut = self.select_for_translation(all_cuts)
# 3. 对每个词进行翻译
translated_words = [self.translate_word(word) for word in best_cut]
# 4. 组合翻译结果
return self.combine_translation(translated_words)步骤2:多切分翻译
python
def translate_with_ambiguity(chinese_text, dict):
all_cuts = all_cut(chinese_text, dict)
# 对每种切分方式进行翻译
translations = []
for cut in all_cuts:
translation = translate_segmentation(cut)
translations.append(translation)
# 选择最佳翻译
return select_best_translation(translations)4.5 文本分析和挖掘
4.5.1 应用场景
- 关键词提取:从文本中提取关键词
- 主题分析:分析文本的主题分布
- 情感分析:分析文本的情感倾向
4.5.2 具体落实
步骤1:文本预处理
python
class TextAnalyzer:
def analyze(self, text, dict):
# 1. 全切分
all_cuts = all_cut(text, dict)
# 2. 选择最佳切分
best_cut = self.select_best_cut(all_cuts)
# 3. 提取特征
features = self.extract_features(best_cut)
return features步骤2:关键词提取
python
def extract_keywords(text, dict, top_k=10):
all_cuts = all_cut(text, dict)
# 统计所有切分方式中的词频
word_freq = {}
for cut in all_cuts:
for word in cut:
word_freq[word] = word_freq.get(word, 0) + 1
# 选择频率最高的词
keywords = sorted(word_freq.items(), key=lambda x: x[1], reverse=True)[:top_k]
return [word for word, freq in keywords]步骤3:多切分特征融合
python
def extract_features_with_all_cuts(text, dict):
all_cuts = all_cut(text, dict)
# 对每种切分提取特征
all_features = []
for cut in all_cuts:
features = extract_features_from_cut(cut)
all_features.append(features)
# 融合所有特征
fused_features = fuse_features(all_features)
return fused_features4.6 自然语言理解(NLU)
4.6.1 应用场景
- 意图识别:识别用户的意图
- 实体抽取:从文本中抽取实体
- 关系抽取:抽取实体之间的关系
4.6.2 具体落实
步骤1:意图识别
python
class NLUSystem:
def understand(self, user_input, dict):
# 1. 全切分
all_cuts = all_cut(user_input, dict)
# 2. 对每种切分进行意图识别
intents = []
for cut in all_cuts:
intent = self.classify_intent(cut)
intents.append(intent)
# 3. 选择最可能的意图
best_intent = self.select_best_intent(intents)
return best_intent步骤2:实体抽取
python
def extract_entities(text, dict, entity_dict):
all_cuts = all_cut(text, dict)
entities = []
for cut in all_cuts:
# 在切分结果中查找实体
for word in cut:
if word in entity_dict:
entities.append({
'word': word,
'type': entity_dict[word],
'cut': cut
})
return entities4.7 智能问答系统
4.7.1 应用场景
- 问答匹配:匹配问题和答案
- 知识检索:从知识库中检索相关信息
- 答案生成:生成问题的答案
4.7.2 具体落实
步骤1:问题理解
python
class QASystem:
def answer(self, question, dict):
# 1. 对问题进行全切分
all_cuts = all_cut(question, dict)
# 2. 提取问题关键词
keywords = []
for cut in all_cuts:
keywords.extend(self.extract_keywords(cut))
# 3. 在知识库中搜索
answers = self.search_knowledge_base(keywords)
# 4. 生成答案
return self.generate_answer(answers)4.8 代码优化和扩展
4.8.1 性能优化
优化1:限制切分数量
python
def all_cut_limited(sentence, Dict, max_cuts=1000):
# 当切分方式过多时,只返回前max_cuts种
all_cuts = all_cut(sentence, Dict)
if len(all_cuts) > max_cuts:
# 使用启发式方法选择最重要的切分
return select_important_cuts(all_cuts, max_cuts)
return all_cuts优化2:并行计算
python
from multiprocessing import Pool
def all_cut_parallel(sentences, Dict):
with Pool() as pool:
results = pool.starmap(all_cut, [(s, Dict) for s in sentences])
return results4.8.2 功能扩展
扩展1:支持词性标注
python
def all_cut_with_pos(sentence, Dict):
all_cuts = all_cut(sentence, Dict)
# 为每个切分添加词性标注
cuts_with_pos = []
for cut in all_cuts:
pos_tags = [get_pos_tag(word) for word in cut]
cuts_with_pos.append(list(zip(cut, pos_tags)))
return cuts_with_pos扩展2:支持命名实体识别
python
def all_cut_with_ner(sentence, Dict, ner_dict):
all_cuts = all_cut(sentence, Dict)
# 识别命名实体
cuts_with_ner = []
for cut in all_cuts:
entities = identify_entities(cut, ner_dict)
cuts_with_ner.append({
'segmentation': cut,
'entities': entities
})
return cuts_with_ner五、总结
5.1 算法优势
- 完整性:能够找出所有可能的切分方式,不遗漏任何情况
- 正确性:保证每个切分结果中的词语都在词典中
- 高效性:通过记忆化优化,避免重复计算
- 灵活性:可以轻松扩展和集成到其他系统中
5.2 算法局限
- 组合爆炸:对于复杂句子,切分方式可能非常多
- 词典依赖:完全依赖词典,无法处理未登录词
- 无语义理解:不考虑上下文和语义信息
- 效率问题:对于超长文本,计算时间可能较长
5.3 改进方向
- 剪枝策略:使用启发式方法提前剪枝不可能的路径
- 动态词典:结合未登录词识别,动态扩展词典
- 上下文感知:考虑上下文信息,优先选择合理的切分
- 并行优化:利用多核CPU或GPU加速计算
5.4 实际应用建议
- 结合其他方法:全切分通常作为第一步,需要结合统计方法或机器学习方法选择最优切分
- 词典质量:词典的质量直接影响切分结果,需要维护高质量的词典
- 性能平衡:在实际应用中,可能需要在完整性和效率之间做出权衡
- 领域适配:针对不同领域(如医疗、法律),需要构建专门的词典
参考文献
- 宗成庆. 统计自然语言处理(第2版). 清华大学出版社, 2013.
- 黄昌宁, 赵海. 中文信息处理. 清华大学出版社, 2007.
- 刘群. 中文分词技术综述. 中文信息学报, 2011.
- 张华平, 刘群. 基于层叠隐马尔可夫模型的中文命名实体识别. 计算机研究与发展, 2004.